Invisible deployable monolithic application in production on AWS. Personal experience
I am Lead DevOps Engineer in RealtimeBoard. I will share with you how our DevOps team solved the problem of daily server releases of a monolithic stateful application and made them automatic, invisible to users and convenient for their own developers.
Our development team is 60 people who are divided into Scrum teams, among which there is a DevOps team. Most Scrum teams support the current functionality of the product and come up with new features. The goal of DevOps is to create and maintain an infrastructure that helps an application to work quickly and reliably and allows teams to quickly deliver new functionality to users.

Our app is an endless online board. It consists of three layers: a website, a client, and a Java server, which is a monolithic stateful application. The application keeps a constant web-socket connection with clients, and each server keeps in memory a cache of open boards.
The entire infrastructure — over 70 servers — is in Amazon: over 30 servers with our Java application, web servers, database servers, brokers, and more. With the growth of functionality, all this should be regularly updated without disrupting users.
Updating the site and the client is simple: we replace the old version with a new one, and the next time the user accesses the new site and the new client. But if we do this with the release of the server, we will get downtime. For us, this is unacceptable, because the main value of our product is the collaboration of users in real time.
Our CI / CD process is git commit, git push, then auto build, autotest, deploy, release and monitoring.
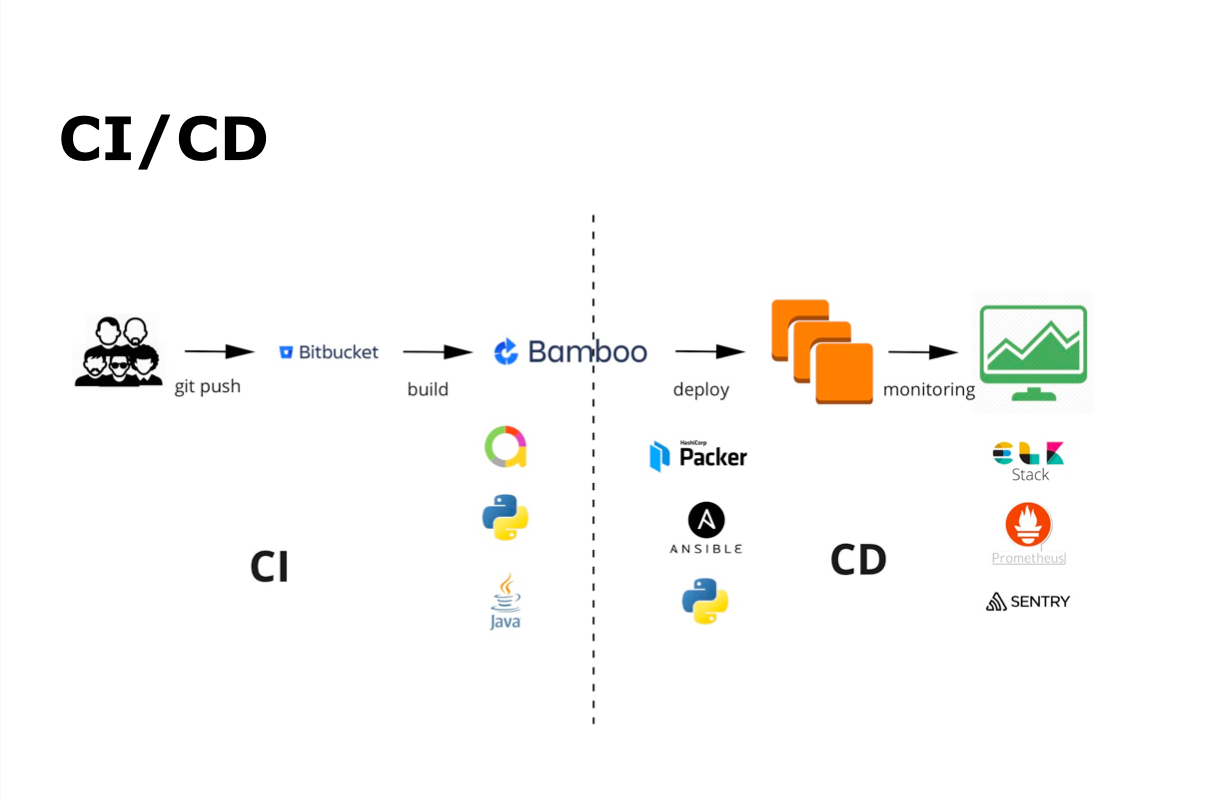
For continuous integration, we use Bamboo and Bitbucket. For automated testing, Java and Python, and Allure for displaying the results of automated testing. For continuous delivery - Packer, Ansible and Python. All monitoring is done using the ELK Stack, Prometheus and Sentry.
