Extreme Scaling in Alibaba JDK
Many are suspicious of the prospect of something to fork and finish on their own. Often the price is too high. Especially strange to hear about their own JDK, which allegedly is in each fairly large company. What the hell, with fat rage? In this article there will be a detailed story about the company, to which all this brings real commercial benefits, and which has done a monstrous job, because they:
- Developed a multi-tenant Java virtual machine;
- Invented the mechanism of operation of objects that do not bring an overhead projector for garbage collection;
- Made something like an analogue of ReadyNow from Azul Zing;
- We wrote down our own korutin with yield and continuations (and are even willing to share the experience with Loom, which I wrote about in the fall );
- Screwed to all these wonders own diagnostic subsystem.
As always, the video, full text transcript and slides are waiting for you under the cut. Welcome to the hell of one of the most difficult ways to adapt open source projects!

Doctor, where do you get these pictures from? The O'Reilly Covers Corner: The KDPV background is provided by Joshua Newton and depicts the sacred dance Sangyang Jaran in Ubud, Indonesia. This is a classic Balinese performance consisting of fire and trance dance. A man with uncovered heels moves around a bonfire, bred on coconut husks, shoving his legs different and dancing in a trance state under the influence of horse spirit. The perfect illustration for your own JDK, right?
Slides and description of the report (you do not need them, in this habratopeke there is everything you need).
Hello, my name is Sanhong Lee, I work at Alibaba, and I would like to tell you about the changes we made to OpenJDK for the needs of our business. The post consists of three parts. In the first one, I’ll talk about how Alibaba uses Java. The second part, in my opinion, is the most important - in it we will discuss how we customize OpenJDK for the needs of our business. The third part will be about the tools that we created for the diagnosis.
But before moving on to the first part, I would like to briefly tell you about our company.
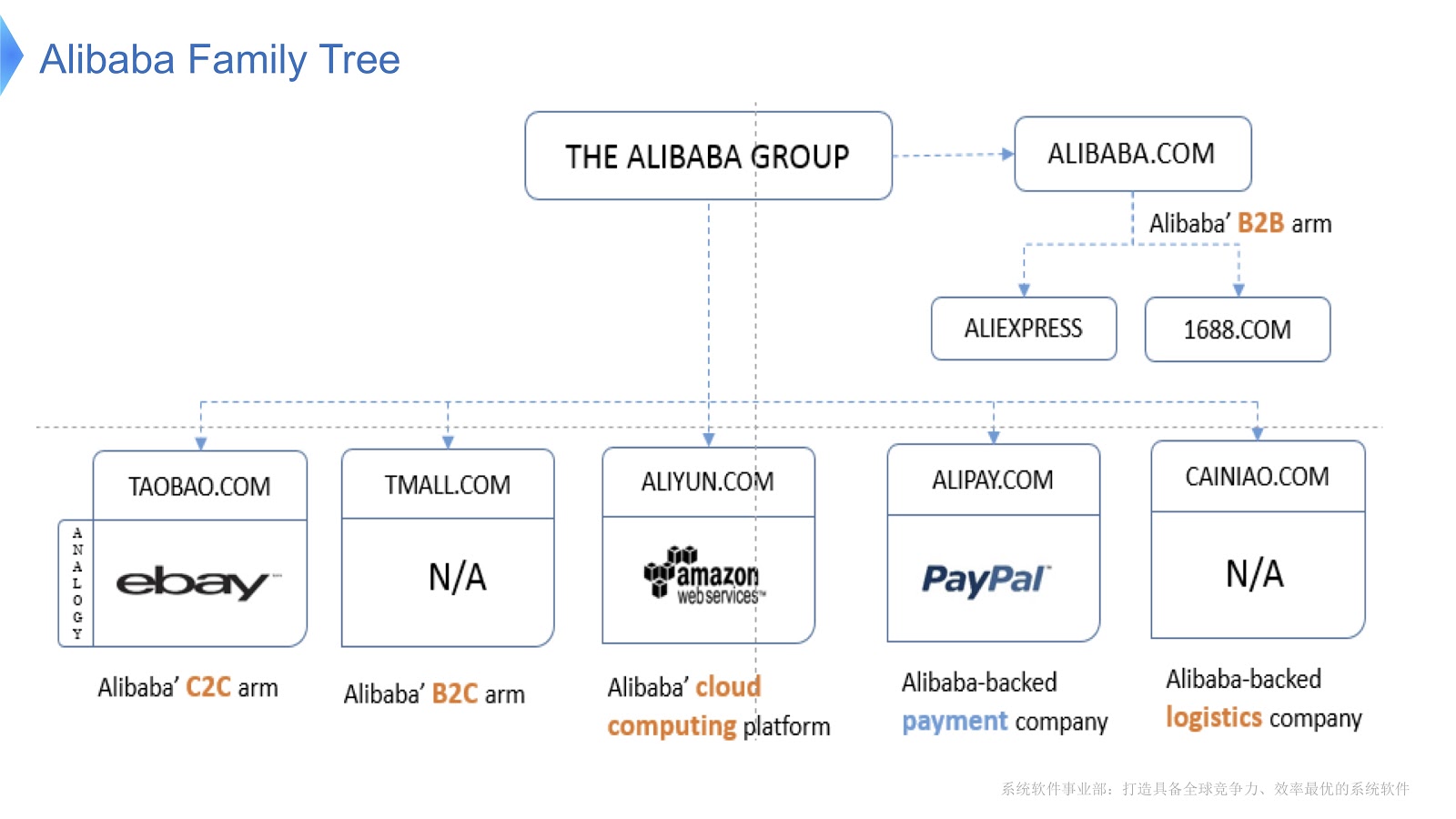
The diagram shows the internal structure of Alibaba. It consists of various companies whose main specialization is the organization of the electronic market and the provision of financial and logistics platforms. I think in Russia most are familiar with AliExpress. Alibaba has a dedicated team of programmers who develop and support the entire distributed stack, which provides customer service for Aliexpress around the world.
To get an idea of the scale of the work of Alibaba, let's see what happens in China on Bachelor’s Day . It is celebrated every year on November 11th, and on this day, people buy especially a lot of goods through Alibaba. As far as I know, from holidays all over the world, this is where the most purchases occur.
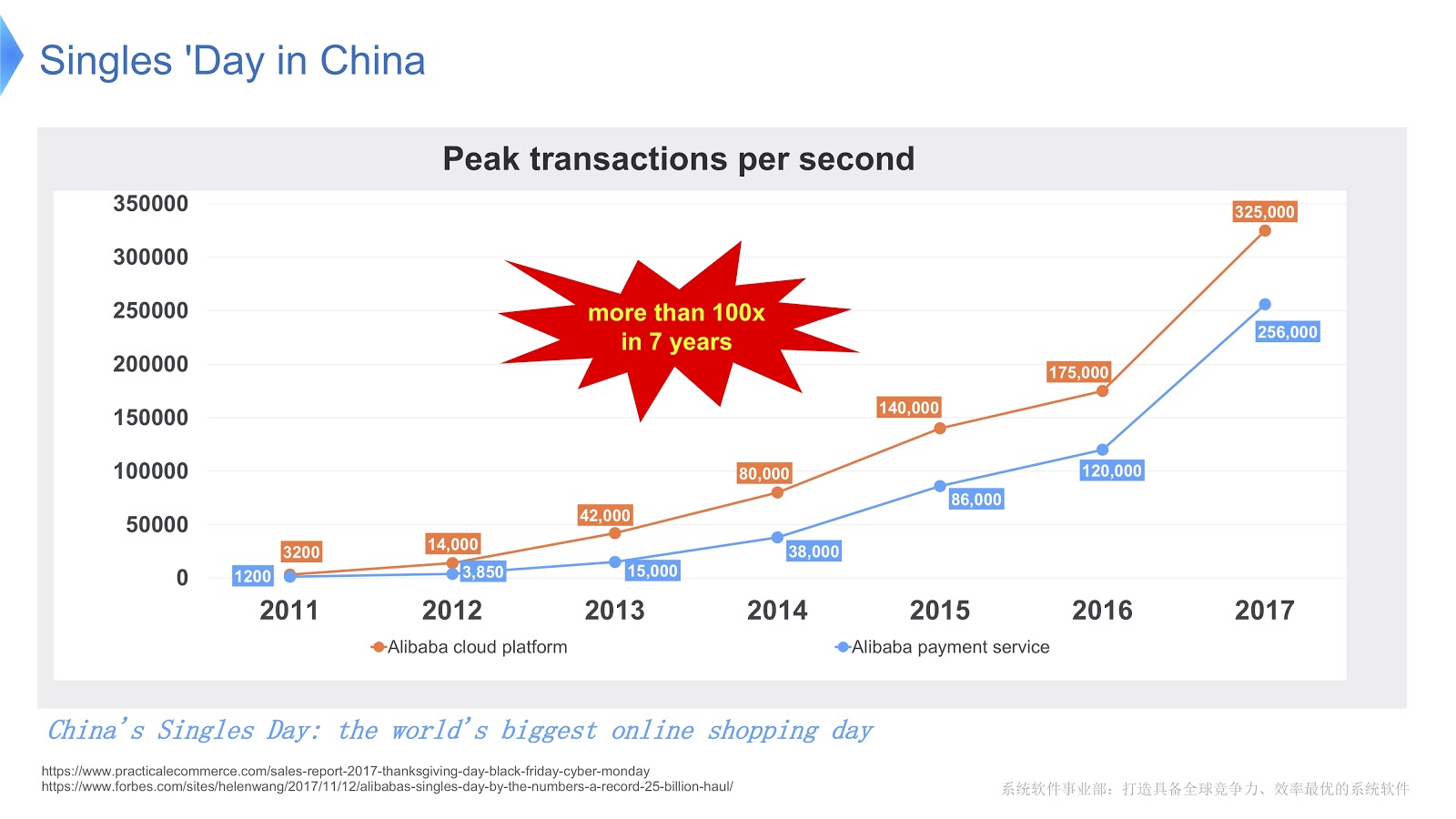
In the picture above you see a diagram that shows the load on our support system. The red line shows the work of our service orders and shows the peak number of transactions per second, last year it was 325 thousand. The blue line refers to the payment service, and this figure is 256 thousand. I would like to talk about how to optimize the stack serving so many transactions.
