How to deal with flaky tests in the opensource community
The problem of flaky-tests faced by many projects, and this topic has repeatedly raised on Habré. Tests that do not determine their condition constantly take away not only the machine time, but also the time of developers and testers. And if in a commercial company it is possible to allocate a certain resource for solving this problem and assign responsible persons, then in the opensource community everything is not so simple. Especially when it comes to large projects - for example, such as Apache Ignite, where there are almost 60 thousand different tests.

In this post, we, in fact, describe how to solve this problem in Apache Ignite. We are Dmitry Pavlov, lead software engineer / community manager in GridGain, and Nikolai Kulagin, IT engineer at Sberbank-Technologies.
Everything written below does not represent the position of any company, including Sberbank. This story is exclusively from members of the Apache Ignite community.
The Apache Ignite story begins in 2014, when GridGain donated the first version of an internal product to the Apache Software Foundation. More than 4 years have passed since that time, and during this time the number of tests has reached 60 thousand.
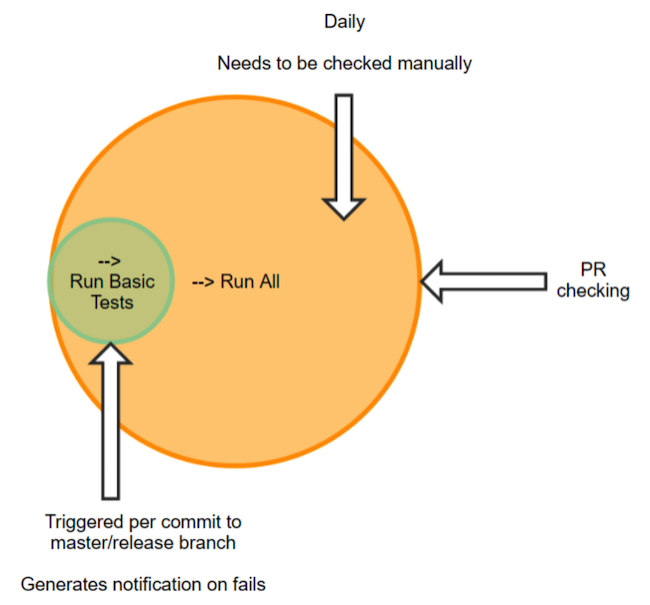
As a continuous integration server, we use JetBrains TeamCity - thanks to the guys from JetBrains for supporting opensource movement. All our tests are distributed by suites, the number of which for the master branch is close to 140. In the suites, the tests are grouped according to some sign. This may be testing only the functionality of Machine Learning [RunMl], only the cache [RunCache], or the entire [RunAll]. In the future, the test run will be referred to as [RunAll] - a full check. It takes about 55 hours of computer time.
Junit is used as the main library, but few unit tests are found. For the most part, all our tests are integration because they contain the launch of one or more nodes (and this takes a few seconds). Of course, integration tests are convenient in that one such test covers many aspects and interactions, which is quite difficult to achieve with a single unit test. But there are drawbacks: in our case, this is quite a long time to complete, as well as the difficulty of finding the problem.
Some of these tests have difficulty with flaky. Now according to the classification of TeamCity, approximately 1700 tests are marked as flaky - that is, with a change of state without changing the code or configuration. Such tests cannot be ignored, since there is a risk of getting a bug in production. Therefore, they have to be rechecked and restarted, sometimes several times, to analyze the results of falls - and precious time and energy is wasted on it. And if already existing members of the community cope with this task, then for new contributors this can be a real barrier. Agree that by doing the editing of Java Doc, you do not expect to face a fall, and not with one, but with several dozens.

Half of the flaky test problems are due to hardware configuration, due to the size of the installation. And the second half is directly related to people who missed and did not fix their bug.
Conventionally, all members of the community can be divided into two groups:
A contributor from the first group may well make a single edit and leave the community. And to reach him in case of detection of a bug is almost impossible. It is easier to interact with people from the second group; they are more likely to react to the test they have broken. But it happens that a company that was previously interested in a product has ceased to need it. She leaves the community, and with it her contributors. Or it is possible that the contributor leaves the company, and with it the community. Of course, after such changes, some still continue to participate in the life of the community. But not all.
If we are talking about people who have left the community, then their bugs, of course, go to the current contributors. It is worth noting that the reviser is also responsible for the revision that led to the bug, but it can also be an enthusiast - that is, it will not always be available.
It happens that it is possible to reach a person, tell him: this is the problem. But he says: no, it was not my fix that introduced the bug. Since the full run of the master branch is automatically performed with a relatively free queue, this happens most often at night. Before that, several commits can be poured into a branch all day.
