Nlp The basics. Techniques. Self development. Part 1
Hello! My name is Ivan Smurov, and I head the NLP research team at ABBYY. About what our group does, you can read here . Recently, I gave a lecture on Natural Language Processing (NLP) at the School of Deep Learning - this is a circle at the MIPT Fiztech School of Applied Mathematics and Computer Science for high school students who are interested in programming and mathematics. Perhaps the theses of my lecture will be useful to someone, so I will share them with Habr.
Since we cannot embrace everything at once, we divide the article into two parts. Today I will talk about how neural networks (or deep learning) are used in NLP. In the second part of the article we will focus on one of the most common tasks of NLP - the task of extracting named entities (Named entity recognition, NER) and analyze in detail the architecture of its solutions.

What is NLP?
This is a wide range of tasks in natural language processing (i.e., in the language that people speak and write). There is a set of classic NLP problems, the solution of which is of practical use.
This is certainly not the entire NLP task list. There are dozens of them. By and large, everything that can be done with the text in natural language can be attributed to the tasks of NLP, just the listed topics are well known, and they have the most obvious practical applications.
Why is it difficult to solve NLP problems?
Problem statements are not very complex, but the tasks themselves are not at all simple, because we work with natural language. Phenomena of polysemy (multi-valued words have a common initial meaning) and homonymy (words that are different in meaning are pronounced and written in the same way) are characteristic of any natural language. And if a Russian carrier is well aware that in a warm reception there is little in common with a combat reception , on the one hand, and a warm beer , on the other, an automatic system has a long time to learn this. Why " Press space bar to continue " is better translated boring " To continue, press the space bar " than " Space Press Bar will continue to work ."
By the way, this year at the conference " Dialogue " tracks will be held both on the anaphor and on the gapping (a kind of ellipse) for the Russian language. For both tasks, shells were assembled with a volume several times larger than the volumes of currently existing shells (and, for gapping, the sheath volume is an order of magnitude larger than the shells not only for Russian, but generally for all languages). If you want to participate in competitions on these buildings, click here (with registration, but without SMS) .
How to solve the problems of NLP
Unlike image processing, NLP still contains articles describing solutions that use not neural networks, but classical algorithms like SVM or Xgboost , and show results that are not too inferior to state-of-the-art solutions.
However, a few years ago, the neural networks began to defeat the classic models. It is important to note that for the majority of problems, solutions based on classical methods were unique, as a rule, not similar to the solutions of other problems, both in architecture and in the way signs are collected and processed.
However, neural network architectures are much more common. The architecture of the network itself, most likely, is also different, but much less, there is a trend towards full universalization. Nevertheless, the fact with which signs and how exactly we work is almost the same for most NLP tasks. Only the last layers of neural networks are different. Thus, we can assume that a single NLP pipeline has been formed. About how it works, we now will tell more.
This way of working with signs, which is more or less the same for all tasks.
When it comes to language, the basic unit with which we work is the word. Or more formally "token". We use this term because it is not very clear what 2128506 is a word or not? The answer is not obvious. The token is usually separated from other tokens by spaces or punctuation marks. And as can be understood from the difficulties that we have described above, the context of each token is very important. There are different approaches, but in 95% of cases such a context, which is considered when the model is working, is a proposal that includes the source token.
Many problems are generally solved at the level of supply. For example, machine translation. Most often, we simply translate one sentence and do not use a broader context. There are tasks where this is not the case, for example, interactive systems. It is important to remember what the system was asked before so that it could answer questions. However, the proposal is also the basic unit with which we work.
Therefore, the first two steps of the pipeline, which are performed practically to solve any tasks, are segmentation (division of the text into sentences) and tokenization (division of sentences into tokens, that is, individual words). This is done by simple algorithms.
Next you need to calculate the signs of each token. As a rule, this occurs in two stages. The first is to calculate context-independent token attributes. This is a set of signs that do not depend on those surrounding our token in other words. Common context-independent features are:
About embeddings and symbolic signs, we will talk in detail later (about symbolic signs - not today, but in the second part of our article), but for now let us give possible examples of additional signs.
One of the most frequently used signs is a part of speech or a POS (part of speech) tag. Such signs can be important for solving many problems, for example, tasks of syntactic parsing. For languages with complex morphology, such as Russian, morphological features are also important: for example, in what case is the noun, what kind of adjective. From this we can draw different conclusions about the structure of the proposal. Also, morphology is needed for lemmatization (reduction of words to initial forms), with the help of which we can reduce the dimension of the attribute space, and therefore, morphological analysis is actively used for most NLP tasks.
