Stylization of music using neural networks

Over the past decade, deep neural networks (Deep Neural Networks, DNN) have become an excellent tool for a number of AI tasks such as image classification, speech recognition, and even participation in games. As developers tried to show how DNN’s success in the field of image classification was created and they created visualization tools (for example, Deep Dream, Filters) to help them understand what the DNN model was “studying”, a new interesting application emerged. : extracting “style” from one image and applying to another, different content. This is called “visual style transfer” (image style transfer).
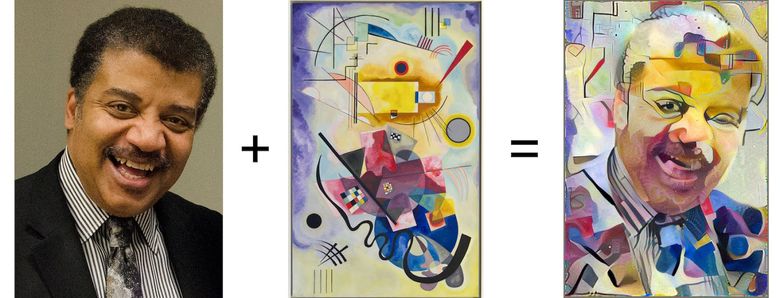
Left: image with useful content, in the center: image with style, right: content + style (source: Google Research Blog )
This not only stirred the interest of many other researchers (for example, 1 and 2 ), but also led to the emergence of several successful mobile applications. Over the past couple of years, these methods of transferring the visual style have greatly improved.

Transferring style from Adobe (source: Engadget )