In TeamCity, any modification of the code is regarded as a change. If after three changers we have a new fall, then three people will say that this is not related to their commit. If there are five changers, then we will hear it from five people.
Another problem: to convey to the contributor that the tests must be run before each review. Some do not know where, what and how to run. Or the tests were run, but the contributor did not write about it in the ticket. At this stage, too, problems arise.
Go ahead. Imagine that the tests are run out, and in the ticket there is a link to the results. But, as it turned out, this does not give any guarantees for the analysis of the tests run. The contributor may look at his run, see some falls there, but write “TeamCity Looks Good”. The reviewer - especially if he is familiar with the contributor or has successfully reviewed it before - may not really see the result. And we get this “TeamCity Looks Good”:
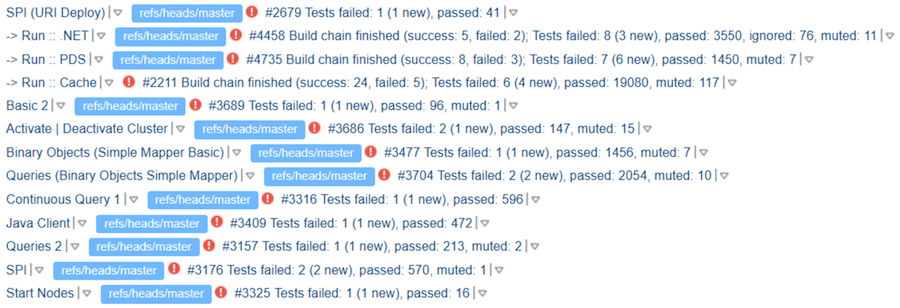
Where is the "Good" - is unclear. But apparently, the authors at least know that the tests need to be run.
We divided the tests into two groups. In the first, “clean” - stable tests. In the second - unstable. The approach is quite obvious, but it was not justified even from two attempts. Why? Because suites with unstable tests turn into such a ghetto, where something starts to necessarily time out, crash, etc. As a result, everyone starts to simply ignore these ever-problematic tests. In general, it makes no sense to divide the tests by grade.
The second option is similar to the first - to allocate more stable tests, and the remaining tests on PR to drive at night. If something breaks in a stable group, a message stating that something needs to be fixed is sent to the distributor using standard TeamCity tools.
0 people responded to these messages. Everyone ignored them.
We divided the suites into several "observers", the most responsible members of the community, and signed them up for alerts about falls. As a result, in practice, it was confirmed that enthusiasm tends to end. Contributors throw this venture and stop checking regularly. I missed it, looked there, and again something climbed into the master.
After another unsuccessful method, the guys from GridGain recalled a previously developed utility that adds functionality that was not available at that time on TeamCity. Namely, the ability to view general statistics on the number of falls: how many and what fell, worsened or improved the result the next day. This utility began to gradually develop, added reports, renamed. Then they added notifications, renamed again. So it turned out TeamSity Bot. Now it has almost 500 commits and 7 contributors and it is in the Apache supplementary repository.
What does the bot do? Its capabilities can be combined into two groups:
Before the advent of Apache Ignite Teamcity Bot, the process of “contributing” to the community was as follows:
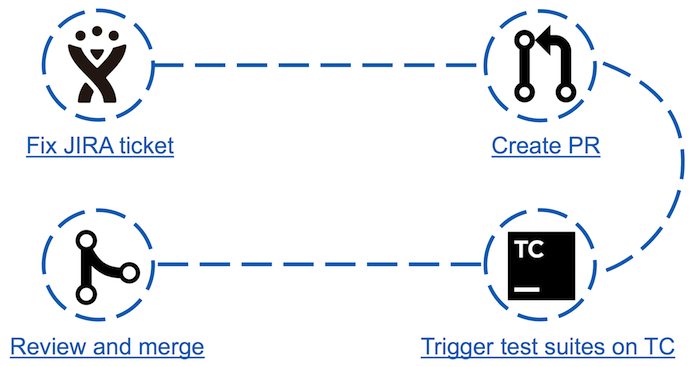
It looks simple, but in fact the third item may be a barrier for some contributors. For example: a novice in the community decides to make his first contribution by choosing the easiest ticket possible. This may be a java doc edit or maven dependency version update. Analyzing the results of the run according to his small fix, he suddenly discovers that about 30 tests have fallen. He does not know where such a number of tests failed and how to analyze them. The expected consequence may be that the contributor will never return here again.
More experienced members of the community also suffer from flaky - spend time analyzing tests that have fallen by chance, and thus inhibit product development.
