New Year's dances around the FC-adapter or a tale about how far the causes of the problem are far from the symptoms
So, on January 4 at 7:15, wiping my eyes from sleep, I discover a packet in the Telegram group from the Zabbix server that the load on the CPU has increased on one of the virtualization servers:
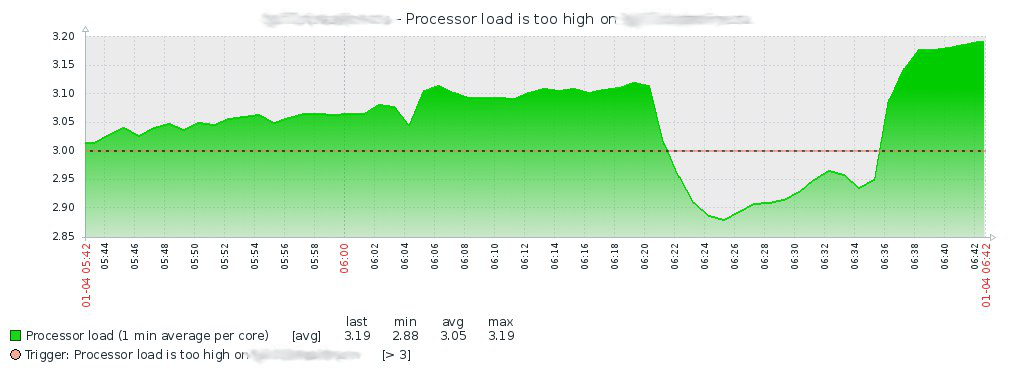
Having looked at the story in Zabbix, I climb to the server and look in the dmesg, where I find the following:
[Чт янв 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. [Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [Чт янв 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device I climbed to the storage at which the QLogic FC adapter is looking, I see that on January 1 at 19:54 one of the drives in the storage was taken out of work, the Spare drive was picked up and on January 2 at 9:11 am the resilvering ended:

I thought: maybe something came from the storage or the FC switch, from which the driver got tangled up in the QLogic adapter.
Created a task in the tracker, restarted the server, everything worked again as it should, at first glance.
On this postponed further action until the end of the New Year holidays.
With the beginning of the working week on January 9, I began to investigate the cause of the failure.
Since the message:
[Чт янв 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. not too informative, got into the source of the driver.
Judging by the driver code, the message is issued when the driver is unloaded due to a PCI error (linux / drivers / scsi / qla2xxx / qla_os.c (v4.15 kernel)):
qla2x00_disable_board_on_pci_error(struct work_struct *work) { struct qla_hw_data *ha = container_of(work, struct qla_hw_data, board_disable); struct pci_dev *pdev = ha->pdev; scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev); /* * if UNLOAD flag is already set, then continue unload, * where it was set first. */ if (test_bit(UNLOADING, &base_vha->dpc_flags)) return; ql_log(ql_log_warn, base_vha, 0x015b, "Disabling adapter.\n"); Began to dig further, got into the BMC, I look in the Event Log:
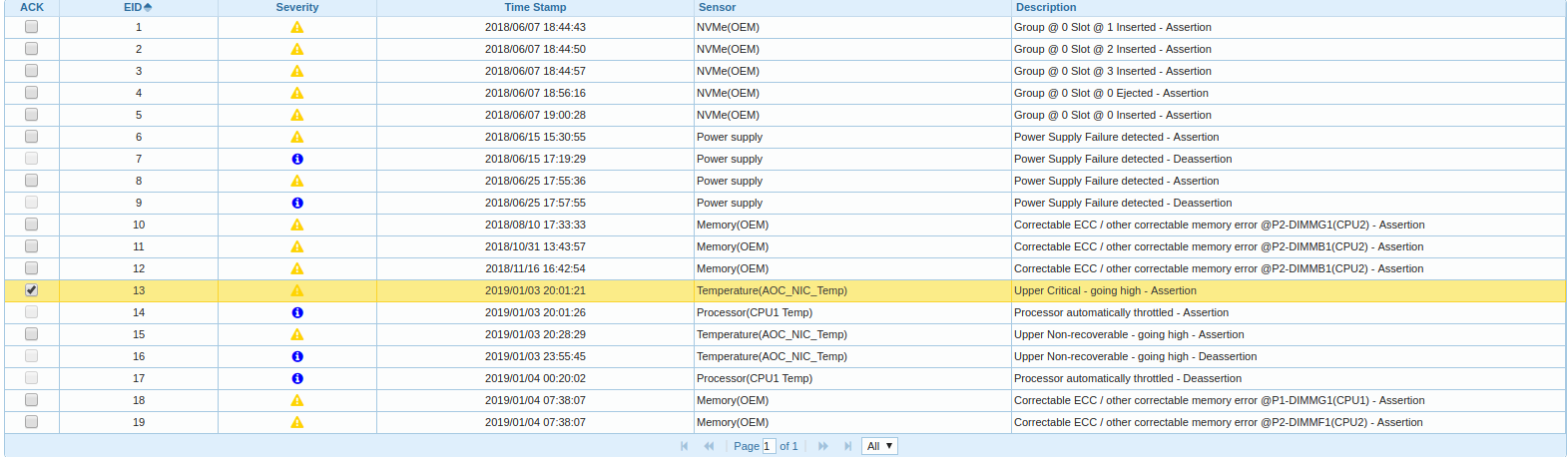
It turns out that one of the two CPU nodes in the platform is heated and throttly, and the time of the message about the unloading of the FC-adapter driver correlates with the start time of the throttling.