When we solve the problem, where the interaction between different objects is important (for example, in the problem of relation extraction extraction or when creating a question-answer system), we need to know a lot about the structure of the sentence. This requires parsing. At school, everyone did the analysis of the sentence on the subject, predicate, addition, etc. The syntactic analysis is something like that, but more complicated.
Another example of an additional feature is the position of the token in the text. We may know a priori that an entity is more common at the beginning of the text or vice versa at the end.
All together - embeddingings, symbolic and additional signs - form a vector of signs of a token that does not depend on the context.
Context-sensitive token attributes are a feature set that contains information not only about the token itself, but also about its neighbors. There are different ways to calculate these signs. In classical algorithms, people often just went "window": they took several (for example, three) tokens to the original and several tokens after, and then calculated all the signs in that window. Such an approach is unreliable, since important information for analysis may be located at a distance greater than the window; accordingly, we may miss something.
Therefore, now all context-sensitive features are calculated at the sentence level in the standard way: using two-way recurrent neural networks LSTM or GRU. To obtain context-dependent token attributes from context-independent, context-independent features of all tokens of a sentence are submitted to the Bidirectional RNN (one or several layers). The output of the Bidirectional RNN at the i-th moment of time is a context-dependent sign of the i-th token, which contains information about both previous tokens (since this information is contained in the i-th value of the direct RNN) and about subsequent ones ( . This information is contained in the corresponding value of the inverse RNN).
Then for each individual task we do something different, but the first few layers - up to the Bidirectional RNN can be used for almost any task.
This method of obtaining features is called an NLP pipeline.
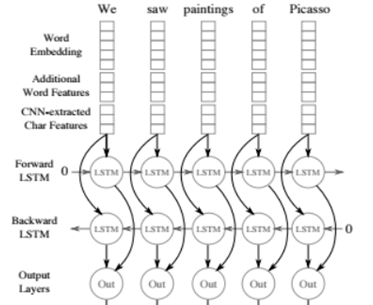
It is worth noting that in the last 2 years, researchers have been actively trying to improve the NLP pipeline - both in terms of speed (for example, a transformer - an architecture based on self-attention, does not contain an RNN and therefore is able to learn and use faster) and with points of view of used signs (now they actively use signs on the basis of pre-trained language models, for example ELMo , or use the first layers of the pre-trained language model and retrain them on the building available for the task - ULMFit , BERT ).
Word form embeddings
Let's take a closer look at what is embedding. Roughly speaking, embedding is a concise view of the context of a word. Why is it important to know the context of a word? Because we believe in the distributional hypothesis - that words of similar meaning are used in similar contexts.
Let's now try to give a strict definition of embedding. Embedding is a mapping from a discrete vector of categorical features into a continuous vector with a predetermined dimension.
A canonical example of embedding is the embedding of a word (word embedding).
What usually acts as a discrete feature vector? A Boolean vector corresponding to all possible values of a category (for example, all possible parts of speech or all possible words from some limited vocabulary).
For word form embeddings, this category is usually the word index in the dictionary. Suppose there is a dictionary with a dimension of 100 thousand. Accordingly, each word has a discrete feature vector — a boolean vector of dimension 100 thousand, where in one place (the index of the word in our dictionary) is one, and the rest are zeros.
Why do we want to display our discrete feature vectors in continuous given dimensions? Because a vector with a dimension of 100 thousand is not very convenient to use for calculations, but a vector of integer numbers of dimension 100, 200 or, for example, 300, is much more convenient.
In principle, we can not try to impose any additional restrictions on such a mapping. But since we are building such a mapping, let's try to ensure that the vectors of words of similar meaning are also in some sense close. This is done using a simple feed-forward network.
Embedding Training
How embeds are trained? We are trying to solve the problem of recovering a word by context (or vice versa, restoring context by word). In the simplest case, we get the input into the index in the dictionary of the previous word (Boolean vector of the dictionary dimension) and try to define the index in the dictionary of our word. This is done using a grid with an extremely simple architecture: two fully connected layers. First comes a fully connected layer from the Boolean vector of the dictionary dimension to the hidden layer of the embedding dimension (i.e., simply multiplying the Boolean vector by the matrix of the desired dimension). And then on the contrary, a fully connected layer with softmax from a hidden layer of embedding dimension into a vector of dictionary dimension. Thanks to the softmax activation function, we get the probability distribution of our word and can choose the most likely option.