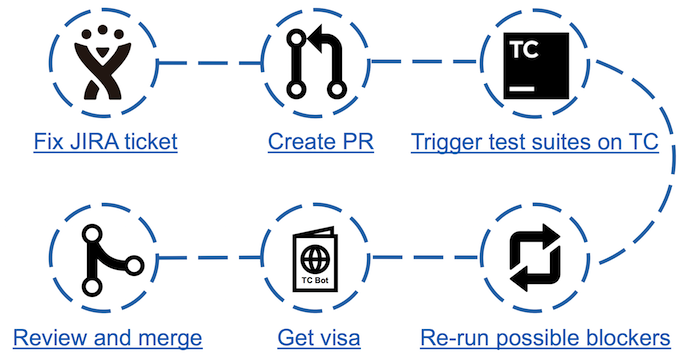
Contributing scheme with TeamCity Bot
With the advent of the bot steps in the confusion has increased, but the time spent on the analysis of the fallen tests, significantly reduced. Now it is enough to run the check and after passing it look at the appropriate page of the bot. If there are possible blockers (dropped tests that are not considered flaky), it is enough to run a double-check, as a result of which get a visa in the form of a comment in JIRA with the results of testing.

Inspect Contribution - a list of all unclosed PRs with summary information for each: the last update date, PR number, title, author, and ticket in JIRA .

For each pull request, a tab with more detailed information is available: the correct name of the PR, without which the bot will not be able to find the right ticket in JIRA; whether tests were run; Is the test result ready? left a comment in JIRA.
Analysis of test results:


Here are two reports on testing the same PR. The first is from the bot. The second is a standard report on Teamcity. The difference in the amount of information is obvious, and this is without taking into account the fact that in order to view the history of test runs on TC, it will also be necessary to make several transitions to adjacent pages.
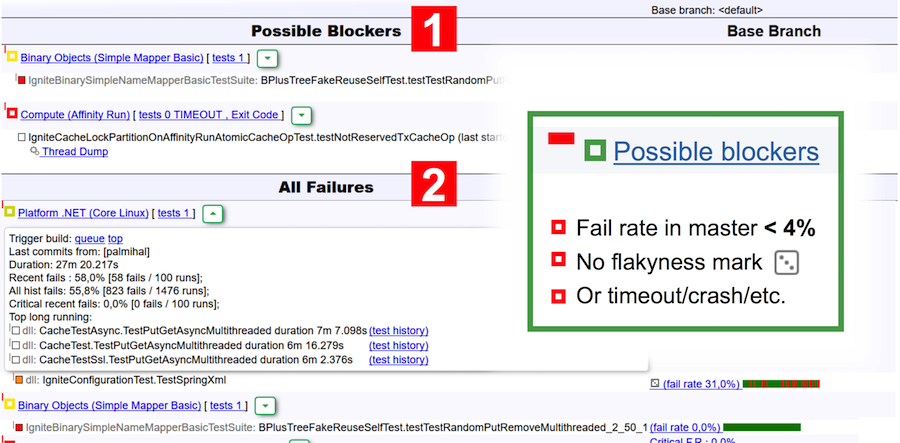
Let's return to the bot report. This report is visually divided into two tables: possible blockers and all drops. The blockers include tests that:
For example, in the screenshot above, two suites are listed as possible blockers - the first test crash occurred, and the second crash timed out.
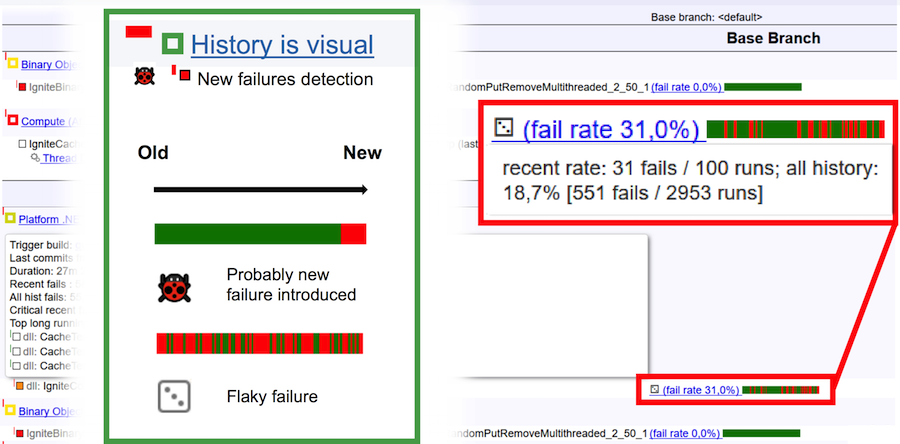
To finally understand what is flaky dough, and what a bug, consider the picture above. The horizontal bar is 100 runs. Vertical green bar - successful passing the test, red - falling. In the case of a bug, the run history looks natural: the monotonous green bar at the end changes color to red. This means that exactly in this place a bug appeared and the test began to fall constantly. If we have a flaky test before us, then its history of runs is a continuous alternation of green and red colors.