Let's discuss the main technologies that work in Alibaba with Java. First of all, it must be said that a number of open-source applications are our basis. For big data processing we use HBase Hadoop. We use Tomcat and OSGi as a container. Java is used on a colossal scale - millions of JVM instances are deployed in our data center. It should also be said that our architecture is service-oriented, that is, we create a multitude of services that communicate with each other using RPC calls. Finally, our architecture is heterogeneous. To improve performance, many algorithms are written using C and C ++ libraries, so they communicate with Java using JNI calls.

The history of our work with OpenJDK began in 2011, during OpenJDK 6. There are three important reasons why we chose OpenJDK. First, we can directly modify its code in accordance with the needs of the business. Secondly, when urgent problems arise, we can resolve them on our own faster than waiting for an official release. For our business, it is vital. Third, our Java developers use our own tools for quick and high-quality debugging and diagnostics.
Before turning to technical issues, I would like to list the main difficulties that we have to overcome. First, we have launched a huge number of copies of the JVM - in this situation there is an urgent need to reduce the costs associated with the hardware. Secondly, I have already said that we serve a huge number of transactions. Thanks to the garbage collector, Java promises us "infinite memory." In addition, it gains performance at a low level thanks to the JIT compiler. But this has a downside: a longer stop-the-world time when collecting garbage. In addition, Java needs additional CPU cycles to compile Java methods. This means that compilers compete for CPU cycles. Both problems are exacerbated as the application becomes more complex.
The third difficulty is connected with the fact that we have a lot of applications running. I think everyone here is familiar with the tools that come with OpenJDK, such as JConsole or VisualVM. The problem is that they do not give us the exact information we need to configure. In addition, when we use these tools (for example, JConsole or VisualVM) in production, a low overhead projector is not just a wish, but a necessary requirement. I had to write my own diagnostic tools.

The picture presents in general terms the changes we made to OpenJDK. Let's take a look at how we overcame the difficulties that I mentioned above.
JVM Multi-Tenant
One solution we call the multi-tenant JVM. It allows you to safely run multiple web applications in a single container. Another solution is called GCIH (GC Invisible Heap). This is the mechanism that provides you with full-fledged Java objects that do not require the cost of garbage collection. Further, in order to reduce the costs of thread contexts, we implemented coroutines on our Java platform. In addition, we wrote a mechanism called JWarmup - its function is very similar to ReadyNow. Douglas Hawkins seems to have mentioned it in his report . Finally, we developed our own profiling tool, ZProfiler.
Let's take a closer look at how we implement OpenJDK based multi-tenancy.
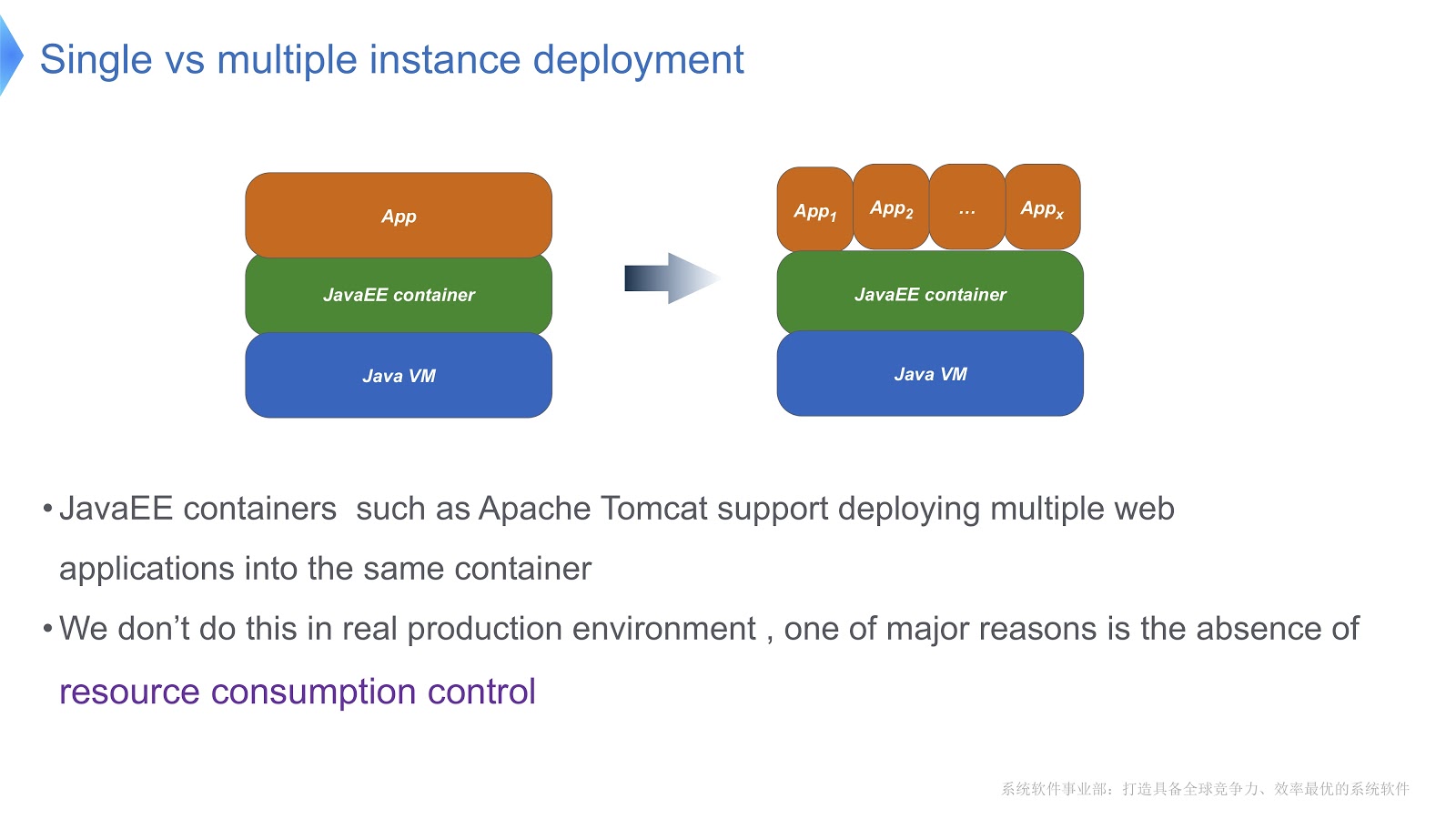
Take a look at the picture above - I think most of you are familiar with this scheme. Compare the traditional approach with multi-tenant. If your application is running using Apache Tomcat, you can also run multiple instances in the same container. But Tomcat does not provide a stable resource consumption for each of them. Say, if one of the running applications needs more CPU time than others, how will you control the CPU time allocation? How to ensure that this application does not affect the work of others? Mainly this question made us turn to multi-tenant technology.
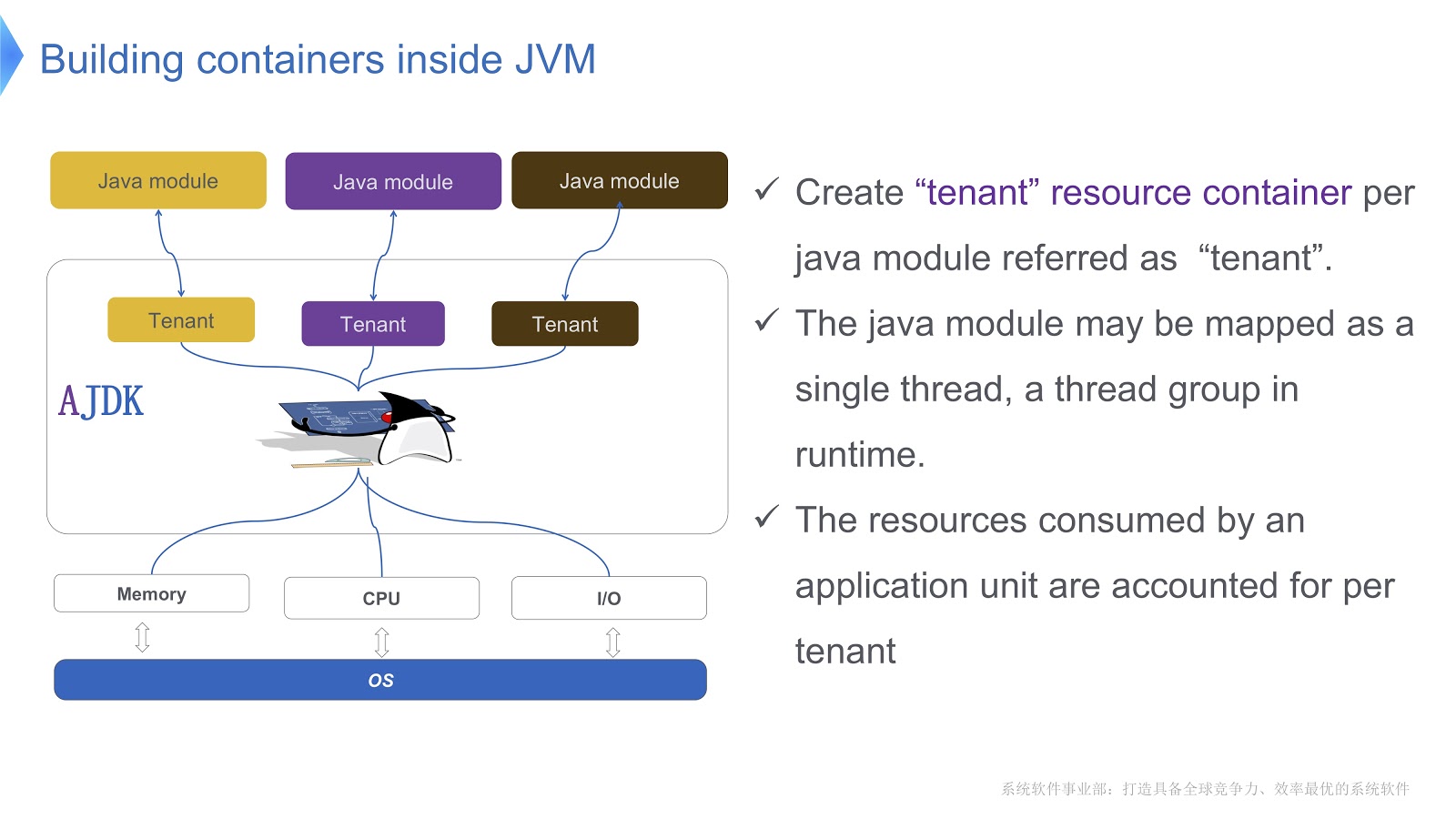
The picture is a schematic representation of how we implement it. We create several containers for tenants inside the JVM. Each of these containers provides reliable control of resource consumption for each Java module. Multiple modules can be deployed in one container. Each module can be associated with one thread or a group of threads in runtime.
