How do we find problem releases using Graphite and Moira. Experience Yandex. Money
Hi, Habr! After plenty of rest after the long holidays, we are again ready to do you good by all available means. There is always something to tell colleagues from the IT department, and today we are sharing with you the report by Alexander Prizov, Yandex.Money system administrator, from the JavaJam meeting.
How we built feedback flow to detect problem releases using Graphite and Moira. We will tell you how to collect and analyze metrics about the number of errors in the application.
- Hello everyone, my name is Alexander Prizov, I work in the department of automation of operation in Yandex.Money, and today I will tell you about how we collect, process, analyze information about our system.
You, probably, might have a question why the report is called The Second Way. Everything is quite simple. The basis of DevOps is a series of principles, which, arbitrarily, are divided into three groups.
The first path is the flow principle. The second path includes the principle of feedback. The third way is continuous learning and experimentation.
As a rule, in terms of the development and operation of software products, feedback means telemetry, which we collect about our system, and the most common case is the collection and processing of metrics.
Why do we need these metrics? With the help of metrics, we get feedback from the system and we can know what state our system is in, if everything is going well, how our changes have affected its work, and whether some kind of intervention is needed to solve certain problems.
What metrics do we collect?
We collect metrics from three levels.
The business level includes indicators that are interesting from the point of view of any business problems. For example, we can get answers to questions such as how many users are registered with us, how often users log in to our system, how many active users are in our mobile application.
The next level is the application level . The metrics of this level are most often viewed by developers, because these indicators give an answer to the question of how well our application works, how quickly it processes requests, whether there is a drop in performance. This includes the response time, the number of requests, the length of the queue, and much more.
And finally, the level of infrastructure . Here everything is clear. Using these metrics, we can estimate the amount of resources consumed, how to predict them, and identify problems related to infrastructure.
Now I’ll briefly describe how we send, process, and store these metrics. Next to the application we have a metrics collector. In our case, this is the Heka service, which listens on the UDP port and waits for the metrics in the StatsD format.
The StatsD format looks like this:
That is, we define the name of the metric, indicate the value of this metric, this is 1, 26, and so on, and indicate its type. In total, StatsD has about four or five types. If you are suddenly interested, you can see in detail the description of these types .
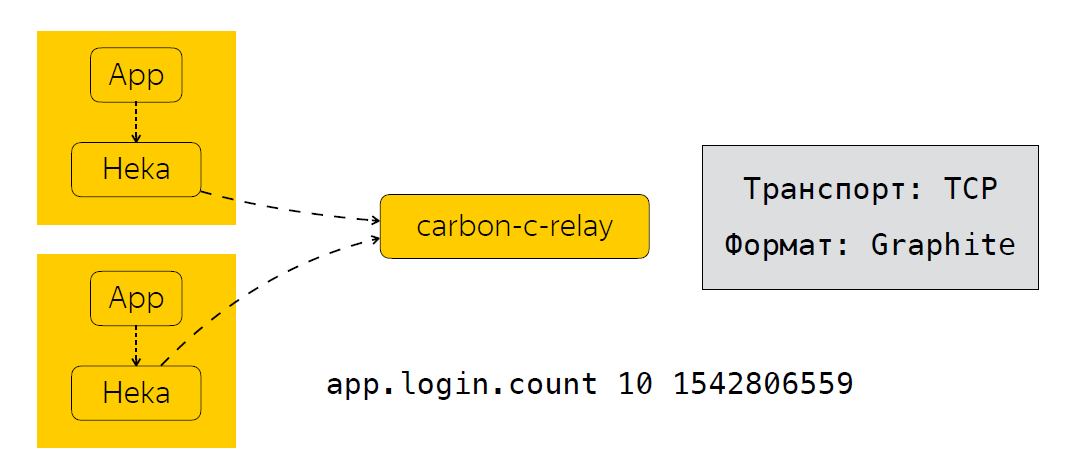
After the application has sent the Heka data, the metrics are aggregated over time. In our case, it is 30 seconds, after which Heka sends data to carbon-c-relay, which performs the filtering, routing, modification of metrics function, which, in turn, sends metrics to our storage, we use clickhouse (yes, it does not slow down ), as well as in Moira. If anyone does not know, this is a service that allows you to configure certain triggers for metrics. I will talk about Moira a little later. So, we looked at what metrics we collect, how we send and process them. And the next logical step is the analysis of these metrics.
