Reverse Engineering Fantastic Dizzy
Fantastic Dizzy is a puzzle-platformer game created by Codemasters in 1991. She is part of a series of games about Dizzy ( Dizzy Series ). Despite the fact that the Dizzy series is still popular, and for it are amateur games ( Dizzy Age ), it seems that no one was engaged in the reverse development of the original games.

I have written some simple tools for extracting, viewing and packing the resources of the original game. The tools are laid out on github .
The PCDIZZY.EXE binary file is packaged in Microsoft EXEPack format. Although there are many tools for Linux that can unpack such executable files, none of them seem to support the version used for Fantastic Dizzy. Therefore, I used the DOS version of UNP to unpack the executable file. After unpacking the executable file, it could be loaded into IDA. Conveniently, the unpacked version of the binary file still worked well, so you could debug it using the DOSBox debugger.
The game has two data files: DIZZY.NDX and DIZZY.RES. Extensions as well as file sizes give us a hint about what they may contain. The NDX file is approximately 8 KB in size, and the RES file is approximately 800 KB. Since the game is written in C, we can search the IDA fopen calls to see where the data files are opened. In games for DOS written in assembly language, for this you need to look for instructions int 21h (to open the file ah = 3d). The Dizzy binary file contains a wrapper function around fopen that allows you to specify the main name and file extension. She leads us to the next block of code:
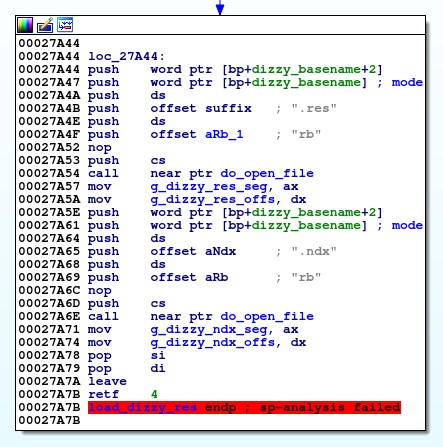
It loads the DIZZY.RES and DIZZY.NDX files, and also stores file pointers in global variables. When backing up DOS binaries, an annoying problem arises: the registers in them are 16-bit, but pointers in some cases can be 32-bit. Here, FILE * pointers are 32 bits in size and returned from do_open_file in ax: dx. Notice that the strings are also 32-bit pointers, and the dizzy_basename is passed to the calling function on the stack (and this confused the IDA's auto-analysis confusing - he considered that this is the mode argument for fopen).
You can search where x_fizs contain entries for g_dizzy_res / ndx where files are read. At this stage, the DOSBox debugger is useful, because the likelihood of multiple read-access file operations is high, and using IDA to determine read offsets would be a fairly monotonous process. A good guide to building and using the DOSBox debugger can be found here .
When using IDA and the DOSBox debugger, it becomes obvious that the NDX file is used as an index for the RES file. Each entry in the NDX file is 16 bytes; it stores the fragment identifier, its size and offset in the RES file. Looking at how the RES data is read, you can see that the flag byte is first checked in the NDX file. If the 0x80 bit is not set, then the data is read directly from the RES file, otherwise a more complex code path is executed. The flag is set for most fragments, so it is very likely that it means some kind of compression used for these fragments.
The compression path begins with reading out from the base of the RES fragment two 32-bit words denoting the initial and final dimensions, and then the unpack function is called. In 1991, simple length-length coding (run length encoding, RLE) and dictionary compression, such as various Liv-Zempel algorithms, were popular. The beginning of the unpacking cycle looks like this:

Unpacking tokens are obtained using the get_next_token function, which reads the next part of the source data in ax: dx with a shift by cl. The cl register is used as the bit-shift position, returning to zero after reaching eight. At the beginning of the cycle, the token is read and the lower bit is checked. If the flag is set, the code is simple:

It only saves the current byte, receives the next token and continues to work. If the flag is cleared, a longer code path is selected, which ends with the rep movsb instruction. This indicates that a dictionary is used in compression.