Analysis of test results
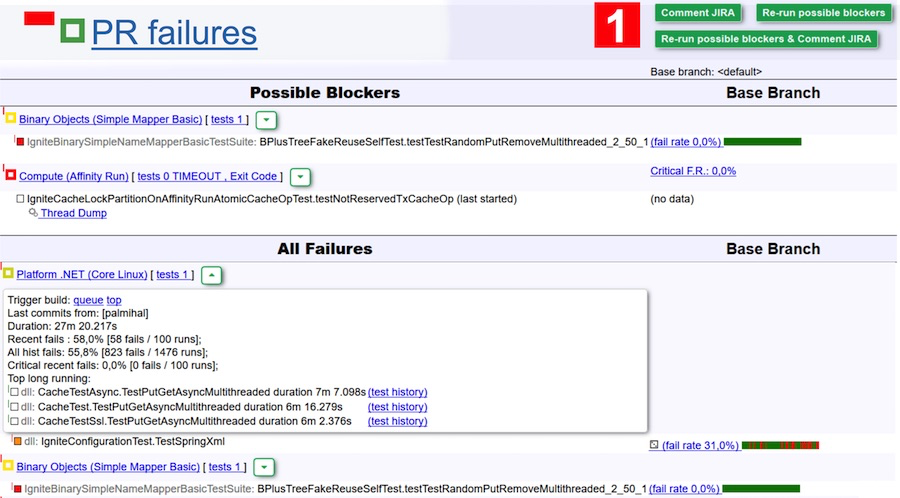
For example, let's analyze the results of passing the tests in the screenshot above. According to the bot version, there may be two drops due to a bug - they are listed in the Possible Blockers table. But it may well be flaky tests with a low fail rate. To exclude this option, simply click the Re-run possible blockers button, and these two suites will go to a double-check. To further simplify the task, you can click Re-run possible blockers & comment JIRA, and get a comment (and with it a notification in the mail) from the bot after the end of the check. Then go in and see if there is a problem or not.
For reviewers, this is very cool. You can forget about edits that did not pass any checks, but simply click on a number of edits, press the big green Re-run button and wait for the letter.
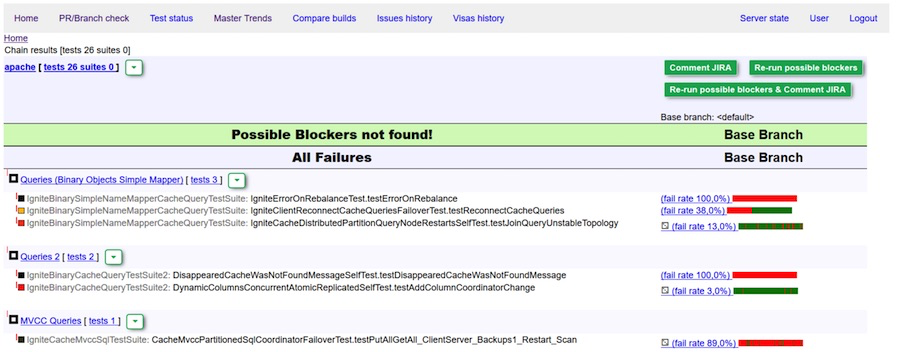
Perfect report: no blockers found

Green visa (comment) bot. No blockers detected.
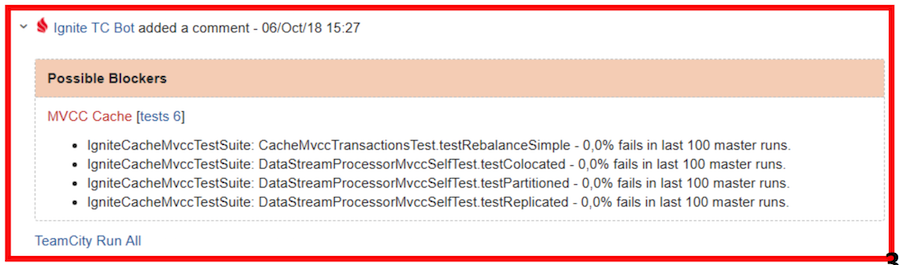
Red Visa - requires verification and / or editing of bugs
It happens that in the "master" still leak some bugs. As we have already said, we have previously struggled with this through personal notifications. Or some person made sure that nothing fell. Now we use a simpler solution:

When a new bug is detected, a message is sent to the dev-list, in which the contributors and their changes are indicated, which may be the cause of the error. So the whole community will know for whom everything happened.
