Dungeon generator based on graph nodes
In this post, I will describe an algorithm for procedurally generating two-dimensional dungeon levels with a predetermined structure. The first part will provide a general description, and the second - the implementation of the algorithm.
Introduction
The algorithm was written as part of the work for a bachelor's degree and is based on the article by Ma et al (2014) . The aim of the work was to accelerate the algorithm and supplement it with new functions. I am quite pleased with the result, because we made the algorithm fast enough to use it during the execution of the game. After completing the bachelor's work, we decided to turn it into an article and send it to the Game-ON 2018 conference.
Algorithm
To create a game level, the algorithm receives as input a set of polygonal building blocks and a level connectivity graph (level topology). The nodes of the graph denote rooms, and the edges define the connections between them. The purpose of the algorithm is to assign each node of the graph the shape and location of the room so that no two room shapes intersect, and each pair of adjacent rooms can be connected with doors.

(a)

(b)

(with)

(d)
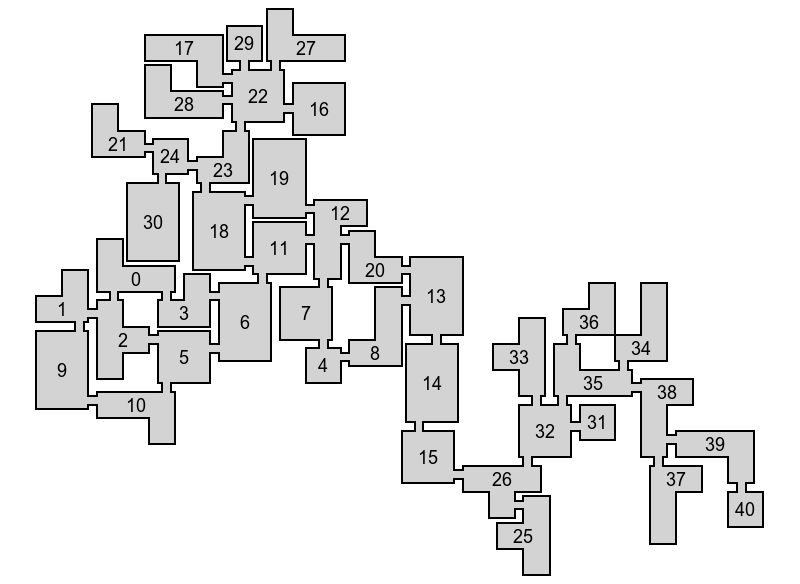
Figures (c) and (d) show diagrams generated from input graph (a) and building blocks (b).
Using the connectivity graph, the game designer can easily control the course of the gameplay. Do you need one common path to the boss room with several optional side paths? Just start with a path graph and then set up a few nodes in which the player can choose: either go along the main path, or explore the side, with possible treasures and / or monsters waiting for him. Need to cut a path? Simply select the two nodes in the graph and add the short road connecting them. The possibilities of this scheme are endless.



Examples of input graphs. The main path is shown in red, the auxiliary path is shown in blue, the short path is orange.
The algorithm not only allows game designers to manage the high-level structure of the maps generated, but also provides the ability to control the appearance of individual rooms and the ways they connect to each other.
Different forms for different rooms
I mentioned the boss room at the end of the level. We don't want the boss room to look like any other ordinary room, right? The algorithm allows you to specify forms for each room. For example, we can create a start level room and a boss room, which should have their own sets of room shapes, and one common set for all other rooms.


Two schemes generated from the input graph, in which with room number 8 is associated a special form of rooms.
Explicit door positions
Imagine that you have a quality boss meeting script, and that we need the player to enter the boss room from a certain tile. Or we may have a room pattern in which some tiles are reserved for walls and other obstacles. The algorithm allows designers to explicitly set possible door positions for individual room shapes.
But sometimes the goal may be the opposite. We can create room templates in such a way that the doors to them can be almost anywhere. Because of this, we impose fewer restrictions on the algorithm, so it is often executed faster, and the generated schemes may seem less monotonous and more organic. For such situations, it is possible to simply indicate the length of the doors and how far they should be from the corners. The distance from the corners is a kind of compromise between manual placement of all doors and the presence of doors in any place.