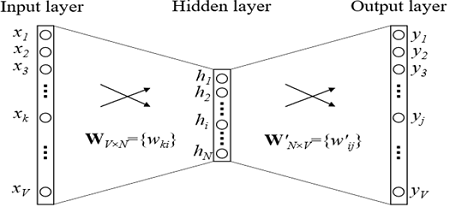
Embedding of the ith word is just the ith row in the transition matrix W.
In the models used in practice, the architecture is more complicated, but not by much. The main difference is that we use not one vector from the context to define our word, but several (for example, everything in a window of size 3). A somewhat more popular option is the situation when we are trying to predict not a word by context, but rather a context by word. This approach is called Skip-gram.
Let's give an example of the application of a problem that is solved during embedding training (in the variant of CBOW - prediction of a word in context). For example, let the token context consist of 2 previous words. If we studied on the corpus of texts about modern Russian literature and the context consists of the words “poet Marina”, then most likely the most likely next word will be the word “Tsvetaeva”.
We emphasize once again, embeddings are only trained in the task of predicting a word by context (or vice versa by the word), and they can be used in any situations where we need to calculate the token feature.
Whichever option we choose, the embedding architecture is very simple, and their big plus is that they can be trained on unallocated data (indeed, we only use information about our token’s neighbors, and only the text itself is used to define them). The resulting embeddings are the averaged context for exactly this body.
Embeddings of word forms, as a rule, are trained in the case that is as large and accessible for training. Usually this is all Wikipedia in the language, because you can deflate it all, and any other corps you can get.
Similar considerations are used in pre-learning for the modern architectures mentioned above - ELMo, ULMFit, BERT. They also use unpartitioned data when training, and therefore they study on the largest available case (although the architects themselves are, of course, more complicated than those of classical embeddings).
Why do we need embeddings?
As already mentioned, there are 2 main reasons for using embeddingings.
But one should not think that such vector arithmetic works reliably. In the article where the embeddings were introduced, there were examples that Angela treats Merkel in much the same way as Barack towards Obama, Nicolas towards Sarkozy and Putin towards Medvedev. Therefore, relying on this arithmetic is not worth it, although it is still important, and the computer is much easier when it knows this information, even if it contains inaccuracies.
In the next part of this article we will talk about the NER task. We will talk about what the task is, why it is needed and what pitfalls can be hidden in its solution. We will tell in detail about how this problem was solved using classical methods, how it was solved using neural networks, and we describe the modern architectures created to solve it.
Since we cannot embrace everything at once, we divide the article into two parts. Today I will talk about how neural networks (or deep learning) are used in NLP. In the second part of the article we will focus on one of the most common tasks of NLP - the task of extracting named entities (Named entity recognition, NER) and analyze in detail the architecture of its solutions.
What is NLP?
This is a wide range of tasks in natural language processing (i.e., in the language that people speak and write). There is a set of classic NLP problems, the solution of which is of practical use.
- The first and most historically important task is machine translation. She is engaged in a very long time, and there is a huge progress. But the task of obtaining a fully automatic translation of high quality (FAHQMT) remains unsolved. In a sense, this is an NLP engine, one of the biggest tasks to do.

- The second task is the classification of texts. A set of texts is given, and the task is to classify these texts into categories. How? This is a question for the body.
The first and one of the most important practical applications is the classification of letters into spam and ham (not spam).
Another classic option is a multi-class classification of news by category (rubrication) - foreign policy, sports, big top, etc. Or, say, you receive letters, and you want to separate orders from the online store from air tickets and hotel reservations.
The third classic version of the application of the text classification problem is sentimental analysis. For example, the classification of reviews for positive, negative and neutral.
Since there are a lot of possible categories that can be divided into texts, text classification is one of the most popular practical tasks of NLP. - The third task is to retrieve the named entities, NER. We select areas in the text that correspond to a pre-selected set of entities, for example, all locations, persons and organizations should be found in the text. In the text “Ostap Bender is the director of the“ Horns and Hoofs ”office”, you should understand that Ostap Bender is a person, and “Horns and Hoofs” is an organization. Why this task is needed in practice and how to solve it, we will talk in the second part of this article.
 The third task is related to the fourth - the task of extracting facts and relationships (relation extraction). For example, there is an attitude of work (Occupation). From the text “Ostap Bender - director of the office“ Horns and Hoofs ”” it is clear that our hero is connected with professional relations with “Horns and Hooves”. The same can be said in many other ways: “The office of“ Horns and Hoof ”is headed by Ostap Bender”, or “Ostap Bender has gone from the simple son of Lieutenant Schmidt to the head of the office of“ Horns and Hoof ””. These sentences differ not only in predicate, but also in structure.