The compression algorithm is interesting for several reasons. First, it uses variable bit length coding. The absolute value is encoded as 1 flag and an 8-bit data value. Curiously, the bitstream is encoded as little endian. This slightly complicates the analysis of unpacking by observing the RES file in a hexadecimal editor. For example, if the first three bytes of a fragment are encoded as absolute values, then the data is arranged as follows:
In addition, the unpacker can skip a byte when reading, if the counter cl returns to zero when the next token is received. I do not know whether this is an optimization, or a bug, or a hack created by a game developer, in order to fix the problem with my tools.
If the flag is cleared, the decompressor performs copying from the initial part of the unpacked data. In this case, the following bits encode the length and offset from which to copy. The offset is encoded in 10 or 13 bits, and the desired option is indicated by a flag. This seems like a very strange choice, because it complicates the code a bit, and at best saves only 2 bits.
Length coding looks a bit strange. The unpacker reads the bits until it reaches the zero bit. Then the number of bits used to encode the length is two plus the number of non-zero bits. For example, when encoding length 58 (0x3a), the bitstream looks like this:
11 bits are required for encoding. Small lengths are better encoded, because the minimum bit length is 2. Copying lengths up to 3 requires only 3 bits to encode, up to 7 requires 5 bits, and so on. I do not know for sure whether this kind of coding is a common technique.
The DOSBox debugger is also very useful for recreating the decompression algorithm. If you do not know what the unpacked data should look like, then it is difficult to understand whether the decompressor works correctly. Using the debugger, you can step through the entire decompression algorithm and save the dump of the unpacked memory for comparison.
Another useful feature is the flag in the NDX file, which indicates that the resource is compressed. Since the original game supports unpacked resources, we can repack the RES file without the need for a compression algorithm. Modifying and repacking fragments and then starting the game is a good way to check our assumptions about data formats.
Fantastic Dizzy is a game with an open world. Levels are areas with vertical or horizontal scrolling. The player moves between levels, reaching the end of the level or entering and leaving buildings. Although references to fragments in the RES file are made through 16-bit identifiers (IDs), the binary game file actually contains a table of matching level names with fragment identifiers. Each level consists of several fragments: a header, one or several layers, a tileset and a palette. There is a small redundancy here, because some levels use the same palette and tileset, but do not reuse the same fragments, so the RES file contains many duplicate resources.
Layers encode tiles for level. Additional layers can be used for different parts of the world or for background layers. For example, at the level tree1.stg there are eight layers for different parts of treetops and one common background layer. However, the underwater levels are divided into sea1.stg and sea2.stg, each of which has one foreground layer and one background layer.
Background layers are backgrounds of a fixed width without scrolling, for example, a forest in a part of the game with treetops. The foreground and background tiles, which are located in front of and behind the character, are encoded in the same layer as the tiles on which you can walk. For example, the screenshot shows the level from the treetops from the beginning of the game:
Treetops level
It is the seventh layer of tree1.stg:

Seventh layer level tree1.stg
It is worth noting that the player can pass in front of the hut, but behind two trees. All information of the tiles is contained in one array of the tile map, which is located in one layer. Tiles in layer fragments are encoded with two bytes, and the lower 9 bits are used for the tile index. I did not fully understand the upper bits, but at least they contain information about the shift of the palette for the tile and, probably, information about collisions.
As the levels in the game are also stored cutscenes, character portraits and inventory control screen. It seems that such a technique is standard for DOS games, probably because it minimizes the amount of code needed.

Inventory Management Level
The format of sprites is not particularly interesting. Each sprite is a bitmap with one byte per pixel, but with only 16 colors per sprite. Using a limited number of colors was a common technique in the era of the 256-color VGA, because for the sprites you could easily shift the palettes or use them in levels with other palettes; besides, it saved the place allocated under sprites.
Sprites have a different size, so a separate fragment contains information about the size of the sprite and their x and y offsets. Sprites are grouped into sets, but the grouping looks rather arbitrary. For example, one set of sprites contains splash screen graphics, inventory items, and also some non-player characters. This makes it a little difficult to view the sets of sprites, because the palette is not the same for all sprites.