The developers write the code, add it to the repository, after which the automatic build and automatic testing is launched. At the same time, teams from other developers gather inside the team and a Code Review is held. When all the required processes, including autotests, are completed, the team merges the build into the main branch, and the build of the main branch build begins and is sent for automatic testing. This whole process is debugged and executed by the team itself.
In parallel with the build build and testing, the build of the AMI image for Amazon is launched. To do this, we use HashiCorp's Packer, an excellent opensource tool that allows you to build a virtual machine image. All parameters are transferred to JSON with a set of configuration keys. The main parameter is builders, which indicates for which provider we create an image (in our case, for Amazon).
It is important that we not only create an image of a virtual machine, but configure it in advance with the help of Ansible: install the necessary packages and do the configuration settings for running a Java application.
We used to use the usual Ansible playbook, but this led to a lot of repetitive code, which has become difficult to keep up to date. We changed something in one playbook, forgot to do it in another, and as a result we had problems. Therefore, we started using Ansible-roles. We made them as versatile as possible to reuse in different parts of the project and not overload the code with large, repetitive chunks. For example, the role of “Monitoring” is used for all types of servers.
From the side of Scrum teams, this process looks as simple as possible: the team receives notifications to Slack that the build and the AMI image are assembled.
We introduced pre-releases to deliver changes to the product to users as quickly as possible. In fact, these are canary releases that allow you to safely test new functionality on a small percentage of users.
Why are releases called canary? Previously, when the miners went down to the mine, they took a canary with them. If there was gas in the mine, the canary was dying and the miners quickly rose to the surface. So it is with us: if something goes wrong with the server, then the release is not ready and we can quickly roll back and most of the users will not notice anything.
How is the launch of the Canary release:
On the Scrum command side, the pre-release launch process looks as simple as possible again: the team receives notifications to Slack that the process has begun, and after 7 minutes the new server is already in operation. Additionally, the application sends the entire changelog of changes in the release to Slack.
In order for this barrier of security and reliability checks to work, Scrum teams monitor new errors in Sentry. This opensource real-time error tracking application. Sentry integrates seamlessly with Java and has logback and log2j connectors. When launching the application, we transfer to Sentry the version on which it is running, and when an error occurs, we see in which version of the application it occurred. This helps Scrum teams respond quickly to errors and fix them quickly.
Pre-release should work at least 4 hours. During this time, the team monitors its work and decides whether it is possible to output the release to all users.
Several teams can simultaneously display their releases . To do this, they agree among themselves what falls into the pre-release and who is responsible for the final release. After that, the teams either merge all changes into one pre-release, or launch several pre-releases at the same time. If all pre-releases are correct, they are released as one release the next day.
We release daily:
Everything is built using Bamboo and Python applications. The application checks the number of running servers and prepares to launch the same number of new ones. If there are not enough servers, they are created from an AMI image. A new version is deployed on them, a Java application is launched and the servers are put into operation.
When monitoring a Python application using the Prometheus API, it checks the number of open boards on new servers. When it understands that everything is working properly, it closes access to old servers and transfers users to new ones.
The process of transferring users between servers is displayed in Grafana. The left half of the graph shows the servers running on the old version, the right - on the new one. The intersection of graphs is the moment of transfer of users.

The team monitors the release of Slack. After the end of the release, the entire changelog of changes is published in a separate channel on Slack, and Jira automatically closes all tasks associated with this release.
The state of the board on which users work, we store in the memory of the application and constantly save all changes to the database. To transfer the board at the cluster interaction level, we load it into the memory on the new server and send a command to reconnect to the clients. At this point, the client disconnects from the old server and connects to the new one. After a couple of seconds, users see the title - Connection restored. However, they continue to work and do not notice any inconvenience.
What we came after a dozen iterations:
This was not possible immediately, we repeatedly attacked the same rake and stuffed many cones. I want to share the lessons we have learned.
First, the manual process, and only then its automation. The first steps do not need to go into automation, because you can automate what ultimately does not come in handy.