Let's take a look at how the tenant container API looks like. We have a tenant configuration class that stores information on resource consumption. Next, there is the class of the container itself.
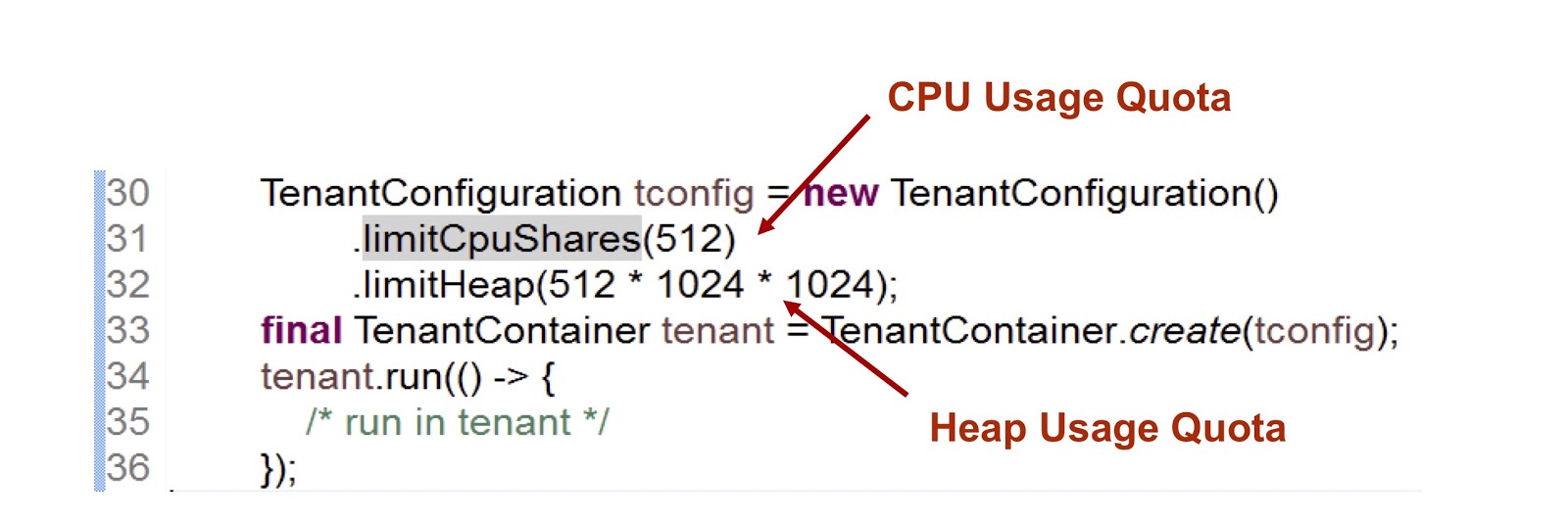
In the presented code snippet, we create one tenant, and then we indicate how long the CPU and memory are given to it. The first indicator is an integer number, which means the share of CPU time available to the tenant, in this case we indicated 512. We use a very similar approach in the case of cgroups, I’ll stay at this point in more detail. The second indicator is the maximum heap size that the tenant can use.
Consider how the tenant interacts with the thread. The TenantContainer class provides the .run() method, and when the thread enters it, it is automatically attached to the tenant, and when it leaves, the reverse procedure occurs. So all the code is executed inside the .run() method. In addition, any thread created inside the .run() method is attached to the tenant of the parent thread.
We come to a very important question - how is the management of the CPU in a multi-tenant JVM? Our solution has just been implemented on a Linux x64 platform. There exists a mechanism of control groups, cgroups. It allows you to separate the process into a separate group, and then specify your own mode of resource consumption for each group. Let's try to move this approach into the context of the Hotspot JVM. In Hotstpot, Java threads are organized as native threads.

This is shown in the diagram above: each Java thread is in one-to-one correspondence with a native thread. In our example, we have a container TenantA , in which there are two native threads. To be able to control the CPU time distribution, we put both native threads in the same control group. Thanks to this, we can regulate resource consumption by relying solely on the functionality of [control groups] ( https://en.wikipedia.org/wiki/Cgroups ).
Let's take a look at a more detailed example.
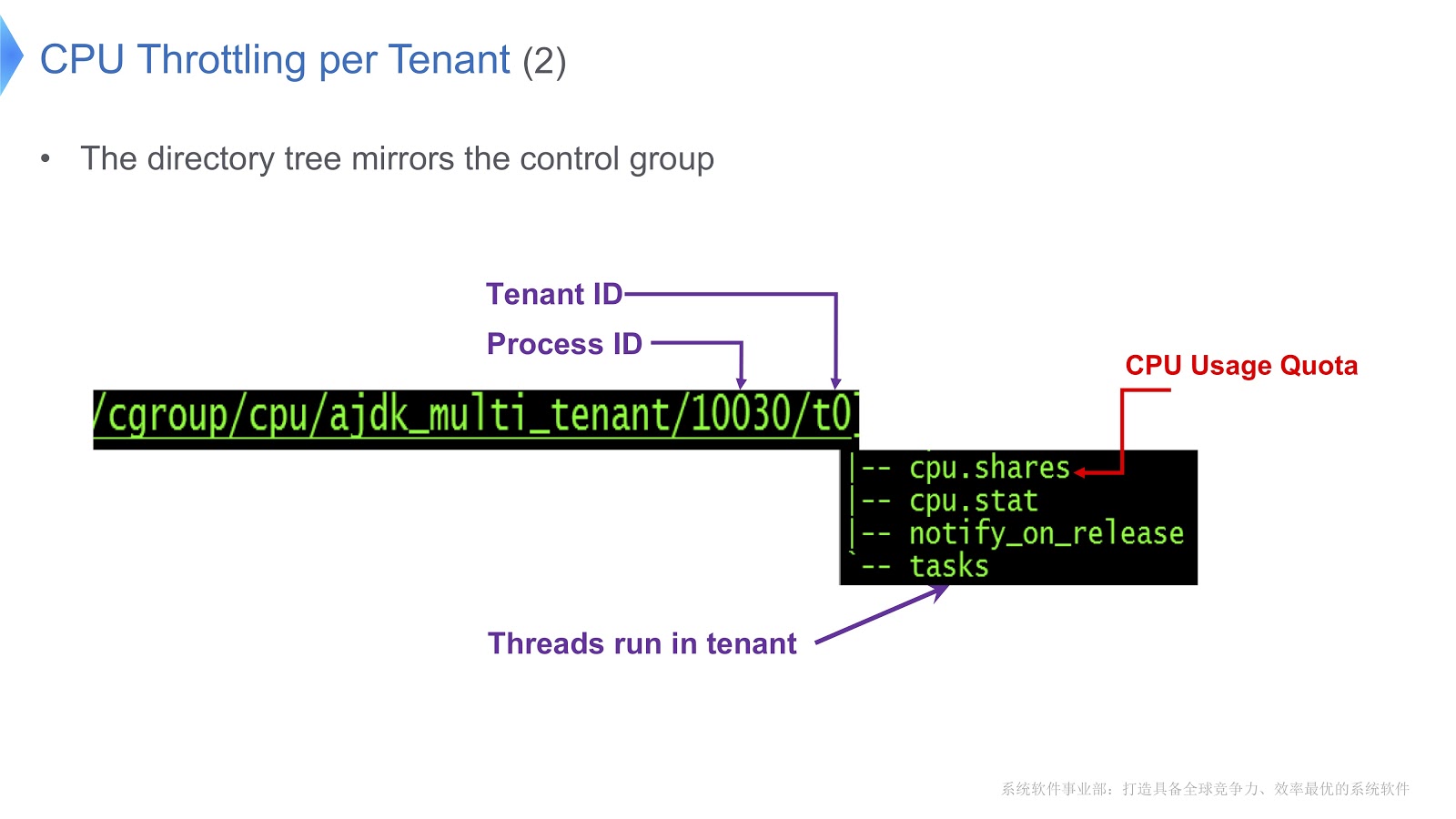
Control groups in Linux are mapped to a directory. In our example, we created the /t0 directory for tenant 0. In this directory is the /t0/tasks directory, all threads for t0 will be located here. Another important file is /t0/cpu.shares . It indicates how long the CPU will be allocated to this tenant. This whole structure is inherited from the control groups — we simply provided a direct correspondence between the Java thread, the native thread, and the control group.
Another important question relates to managing a bunch of each tenant.
