Linux API. Managing File I / O Buffering in the Kernel
 Hi, Habrozhiteli! We have already written about the book by Michael Kerrisk “Linux API. A comprehensive guide . Now we have decided to publish an excerpt from the book "Managing File I / O Buffering in the Kernel"
Hi, Habrozhiteli! We have already written about the book by Michael Kerrisk “Linux API. A comprehensive guide . Now we have decided to publish an excerpt from the book "Managing File I / O Buffering in the Kernel"Resetting kernel buffer memory for output files can be forced. Sometimes this is necessary if the application, before continuing to work (for example, a process that logs database changes), must guarantee the actual writing of the output to disk (or at least to the hardware cache of the disk).
Before considering the system calls used to manage buffering in the kernel, it is useful to consider a few related definitions from SUSv3.
Synchronized I / O with data and file integrity
In SUSv3, the concept of synchronized I / O completion means “an I / O operation that either led to a successful transfer of data [to disk] or was diagnosed as unsuccessful”.
SUSv3 defines two different types of synchronized I / O terminations. The difference between types relates to metadata (“data about data”) describing a file. The kernel stores them together with the data of the file itself. The details of the file metadata will be discussed in section 14.4 when examining inode file descriptors. In the meantime, it will suffice to note that file metadata includes information such as information about the owner of the file and its group, file access permissions, file size, the number of hard links to the file, time stamps showing the time of the last access to the file, the time it was last changed and the time of the last metadata change, as well as pointers to data blocks.
The first type of synchronized I / O completion in SUSv3 is termination with data integrity. When updating the file data, the transfer of information sufficient to allow further retrieval of this data to continue the work should be ensured.
- for a read operation, this means that the requested file data has been transferred (from disk) to the process. If there are deferred write operations that may affect the requested data, the data will be transferred to the disk before reading.
- for a write operation, this means that the data specified in the write request has been transferred (to disk), as well as all the file metadata required to retrieve this data. The key point to pay attention to is: to ensure that data from the modified file is extracted, it is not necessary to transfer all the medatans of the file. As an example, the metadata attribute of a modified file that needs to be transferred can be given its size (if the write operation leads to an increase in the file size). In contrast, the timestamps of the modified file will not need to be transferred to disk before subsequent data retrieval takes place.
The second type of completion of synchronized I / O defined in SUSv3 is the completion with file integrity. This is an advanced way to complete synchronized I / O with data integrity. The difference between this mode is that during the update of the file all its metadata is transferred to the disk, even if it is not required for the subsequent extraction of the file data.
System calls to control the buffering performed in the kernel during file I / O
The fsync () system call resets all buffered data and all metadata that is associated with an open file that has a fd descriptor. The fsync () call brings the file to the integrity (file) state after the completion of synchronous I / O.
The fsync () call returns only after the data transfer to the disk device (or at least its cache memory) is completed.
#include <unistd.h> int fsync(int fd); Returns 0 on success; or –1 on error.
The fdatasync () system call works in the same way as fsync (), but brings the file to a state of integrity (data) after the completion of synchronous I / O.
#include <unistd.h> int fdatasync(int fd); Returns 0 on success; or –1 on error.
Using fdatasync () potentially reduces the number of disk operations from the two needed by the fsync () system call to one. For example, if the file data has changed, but the size remains the same, the call to fdatasync () only causes a forced update of the data. (As noted above, to complete a synchronous I / O operation with data integrity, there is no need to transfer changes in attributes such as the last file modification time.) In contrast, calling fsync () will also force metadata to be transferred to disk.
Such a reduction in the number of disk I / O operations will be useful for individual applications, for which performance plays a crucial role and it does not matter if the specific metadata is accurately updated (for example, time stamps). This can lead to significant improvements in the performance of applications that make multiple file updates at once. Since the data and file metadata are usually located in different parts of the disk, updating both those and others will require repeated search operations back and forth across the disk.
In Linux 2.2 and earlier versions, fdatasync () is implemented as an fsync () call, so it does not provide any performance gain.
Starting with kernel 2.6.17, Linux provides the nonstandard system call sync_file_range (). It allows you to more accurately control the process of flushing file data to disk than fdatasync (). When you call, you can specify the drop area of the file and set flags that set the conditions for blocking this call. Further details can be found on the sync_file_range (2) manual page.