Ansible is good, but Ansible roles are better. We made our roles as universal as possible: we got rid of duplicate code, thanks to which they carry only the functionality that they have to carry. This allows you to significantly save time by reusing roles that we already have over 50.
Reuse the code in Python and break it into separate libraries and modules. It helps to navigate complex projects and quickly immerse new people in them.
The process of invisible deployment is not finished yet. Here are some of the following steps:
Our infrastructure
Our development team is 60 people who are divided into Scrum teams, among which there is a DevOps team. Most Scrum teams support the current functionality of the product and come up with new features. The goal of DevOps is to create and maintain an infrastructure that helps an application to work quickly and reliably and allows teams to quickly deliver new functionality to users.
Our app is an endless online board. It consists of three layers: a website, a client, and a Java server, which is a monolithic stateful application. The application keeps a constant web-socket connection with clients, and each server keeps in memory a cache of open boards.
The entire infrastructure — over 70 servers — is in Amazon: over 30 servers with our Java application, web servers, database servers, brokers, and more. With the growth of functionality, all this should be regularly updated without disrupting users.
Updating the site and the client is simple: we replace the old version with a new one, and the next time the user accesses the new site and the new client. But if we do this with the release of the server, we will get downtime. For us, this is unacceptable, because the main value of our product is the collaboration of users in real time.
What does the CI / CD process look like?
Our CI / CD process is git commit, git push, then auto build, autotest, deploy, release and monitoring.
For continuous integration, we use Bamboo and Bitbucket. For automated testing, Java and Python, and Allure for displaying the results of automated testing. For continuous delivery - Packer, Ansible and Python. All monitoring is done using the ELK Stack, Prometheus and Sentry.
The developers write the code, add it to the repository, after which the automatic build and automatic testing is launched. At the same time, teams from other developers gather inside the team and a Code Review is held. When all the required processes, including autotests, are completed, the team merges the build into the main branch, and the build of the main branch build begins and is sent for automatic testing. This whole process is debugged and executed by the team itself.
AMI image
In parallel with the build build and testing, the build of the AMI image for Amazon is launched. To do this, we use HashiCorp's Packer, an excellent opensource tool that allows you to build a virtual machine image. All parameters are transferred to JSON with a set of configuration keys. The main parameter is builders, which indicates for which provider we create an image (in our case, for Amazon).
"builders": [{ "type": "amazon-ebs", "access_key": "{{user `aws_access_key`}}", "secret_key": "{{user `aws_secret_key`}}", "region": "{{user `aws_region`}}", "vpc_id": "{{user `aws_vpc`}}", "subnet_id": "{{user `aws_subnet`}}", "tags": { "releaseVersion": "{{user `release_version`}}" }, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ami_name": "packer-board-ami_{{isotime \"2006-01-02_15-04\"}}" }], It is important that we not only create an image of a virtual machine, but configure it in advance with the help of Ansible: install the necessary packages and do the configuration settings for running a Java application.
"provisioners": [{ "type": "ansible", "playbook_file": "./playbook.yml", "user": "ubuntu", "host_alias": "default", "extra_arguments": ["--extra_vars=vars"], "ansible_env_vars": ["ANSIBLE_HOST_KEY_CHECKING=False", "ANSIBLE_NOCOLOR=True"] }] Ansible roles
We used to use the usual Ansible playbook, but this led to a lot of repetitive code, which has become difficult to keep up to date. We changed something in one playbook, forgot to do it in another, and as a result we had problems. Therefore, we started using Ansible-roles. We made them as versatile as possible to reuse in different parts of the project and not overload the code with large, repetitive chunks. For example, the role of “Monitoring” is used for all types of servers.
- name: Install all board dependencies hosts: all user: ubuntu become: yes roles: - java - nginx - board-application - ssl-certificates - monitoring From the side of Scrum teams, this process looks as simple as possible: the team receives notifications to Slack that the build and the AMI image are assembled.
Pre-releases
We introduced pre-releases to deliver changes to the product to users as quickly as possible. In fact, these are canary releases that allow you to safely test new functionality on a small percentage of users.
Why are releases called canary? Previously, when the miners went down to the mine, they took a canary with them. If there was gas in the mine, the canary was dying and the miners quickly rose to the surface. So it is with us: if something goes wrong with the server, then the release is not ready and we can quickly roll back and most of the users will not notice anything.