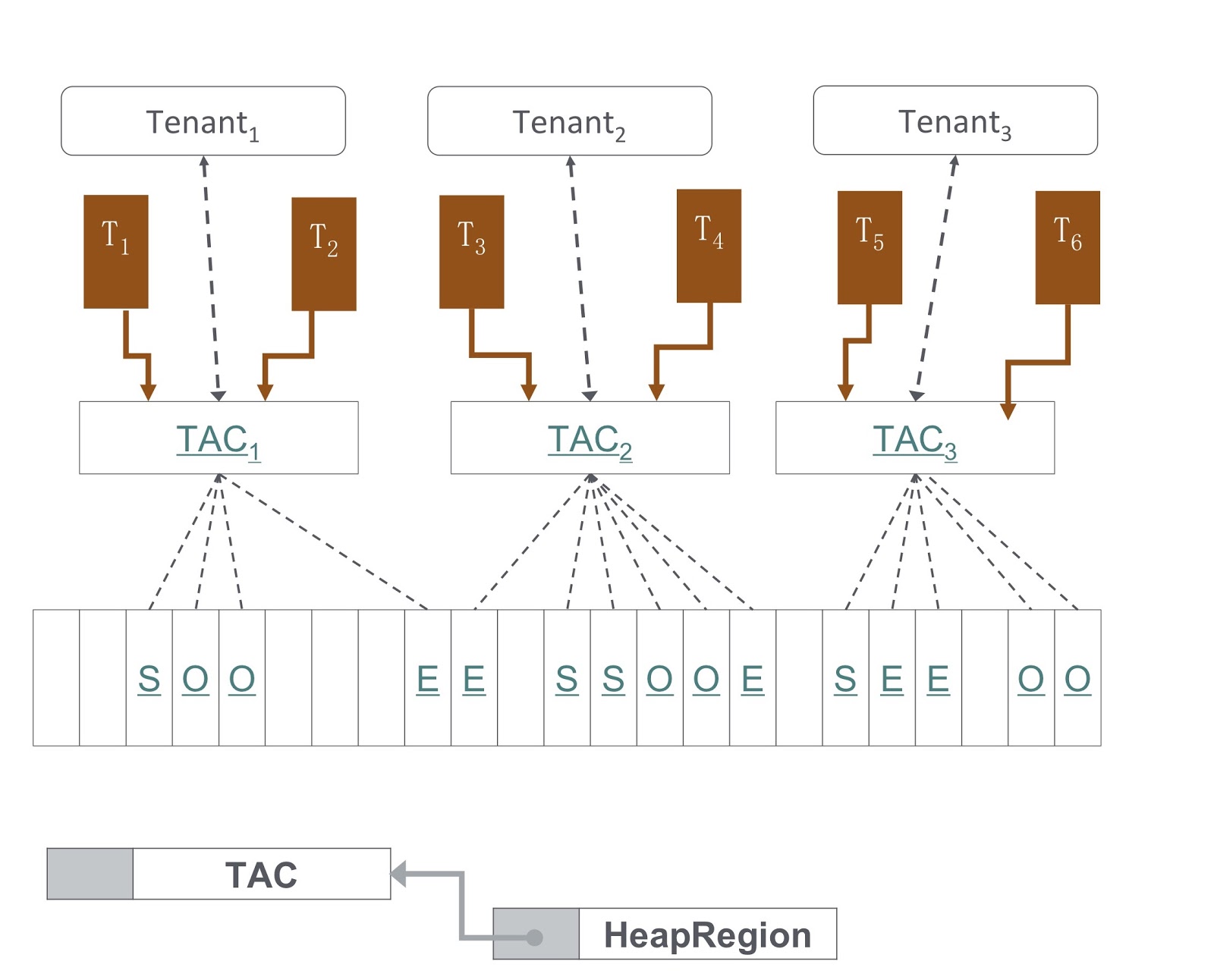
In the picture you can see the scheme of how it is implemented. Our approach is based on G1GC. At the bottom of the picture, it is shown that G1GC divides the heap into sections of equal size. Based on these, we create Tenant Allocation Contexts, TAC-and, with which the tenant manages his heap site. Through TAC, we limit the size of the heap area available to the tenant. Here, the principle that every section of the heap contains objects of only one tenant is in effect. To implement it, we needed to make changes to the process of copying an object during garbage collection — it was necessary to ensure that the object was copied to the correct part of the heap.
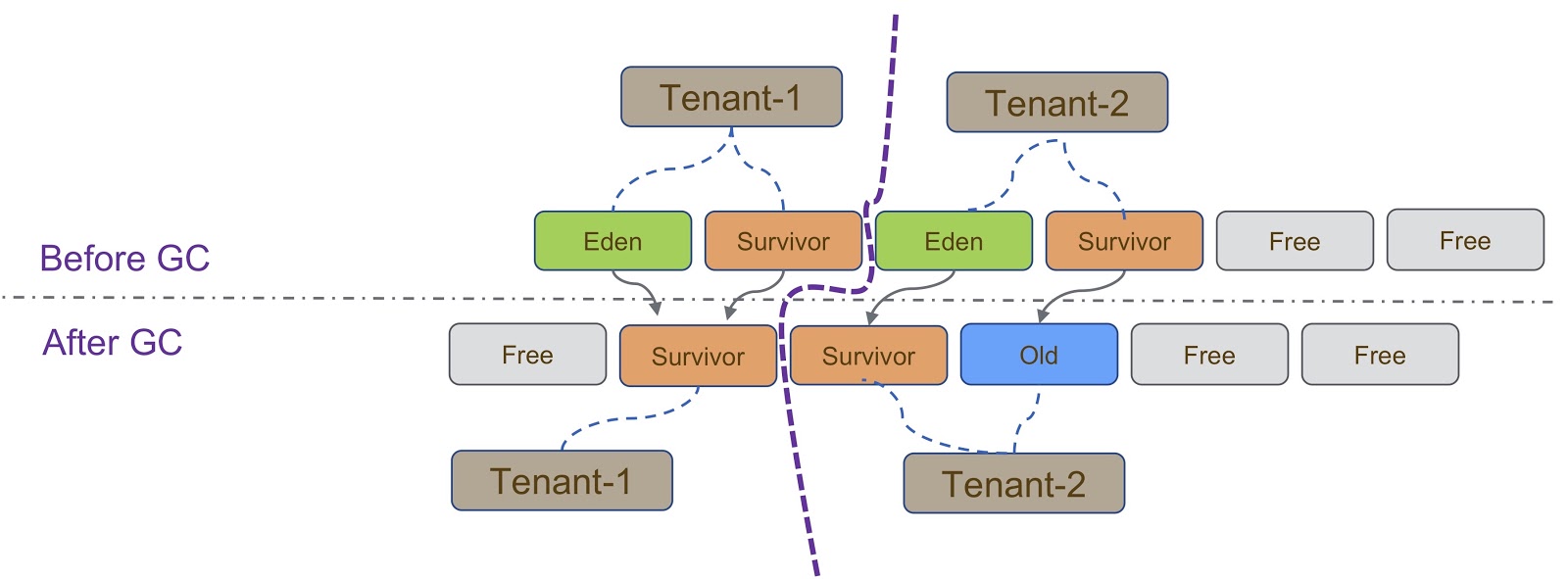
Schematically, this process is depicted in the diagram above. As I said, our implementation is based on G1GC. G1GC is a copying garbage collector, so during garbage collection we need to make sure that the object is copied to the correct part of the heap. On the slide, all objects created by Tenant-1 should be copied to its heap portion, similarly to Tenant-2 .
There are other considerations that arise when isolating tenants from each other. Here you need to say about TLAB (Thread Local Allocation Buffer) - this is a quick memory allocation mechanism. The TLAB space depends on the part of the heap. As I already said, different tenants have different groups of heap areas.

The specifics of working with TLAB is shown on the slide - when the thread switches from Tenant 1 to Tenant 2 , we need to make sure that the correct heap area is used for the TLAB space. This can be achieved in two ways. The first way is when Thread A switches from Tenant 1 to Tenant 2 , we just get rid of the old one, and create a new one in Tenant 2 . This method is relatively easy to implement, but it wastes space in the TLAB, which is undesirable. The second way is more difficult - to make TLAB aware of tenants. This means that we will have several TLAB buffers for one thread. When Thread A switches from Tenant 1 to Tenant 2 , we need to change the buffer and use the one that was created in Tenant 2 .
Another mechanism that needs to be mentioned in connection with the delimitation of tenants is the IHOP (Initiating Thread Occupancy Percent). Initially, the IHOP was calculated based on the entire heap, but in the case of a multi-tenant mechanism, it should be calculated on the basis of only one segment of the heap.
Let's take a closer look at what GCIH (GC Invisible Heap) is. This mechanism creates a plot in the heap, hidden from the garbage collector, and, accordingly, not affected by the garbage collection. This plot is managed by a GCIH tenant.

Here it is important to say that we provide a public API to our Java developers. An example of working with him can be seen on the screen. It allows using the moveIn() method to move objects from the regular heap to the heap portion of the GCIH. Its advantage is that you can still interact with these objects, as with ordinary Java objects, they are very similar in structure. But at the same time they do not require the cost of garbage collection. The conclusion, in my opinion, is that if you want to speed up garbage collection, you need to customize the behavior of the garbage collector according to the needs of your application.
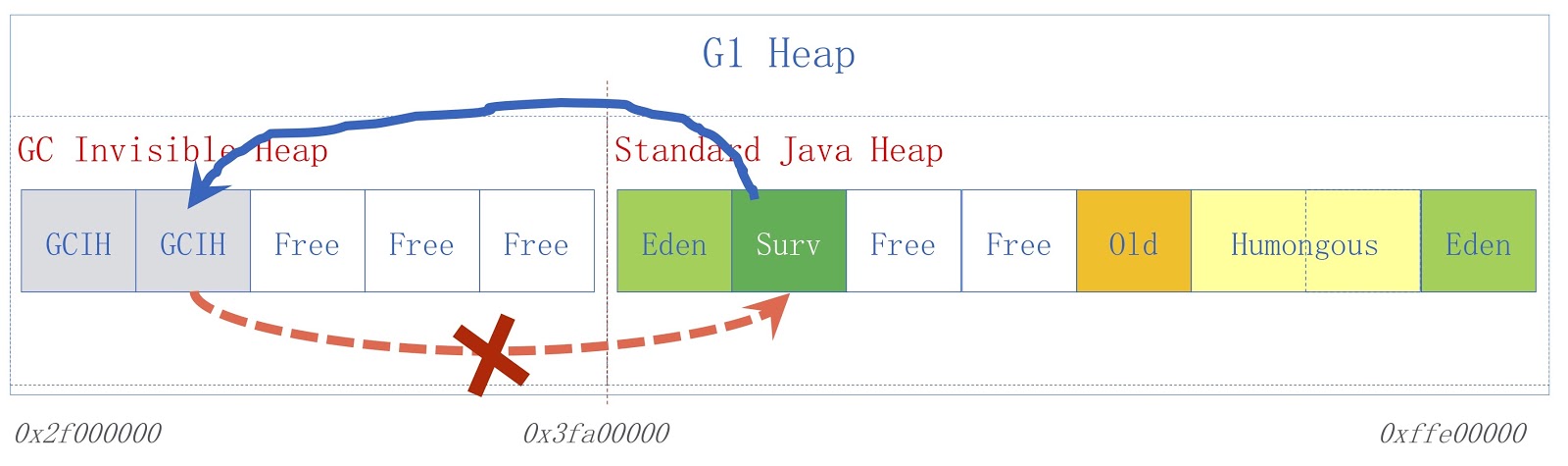
The picture shows the high-level GCIH scheme. On the right is the usual Java heap, on the left is the space allocated for GCIH. Links from a regular heap to objects in GCIH are valid, but links from GCIH to a regular heap are not. To understand why this is so, consider an example. We have object “A” in GCIH, which contains a reference to object “B” in the regular heap. The problem is that object “B” can be moved by the garbage collector. As I said, we do not make updates in GCIH, so after the garbage collector has been running, object “A” may contain an invalid reference to object “B”. This problem can be solved with the help of the pre-write barrier - they were discussed in the previous report. As an example, suppose that someone needs to save a link from a regular Java heap to GCIH before the save we assumed, this will lead to the appearance of a predictor exception with an indicator flag that the rule was violated.