The sync () system call causes all kernel buffers containing updated file information (ie, data blocks, pointer blocks, metadata, etc.) to be flushed to disk.
#include <unistd.h> void sync(void); In the Linux implementation, the sync () function returns control only after all data has been transferred to the disk device (or at least into its cache memory). But in SUSv3, it is allowed for sync () to simply transfer data for an I / O operation to the plan and return control until the transfer is complete.
A constantly executing kernel thread will flush modified kernel buffers to disk if they have not been explicitly synchronized for 30 seconds. This is done in order to prevent data buffers from being out of sync with the corresponding disk file for long periods of time (and not putting them at risk of loss in the event of a system failure). In Linux 2.6, this task is performed by the pdflush kernel stream. (In Linux 2.4, it was executed by the kupdated kernel thread.)
The time period (in hundredths of a second), through which the modified buffer should be flushed to disk by the pdflush stream code, is defined in the / proc / sys / vm / dirty_expire_centisecs file. Additional files in the same directory control other features of the operation performed by the pdflush stream.
Enable synchronization mode for all entries: O_SYNC
Specifying the O_SYNC flag when calling open () causes all subsequent output operations to be performed in synchronous mode:
fd = open(pathname, O_WRONLY | O_SYNC); After this open () call, each write () operation with the file automatically flushes the file's data and metadata to disk (that is, the entries are performed as synchronized write operations with the integrity of the file).
In older versions of the BSD system, the O_FSYNC flag was used to provide the functionality enabled by the O_SYNC flag. In glibc, the O_FSYNC flag is defined as a synonym for O_SYNC.
O_SYNC flag performance impact
Using the O_SYNC flag (or frequent calls to fsync (), fdatasync () or sync ()) can greatly affect performance. In tab. 13.3 shows the time required to write 1 million bytes to the newly created file (in the ext2 file system) with different buffer sizes with the O_SYNC flag set and cleared. The results were obtained (using the filebuff / write_bytes.c program provided in the source code for the book) using the “vanilla” kernel version 2.6.30 and the ext2 file system with a block size of 4096 bytes. Each line contains the average value obtained after 20 launches for a given buffer size.
Table 13.3. The effect of the O_SYNC flag on the write speed of 1 million bytes
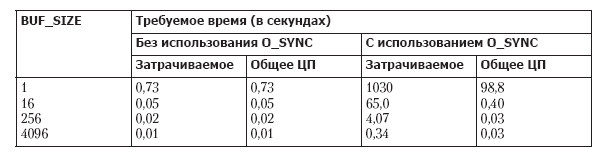
As you can see, specifying the O_SYNC flag results in a monstrous increase in time spent when using a 1-byte buffer of more than 1000 times. Note also the large difference that occurs when executing records with the O_SYNC flag between the elapsed time and the time that the CPU is used. It is a consequence of blocking program execution when the contents of each buffer are actually flushed to disk.
In the results shown in table. 13.3, does not take into account another factor affecting performance when using O_SYNC. Modern disk drives have a large amount of internal cache, and by default, setting the O_SYNC flag simply leads to the transfer of data to this cache. If you turn off disk caching (using the hdparm –W0 command), the performance impact of O_SYNC will become even more significant. With a buffer size of 1 byte, the elapsed time will increase from 1030 seconds to approximately 16,000 seconds. With a buffer size of 4096 bytes, the elapsed time will increase from 0.34 seconds to 4 seconds. As a result, if you need to force a dump of kernel buffers to disk, you should consider whether the application can be designed with larger buffers for write () or consider using periodic calls of fsync () or fdatasync () instead of the O_SYNC flag.
O_DSYNC and O_RSYNC flags
SUSv3 defines two additional open file status flags related to synchronized I / O: O_DSYNC and O_RSYNC.
The O_DSYNC flag causes subsequent synchronized write operations to be performed with data integrity of the terminated I / O (like using fdatasync ()). The effect of its operation is different from the effect caused by the O_SYNC flag, the use of which leads to subsequent synchronized write operations with the integrity of the file (like fsync ()).