The third task is related to the fourth - the task of extracting facts and relationships (relation extraction). For example, there is an attitude of work (Occupation). From the text “Ostap Bender - director of the office“ Horns and Hoofs ”” it is clear that our hero is connected with professional relations with “Horns and Hooves”. The same can be said in many other ways: “The office of“ Horns and Hoof ”is headed by Ostap Bender”, or “Ostap Bender has gone from the simple son of Lieutenant Schmidt to the head of the office of“ Horns and Hoof ””. These sentences differ not only in predicate, but also in structure.
Examples of other frequently distinguished relationships are the purchase and sale (Purchase and Sale), Ownership relations, the fact of birth with attributes - date, place, etc. (Birth) and some others.
The task seems to have no obvious practical application, but, nevertheless, it is used in the structuring of unstructured information. In addition, it is important in question-answer and conversational systems, in search engines - whenever you need to analyze a question and understand what type it is, as well as what restrictions are on the answer.
- The next two tasks are probably the most hyip. These are question-answer and interactive systems (chat bots). Amazon Alexa, Alice - these are classic examples of conversational systems. In order for them to work properly, many NLP tasks must be solved. For example, textual classification helps determine whether we are in one of the scenarios of a goal-oriented chat bot. Suppose, "the question of exchange rates." Relation extraction is needed to define the placeholders for the script template, and the task of conducting a dialogue on common topics (“talkers”) will help us in a situation where we did not fall into any of the scenarios.
Question-answer systems are also an understandable and useful thing. You ask the machine a question, the machine is looking for an answer to it in the database or the body of texts. Examples of such systems are IBM Watson or Wolfram Alpha. - Another example of the classic NLP task is self-freezing. The formulation of the problem is simple - the system accepts large-sized text as input, and the output is a smaller text that somehow reflects the content of a large one. For example, the machine is required to generate a retelling of the text, its name or annotation.

- Another popular task is argumentation mining, the search for justification in the text. You are given a fact and a text; you need to find a justification for this fact in the text.
This is certainly not the entire NLP task list. There are dozens of them. By and large, everything that can be done with the text in natural language can be attributed to the tasks of NLP, just the listed topics are well known, and they have the most obvious practical applications.
Why is it difficult to solve NLP problems?
Problem statements are not very complex, but the tasks themselves are not at all simple, because we work with natural language. Phenomena of polysemy (multi-valued words have a common initial meaning) and homonymy (words that are different in meaning are pronounced and written in the same way) are characteristic of any natural language. And if a Russian carrier is well aware that in a warm reception there is little in common with a combat reception , on the one hand, and a warm beer , on the other, an automatic system has a long time to learn this. Why " Press space bar to continue " is better translated boring " To continue, press the space bar " than " Space Press Bar will continue to work ."
- Polysemy: stop (process or building), table (organization or object), woodpecker (bird or person).
- Homology: key, bow, lock, oven.

- Another classic example of language complexity is the pronominal anaphora. For example, suppose we are given the text “ Janitor for two hours of snow and snow, he was unhappy .” The pronoun "he" can refer to both the janitor and snow. By context, we easily understand that he is a janitor, not snow. But to ensure that the computer is also easy to understand is not easy. The task of the pronoun anaphor is not well solved even now, active attempts to improve the quality of the solutions are continuing.
- Another additional difficulty is ellipse. For example, “ Peter ate a green apple, and Masha a red one .” We understand that Masha ate a red apple. However, getting the car to understand this too is not easy. Now the task of restoring an ellipse is solved on tiny shells (several hundred sentences), and the quality of complete recovery is frankly weak (about 0.5). It is clear that for practical applications such quality is no good.
By the way, this year at the conference " Dialogue " tracks will be held both on the anaphor and on the gapping (a kind of ellipse) for the Russian language. For both tasks, shells were assembled with a volume several times larger than the volumes of currently existing shells (and, for gapping, the sheath volume is an order of magnitude larger than the shells not only for Russian, but generally for all languages). If you want to participate in competitions on these buildings, click here (with registration, but without SMS) .
How to solve the problems of NLP
Unlike image processing, NLP still contains articles describing solutions that use not neural networks, but classical algorithms like SVM or Xgboost , and show results that are not too inferior to state-of-the-art solutions.
However, a few years ago, the neural networks began to defeat the classic models. It is important to note that for the majority of problems, solutions based on classical methods were unique, as a rule, not similar to the solutions of other problems, both in architecture and in the way signs are collected and processed.