Here it is worth making a remark that the server platform here is https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm with two EPYC 7601 for each node:
I moved it to the data center, took the node out of the server, changed the thermal paste, stuck it back, but it still heats up.
We noticed that the air flow in one part of the server is not as strong as in the other. Having a little loaded all the nodes with the help of stress-ng, it became clear that the processors of the nodes in the right side of the platform are not blown properly and the temperature of the second CPU in two nodes very quickly reaches the critical one.
After trying to change the parameters of the blower in the BMC, it turned out that they do not have an action:
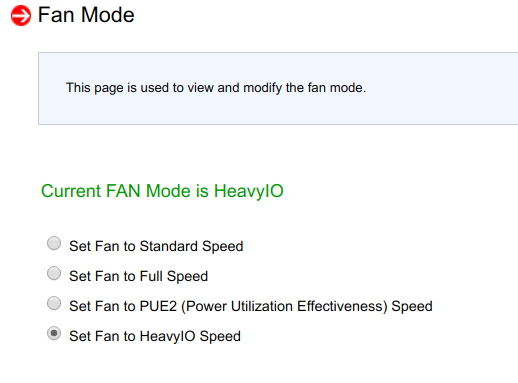
Restarting the BMC also had no effect.
Looking into the Sensor Readings, I saw that on one node of 53 sensors, only 4 are detected, and on the other node only 6:
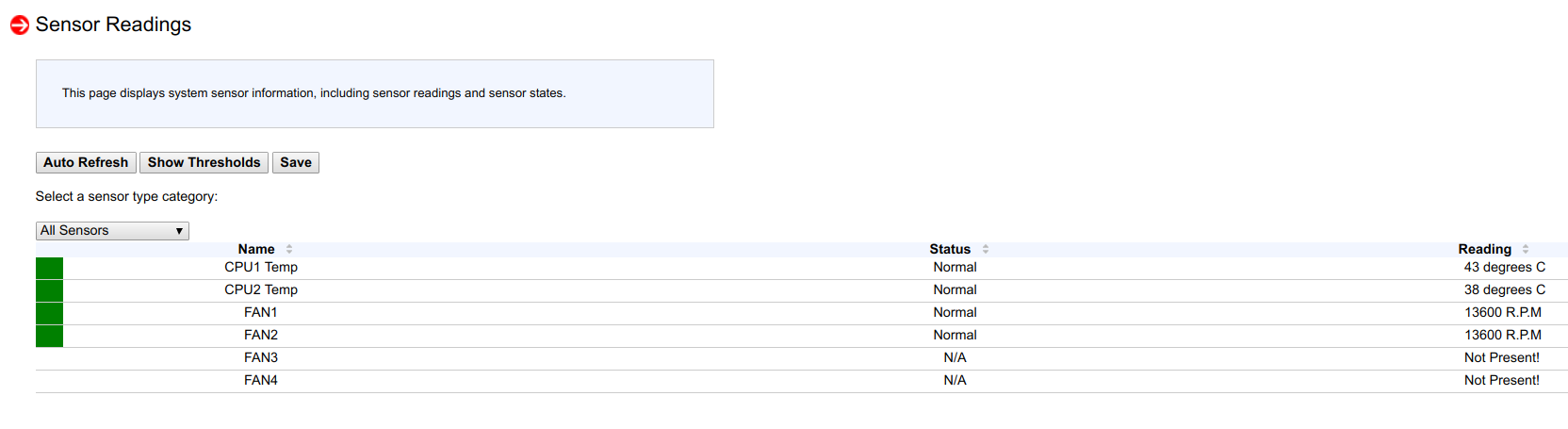
And then, I remembered that flashing the new BIOS version and a new BMC into nodes from a month or two ago, on two nodes I did not reset the BMC configuration to the factory settings (to check one special case of settings).
After resetting the BMC to the factory settings, all 53 sensors again showed up, fan speed control started up again, and the processors stopped warming up.
The fact that the reason for unloading the QLogic driver is overheating of the processor is not certain, but I did not find any close correlations.
Findings:
- after the BMC firmware, even if everything works fine at first glance, it is still worth resetting the settings to the factory settings;
- Of course, the temperature and error messages of the kernel should be put under monitoring, and this is natural in the plans, but not all at once.
Source: https://habr.com/ru/post/436874/