Thus, we managed to increase the number of hotfixes and greatly reduce the time spent on fixing the problem.
Wizard status monitoring
One of the functions of the bot is to monitor the status of the wizard with the statistics on the latest launches.

Master trends

On the Master trends page, two “master” samples are compared for specific time intervals. For each item in the table displays the maximum, minimum value and median.

In addition to the general results for the entire sample, the table contains graphs for each indicator showing the values of each build. Clicking on a point, you can go to the results of the run on TeamCity. In addition, it is possible to remove the result from the statistics. This is useful when completely abnormal values occur, due to serious breakdowns, which are probably not the fault of the contributor. Such results should be excluded so that they are not taken into account when calculating the same flaky tests. In addition, the build can also be highlighted to follow the results for each indicator.
Over 65 people are currently registered with Apache Ignite Teamcity Bot. For all the time the bot was used, over 400 pull requests were received, and on average, five visas are issued per day.
The bot is located on a separate server, goes to ignite.apache.org for data, publicly notifies everyone on the dev-list — this is our main platform for Ignite developers — and writes visas on tickets through the JIRA API.
Jetty server, Jersey servlets, a number of services with complex business logic of the bot itself, including Teamcity, JIRA and GitHub services that use the Ignited Integration service are used. Over this Pure Integration for http requests. As storage - Apache Ignite's own product in the Single Node embedded-mode configuration with active persistence. In addition to the obvious advantages of using Ignite as a database, it also helps us find various uses of Ignite and understand what is convenient and what is not.
The first bot implementation was inspired by one article on REST caching and was a REST cache and GitHub and Teamcity services. The xml and json returned from the Teamcity server were versed in Pure Java Objects, which were then cached. At first it worked, and quite quickly. But with the increase in the amount of data results began to deteriorate.
It is worth noting here that TeamCity deletes a story older than ~ 2 weeks, but a bot does not. In the end, with this approach, there were tons of data that are very difficult to manage.
In the new approach, a variant of compact data storage is implemented and the choice is made in favor of a small number of cache partitions. A large number of partitions on one node adversely affects the speed of data synchronization to the disk and increases the start time of the cluster.
All major data updates are performed asynchronously, because otherwise we risk getting a bad UX due to the slow return of TeamCity data.
For strings that rarely change their values (for example, test names), a simple mapping into id generated by Atomic Sequence is made. Here is an example of such an Entry:

The long name of the test corresponds to an int-s number, which is stored in all builds. This saves a huge amount of resources. On top of the methods that return this line is the Guava in-memory cache interceptor. Thanks to the cache annotation, we don’t even select lines in heap by reading them from Ignite by id. And by id we always get the same string, which is good for performance.
For “unpredictable” lines, for example, stack trace log, different types of compression are used - gzip-compression, snappy-compression or uncompressed, depending on what is better. All these methods help to fit the maximum data into in-memory and quickly respond to the client.
It’s not to say that TeamSity doesn’t have the capabilities listed above. They are, but scattered on a pile of different places. In the bot, everything is collected on one page and you can quickly understand what the problem is.
A nice addition is a letter that the bot sends to the dev-list when a problem is detected. Immediately in the community there is a reason to start a discussion: “Let's, maybe now we are going to reverse?”. This adds confidence to the reviewers.
With a bot, new contributors are much easier to integrate into the development process. Making your first fix, you don’t always know that the changes you make may result. And diving headlong into the analysis of the test results for TeamCity, you can easily lose the enthusiasm for further development. Apache Ignite TeamCity Bot will also help you quickly understand whether there is a problem and keep you enthusiastic.
We hope that the bot will simplify the lives of current contributors and will attract new people in the community. Finally, we advise, of course, not to allow the appearance of a huge number of flaky-tests, because it is difficult to fight them. And trust the robots - they have no preferences and they do not believe the word for people.
In this post, we, in fact, describe how to solve this problem in Apache Ignite. We are Dmitry Pavlov, lead software engineer / community manager in GridGain, and Nikolai Kulagin, IT engineer at Sberbank-Technologies.
Everything written below does not represent the position of any company, including Sberbank. This story is exclusively from members of the Apache Ignite community.
Apache Ignite and tests
The Apache Ignite story begins in 2014, when GridGain donated the first version of an internal product to the Apache Software Foundation. More than 4 years have passed since that time, and during this time the number of tests has reached 60 thousand.