How do we analyze metrics?
I will give a real situation where the analysis of metrics has given us tangible results. As an example, take our release process. In general, it includes the following steps.
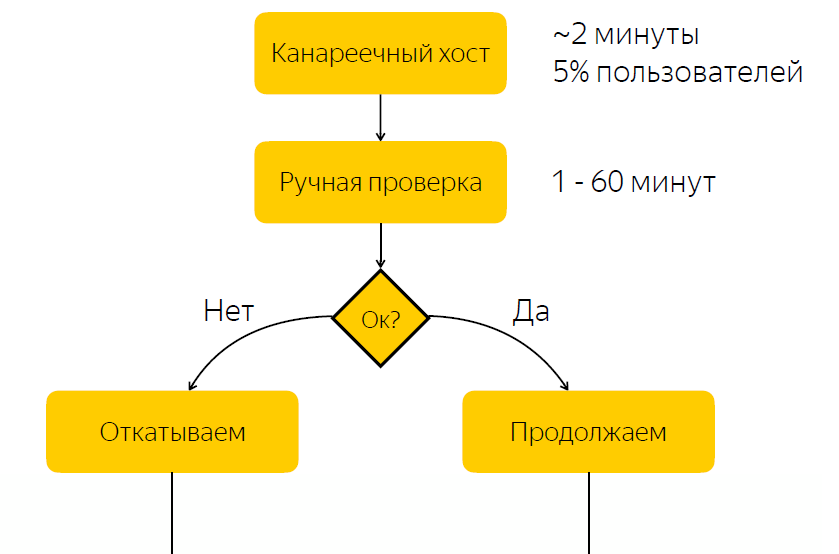
The release is deployed to the canary host. It accounts for about five percent of user traffic. After the release to the canary host is completed, we notify the release manager that he should check if everything is fine with the release. And he should give a reaction, react to this release and press the button with the decision about whether this release should be rolled further, or it should be rolled back.
It is not difficult to guess that there is a significant drawback in this scheme, namely, that we expect the reaction of the responsible person. If the person in charge is currently unable to react quickly for some reason, then if we have a release with bugs, then for some time five percent of the traffic comes to the problem node. If the release is all right, then we simply spend time waiting, and thus slow down the release process.
No bugs - we slow down the release process
With bugs - users affect
With an understanding of this problem, we decided to find out whether it is possible to automate the process of deciding whether a release is problematic or not.
We, of course, turned to our developers to understand how the release check is performed. It turned out, and it seems quite logical that the main indicator that the release is problematic, is the increase in the number of errors in the logs of this application.
What did the developers do? They opened Kibana, sampled the ERROR level of the application block, and in case they saw the lists, they thought that something was wrong with the application. It is worth mentioning that the logs of our application are stored in Elastic, and it seems that everything looks quite simple. We have logs in Elastic, we only need to form a request in Elastic, make a selection and understand, based on this data, whether the release is problematic or not. But this solution seemed to us not very good.
Why not Elastic?
First of all, we were concerned that we could not promptly receive data from Elastic. There are such cases, for example, during load testing, when we have a large flow of data, and the cluster can not cope, and, ultimately, there is a delay in sending logs of about 10-15 minutes.
There were also secondary reasons, for example, the lack of a uniform name for indexes. This had to be taken into account in the automation tool. As well as applications on different platforms could have a different format of logs.
We thought, why not try to make some metrics on the basis of which we can decide whether the release is problematic or not. At the same time, we did not want to burden our developers to make changes to the code base. And, as it seems to us, we found a rather elegant solution by adding an additional appender to log4j.