(a)

(b)
Figure (a) illustrates the different types of door placement — a square room has 8 clearly defined door positions, and a length and distance from corners are used in a rectangular room. Figure (b) shows a simple generated diagram with the shapes of the rooms in figure (a).
Corridors between rooms
When we talk about dungeon levels, we often present rooms connected by narrow corridors. I would like to assume that the connections in the input graph denote corridors, but they are not. They simply ensure that all neighboring nodes are directly connected by doors. If we want the rooms to be connected by corridors, then we need to insert a new node between all pairs of adjacent rooms and pretend that these are corridor rooms (with certain room shapes and given door positions).

(a)

(b)
Illustration of how we can change the input graph to add corridors between rooms. Figure (a) shows the input graph before adding corridor rooms. (B) shows the input graph created from (a) adding new rooms between all adjacent rooms of the original graph.
Unfortunately, this way we greatly complicate the task of the algorithm, because often the number of nodes doubles. Therefore, I implemented a version of the corridor-based algorithm, which reduces the decrease in performance when the corridor rooms are located. At the moment, the algorithm supports or corridors between all rooms, or the complete absence of corridors, but in the future I plan to make it more flexible.
Examples




Several circuits generated from different sets of building blocks and with included corridors.




Several circuits generated from different sets of building blocks with corridors on and off.
In the second part of the post I will talk about the internal workings of the algorithm.
I am also working on a Unity plugin for procedural dungeon generation, which will include this algorithm. I do this because despite the possibility of using this algorithm directly in Unity (it is written in C #), the convenience of working with it is far from ideal. It takes a lot of time to create room templates without a GUI, and a lot of code is needed to convert the output of the algorithm into the presentation used inside the game.
Since I myself am not a game developer, my goal is to make the plugin good enough for other people to use. If everything goes well, then I will try to publish updates when I have to tell about something interesting. I already have quite a few ideas about the generator itself and about testing its capabilities.




Unity plugin screenshots (project is under development)
Part 2. Implementation of the algorithm
In this part I will talk about the main ideas laid down in the foundation of the algorithm described in the first part of the post. Initially, I wanted to describe the basic concepts along with the main improvements required for the algorithm to be fast enough. However, as it turned out, even basic concepts are more than enough for this post. So I decided to reveal the performance improvements in a future article.
Motivation
Before proceeding with the implementation, I want to show the result of what we will do. The video shown below shows 30 different schemes generated from one input graph and one set of building blocks. The algorithm always stops for 500 ms after generating a circuit, and then tries to generate the next one.
How it works
The purpose of the algorithm is to assign the shape and position of the room to each node of the graph in such a way that no two rooms intersect and the adjacent rooms are connected by doors.
One way to achieve this is to try all possible combinations of room shapes and their positions. However, as you can guess, this will be very inefficient, and we probably will not be able to generate circuits, even based on very simple input graphs.
Instead of searching through all possible combinations, the algorithm calculates how all individual rooms can be correctly connected (the so-called configuration spaces) and uses this information to direct the search. Unfortunately, even with this information, it is still quite difficult to find the right scheme. Therefore, for effective study of the search space, we use a probabilistic optimization technique (in this case, annealing imitation). And to further accelerate the optimization, we divide the input task into smaller and easier to solve subtasks. This is done by dividing the graph into smaller parts (called chains), followed by the creation of diagrams for each of them in order.
Configuration spaces
For a pair of polygons in which one is fixed in place, and the other can move freely, the configuration space is the set of free polygon positions at which two polygons do not intersect and can be connected by doors. When working with polygons, each configuration space can be represented as a possible empty set of lines and calculated with the simplest geometric tools.