How is the launch of the Canary release:
- The Bamboo development team presses the button → a Python application is invoked, which launches a pre-release.
- It creates a new instance in Amazon from a previously prepared AMI image with a new version of the application.
- Instance is added to the required target groups and load balancers.
- With Ansible, an individual configuration is configured for each instance.
- Users work with a new version of Java application.
On the Scrum command side, the pre-release launch process looks as simple as possible again: the team receives notifications to Slack that the process has begun, and after 7 minutes the new server is already in operation. Additionally, the application sends the entire changelog of changes in the release to Slack.
In order for this barrier of security and reliability checks to work, Scrum teams monitor new errors in Sentry. This opensource real-time error tracking application. Sentry integrates seamlessly with Java and has logback and log2j connectors. When launching the application, we transfer to Sentry the version on which it is running, and when an error occurs, we see in which version of the application it occurred. This helps Scrum teams respond quickly to errors and fix them quickly.
Pre-release should work at least 4 hours. During this time, the team monitors its work and decides whether it is possible to output the release to all users.
Several teams can simultaneously display their releases . To do this, they agree among themselves what falls into the pre-release and who is responsible for the final release. After that, the teams either merge all changes into one pre-release, or launch several pre-releases at the same time. If all pre-releases are correct, they are released as one release the next day.
Releases
We release daily:
- We introduce new servers to work.
- Monitor user activity on new servers using Prometheus.
- We close access of new users to old servers.
- We transfer users from old servers to new ones.
- Turn off the old server.
Everything is built using Bamboo and Python applications. The application checks the number of running servers and prepares to launch the same number of new ones. If there are not enough servers, they are created from an AMI image. A new version is deployed on them, a Java application is launched and the servers are put into operation.
When monitoring a Python application using the Prometheus API, it checks the number of open boards on new servers. When it understands that everything is working properly, it closes access to old servers and transfers users to new ones.
import requests PROMETHEUS_URL = 'https://prometheus' def get_spaces_count(): boards = {} try: params = { 'query': 'rtb_spaces_count{instance=~"board.*"}' } response = requests.get(PROMETHEUS_URL, params=params) for metric in response.json()['data']['result']: boards[metric['metric']['instance']] = metric['value'][1] except requests.exceptions.RequestException as e: print('requests.exceptions.RequestException: {}'.format(e)) finally: return boards The process of transferring users between servers is displayed in Grafana. The left half of the graph shows the servers running on the old version, the right - on the new one. The intersection of graphs is the moment of transfer of users.
The team monitors the release of Slack. After the end of the release, the entire changelog of changes is published in a separate channel on Slack, and Jira automatically closes all tasks associated with this release.
What is user migration?
The state of the board on which users work, we store in the memory of the application and constantly save all changes to the database. To transfer the board at the cluster interaction level, we load it into the memory on the new server and send a command to reconnect to the clients. At this point, the client disconnects from the old server and connects to the new one. After a couple of seconds, users see the title - Connection restored. However, they continue to work and do not notice any inconvenience.
What we have learned while making the invisible
What we came after a dozen iterations:
- Scrum-team itself checks its code.
- The scrum team decides for itself when to launch a pre-release and bring some changes to new users.
- The scrum team decides whether its release is ready for all users.
- Users continue to work and do not notice anything.
This was not possible immediately, we repeatedly attacked the same rake and stuffed many cones. I want to share the lessons we have learned.
First, the manual process, and only then its automation. The first steps do not need to go into automation, because you can automate what ultimately does not come in handy.
Ansible is good, but Ansible roles are better. We made our roles as universal as possible: we got rid of duplicate code, thanks to which they carry only the functionality that they have to carry. This allows you to significantly save time by reusing roles that we already have over 50.
Reuse the code in Python and break it into separate libraries and modules. It helps to navigate complex projects and quickly immerse new people in them.
Next steps
The process of invisible deployment is not finished yet. Here are some of the following steps:
- Allow teams to perform not only pre-releases, but all releases.
- Make automatic rollbacks in case of errors. For example, a pre-release should automatically roll back if critical errors are detected in Sentry.
- Fully automate the release with no errors. If the pre-release was not a single error, then it can automatically roll out further.
- Add automatic code scanning for potential security errors.
Source: https://habr.com/ru/post/436444/