What it looks like
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status="warn" name="${sys:application.name}" > <Properties> <Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property> </Properties> ... <Appenders> <Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP"> <PatternLayout pattern="${logsCountStatsDFormat}"/> </Socket> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="STATSD"/> </Root> </Loggers> </Configuration> First we define the format of the metric that we send. The following describes an additional appender that sends entries in the format that we have indicated above to port 8125 via UDP, that is, to Heka. What does this give us? Log4j for each record in the log sends a Counter type metric, with a given record level of ERROR, INFO, WARN, and so on.
However, we quickly realized that sending metrics to each record in the logs can create quite a significant load, and we wrote a library that aggregates the metrics for a certain time and sends the already aggregated metric to the Heka service. Actually, we add this appender to loggers, and using this approach, we now know how much our application writes breakdown logs by levels, we have a unified name for metrics, regardless of which platform is used. We can easily understand how many errors are in the application log. And finally, we were able to automate the process of making a decision about a problem release.
Automation
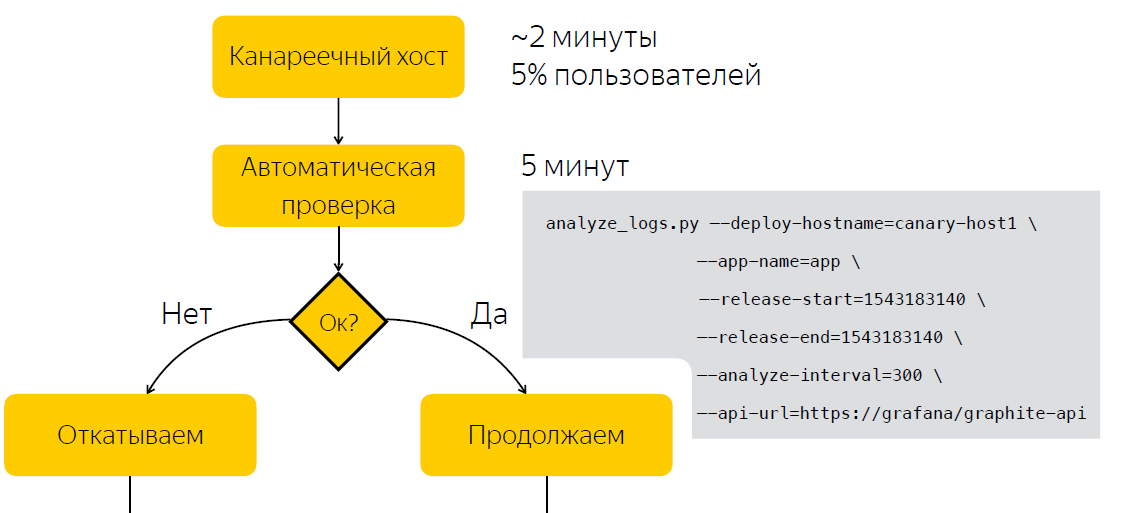
Instead of a manual check after release, we wait five minutes, after which we collect data on the number of entries in the application logs. After we run the script, which, based on two samples, before the release and after, decides whether the release is problematic. Thus, we have reduced the amount of time we spend on making a decision to five minutes.
Apart from the fact that information about the number of errors in the logs is useful during the release, a pleasant bonus for us was that it is also useful during the operation. So, for example, we can visualize the number of errors in the logs in Grafana and fix anomalous bursts in the application logs.