The O_RSYNC flag is specified together with O_SYNC or with O_DSYNC and leads to the extension of the behavior associated with these flags when performing read operations. Specifying the O_RSYNC and O_DSYNC flags when opening a file causes subsequent synchronized read operations with data integrity (that is, before the read is completed, due to the presence of O_DSYNC, all pending file records complete). Specifying the O_RSYNC and O_SYNC flags when opening a file causes subsequent synchronized read operations with the integrity of the file (that is, before the read is completed, due to the presence of O_SYNC all pending file entries are completed).
Before the release of kernel version 2.6.33, the O_DSYNC and O_RSYNC flags in Linux were not implemented and these constants in the glibc header files were defined as setting the O_SYNC flag. (In the case of O_RSYNC, this was incorrect, since O_SYNC does not affect any functional features of read operations.)
Starting with kernel version 2.6.33, the O_DSYNC flag is implemented in Linux, and the implementation of the O_RSYNC flag will most likely be added to future releases of the kernel.
Prior to the release of the 2.6.33 kernel in Linux, there was no complete implementation of the O_SYNC semantics. Instead, the O_SYNC flag was implemented as O_DSYNC. In applications linked to old GNU versions of the C library for old kernels, in Linux versions 2.6.33 and above, the O_SYNC flag still behaves like O_DSYNC. This is done to preserve the usual behavior of such programs. (To preserve backward binary compatibility in the 2.6.33 kernel, the O_DSYNC flag was assigned the old O_SYNC flag value, and the new O_SYNC value includes the O_DSYNC flag (on one of the machines it is 04010000 and 010000, respectively). This allows applications compiled with new header files , get in kernels released before version 2.6.33, at least the semantics of O_DSYNC.)
13.4. I / O Buffering Overview
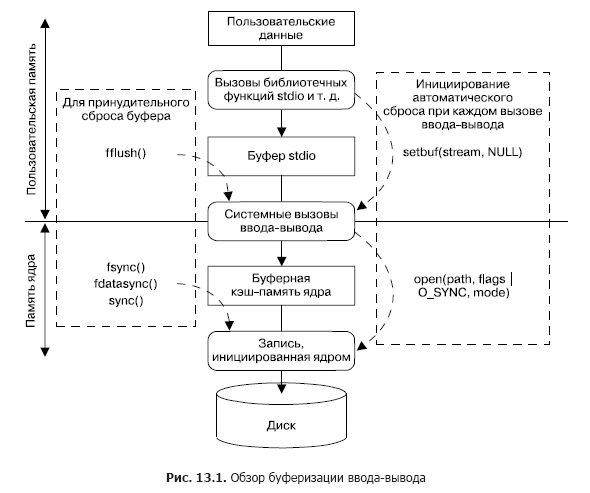
In fig. Figure 13.1 shows the buffering scheme used (for output files) by the stdio library and the kernel, and also shows the mechanisms for managing each type of buffering. If you follow the scheme down to its middle, you will see the transfer of user data by the functions of the stdio library to the stdio buffer, which works in user memory space. When this buffer is full, the stdio library resorts to the write () system call, which transfers data to the kernel's buffer cache (stored in the kernel's memory). As a result, the kernel initiates a disk operation to transfer data to disk.
In the left part of the diagram in fig. Figure 13.1 shows calls that can be used at any time to explicitly force a reset of any of the buffers. The right side shows the calls that can be used to automatically perform a reset, either by turning off buffering in the stdio library or by turning on the file output of synchronous execution mode for system calls, so that each time you write () it will immediately flush to disk.
13.5. Kernel Notification of I / O Schemes
The posix_fadvise () system call allows a process to inform the kernel about its preferred scheme for accessing file data.
The kernel can (but does not have to) use the information provided by the posix_fadvise () system call to optimize its use of the buffer cache, thereby increasing I / O performance for the process and for the system as a whole. Calling posix_fadvise () does not affect the semantics of the program.
#define _XOPEN_SOURCE 600 #include <fcntl.h> int posix_fadvise(int fd, off_t offset, off_t len, int advice); Returns 0 on success, or a positive error number when an error occurs.