As for the specific application, the multi-tenant JVM is used in our Taobao Personalization Platform, abbreviated TPP. This is a recommendation system for our e-shopping application. TPP can deploy several microservices in one container, and with the help of a multi-tenant JVM, we adjust the memory and CPU time provided to each microservice.
As for GCIH, it is used in our other system, the UM Platform. This is an online discount application. The owner of this application uses GCIH to pre-cache GCIH data on the local machine so as not to access objects from a remote cache server or remote database. As a result, we lighten the load on the network and perform less serialization and deserialization.
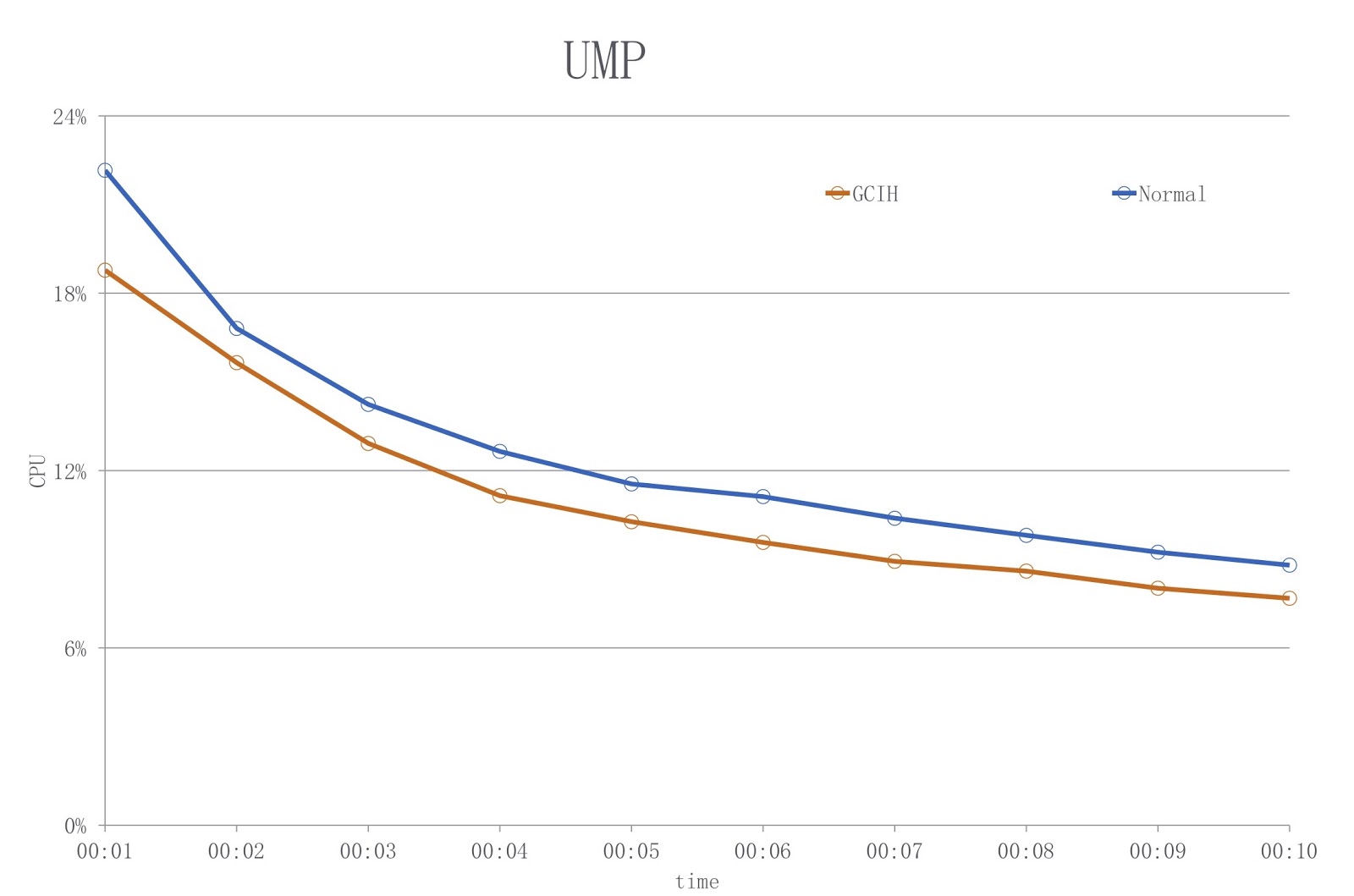
The picture shows a diagram in which the blue color shows the load when using the usual JDK, and the red color shows GCIH. As you can see, we reduce the CPU usage by over 18%.
As far as I know, BellSoft solved a similar problem, and their solution was similar to GCIH, but they used a different approach to reduce serialization and deserialization costs.
Jokes in java
Let's now go back to Alibaba and see how you can implement Korutinas in Java. But first, let's talk about the origins, why in general this needs to be addressed. In Java, it was always very easy to write applications with multithreading. But the problem with creating such applications is that, as I said, in the Hotspot Java threads are already implemented as native threads. Therefore, when there are many threads in your application, the costs of changing the context of a thread become very high.

Consider an example in which we will have 4 I / O threads and 200 threads with the logic of your application. The table on the screen shows the results of launching this simple demo - you can see how much time the CPU takes to change contexts. The solution for this problem can be the implementation of Corutin in Java.
To provide it, we needed two things. First, Alibaba JDK needed to add support for sequels. This work was based on the JKU patch, we will dwell on it in more detail. Secondly, we added a user-mode sheduler, which will be responsible for the continuation in the thread. Thirdly, Alibaba has a lot of applications. Therefore, our solution is very important for our Java developers, and it was necessary to make it absolutely transparent for them. And this means that in our business application there should be practically no changes in the code. We called our solution Wisp. Our coroutine implementation in Java is widely used in Alibaba, so it can be considered proven that it works in Java. Get to know him more.

Let's start with an example, the code of which is presented above - this is quite a normal Java-application. First, a thread pool is created. Then another runnable task is created that accepts a socket. After that, read from the stream. Next, we create another Runnable task, with which we connect to the server and, finally, write data to the stream. As you can see, everything looks quite standard. If you run the code on a regular JDK, each of these Runnable tasks will be executed in a separate thread. But in our decision the mechanics will be completely different.
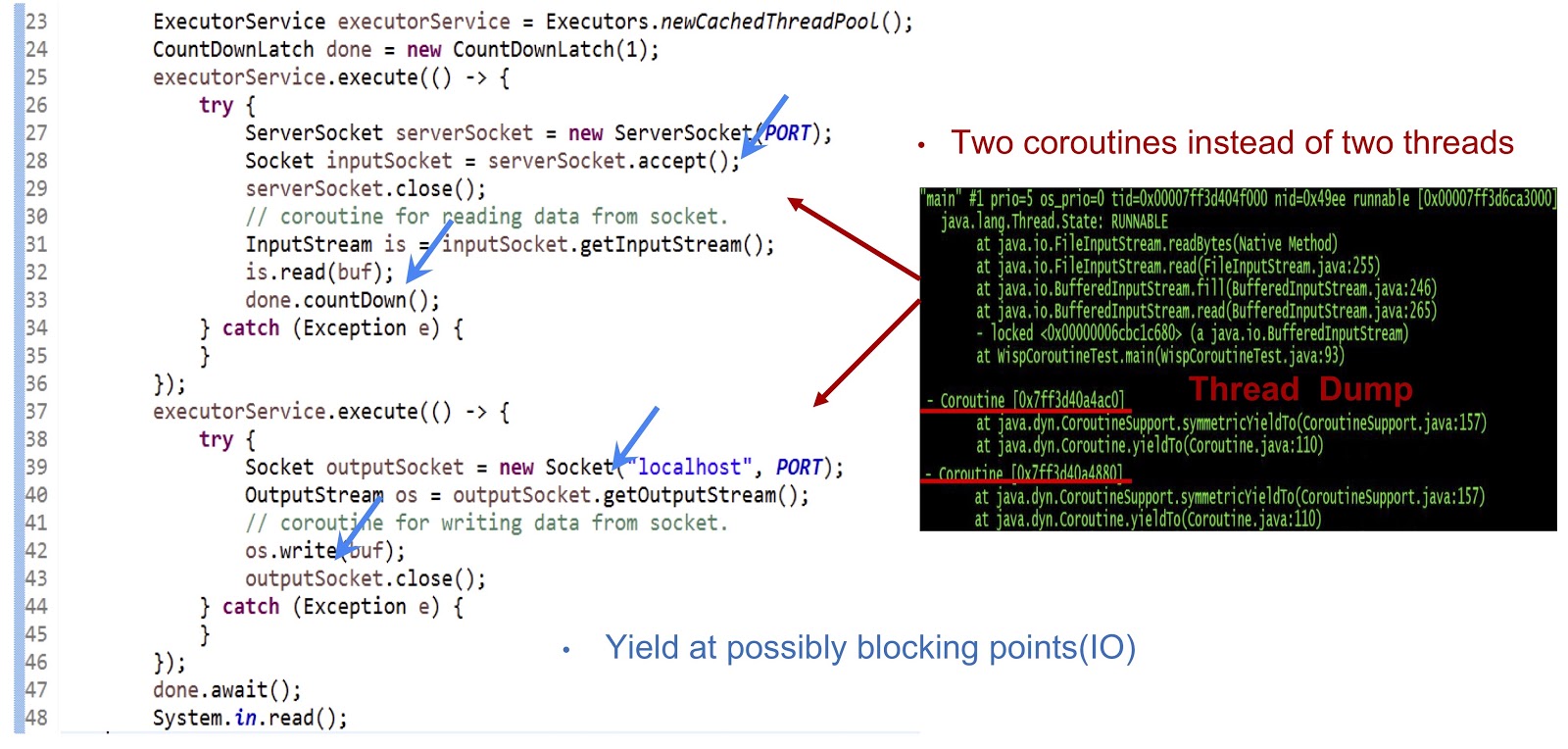
As can be seen from the dump thread presented on the slide, we create two coroutines in one thread, not two threads. Now it is necessary to ensure that this solution works. The main thing here is to generate generation of yieldTo events at all possible points of blocking. In our example, these dots will be serverSocket.accept() , is.read(buf) , socket connection, and os.write(buf) . Thanks to the yield events at these points, we can transfer control from one cortina to another within the same thread. To summarize, our approach is that we achieve asynchronous performance using Coroutine, but our programmers can write code in a synchronous style, since such code is much simpler and easier to maintain and debug.