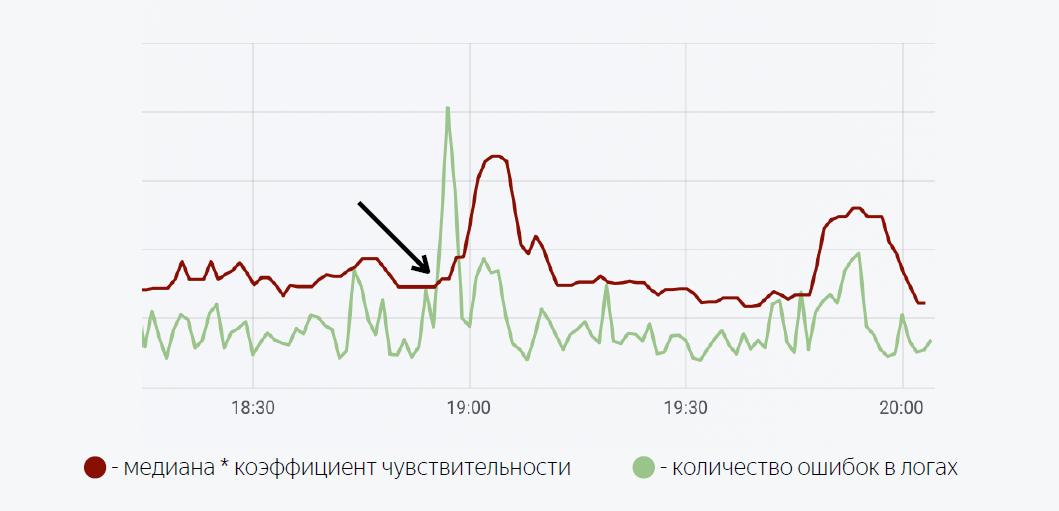
It uses a fairly simple mathematical model. The green line is the number of errors in the application logs. Dark red is the median multiplied by the coefficient of sensitivity. In the case where the number of errors in the logs crosses the median, we trigger a trigger, when triggered, a notification is sent through Moira.
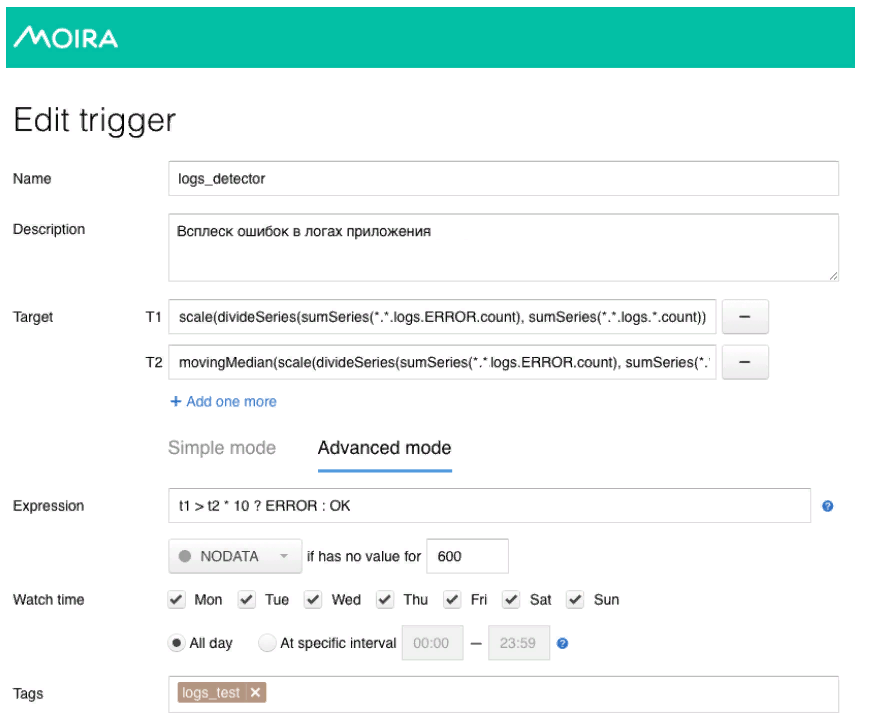
As I promised, I will tell you a little about Moira, how it works. We define the target metrics we want to observe. This is the number of errors and the moving median, as well as the conditions under which this trigger will work, that is, when the number of errors in the logs exceeds the median multiplied by the sensitivity coefficient. When the trigger is triggered, the developer receives a notification that an anomalous surge of errors has been detected in the application, and some action should be taken.

What do we have in the end? We have developed a general mechanism for all our backend-applications, which allow us to obtain information about the number of records in the logs of a given level. Also, using the metrics about the number of errors in the application logs, we were able to automate the process of deciding whether a release is problematic or not. They also wrote a library for log4j, which you can use if you want to try the approach I described. Link to the library below.
On this I have, perhaps, everything. Thank.
useful links
Source: https://habr.com/ru/post/436512/