(a)

(b)
Space configurations. Figure (a) shows the configuration space (red lines) of a free rectangle relative to a fixed L-shaped polygon. It determines all the locations of the center of the square at which the two blocks do not intersect and touch each other. Figure (b) shows the intersection (yellow dots) of the configuration space of a moving square with respect to two fixed rectangles.
The following algorithm is used to calculate the configuration space of one fixed and one free block. We select the reference point on the movable block and consider all locations in , such that when the polygon is moved so that its reference point is located in this location, both the movable and the fixed block touch each other, but do not intersect. The set of all such points forms the space of configurations of two blocks (figure (a) above). To obtain the space of configurations of the movable block relative to two or more fixed blocks, the intersection of the individual spaces of the configurations is calculated (figure (b) above).
The algorithm uses configuration spaces in two ways. First, instead of trying random positions of individual rooms, we use configuration spaces to search for positions leading to as many adjacent doors as possible. To do this, we need to obtain the maximum non-empty intersection of the configuration spaces of our neighbors. Secondly, we use configuration spaces to check whether all pairs of adjacent rooms can be connected with doors. This is done by checking whether the position of the room is within the configuration space of all its neighbors.
Since the forms of rooms do not change during the execution of the game, we can precompute the configuration spaces of all pairs of room forms before the algorithm starts. Due to this, the entire algorithm is significantly accelerated.
Incremental pattern
When solving a complex problem, one of the possible approaches is to divide it into smaller and simple subtasks, and to solve them already. This is exactly what we will do with the task of locating individual rooms. Instead of arranging all the rooms at a time, we divide the input graph into smaller subgraphs and try one by one to create diagrams from them. The authors of the original algorithm call these subgraphs "chains" because of the very principle of these graphs, in which each node has no more than two neighbors, and therefore it is quite simple to create their scheme.
The final output scheme is always one connected component, so there is no point in connecting the individual components into the diagrams, and then trying to combine them, because the merging process can be quite complicated. Therefore, after placing the chain, the next chain to be connected will always be the one that is connected to the vertices already lined up in the scheme.
Layout GenerateLayout(inputGraph) { var emptyLayout = new Layout(); var stack = new Stack<Layout>(); stack.Push(emptyLayout); while(!stack.Empty()) { var layout = stack.Pop(); var nextChain = GetNextChain(layout, inputGraph); Layout[] partialLayouts = AddChain(layout, nextChain); if (!partialLayouts.Empty()) { if (IsFullLayout(partialLayouts[0])) { return partialLayouts[0]; } else { stack.Push(partialLayouts); } } } return null; } Pseudocode that demonstrates an incremental approach to finding the right scheme.
The pseudo-code shown above demonstrates the implementation of the incremental scheme. At each iteration of the algorithm (lines 6-18), we first take the last circuit from the stack (line 7) and calculate which chain to add next (line 8). This can be done by simply storing the last chain number added to each partial circuit. The next step is to add the following chain to the schema (line 9), generating several deployed diagrams, and save them. If the expansion stage ends in failure, but no new partial schemes are added to the stack, and the algorithm must be continued with the last saved partial scheme. We call this situation a return search, because the algorithm cannot expand the current partial scheme and must go back and continue with another saved scheme. This is usually necessary when there is not enough space to connect additional circuits to the vertices that are already mapped. Also, a return search is the reason that we are always trying to generate several advanced schemas (line 9). Otherwise, we would have nothing to return to. The process ends when we generate a complete circuit, or the stack is empty.

(a) Input Count

(b) Partial scheme

(c) Partial scheme

(d) Complete layout

(e) Complete scheme
Incremental scheme. Figures (b) and (c) show two partial diagrams after the layout of the first chain. (D) shows the complete circuit after expansion (b) with the second circuit. Figure (e) shows the complete circuit after expansion (c) with the second circuit.
To divide the graph into parts, you need to find a flat embedding of the input graph, that is, a drawing on a plane in which the edges intersect only at the end points. This embedding is then used to obtain all the faces of the graph. The basic idea of decomposition is that it is more difficult to create a circuit from cycles, because their nodes have more restrictions. Therefore, we are trying to arrange the cycles at the beginning of the decomposition so that they are processed as early as possible and reduce the likelihood of the need to go back to the subsequent stages. The first decomposition chain is formed by the smallest edge of the attachment, and the subsequent edges are then added in the search order in width (breadth-first search). If there are other faces that can be selected, then the smallest one is used. When no faces remain, the remaining non-cyclic components are added. Figure 4 shows an example of a decomposition in a chain, which is obtained in accordance with these steps.

