AttnGAN neural network draws objects in parts, using the vector space of not only sentences, but also words

AttnGAN example. In the top row are several images of different resolutions, generated by the neural network. In the second and third rows, the processing of the five most appropriate words is shown by two models of neural network attention for drawing the most relevant sections.
The automatic creation of images from textual descriptions in natural language is a fundamental problem for many applications, such as the generation of works of art and computer design. This problem also stimulates progress in the field of multimodal learning of AI with the interconnection of vision and language.
Recent developments by researchers in this area are based on generative-adversary networks (GAN). A common approach is to translate the entire text description into the global vector sentence space (global sentence vector). This approach demonstrates a number of impressive results, but it has major drawbacks: the lack of clear detail at the word level and the impossibility of generating high-resolution images. A group of developers from Lehigh University, Rutgers University, Duke University (all from the USA) and Microsoft offered their solution to the problem: the Attentional Generative Adversarial Network (AttnGAN) is an improvement of the traditional approach and allows you to change the generated image in several steps by changing individual words in the text the description.
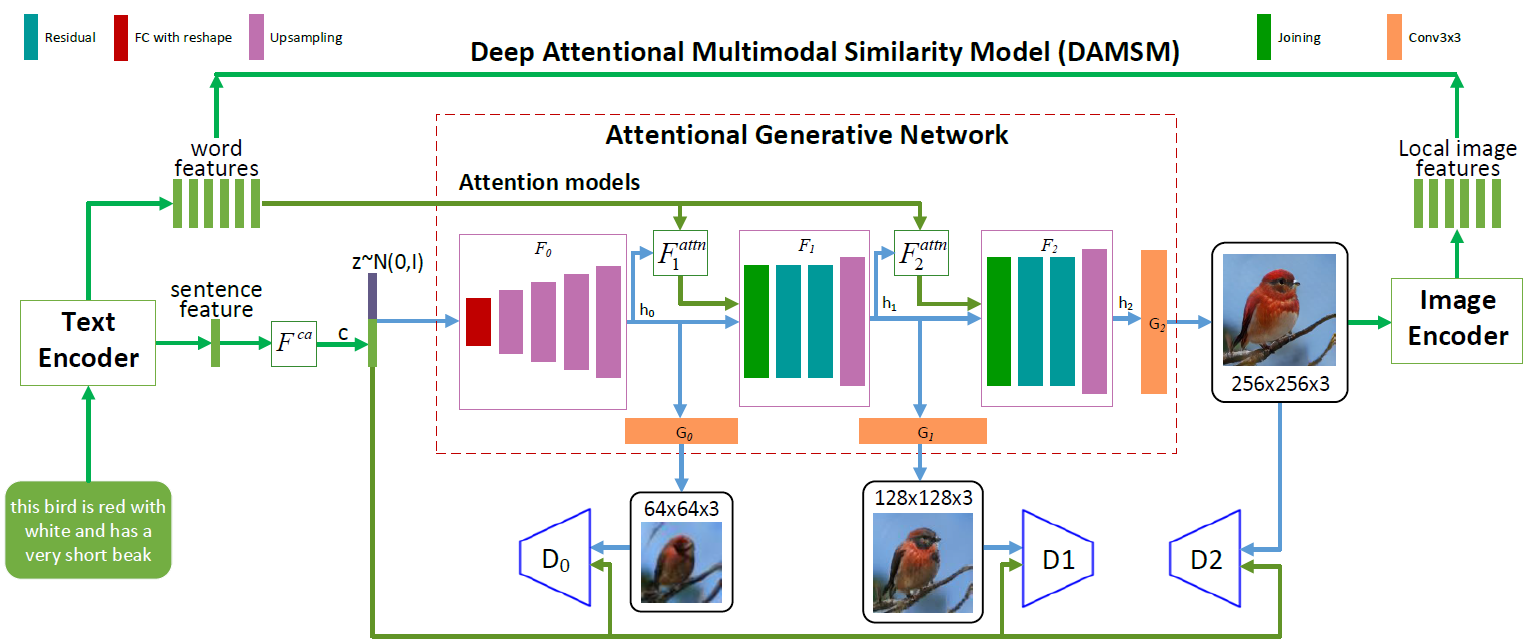
AttnGAN neural network architecture. Each attention model automatically receives conditions (i.e., corresponding word vectors) for generating different areas of the image. The DAMSM module provides additional detailing for the loss of compliance function on the translation from image to text in the generation network.
As can be seen in the illustration of the neural network architecture, the AttnGAN model has two innovations compared to traditional approaches.
First, it is the generative-adversary network, which treats attention as a training factor (Attentional Generative Adversarial Network). That is, it implements the attention mechanism, which defines the words most suitable for generating the corresponding parts of the picture. In other words, in addition to coding the entire text description in the global vector sentence space, each individual word is also encoded as a text vector. At the first stage, the generative neural network uses the global vector space of sentences to draw a low-resolution image. In the next steps, she uses the image vector in each region to query the word vectors, using the attention layer to form the word-context vector. Then the regional image vector is combined with the corresponding word-vector vector to form a multimodal context vector, on the basis of which the model generates new image attributes in the respective regions. This allows you to effectively increase the resolution of the entire image as a whole, since at each stage there is increasing detail.
Microsoft's second neural network innovation is the Deep Attentional Multimodal Similarity Model (DAMSM) module. Using the attention mechanism, this module calculates the degree of similarity of the generated image and the text sentence, using both the information from the level of the vector space of sentences and the well-detailed level of word vectors at the same time. Thus, DAMSM provides additional detail for the loss of correspondence function on translation from image to text when training a generator.
Thanks to these two innovations, the AttnGAN neural network shows significantly better results than the best of the traditional GAN systems, the developers write. In particular, the maximum known inception score for existing neural networks has been improved by 14.14% (from 3.82 to 4.36) on the CUB data set and improved by as much as 170.25% (from 9.58 to 25.89) on the more complex COCO dataset.
The importance of this development is difficult to overestimate. The AttnGAN neural network for the first time showed that a multi-layer, generative-adversary network that relates to attention as a learning factor can automatically determine word-level conditions for generating individual parts of an image.
The scientific article was published on November 28, 2017 on the site of preprints arXiv.org (arXiv: 1711.10485v1).
Source: https://habr.com/ru/post/409747/