Let's take a look at how exactly we provided support for the sequels in Alibaba JDK. As I said, this work is based on a multi-lingual virtual machine project created by the community - it is in the public domain. We used this patch in Alibaba JDK and fixed some bugs that occurred in our production environment.
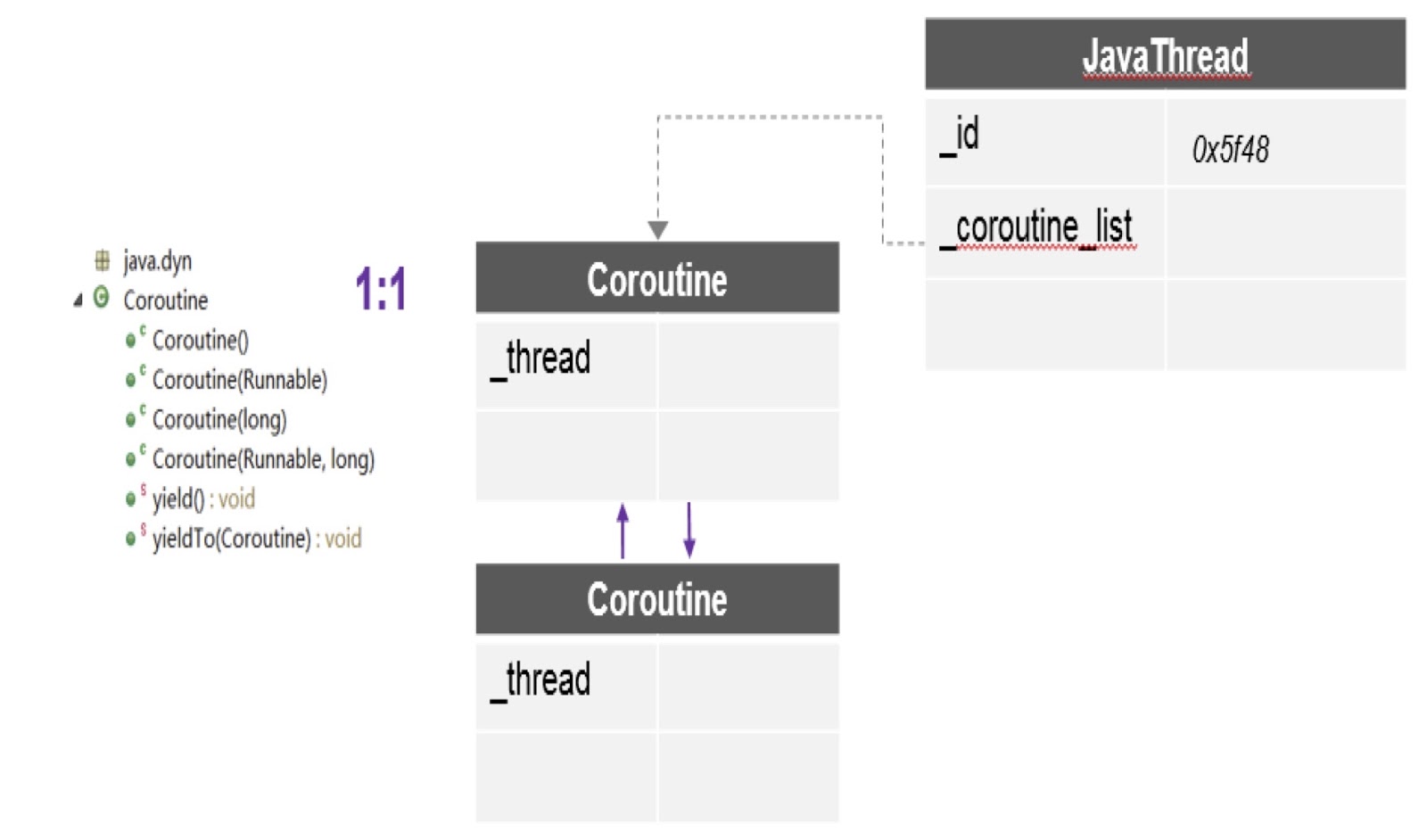
As can be seen in the diagram, here in one thread there can be several coroutines, and for each a separate stack is created. In addition, the patch about which I spoke provides us with the most important API here, yieldTo, with the help of which the transfer of control from one coroutine to another occurs.
Let us turn to how we have implemented a user-mode sheduler for corutin. We use a selector, and with the help of it we register several channels. When an I / O event occurs (socket read, socket write, socket connect, or socket accept), it is recorded as a key for the selector. Therefore, when this event ends, we receive an alert from the selector. Thus, we use a selector to schedule coroutines in case of an I / O lock. Consider an example of how this will work.
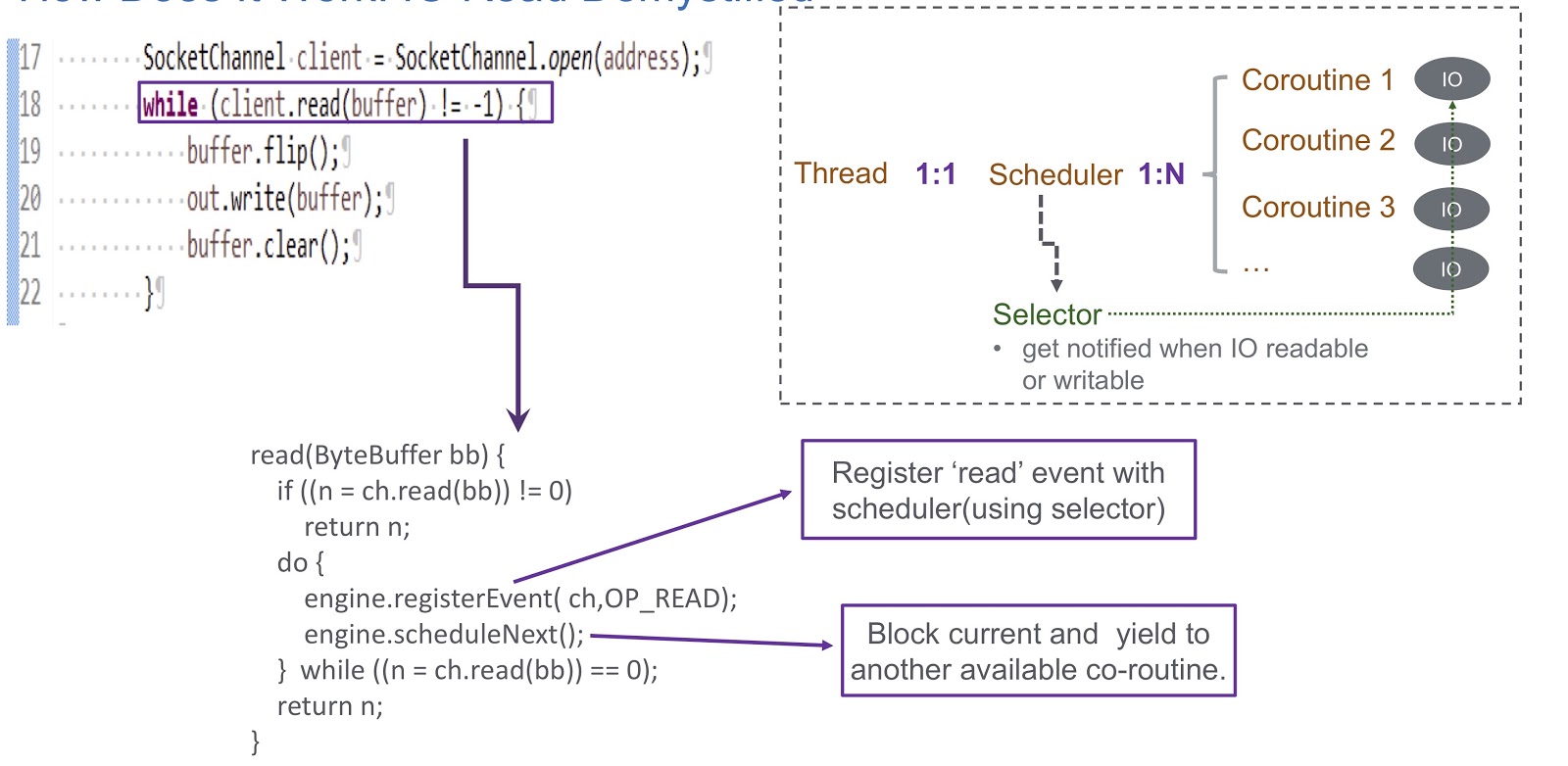
In the picture we see the socket and the synchronous call client.read(buffer) . At the bottom of the slide is written the code that will be executed inside this call. First, it checks whether it is possible to read from the channel or not. If yes, then we return the result. The most interesting thing happens if reading cannot be done. Then we register the read event in our scheduler with selector. This makes it possible to schedule the execution of some other coroutine. Take a look at how this happens. We have a thread in which to create a scheduler. The thread and our korutina are in one-to-one correspondence with each other. Sheduler allows us to manage the korutinami this thread. What happens if I / O is blocked? When an I / O event occurs, the scheduler receives an alert, and in this situation it relies entirely on the selector. After such an event, the sheduler gets the opportunity to schedule the next available quortin.
Let's summarize the review of the work of our sheduler, which we called WispEngine. For each of our threads we allocate a separate WispEngine. When a coroutine lock occurs, we register certain events (socket read / write and so on) with WispEngine. Some events are related to the parking thread, for example, if you call thread.sleep() with a delay of 100 milliseconds. In this case, you will generate a thread parking event, which will then be registered in the selector. Another important question is when the sheduler assigns the execution of the next available cortina. There are two main conditions. The first is when certain events are generated, such as I / O events or timeout events. Everything is quite simple here: suppose you make a thread.sleep() call with a delay of 200 milliseconds. When they expire, the sheduler has the ability to perform the next available quortin. Or here we can talk about some unpacking events that are generated, say, by calling object.notify() or object.notifyAll() The second condition is when the user submits new requests and we create a quortenine to serve these requests, and then the sheduler assigns its implementation.