(a)

(b)
Decomposition on the chain. Figure (b) shows an example of how figure (a) can be expanded on a chain. Each color denotes a separate chain. Numbers indicate the order in which the chains are created.

(c) Good partial layout


(a) Input Count

(b) Bad partial graph
Search with return. Figure (b) shows an example of a bad partial scheme, because it does not have enough space to connect nodes 0 and 9. To generate a complete scheme (d), a return to another partial scheme (c) is necessary.
Annealing imitation
The annealing simulation algorithm is a probabilistic optimization technique, the purpose of which is to study the space of possible schemes. She was chosen by the authors of the original article because she was useful in similar situations in the past. When implementing the algorithm, I decided to use the same method, because I wanted to start with what has already proven its effectiveness in solving this problem. However, I think that it can be replaced by another method and my library is written in such a way that the process of replacing a method is quite simple.
The annealing simulation algorithm iteratively evaluates small changes in the current configuration, or pattern. This means that we create a new configuration, randomly selecting one node and changing its position or shape. If the new configuration improves the energy function, it is always accepted. Otherwise, there is a small chance of making the configuration anyway. The likelihood of making the worst decisions decreases over time. The energy function is created in such a way that it imposes heavy penalties on intersecting nodes and non-interconnecting neighboring nodes.
A is the total area of intersection between all pairs of blocks in the circuit. D is the sum of the squares of the distances between the centers of pairs of blocks that are neighbors in the input graph but are not related to each other. Value affects the likelihood that the simulated annealing will be allowed to go to the worst configuration; This parameter is calculated from the average area of the building blocks.
After selecting a node to change, we change either its shape or position. How do we choose a new position? You can choose it randomly, but this will often degrade the energy function, and the algorithm will converge very slowly. Can we choose a position that is likely to increase the energy function? Do you understand what I am doing? We use configuration spaces to select a position that satisfies the constraints of the largest number of adjacent rooms.
Then, to change the shape, simply select one of the available room shapes. While the algorithm is not trying to decide which form is most likely to lead us to the correct scheme. Nevertheless, it would be interesting to try this opportunity and see if it accelerates the work of the algorithm.
List<Layout> AddChain(chain, layout) { var currentLayout = GetInitialLayout(layout, chain); var generatedLayouts = new List<Layout>(); for (int i = 1; i <= n, i++) { if (/* мы уже сгенерировали достаточное количество схем */) { break; } for (int j = 1; j <= m, j++) { var newLayout = PerturbLayout(currentLayout, chain); if (IsValid(newLayout)) { if (DifferentEnough(newLayout, generatedLayouts)) { generatedLayouts.Add(newLayout); } } if (/* newLayout лучше, чем currentLayout */) { currentLayout = newLayout; } else if (/* вероятность, зависящая от того, насколько плоха энергия newLayout */) { currentLayout = newLayout; } } /* уменьшаем вероятность принятия худших схем */ } return generatedLayouts; } This is the pseudo-code of the method responsible for creating the circuit of a separate circuit using simulated annealing.
To speed up the whole process, we will try to find the initial configuration with low energy. To do this, we will order the nodes in the current chain in search in width, starting with those that are adjacent to the nodes already included in the scheme. Then the ordered nodes are placed one by one and the lowest energy position is selected from the configuration space for them. Here we do not do any return back - this is a simple greedy process.
Bonus Video
The video shown below shows the schemas generated from the same input graph as in the first video. However, this time an incremental approach is shown. You may notice that the algorithm adds a chain of nodes one by one. It also shows that sometimes there are two consecutive partial circuits with the same number of nodes. This happens when the algorithm returns. If the first attempts to add another circuit to the first partial circuit fail, then the algorithm tries another partial circuit.
Downloadable materials
Algorithm implementation on .NET can be found in my github . The repository contains the .NET DLL and the WinForms GUI application, managed by the YAML configuration files.
Source: https://habr.com/ru/post/436198/