The fd argument is a file descriptor that identifies the file whose calling scheme you want to inform the kernel. The arguments offset and len identify the area of the file to which the notification relates: offset indicates the initial offset of the area, and len indicates its size in bytes. The assignment to len of a value of 0 means that all bytes are meant, starting with offset and ending with the end of the file. (In kernel versions prior to 2.6.6, the value 0 for len was interpreted literally as 0 bytes.)
The advice argument shows the intended nature of the file access process. It is defined with one of the following values.
POSIX_FADV_NORMAL - The process has no special notification regarding handling patterns. This is the default behavior if no notification is given for the file. In Linux, this operation sets the window for proactive reading of data from a file to its original size (128 KB).
POSIX_FADV_SEQUENTIAL - the process involves sequential reading of data from smaller offsets to larger ones. In Linux, this operation sets the proactive data read window to double its initial value.
POSIX_FADV_RANDOM - the process involves accessing data in an arbitrary order. In Linux, this option disables the proactive reading of data from a file.
POSIX_FADV_WILLNEED - the process involves accessing the specified file area in the near future. The kernel proactively reads data to fill the buffer cache with file data in the range specified by the arguments offset and len. Subsequent read () calls to the file do not block disk I / O, but simply retrieve data from the buffer cache. The kernel does not make any guarantees about the duration of the data retrieved from the file in the buffer cache. If there is a special need for memory when another process or kernel is running, the page will eventually be reused. In other words, if the memory is in great demand, we need to guarantee a small time gap between the posix_fadvise () call and the subsequent read () call (or calls). (Functionality equivalent to the POSIX_FADV_WILLNEED operation provides the Linux-specific readahead () system call.)
POSIX_FADV_DONTNEED - the process does not imply calls to the specified file area in the near future. Thus, the kernel is notified that it can free the relevant cache pages (if any). On Linux, this operation is performed in two stages. First, if the write queue on the underlying device is not full with a series of requests, the kernel flushes any modified cache pages in the specified area. The kernel then attempts to free all cache pages from the specified area. For modified pages in this area, the second stage will be completed successfully, only if they were recorded on the basic device during the first stage, that is, the recording queue on the device is not full. Since the application cannot check the queue status on the device, you can ensure that cache pages are freed by calling fsync () or fdatasync () on the fd descriptor before using POSIX_FADV_DONTNEED.
POSIX_FADV_NOREUSE - the process involves a one-time access to the data in the specified area of the file, without re-using it. Thus, the kernel is notified that it can free up pages after a single reference to them. On Linux, this operation is currently overlooked.
The posix_fadvise () specification appeared only in SUSv3, and this interface is not supported by all UNIX implementations. On Linux, the posix_fadvise () call is provided starting with kernel version 2.6.
13.6. Bypass Buffer Cache: Direct I / O
Starting with version 2.4 of the kernel, Linux allows an application to bypass the buffer cache when performing disk I / O, moving data directly from user memory to a file or disk device. Sometimes this mode is called direct or unhandled I / O.
The information provided here applies solely to Linux and is not standardized in SUSv3. However, some direct I / O access options for devices or files are provided by most UNIX implementations.
Sometimes direct I / O is misunderstood as a means of achieving high I / O performance. But for most applications, using direct I / O can significantly reduce performance. The fact is that the kernel performs several optimizations to improve I / O performance by using buffer cache memory, including sequential data prefetching, performing I / O in clusters consisting of disk blocks, and allowing processes that access the same same file, share buffers in the cache. All these types of optimization are lost when using direct I / O. It is intended only for applications with specialized I / O requirements, for example, for database management systems that perform their own caching and I / O optimization, and which do not need the kernel to spend its CPU time and memory on performing the same tasks.
Direct I / O can be performed either with respect to a single file, or with respect to a block device (for example, a disk). To do this, when opening a file or device using the open () call, the O_DIRECT flag is specified.
The O_DIRECT flag works starting with kernel version 2.4.10. The use of this flag is not supported by all file systems and Linux kernel versions. Most basic file systems support the O_DIRECT flag, but many non-UNIX file systems (for example, VFAT) do not. You can test the support for this feature by testing the selected file system (if the file system does not support O_DIRECT, the open () call will fail with an EINVAL error) or by examining the kernel source code on this subject.