Here you also need to say about the service we created, WispThreadExecutor.

The screen shows an example of code, and we see that this is the usual ExecutorService, created in the same way. It has .execute() and submit() methods for Runnable tasks, but the problem is that all Runnable tasks that go through the submit() method will be executed in coroutine, not in the thread. This solution is completely transparent to those who will implement our application, they will be able to use our API for coroutines.

I come to the last difficult part of the post - how to solve the issue of synchronization in the korutinas. This is a difficult question, so let's look at it in a simplified example. Here we have a quorutine A ( test::foo ) and a quorutine В ( test::bar ). First, we assign the execution of test:foo in box А Then Korutina А calls wait() . If nothing is done, the current thread will be blocked by a wait() call. As you can see from this dump thread, a deadlock will occur, and we will not be able to assign the execution of the next cortina.
How to solve this problem? Hotspot provides three types of locks. The first is fast lock. Here the owner of the lock is determined by the address on the stack. As I said before, each of our Corutin has a separate stack. Therefore, in the case of fast lock, we do not need to do any additional work. There is no similar support for biased lock in our system. We tried it on our production and it turned out that in the absence of biased lock, performance does not decrease. For us it is quite suitable.
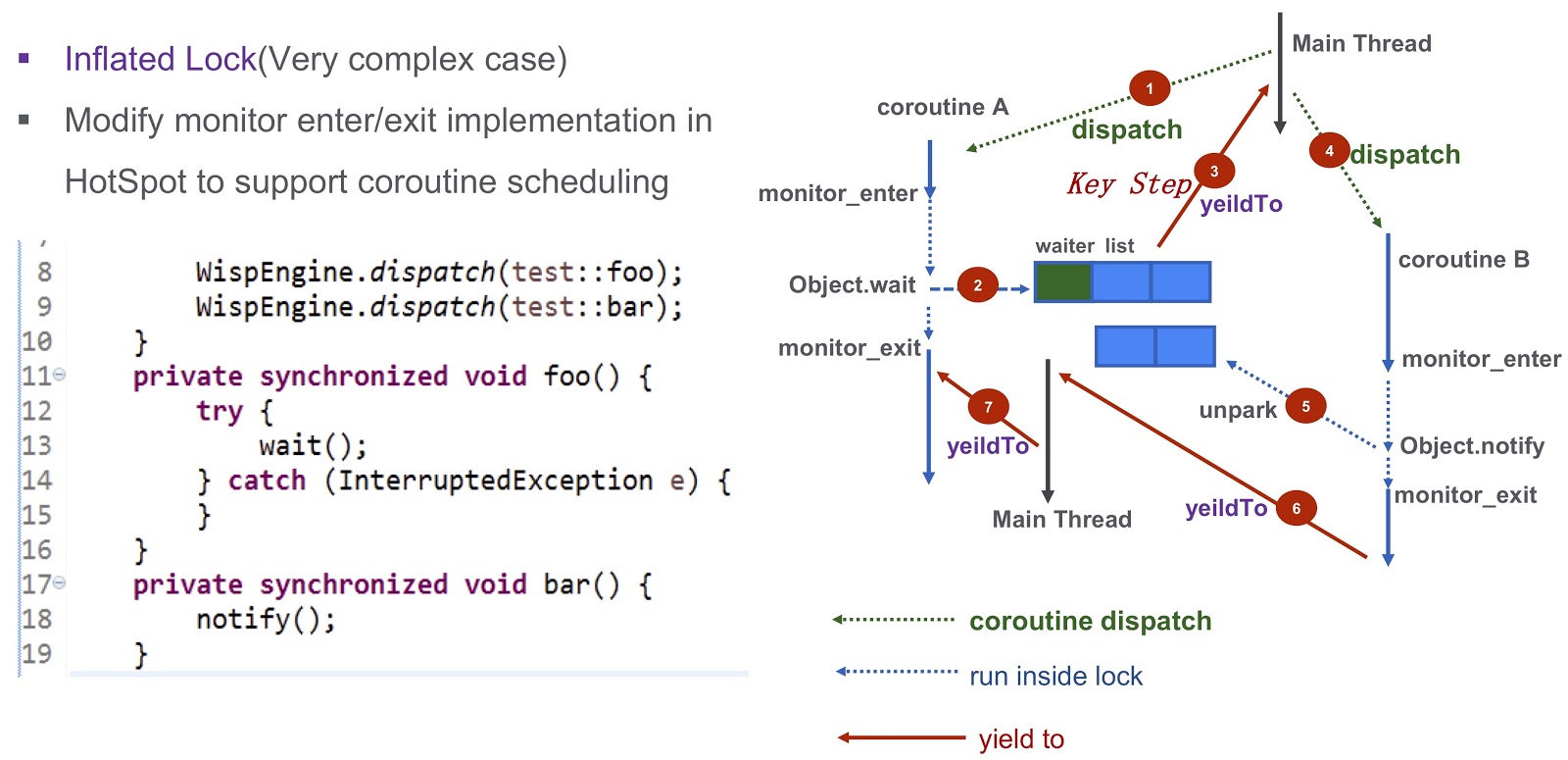
Let's talk about a more difficult case - inflated lock. Take another look at the example I gave above. We have a korutin А ( .foo() ) and a korutin B ( .bar() ). First, we assign the execution of Coroutine А and launch it. It then calls Object.wait , after which it falls into the waiting list. After this, we take a very important step: we generate a yieldTo event that passes control to the main thread. Next, we run B Corutina. It calls Object.notify , and the corresponding unpark events are unpark . Eventually they will wake coroutine А After the execution of bar() , it will be possible to transfer control to the corornet А Thus, the deadlock, which I mentioned earlier, is completely overcome.
Let's now discuss performance. We use Korutin in one of our online applications Carts. Based on this, we can compare the work of a corutin with the work of a regular JDK.
As you can see, they allow us to reduce the CPU consumption by almost 10%. I understand that most of you most likely do not have the ability to directly make such complex changes to the JDK code. But the main conclusion here, in my opinion, is that if productivity losses cost money and the resulting amount is sufficiently large, you can try to improve performance with the help of the korutin library.
Jwarmup
Let's move on to our other tool - JWarmup. It is very similar to another tool, ReadyNow. As we know, Java has a warm-up problem — the compiler at this stage requires additional CPU cycles. This caused us problems - for example, a TimeOut Error occurred. When scaling, these problems only get worse, and in our case we are talking about a very complex application - more than 20 thousand classes and more than 50 thousand methods.
Before we started using JWarmup, the owners of our application used simulated data to warm up. On this data, the JIT compiler performed a preliminary compilation while no requests had yet been received. But the simulated data is different from the real, so for the compiler they are not representative. In some cases, unexpected de-optimization occurred, performance suffered. The solution to this problem was JWarmup. He has two main stages of work - recording and compilation. Alibaba has two types of media, beta and production. Both those and others receive real requests from users, after which the same version of the application is deployed in these two environments. In a beta environment, only profiling data is collected, which is then precompiled in production.

Let's take a closer look at what kind of information we collect. We need to record exactly which classes are initialized, which methods are compiled, then this data is dumped into a log on the hard disk, which is accessible to the compiler. The most difficult moment is the initialization of classes. Её порядок полностью зависит от логики приложения. На слайде представлен пример — инициализация класса Bar должна происходить после выполнения Foo.test() , поскольку она использует foo.count . В этой ситуации мы выполняем инициализацию в момент, когда вся необходимая логика уже выполнена.
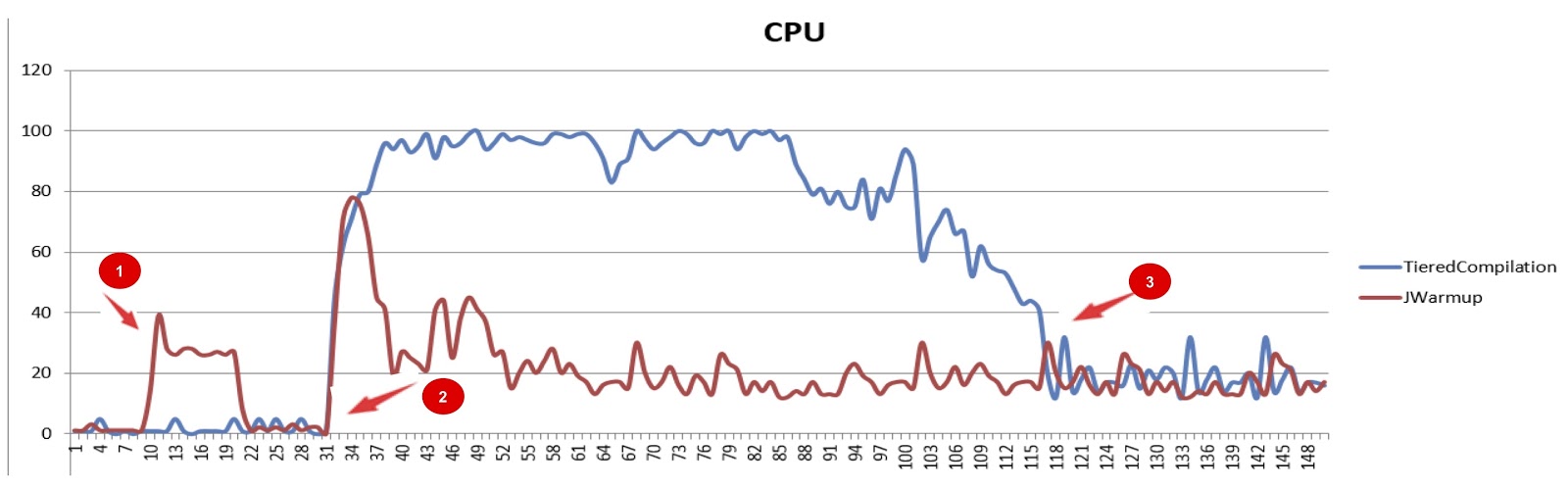
На картинке представлено сравнение производительности JWarmup и ступенчатой компиляции (tiered compilation), красный и синий графики соответственно. По оси х отложено время, по оси у — время CPU. На первом этапе у JWarmup происходит предварительная компиляция кода, поэтому он потребляет больше времени CPU, чем обычный JDK. Но затем, когда начинают поступать реальные запросы от пользователей, мы видим существенное улучшение в производительности по сравнению со стандартным JDK. Наконец, на последнем этапе при ступенчатой компиляции все наиболее часто используемые методы уже скомпилированы, и потребление ресурсов снова падает.
