Improving Q-Learning agent trading stocks, by adding recurrence and rewards
Reminder
Hi, Habr! I bring to your attention one more translation of my new article from a medium .
Last time (the first article ) ( Habr ) we created an agent on Q-Learning technology, who makes deals on simulated and real stock exchange time series and tried to check whether this task area is suitable for reinforcement learning.
This time we will add an LSTM layer to account for the time dependencies inside the trajectory and do reward shaping based on the presentations.
I recall that to test the concept, we used the following synthetic data:
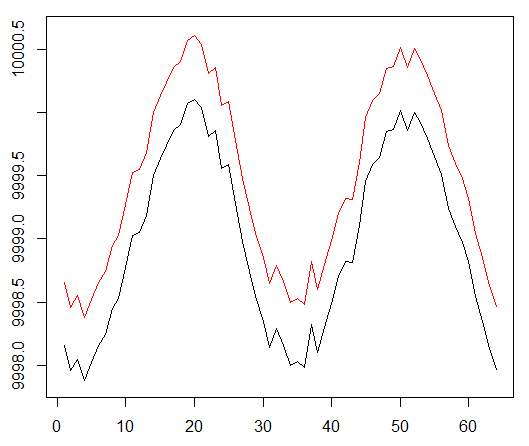
Synthetic data: sine with white noise.
The sine function was the first starting point. Two curves mimic the purchase and sale price of an asset, where the spread is the minimum transaction value.
However, this time we want to complicate this simple task by extending the credit assignment path:
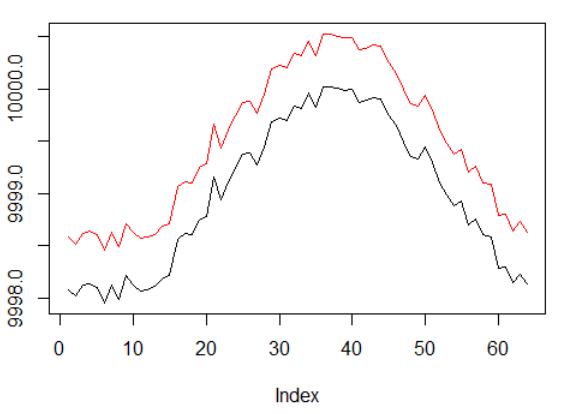
Synthetic data: sine with white noise.
The sine phase has been doubled.
This means that the sparse rewards that we use should spread along longer paths. In addition, we significantly reduce the likelihood of receiving a positive remuneration, since the agent had to perform a sequence of correct actions 2 times longer in order to overcome transaction costs. Both factors significantly complicate the task for RL even in such simple conditions as a sinusoid.
In addition, we recall that we used this neural network architecture:
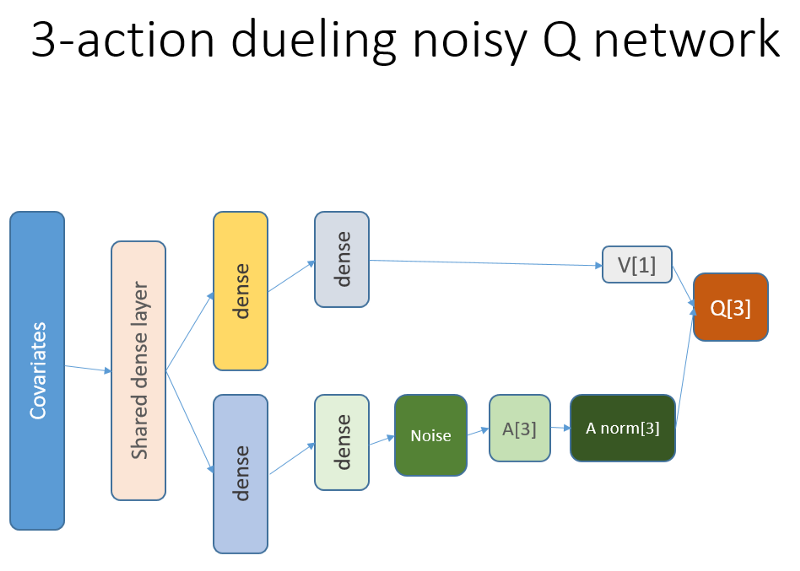
What was added and why
Lstm
First of all, we wanted to give the agent more insight into the dynamics of changes within the trajectory. Simply put, the agent should better understand his own behavior: what he did right now and some time in the past, and how the distribution of state-actions, as well as the awards received, developed. Using a recurrent layer can solve this particular problem. Welcome the new architecture used to launch a new set of experiments:

Please note that I have slightly improved the description. The only difference from the old NN is the first hidden layer of LSTM instead of the fully bound one.
Please note that with LSTM in work, we need to change the sample of examples of experience reproduction for training: now we need transition sequences instead of individual examples. This is how it works (this is one of the algorithms). We used point sampling earlier:

Dummy buffer playback.
We use this scheme with LSTM:

Now the sequences are selected (whose length we define empirically).
Both before and now the sample is regulated by a priority algorithm based on errors of temporal and temporal training.
The recurrent level of LSTM allows the direct dissemination of information from the time series to intercept an additional signal hidden in past logs. Our time series is a two-dimensional tensor with size: the length of a sequence on the representations of our state-action.
Presentations
The award-winning engineering, Potential Based Reward Shaping (PBRS) - based on potential, is a powerful tool that allows you to increase speed, stability and not violate the optimality of the policy search process to solve our environment. I recommend reading at least this original document on the subject:
people.eecs.berkeley.edu/~russell/papers/ml99-shaping.ps
The potential determines how well our current state is relative to the target state we want to enter. Sketchy look at how this works:

There are options and difficulties that you might understand after trial and error, and we omit these details, leaving you to do your homework.
Another thing worth mentioning is that PBRS can be justified with the help of presentations, which are a form of expert (or simulated) knowledge of the almost optimal behavior of the agent in the environment. There is a way to find such presentations for our task using optimization schemes. Omit the search details.
The potential reward takes the following form (equation 1):
r '= r + gamma * F (s') - F (s)
where F means the potential of the state, and r is the initial reward, gamma is the discounting factor (0: 1).
With these thoughts, we turn to coding.
Implementation in R
Here is the neural network code based on the Keras API:
Code
# configure critic NN — — — — — — library('keras') library('R6') state_names_length <- 12 # just for example lstm_seq_length <- 4 learning_rate <- 1e-3 a_CustomLayer <- R6::R6Class( “CustomLayer” , inherit = KerasLayer , public = list( call = function(x, mask = NULL) { x — k_mean(x, axis = 2, keepdims = T) } ) ) a_normalize_layer <- function(object) { create_layer(a_CustomLayer, object, list(name = 'a_normalize_layer')) } v_CustomLayer <- R6::R6Class( “CustomLayer” , inherit = KerasLayer , public = list( call = function(x, mask = NULL) { k_concatenate(list(x, x, x), axis = 2) } , compute_output_shape = function(input_shape) { output_shape = input_shape output_shape[[2]] <- input_shape[[2]] * 3L output_shape } ) ) v_normalize_layer <- function(object) { create_layer(v_CustomLayer, object, list(name = 'v_normalize_layer')) } noise_CustomLayer <- R6::R6Class( “CustomLayer” , inherit = KerasLayer , lock_objects = FALSE , public = list( initialize = function(output_dim) { self$output_dim <- output_dim } , build = function(input_shape) { self$input_dim <- input_shape[[2]] sqr_inputs <- self$input_dim ** (1/2) self$sigma_initializer <- initializer_constant(.5 / sqr_inputs) self$mu_initializer <- initializer_random_uniform(minval = (-1 / sqr_inputs), maxval = (1 / sqr_inputs)) self$mu_weight <- self$add_weight( name = 'mu_weight', shape = list(self$input_dim, self$output_dim), initializer = self$mu_initializer, trainable = TRUE ) self$sigma_weight <- self$add_weight( name = 'sigma_weight', shape = list(self$input_dim, self$output_dim), initializer = self$sigma_initializer, trainable = TRUE ) self$mu_bias <- self$add_weight( name = 'mu_bias', shape = list(self$output_dim), initializer = self$mu_initializer, trainable = TRUE ) self$sigma_bias <- self$add_weight( name = 'sigma_bias', shape = list(self$output_dim), initializer = self$sigma_initializer, trainable = TRUE ) } , call = function(x, mask = NULL) { #sample from noise distribution e_i = k_random_normal(shape = list(self$input_dim, self$output_dim)) e_j = k_random_normal(shape = list(self$output_dim)) #We use the factorized Gaussian noise variant from Section 3 of Fortunato et al. eW = k_sign(e_i) * (k_sqrt(k_abs(e_i))) * k_sign(e_j) * (k_sqrt(k_abs(e_j))) eB = k_sign(e_j) * (k_abs(e_j) ** (1/2)) #See section 3 of Fortunato et al. noise_injected_weights = k_dot(x, self$mu_weight + (self$sigma_weight * eW)) noise_injected_bias = self$mu_bias + (self$sigma_bias * eB) output = k_bias_add(noise_injected_weights, noise_injected_bias) output } , compute_output_shape = function(input_shape) { output_shape <- input_shape output_shape[[2]] <- self$output_dim output_shape } ) ) noise_add_layer <- function(object, output_dim) { create_layer( noise_CustomLayer , object , list( name = 'noise_add_layer' , output_dim = as.integer(output_dim) , trainable = T ) ) } critic_input <- layer_input( shape = list(NULL, as.integer(state_names_length)) , name = 'critic_input' ) common_lstm_layer <- layer_lstm( units = 20 , activation = “tanh” , recurrent_activation = “hard_sigmoid” , use_bias = T , return_sequences = F , stateful = F , name = 'lstm1' ) critic_layer_dense_v_1 <- layer_dense( units = 10 , activation = “tanh” ) critic_layer_dense_v_2 <- layer_dense( units = 5 , activation = “tanh” ) critic_layer_dense_v_3 <- layer_dense( units = 1 , name = 'critic_layer_dense_v_3' ) critic_layer_dense_a_1 <- layer_dense( units = 10 , activation = “tanh” ) # critic_layer_dense_a_2 <- layer_dense( # units = 5 # , activation = “tanh” # ) critic_layer_dense_a_3 <- layer_dense( units = length(actions) , name = 'critic_layer_dense_a_3' ) critic_model_v <- critic_input %>% common_lstm_layer %>% critic_layer_dense_v_1 %>% critic_layer_dense_v_2 %>% critic_layer_dense_v_3 %>% v_normalize_layer critic_model_a <- critic_input %>% common_lstm_layer %>% critic_layer_dense_a_1 %>% #critic_layer_dense_a_2 %>% noise_add_layer(output_dim = 5) %>% critic_layer_dense_a_3 %>% a_normalize_layer critic_output <- layer_add( list( critic_model_v , critic_model_a ) , name = 'critic_output' ) critic_model_1 <- keras_model( inputs = critic_input , outputs = critic_output ) critic_optimizer = optimizer_adam(lr = learning_rate) keras::compile( critic_model_1 , optimizer = critic_optimizer , loss = 'mse' , metrics = 'mse' ) train.x <- array_reshape(rnorm(10 * lstm_seq_length * state_names_length) , dim = c(10, lstm_seq_length, state_names_length) , order = 'C') predict(critic_model_1, train.x) layer_name <- 'noise_add_layer' intermediate_layer_model <- keras_model(inputs = critic_model_1$input, outputs = get_layer(critic_model_1, layer_name)$output) predict(intermediate_layer_model, train.x)[1,] critic_model_2 <- critic_model_1 Debug your decision on your conscience ...
Results and Comparison
Let's dive straight to the final results. Note: all results are point estimates and may differ with repeated launch with different random initial sidami.
The comparison includes:
- previous version without LSTM and presentations
- simple 2-element LSTM
- 4-element LSTM
- LSTM with 4 cells and awards formed through PBRS
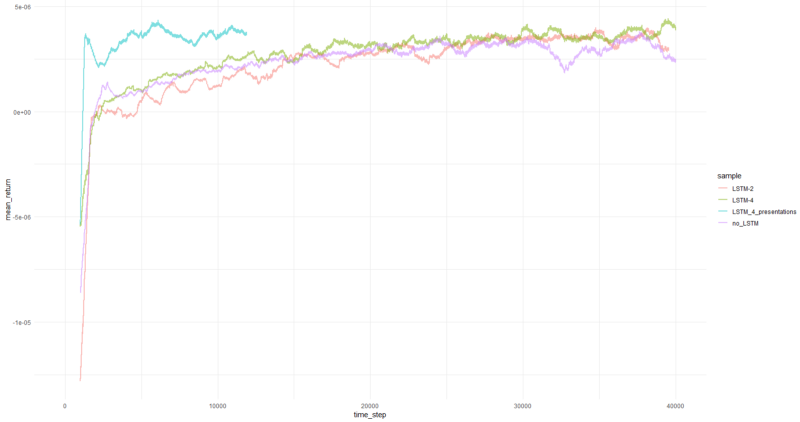
The average yield per episode averaged over 1000 episodes.
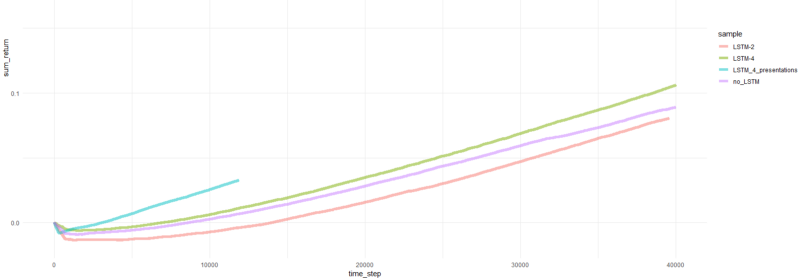
The total return on episodes.
Charts for the most successful agent:


The performance of the agent.
Well, it’s pretty obvious that an agent in the form of PBRS converges so quickly and stably compared to earlier attempts that you can take it as a meaningful result. The speed is about 4–5 times higher than without presentations. Stability is wonderful.
When it comes to using LSTM, 4 cells performed better than 2 cells. The 2-cell LSTM performed better than the non-LSTM version (however, this may be an illusion of a single experiment).
Final words
We have witnessed that recurrence and capacity-based reward helps. I especially liked how PBRS showed itself so highly.
Do not believe anyone who makes me say that it is easy to create an RL agent who fits well, as this is a lie. Each new component added to the system makes it potentially less stable and requires a lot of configuration and debugging.
Nevertheless, there is clear evidence that the solution to the problem can be improved simply by improving the methods used (the data remained intact). It is a fact that for any task a certain range of parameters works better than others. With this in mind, you embark on the path of successful training with reinforcements.
Thank.
Source: https://habr.com/ru/post/436628/