If one process opened the file with the O_DIRECT flag and the other in the usual way (that is, using the buffer cache), there is no consistency between the contents of the buffer cache and the data read or written through direct input / output. Similar developments should be avoided.
For information on the outdated (now deprecated) method for obtaining unhandled (raw) access to a disk device, see the raw (8) manual page.
Alignment restrictions for direct I / O
Since direct I / O (both on disk devices and in terms of files) implies direct access to the disk, certain limitations should be observed when performing I / O.
- the transferred data buffer should be aligned to the memory boundary, a multiple of the block size.
- The offset in the file or in the device from which the transferred data begins must be a multiple of the block size.
- the length of the transferred data must be a multiple of the block size.
Failure to comply with any of these restrictions entails an EINVAL error. In the above list, the block size refers to the physical block size of the device (usually 512 bytes).
When performing direct I / O in Linux 2.4, more restrictions are imposed than in Linux 2.6: alignment, length, and offset must be a multiple of the logical block size of the file system used. (Typically, the size of logical blocks in the file system is 1024, 2048, or 4096 bytes.)
Sample program
В листинге 13.1 предоставляется простой пример использования O_DIRECT при открытии файла для чтения. Эта программа воспринимает до четырех аргументов командной строки, указывающих (в порядке следования) файл, из которого будут считываться данные, количество считываемых из файла байтов, смещение, к которому программа должна перейти, прежде чем начать считывание данных из файла, и выравнивание буфера данных, передаваемое read(). Последние два аргумента опциональны и по умолчанию настроены соответственно на значения нулевого смещения и 4096 байт.
Рассмотрим примеры того, что будет показано при запуске программы:
$ ./direct_read /test/x 512 Считывание 512 байт со смещения 0 Read 512 bytes Успешно $ ./direct_read /test/x 256 ERROR [EINVAL Invalid argument] read Длина не кратна 512 $ ./direct_read /test/x 512 1 ERROR [EINVAL Invalid argument] read Смещение не кратно 512 $ ./direct_read /test/x 4096 8192 512 Read 4096 bytes Успешно $ ./direct_read /test/x 4096 512 256 ERROR [EINVAL Invalid argument] read Выравнивание не кратно 512 Программа в листинге 13.1 выделяет блок памяти, который выровнен по адресу, кратному ее первому аргументу, и для этого использует функцию memalign(). Функция memalign() рассматривалась в подразделе 7.1.4.
#define _GNU_SOURCE /* Получение определения O_DIRECT из <fcntl.h> */ #include <fcntl.h> #include <malloc.h> #include "tlpi_hdr.h" int main(int argc, char *argv[]) { int fd; ssize_t numRead; size_t length, alignment; off_t offset; void *buf; if (argc < 3 || strcmp(argv[1], "–help") == 0) usageErr("%s file length [offset [alignment]]\n", argv[0]); length = getLong(argv[2], GN_ANY_BASE, "length"); offset = (argc > 3) ? getLong(argv[3], GN_ANY_BASE, "offset") : 0; alignment = (argc > 4) ? getLong(argv[4], GN_ANY_BASE, "alignment") : 4096; fd = open(argv[1], O_RDONLY | O_DIRECT); if (fd == -1) errExit("open"); /* Функция memalign() выделяет блок памяти, выровненный по адресу, кратному ее первому аргументу. Следующее выражение обеспечивает выравнивание 'buf' по границе, кратной 'alignment', но не являющейся степенью двойки. Это делается для того, чтобы в случае, к примеру, запроса буфера с выравниванием, кратным 256 байтам, не происходило случайного получения буфера, выровненного также и по 512-байтовой границе. Приведение к типу '(char *)' необходимо для проведения с указателем арифметических операций (что невозможно сделать с типом 'void *', который возвращает memalign(). */ buf = (char *) memalign(alignment * 2, length + alignment) + alignment; if (buf == NULL) errExit("memalign"); if (lseek(fd, offset, SEEK_SET) == -1) errExit("lseek"); numRead = read(fd, buf, length); if (numRead == -1) errExit("read"); printf("Read %ld bytes\n", (long) numRead); exit(EXIT_SUCCESS); } _______________________________________________________________filebuff/direct_read.c » Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Linux
Source: https://habr.com/ru/post/436986/