Необходимо сказать ещё несколько слов о JWarmup. Мы не можем записать класс, если он был сгенерирован динамически, скажем, некоторым groovy-скриптом, или при помощи Java-рефлексии, или прокси. Такие классы мы просто игнорируем. Кроме того, нам приходится отключать некоторые оптимизации, например «null check elimination». В противном случае у нас может происходить неожиданная деоптимизация. Наконец, наша текущая реализация JWarmup несовместима со ступенчатой компиляцией, так что если вы хотите пользоваться JWarmup, её необходимо отключить.
Diagnostic tools
И напоследок поговорим о средствах диагностики, которые мы создали в Alibaba.
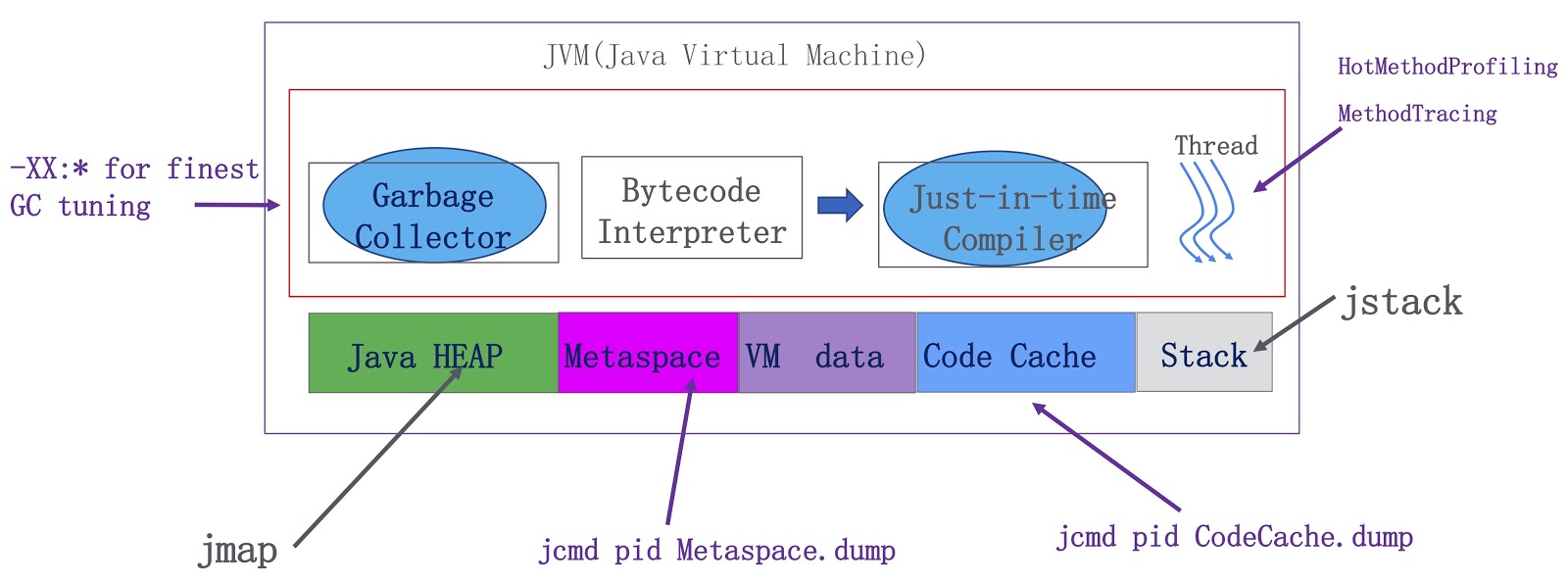
Схема описывает их функционирование. Здесь изображены компоненты JVM — сборщик мусора, интерпретатор байткода и компилятор, а также треды в рантайме. С точки зрения памяти мы имеем Java-кучу, metaspace, данные VM (предназначенные для внутреннего использования в VM) и кэш кода для JIT-компилятора. Мы добавили значительно больше возможностей профилирования для OpenJDK. Во-первых, сборщик мусора теперь работает на основе значительно более точной информации, что позволяет нам существенно улучшить его производительность. Во-вторых, мы реализовали два важных фичи для запуска тредов. Первая называется HotMethodProfiling, она позволяет определить, какие методы используют больше всего времени CPU. Кстати говоря, если вам необходимо профилировать ваши методы, я предлагаю воспользоваться Honest Profiler , это очень хороший опенсорсный инструмент, он работает по тому же принципу, что и наша фича HotMethodProfiling. Другая фича называется MethodTracing. Мы инструментируем метод на входе и на выходе на уровне компиляции, так что мы знаем, сколько времени занимает его выполнение. Помимо этого, мы добавили возможность создания дампа для metaspace и кэша кода. На основе дампа кэша кода мы можем сказать нашим Java-разработчикам, какой загрузчик классов потребляет больше памяти этого кэша. Благодаря дампу metaspace можно понять, фрагментировано оно или нет. Это очень полезно при разработке на Java.
Далее, мы также создали инструмент для диагностики, который назвали ZProfiler.
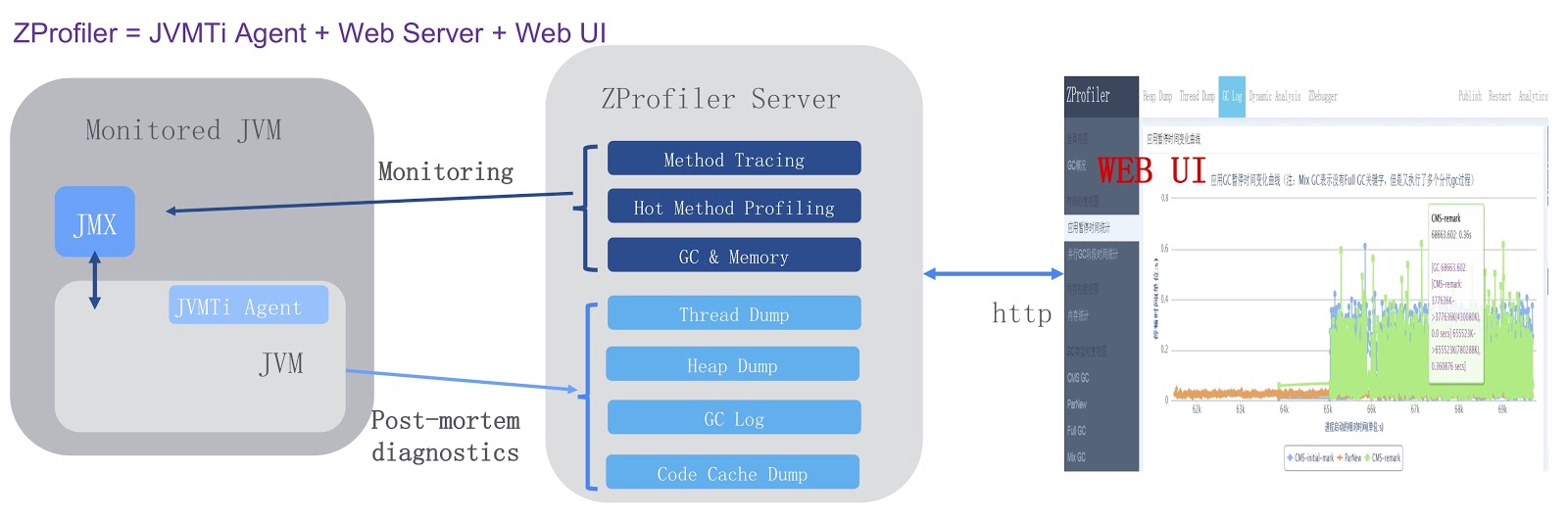
Схематично его работа изображена на картинке выше. Для него мы разработали агент JVMTi, который запускается внутри процесса JVM (на схеме слева). Кроме того, мы создали сервер ZProfiler на основе Apache Tomcat. Он напрямую развёрнут в нашем дата-центре. Это позволяет серверу ZProfiler напрямую обращаться к целевой JVM. Наконец, у ZProfiler есть веб-UI, которым могут пользоваться наши разработчики. ZProfiler предоставляет две основных функциональности. Во-первых, простым щелчком мыши на в UI можно получить очень точную информацию о целевой JVM. Во-вторых, ZProfiler предоставляет post-mortem диагностику. Например, если в нашей среде продакшна произошла ошибка OutOfMemoryError, одним щелчком мыши можно сгенерировать дамп кучи, и этот файл будет загружен с сервера целевой JVM на сервер ZProfiler, после чего результаты анализа будут доступны разработчикам. Это очень эффективное решение, которое позволяет обходиться без, скажем, Eclipse MAT.
Подведу итоги. Мы создали несколько решений для возникших перед нами проблем. Это мультитенантная JVM, GCIH, корутины для Alibaba JDK, а также JWarmup — средство, очень похожее на ReadyNow и коммерческую Zing JVM. Наконец, мы создали инструмент ZProfiler. В заключение я хотел бы сказать, что мы с радостью готовы предоставить сообществу те улучшения, которые мы создали на основе OpenJDK. По этому поводу уже идёт диалог, в частности, обсуждается возможность добавить JWarmup к OpenJDK. Кроме того, мы планируем участвовать в проекте OpenJDK под названием Loom, это реализация корутин для Java. На этом у меня всё, спасибо за внимание.
Минутка рекламы. Доклад, который вы только что прочитали, был сделан на конференции JPoint в 2018 году. На дворе уже 2019 год, и следующий JPoint состоится в Москве, 5-6 апреля. Программа всё ещё на стадии формирования, но уже можно увидеть таких известных товарищей как Rafael Winterhalter и Sebastian Daschner. Билеты можно приобрести на официальном сайте конференции. Чтобы оценить качество остальных докладов с прошлой конференции, можно посмотреть архив видеозаписей на YouTube . Встретимся на JPoint!
Source: https://habr.com/ru/post/436266/