Player Character Sprites
It remains to expose a reverse engineering a few more things. I am mainly interested in data file formats, but there are some aspects that I don’t understand:
I have written some simple tools for extracting, viewing and packing the resources of the original game. The tools are laid out on github .
Unpacking exe
The PCDIZZY.EXE binary file is packaged in Microsoft EXEPack format. Although there are many tools for Linux that can unpack such executable files, none of them seem to support the version used for Fantastic Dizzy. Therefore, I used the DOS version of UNP to unpack the executable file. After unpacking the executable file, it could be loaded into IDA. Conveniently, the unpacked version of the binary file still worked well, so you could debug it using the DOSBox debugger.
Data files
The game has two data files: DIZZY.NDX and DIZZY.RES. Extensions as well as file sizes give us a hint about what they may contain. The NDX file is approximately 8 KB in size, and the RES file is approximately 800 KB. Since the game is written in C, we can search the IDA fopen calls to see where the data files are opened. In games for DOS written in assembly language, for this you need to look for instructions int 21h (to open the file ah = 3d). The Dizzy binary file contains a wrapper function around fopen that allows you to specify the main name and file extension. She leads us to the next block of code:
It loads the DIZZY.RES and DIZZY.NDX files, and also stores file pointers in global variables. When backing up DOS binaries, an annoying problem arises: the registers in them are 16-bit, but pointers in some cases can be 32-bit. Here, FILE * pointers are 32 bits in size and returned from do_open_file in ax: dx. Notice that the strings are also 32-bit pointers, and the dizzy_basename is passed to the calling function on the stack (and this confused the IDA's auto-analysis confusing - he considered that this is the mode argument for fopen).
You can search where x_fizs contain entries for g_dizzy_res / ndx where files are read. At this stage, the DOSBox debugger is useful, because the likelihood of multiple read-access file operations is high, and using IDA to determine read offsets would be a fairly monotonous process. A good guide to building and using the DOSBox debugger can be found here .
When using IDA and the DOSBox debugger, it becomes obvious that the NDX file is used as an index for the RES file. Each entry in the NDX file is 16 bytes; it stores the fragment identifier, its size and offset in the RES file. Looking at how the RES data is read, you can see that the flag byte is first checked in the NDX file. If the 0x80 bit is not set, then the data is read directly from the RES file, otherwise a more complex code path is executed. The flag is set for most fragments, so it is very likely that it means some kind of compression used for these fragments.
Compression
The compression path begins with reading out from the base of the RES fragment two 32-bit words denoting the initial and final dimensions, and then the unpack function is called. In 1991, simple length-length coding (run length encoding, RLE) and dictionary compression, such as various Liv-Zempel algorithms, were popular. The beginning of the unpacking cycle looks like this:
Unpacking tokens are obtained using the get_next_token function, which reads the next part of the source data in ax: dx with a shift by cl. The cl register is used as the bit-shift position, returning to zero after reaching eight. At the beginning of the cycle, the token is read and the lower bit is checked. If the flag is set, the code is simple:
It only saves the current byte, receives the next token and continues to work. If the flag is cleared, a longer code path is selected, which ends with the rep movsb instruction. This indicates that a dictionary is used in compression.
The compression algorithm is interesting for several reasons. First, it uses variable bit length coding. The absolute value is encoded as 1 flag and an 8-bit data value. Curiously, the bitstream is encoded as little endian. This slightly complicates the analysis of unpacking by observing the RES file in a hexadecimal editor. For example, if the first three bytes of a fragment are encoded as absolute values, then the data is arranged as follows:
Байты: AAAAAAAA BBBBBBBB CCCCCCCC DDDDDDDD Токен 1: 6543210F 7 Токен 2: 543210F 76 Токен 3: 43210F 765 In addition, the unpacker can skip a byte when reading, if the counter cl returns to zero when the next token is received. I do not know whether this is an optimization, or a bug, or a hack created by a game developer, in order to fix the problem with my tools.
If the flag is cleared, the decompressor performs copying from the initial part of the unpacked data. In this case, the following bits encode the length and offset from which to copy. The offset is encoded in 10 or 13 bits, and the desired option is indicated by a flag. This seems like a very strange choice, because it complicates the code a bit, and at best saves only 2 bits.