As a continuous integration server, we use JetBrains TeamCity - thanks to the guys from JetBrains for supporting opensource movement. All our tests are distributed by suites, the number of which for the master branch is close to 140. In the suites, the tests are grouped according to some sign. This may be testing only the functionality of Machine Learning [RunMl], only the cache [RunCache], or the entire [RunAll]. In the future, the test run will be referred to as [RunAll] - a full check. It takes about 55 hours of computer time.
Junit is used as the main library, but few unit tests are found. For the most part, all our tests are integration because they contain the launch of one or more nodes (and this takes a few seconds). Of course, integration tests are convenient in that one such test covers many aspects and interactions, which is quite difficult to achieve with a single unit test. But there are drawbacks: in our case, this is quite a long time to complete, as well as the difficulty of finding the problem.
Flaky issues
Some of these tests have difficulty with flaky. Now according to the classification of TeamCity, approximately 1700 tests are marked as flaky - that is, with a change of state without changing the code or configuration. Such tests cannot be ignored, since there is a risk of getting a bug in production. Therefore, they have to be rechecked and restarted, sometimes several times, to analyze the results of falls - and precious time and energy is wasted on it. And if already existing members of the community cope with this task, then for new contributors this can be a real barrier. Agree that by doing the editing of Java Doc, you do not expect to face a fall, and not with one, but with several dozens.
Who is guilty?
Half of the flaky test problems are due to hardware configuration, due to the size of the installation. And the second half is directly related to people who missed and did not fix their bug.
Conventionally, all members of the community can be divided into two groups:
- Enthusiasts who have fallen into the community of their own accord, and making a contribution to their free time.
- Full-time contributors working in companies that somehow use this open source product or are associated with it.
A contributor from the first group may well make a single edit and leave the community. And to reach him in case of detection of a bug is almost impossible. It is easier to interact with people from the second group; they are more likely to react to the test they have broken. But it happens that a company that was previously interested in a product has ceased to need it. She leaves the community, and with it her contributors. Or it is possible that the contributor leaves the company, and with it the community. Of course, after such changes, some still continue to participate in the life of the community. But not all.
Who will fix?
If we are talking about people who have left the community, then their bugs, of course, go to the current contributors. It is worth noting that the reviser is also responsible for the revision that led to the bug, but it can also be an enthusiast - that is, it will not always be available.
It happens that it is possible to reach a person, tell him: this is the problem. But he says: no, it was not my fix that introduced the bug. Since the full run of the master branch is automatically performed with a relatively free queue, this happens most often at night. Before that, several commits can be poured into a branch all day.
In TeamCity, any modification of the code is regarded as a change. If after three changers we have a new fall, then three people will say that this is not related to their commit. If there are five changers, then we will hear it from five people.
Another problem: to convey to the contributor that the tests must be run before each review. Some do not know where, what and how to run. Or the tests were run, but the contributor did not write about it in the ticket. At this stage, too, problems arise.
Go ahead. Imagine that the tests are run out, and in the ticket there is a link to the results. But, as it turned out, this does not give any guarantees for the analysis of the tests run. The contributor may look at his run, see some falls there, but write “TeamCity Looks Good”. The reviewer - especially if he is familiar with the contributor or has successfully reviewed it before - may not really see the result. And we get this “TeamCity Looks Good”:
Where is the "Good" - is unclear. But apparently, the authors at least know that the tests need to be run.
How we fought it
Method 1. Separation of tests
We divided the tests into two groups. In the first, “clean” - stable tests. In the second - unstable. The approach is quite obvious, but it was not justified even from two attempts. Why? Because suites with unstable tests turn into such a ghetto, where something starts to necessarily time out, crash, etc. As a result, everyone starts to simply ignore these ever-problematic tests. In general, it makes no sense to divide the tests by grade.
Method 2. Separation and Notification
The second option is similar to the first - to allocate more stable tests, and the remaining tests on PR to drive at night. If something breaks in a stable group, a message stating that something needs to be fixed is sent to the distributor using standard TeamCity tools.
0 people responded to these messages. Everyone ignored them.
Method 3. Daily Monitoring
We divided the suites into several "observers", the most responsible members of the community, and signed them up for alerts about falls. As a result, in practice, it was confirmed that enthusiasm tends to end. Contributors throw this venture and stop checking regularly. I missed it, looked there, and again something climbed into the master.
Method 4. Automation
After another unsuccessful method, the guys from GridGain recalled a previously developed utility that adds functionality that was not available at that time on TeamCity. Namely, the ability to view general statistics on the number of falls: how many and what fell, worsened or improved the result the next day. This utility began to gradually develop, added reports, renamed. Then they added notifications, renamed again. So it turned out TeamSity Bot. Now it has almost 500 commits and 7 contributors and it is in the Apache supplementary repository.