Prisma example
A short introduction to the work of such algorithms:
However, despite the advances in working with images, the application of these techniques in other areas, for example, for processing music, was very limited (see 3 and 4 ), and the results are not at all as impressive as in the case of images. This suggests that in music to transfer the style is much more difficult. In this article we will look at the problem in more detail and discuss some possible approaches.
Why is it so difficult to endure style in music?
Let's first answer the question: what is “style transfer” in music ? The answer is not so obvious. In the images, the concepts of “content” and “style” are intuitive. “Image content” describes the objects represented, for example, dogs, houses, faces, and so on, and “image style” refers to colors, lighting, brush strokes, and texture.
However, music is by its nature semantically abstract and multidimensional . “Music Content” can mean different things in different contexts. Often the music content is associated with the melody, and the style - with the arrangement or harmonization. However, the content may be the lyrics of the song, and the different melodies used for singing can be interpreted as different styles. In classical music, the content can be considered a score (including harmonization), while the style will be the interpretation of the notes by the performer who brings his own expression (varying and adding some sounds from himself). To better understand the essence of the transfer of style in music, watch a couple of these videos:
In the second video, various machine learning techniques are used.
So, the transfer of style in music is by definition difficult to formalize. There are other key factors complicating the task:
- BAD machines understand music (for now): success in porting style in images stems from the success of DNN in tasks related to understanding images, for example, recognizing objects. Since DNNs can learn properties that vary across different objects, back propagation techniques can be used to modify the target image to match the properties of the content. Although we have made significant progress in creating models based on DNN, capable of understanding musical tasks (for example, transcribing a melody, defining a genre, etc.), we are still far from the heights achieved in image processing. This is a serious obstacle to the transfer of style in music. Existing models simply can not learn the "excellent" properties that allow to classify music, and therefore the direct use of style transfer algorithms used when working with images, does not give the same result.
- Music is transient : it is data that represents a dynamic series, that is, a piece of music changes with time. This complicates learning. And although recurrent neural networks and LSTM (Long Short-Term Memory, long short-term memory) make it possible to study more efficiently with transient data, we still have to create reliable models that can learn to reproduce the long-term structure of music (note: this is a current research direction, and scientists from Google Magenta achieved some success in this ).
- Music is discrete (at least at the symbolic level): character, or music recorded on paper is inherently discrete. In a uniformly tempered system , the most popular system for tuning musical instruments today, sound tones occupy discrete positions on a continuous scale of frequencies. At the same time, the duration of the tones also lies in the discrete space (they usually single out quarter tones, full tones, and so on). Therefore, it is very difficult to adapt pixel back-propagation methods (used for working with images) in the field of symbolic music.
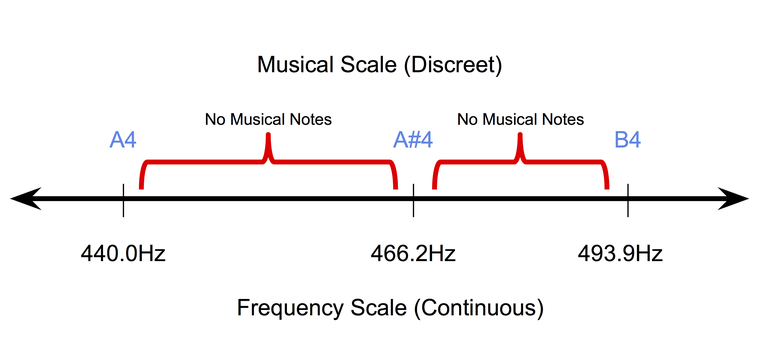
The discrete nature of musical notes in a uniformly tempered structure.
Consequently, the techniques used to transfer the style in images are not directly applicable in music. To do this, they need to recycle with an emphasis on musical concepts and ideas.
What is the transfer of style in music?
Why do we need to solve this problem? As in the case of images, the potential applications of style transfer in music are quite interesting. For example, the development of a tool to help composers . For example, an automatic instrument that can transform a melody using arrangements from different genres will be extremely useful for composers who need to quickly try out different ideas. Interested in such instruments and DJs.