Length coding looks a bit strange. The unpacker reads the bits until it reaches the zero bit. Then the number of bits used to encode the length is two plus the number of non-zero bits. For example, when encoding length 58 (0x3a), the bitstream looks like this:
11110 111010 11 bits are required for encoding. Small lengths are better encoded, because the minimum bit length is 2. Copying lengths up to 3 requires only 3 bits to encode, up to 7 requires 5 bits, and so on. I do not know for sure whether this kind of coding is a common technique.
The DOSBox debugger is also very useful for recreating the decompression algorithm. If you do not know what the unpacked data should look like, then it is difficult to understand whether the decompressor works correctly. Using the debugger, you can step through the entire decompression algorithm and save the dump of the unpacked memory for comparison.
Another useful feature is the flag in the NDX file, which indicates that the resource is compressed. Since the original game supports unpacked resources, we can repack the RES file without the need for a compression algorithm. Modifying and repacking fragments and then starting the game is a good way to check our assumptions about data formats.
Levels
Fantastic Dizzy is a game with an open world. Levels are areas with vertical or horizontal scrolling. The player moves between levels, reaching the end of the level or entering and leaving buildings. Although references to fragments in the RES file are made through 16-bit identifiers (IDs), the binary game file actually contains a table of matching level names with fragment identifiers. Each level consists of several fragments: a header, one or several layers, a tileset and a palette. There is a small redundancy here, because some levels use the same palette and tileset, but do not reuse the same fragments, so the RES file contains many duplicate resources.
Layers encode tiles for level. Additional layers can be used for different parts of the world or for background layers. For example, at the level tree1.stg there are eight layers for different parts of treetops and one common background layer. However, the underwater levels are divided into sea1.stg and sea2.stg, each of which has one foreground layer and one background layer.
Background layers are backgrounds of a fixed width without scrolling, for example, a forest in a part of the game with treetops. The foreground and background tiles, which are located in front of and behind the character, are encoded in the same layer as the tiles on which you can walk. For example, the screenshot shows the level from the treetops from the beginning of the game:
Treetops level
It is the seventh layer of tree1.stg:
Seventh layer level tree1.stg
It is worth noting that the player can pass in front of the hut, but behind two trees. All information of the tiles is contained in one array of the tile map, which is located in one layer. Tiles in layer fragments are encoded with two bytes, and the lower 9 bits are used for the tile index. I did not fully understand the upper bits, but at least they contain information about the shift of the palette for the tile and, probably, information about collisions.
As the levels in the game are also stored cutscenes, character portraits and inventory control screen. It seems that such a technique is standard for DOS games, probably because it minimizes the amount of code needed.
Inventory Management Level
Sprites
The format of sprites is not particularly interesting. Each sprite is a bitmap with one byte per pixel, but with only 16 colors per sprite. Using a limited number of colors was a common technique in the era of the 256-color VGA, because for the sprites you could easily shift the palettes or use them in levels with other palettes; besides, it saved the place allocated under sprites.
Sprites have a different size, so a separate fragment contains information about the size of the sprite and their x and y offsets. Sprites are grouped into sets, but the grouping looks rather arbitrary. For example, one set of sprites contains splash screen graphics, inventory items, and also some non-player characters. This makes it a little difficult to view the sets of sprites, because the palette is not the same for all sprites.
Player Character Sprites
What is left?
It remains to expose a reverse engineering a few more things. I am mainly interested in data file formats, but there are some aspects that I don’t understand:
- Where are the locations of objects (keys, fruits, etc.). It seems that they are not recorded in the fragments of the levels. They may be stored in a binary game file, because a player can pick up an object on one level and throw it on another.
- How collisions work for levels. A player may pass in front of or behind some tiles, and the floors may be flat or sloping.
- How levels are connected. This information may be stored in a binary game file.
- The shift of the palette for tiles at the levels is not quite correct. Some tiles show incorrect colors.
- Each set of sprites has three fragments: a title, a table and data. Fragments with a table and data are clear to me, but some information about sprites is included in the header, for example, an x and y offset. With its format, I figured out not to the end.
Source: https://habr.com/ru/post/436674/