What does the bot do? Its capabilities can be combined into two groups:
- Project monitoring - visual monitoring by viewing the results of the runs, as well as automatic notification to the instant messengers (for example, slack)
- Branch verification - analysis of PR testing, as well as issuing a visa in a ticket.
TeamSity Bot work scheme
Before the advent of Apache Ignite Teamcity Bot, the process of “contributing” to the community was as follows:
- In JIRA, one of the tickets is selected and fixed;
- A pull request is created;
- Tests are run that may be affected by the changes made;
- If the tests are passed, the pull request can be verified by the committer.
It looks simple, but in fact the third item may be a barrier for some contributors. For example: a novice in the community decides to make his first contribution by choosing the easiest ticket possible. This may be a java doc edit or maven dependency version update. Analyzing the results of the run according to his small fix, he suddenly discovers that about 30 tests have fallen. He does not know where such a number of tests failed and how to analyze them. The expected consequence may be that the contributor will never return here again.
More experienced members of the community also suffer from flaky - spend time analyzing tests that have fallen by chance, and thus inhibit product development.
Contributing scheme with TeamCity Bot
With the advent of the bot steps in the confusion has increased, but the time spent on the analysis of the fallen tests, significantly reduced. Now it is enough to run the check and after passing it look at the appropriate page of the bot. If there are possible blockers (dropped tests that are not considered flaky), it is enough to run a double-check, as a result of which get a visa in the form of a comment in JIRA with the results of testing.
Feature Overview
Inspect Contribution - a list of all unclosed PRs with summary information for each: the last update date, PR number, title, author, and ticket in JIRA .
For each pull request, a tab with more detailed information is available: the correct name of the PR, without which the bot will not be able to find the right ticket in JIRA; whether tests were run; Is the test result ready? left a comment in JIRA.
Analysis of test results:
Here are two reports on testing the same PR. The first is from the bot. The second is a standard report on Teamcity. The difference in the amount of information is obvious, and this is without taking into account the fact that in order to view the history of test runs on TC, it will also be necessary to make several transitions to adjacent pages.
Let's return to the bot report. This report is visually divided into two tables: possible blockers and all drops. The blockers include tests that:
- less than 4% have a fail rate in the master (less than 4 launches out of 100 were unsuccessful);
- are not flaky by TeamCity classification;
- dropped due to timeout, lack of memory, exit code, JVM crash.
For example, in the screenshot above, two suites are listed as possible blockers - the first test crash occurred, and the second crash timed out.
To finally understand what is flaky dough, and what a bug, consider the picture above. The horizontal bar is 100 runs. Vertical green bar - successful passing the test, red - falling. In the case of a bug, the run history looks natural: the monotonous green bar at the end changes color to red. This means that exactly in this place a bug appeared and the test began to fall constantly. If we have a flaky test before us, then its history of runs is a continuous alternation of green and red colors.
Analysis of test results
For example, let's analyze the results of passing the tests in the screenshot above. According to the bot version, there may be two drops due to a bug - they are listed in the Possible Blockers table. But it may well be flaky tests with a low fail rate. To exclude this option, simply click the Re-run possible blockers button, and these two suites will go to a double-check. To further simplify the task, you can click Re-run possible blockers & comment JIRA, and get a comment (and with it a notification in the mail) from the bot after the end of the check. Then go in and see if there is a problem or not.
For reviewers, this is very cool. You can forget about edits that did not pass any checks, but simply click on a number of edits, press the big green Re-run button and wait for the letter.
Perfect report: no blockers found
Green visa (comment) bot. No blockers detected.
Red Visa - requires verification and / or editing of bugs
It happens that in the "master" still leak some bugs. As we have already said, we have previously struggled with this through personal notifications. Or some person made sure that nothing fell. Now we use a simpler solution:
When a new bug is detected, a message is sent to the dev-list, in which the contributors and their changes are indicated, which may be the cause of the error. So the whole community will know for whom everything happened.
Thus, we managed to increase the number of hotfixes and greatly reduce the time spent on fixing the problem.
Wizard status monitoring
One of the functions of the bot is to monitor the status of the wizard with the statistics on the latest launches.
Master trends
On the Master trends page, two “master” samples are compared for specific time intervals. For each item in the table displays the maximum, minimum value and median.
In addition to the general results for the entire sample, the table contains graphs for each indicator showing the values of each build. Clicking on a point, you can go to the results of the run on TeamCity. In addition, it is possible to remove the result from the statistics. This is useful when completely abnormal values occur, due to serious breakdowns, which are probably not the fault of the contributor. Such results should be excluded so that they are not taken into account when calculating the same flaky tests. In addition, the build can also be highlighted to follow the results for each indicator.