The indirect result of such research will be a significant improvement in musical informatics systems. As explained above, in order for the transfer of style to work in music, the models we create must learn to better “understand” different aspects.
Simplify the task of transferring style in music
Let's start with a very simple task of analyzing monophonic melodies in different genres. Monophonic melodies are sequences of notes, each of which is determined by tone and duration. The tone progression mostly depends on the melody scale, and the duration progression depends on the rhythm. So, first, we clearly distinguish between “ pitch content” and “rhythmic style” (rhythmic style) as two entities with which you can rephrase the style transfer task. Also, when working with monophonic melodies, we will now avoid tasks related to arrangement and text.
In the absence of pre-trained models that can successfully distinguish between tonal progression and rhythms of monophonic melodies, we first resort to a very simple approach to transferring style. Instead of trying to change the tone content learned on the target melody, the rhythm style learned on the target rhythm, we will try individually to teach patterns of tones and durations from different genres, and then try to combine them. Approximate approach scheme:
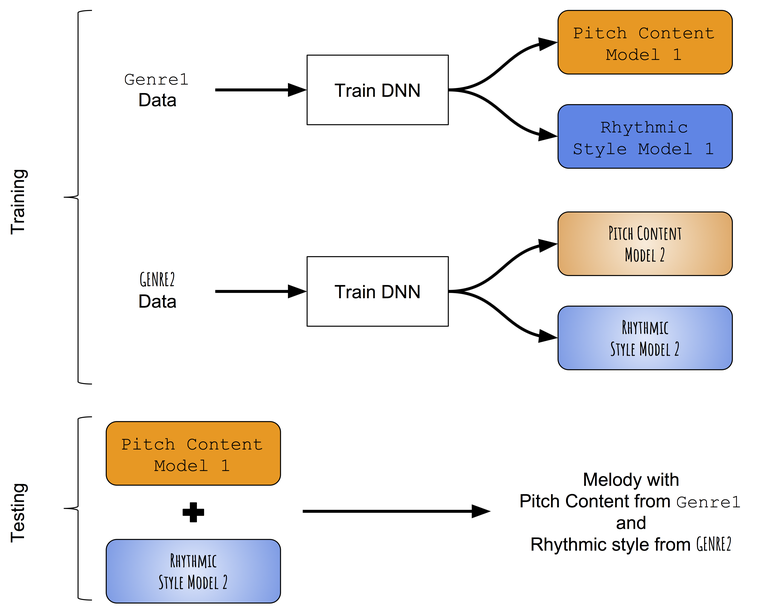
Diagram of inter-genre transfer method of style.
We teach separately tonal and rhythmic progression
Data presentation
We will present monophonic melodies as a sequence of musical notes, each of which has an index of tone and sequence. In order for our presentation key to be independent, we use the interval-based representation: the tone of the next note will be represented as a deviation (± semitones) from the tone of the previous note. Create two dictionaries for tones and durations in which each discrete state (for a tone: +1, -1, +2, -2, and so on; for durations: a quarter note, full note, quarter with a dot, and so on) assigned an index dictionary.
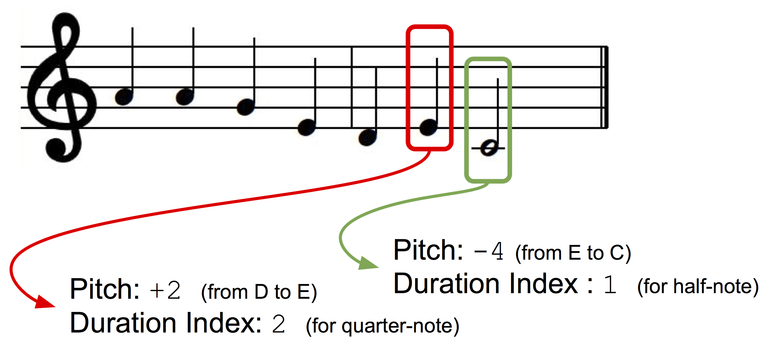
Presentation of data.
Model architecture
We will use the same architecture that Colombo and colleagues used — they simultaneously taught two LSTM neural networks to the same music genre: a) the tone network learned to predict the next tone based on the previous note and the previous duration, b) the duration network learned to predict the next duration based on the next note and previous duration. Also, before the LSTM networks, we will add embedding layers (embedding layer) to match the input tone and duration indices in memorized embedding spaces. The neural network architecture is shown in the picture:
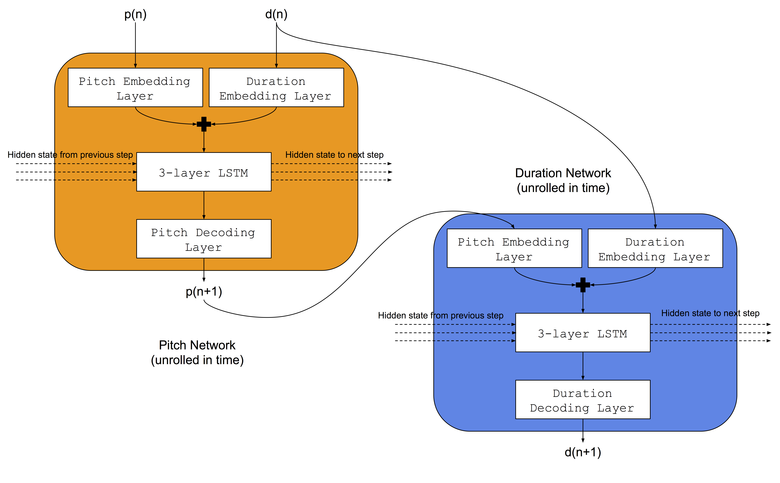
Learning procedure
For each genre, the networks responsible for tones and durations are trained simultaneously. We will use two datasets: a) Norbeck Folk Dataset , covering about 2000 Irish and Swedish folk tunes, b) jazz dataset (not publicly available), covering about 500 jazz tunes.
Merging trained models
When testing, the melody is first generated using a tone network and a network of durations that are trained in the first genre (say, folk). Then the sequence of tones from the generated melody is used at the input for a network of sequences trained in a different genre (say, jazz), and the result is a new sequence of durations. Therefore, a melody created using a combination of two neural networks has a sequence of tones corresponding to the first genre (folk), and a sequence of durations corresponding to the second genre (jazz).
Preliminary results
Short excerpts from some of the resulting tunes:
Folk-tones and folk-duration

Excerpt from musical notation.

Excerpt from musical notation.

Excerpt from musical notation .

Excerpt from musical notation.
Conclusion
Although the current algorithm is not bad for a start, it has some critical flaws:
- It is impossible to "transfer style" based on a specific target melody . Models learn patterns of tones and durations on the genre, which means all transformations are determined by the genre. It would be ideal to change a piece of music in the style of a specific target song or piece.
- Unable to control the degree of style change. It would be very interesting to get a “handle” that controls this aspect.
- When merging genres, it is impossible to preserve the musical structure in the transformed melody. The long-term structure is important for musical evaluation as a whole, and for the generated melodies to be musically aesthetic, the structure must be preserved.
In future articles, we will look at ways to circumvent these shortcomings.
Source: https://habr.com/ru/post/409697/