Over 65 people are currently registered with Apache Ignite Teamcity Bot. For all the time the bot was used, over 400 pull requests were received, and on average, five visas are issued per day.
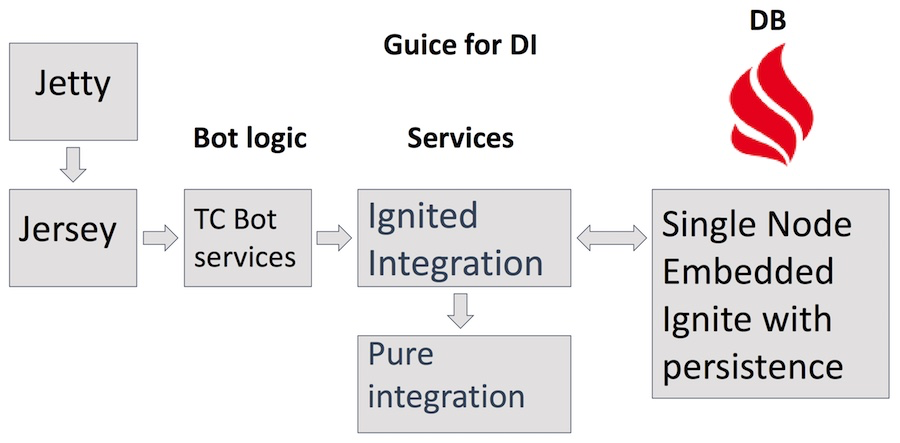
TeamCity Bot Structure
The bot is located on a separate server, goes to ignite.apache.org for data, publicly notifies everyone on the dev-list — this is our main platform for Ignite developers — and writes visas on tickets through the JIRA API.
Jetty server, Jersey servlets, a number of services with complex business logic of the bot itself, including Teamcity, JIRA and GitHub services that use the Ignited Integration service are used. Over this Pure Integration for http requests. As storage - Apache Ignite's own product in the Single Node embedded-mode configuration with active persistence. In addition to the obvious advantages of using Ignite as a database, it also helps us find various uses of Ignite and understand what is convenient and what is not.
The first bot implementation was inspired by one article on REST caching and was a REST cache and GitHub and Teamcity services. The xml and json returned from the Teamcity server were versed in Pure Java Objects, which were then cached. At first it worked, and quite quickly. But with the increase in the amount of data results began to deteriorate.
It is worth noting here that TeamCity deletes a story older than ~ 2 weeks, but a bot does not. In the end, with this approach, there were tons of data that are very difficult to manage.
TeamCity Bot Development
In the new approach, a variant of compact data storage is implemented and the choice is made in favor of a small number of cache partitions. A large number of partitions on one node adversely affects the speed of data synchronization to the disk and increases the start time of the cluster.
All major data updates are performed asynchronously, because otherwise we risk getting a bad UX due to the slow return of TeamCity data.
For strings that rarely change their values (for example, test names), a simple mapping into id generated by Atomic Sequence is made. Here is an example of such an Entry:
The long name of the test corresponds to an int-s number, which is stored in all builds. This saves a huge amount of resources. On top of the methods that return this line is the Guava in-memory cache interceptor. Thanks to the cache annotation, we don’t even select lines in heap by reading them from Ignite by id. And by id we always get the same string, which is good for performance.
For “unpredictable” lines, for example, stack trace log, different types of compression are used - gzip-compression, snappy-compression or uncompressed, depending on what is better. All these methods help to fit the maximum data into in-memory and quickly respond to the client.
Why is TeamCity Bot better
It’s not to say that TeamSity doesn’t have the capabilities listed above. They are, but scattered on a pile of different places. In the bot, everything is collected on one page and you can quickly understand what the problem is.
A nice addition is a letter that the bot sends to the dev-list when a problem is detected. Immediately in the community there is a reason to start a discussion: “Let's, maybe now we are going to reverse?”. This adds confidence to the reviewers.
With a bot, new contributors are much easier to integrate into the development process. Making your first fix, you don’t always know that the changes you make may result. And diving headlong into the analysis of the test results for TeamCity, you can easily lose the enthusiasm for further development. Apache Ignite TeamCity Bot will also help you quickly understand whether there is a problem and keep you enthusiastic.
We hope that the bot will simplify the lives of current contributors and will attract new people in the community. Finally, we advise, of course, not to allow the appearance of a huge number of flaky-tests, because it is difficult to fight them. And trust the robots - they have no preferences and they do not believe the word for people.
Source: https://habr.com/ru/post/436070/