However, neural network architectures are much more common. The architecture of the network itself, most likely, is also different, but much less, there is a trend towards full universalization. Nevertheless, the fact with which signs and how exactly we work is almost the same for most NLP tasks. Only the last layers of neural networks are different. Thus, we can assume that a single NLP pipeline has been formed. About how it works, we now will tell more.
Pipeline NLP
This way of working with signs, which is more or less the same for all tasks.
When it comes to language, the basic unit with which we work is the word. Or more formally "token". We use this term because it is not very clear what 2128506 is a word or not? The answer is not obvious. The token is usually separated from other tokens by spaces or punctuation marks. And as can be understood from the difficulties that we have described above, the context of each token is very important. There are different approaches, but in 95% of cases such a context, which is considered when the model is working, is a proposal that includes the source token.
Many problems are generally solved at the level of supply. For example, machine translation. Most often, we simply translate one sentence and do not use a broader context. There are tasks where this is not the case, for example, interactive systems. It is important to remember what the system was asked before so that it could answer questions. However, the proposal is also the basic unit with which we work.
Therefore, the first two steps of the pipeline, which are performed practically to solve any tasks, are segmentation (division of the text into sentences) and tokenization (division of sentences into tokens, that is, individual words). This is done by simple algorithms.
Next you need to calculate the signs of each token. As a rule, this occurs in two stages. The first is to calculate context-independent token attributes. This is a set of signs that do not depend on those surrounding our token in other words. Common context-independent features are:
- embeddings
- character signs
- additional features specific to a particular task or language
About embeddings and symbolic signs, we will talk in detail later (about symbolic signs - not today, but in the second part of our article), but for now let us give possible examples of additional signs.
One of the most frequently used signs is a part of speech or a POS (part of speech) tag. Such signs can be important for solving many problems, for example, tasks of syntactic parsing. For languages with complex morphology, such as Russian, morphological features are also important: for example, in what case is the noun, what kind of adjective. From this we can draw different conclusions about the structure of the proposal. Also, morphology is needed for lemmatization (reduction of words to initial forms), with the help of which we can reduce the dimension of the attribute space, and therefore, morphological analysis is actively used for most NLP tasks.
When we solve the problem, where the interaction between different objects is important (for example, in the problem of relation extraction extraction or when creating a question-answer system), we need to know a lot about the structure of the sentence. This requires parsing. At school, everyone did the analysis of the sentence on the subject, predicate, addition, etc. The syntactic analysis is something like that, but more complicated.
Another example of an additional feature is the position of the token in the text. We may know a priori that an entity is more common at the beginning of the text or vice versa at the end.
All together - embeddingings, symbolic and additional signs - form a vector of signs of a token that does not depend on the context.
Context-sensitive features
Context-sensitive token attributes are a feature set that contains information not only about the token itself, but also about its neighbors. There are different ways to calculate these signs. In classical algorithms, people often just went "window": they took several (for example, three) tokens to the original and several tokens after, and then calculated all the signs in that window. Such an approach is unreliable, since important information for analysis may be located at a distance greater than the window; accordingly, we may miss something.
Therefore, now all context-sensitive features are calculated at the sentence level in the standard way: using two-way recurrent neural networks LSTM or GRU. To obtain context-dependent token attributes from context-independent, context-independent features of all tokens of a sentence are submitted to the Bidirectional RNN (one or several layers). The output of the Bidirectional RNN at the i-th moment of time is a context-dependent sign of the i-th token, which contains information about both previous tokens (since this information is contained in the i-th value of the direct RNN) and about subsequent ones ( . This information is contained in the corresponding value of the inverse RNN).
Then for each individual task we do something different, but the first few layers - up to the Bidirectional RNN can be used for almost any task.
This method of obtaining features is called an NLP pipeline.
It is worth noting that in the last 2 years, researchers have been actively trying to improve the NLP pipeline - both in terms of speed (for example, a transformer - an architecture based on self-attention, does not contain an RNN and therefore is able to learn and use faster) and with points of view of used signs (now they actively use signs on the basis of pre-trained language models, for example ELMo , or use the first layers of the pre-trained language model and retrain them on the building available for the task - ULMFit , BERT ).
Word form embeddings
Let's take a closer look at what is embedding. Roughly speaking, embedding is a concise view of the context of a word. Why is it important to know the context of a word? Because we believe in the distributional hypothesis - that words of similar meaning are used in similar contexts.
Let's now try to give a strict definition of embedding. Embedding is a mapping from a discrete vector of categorical features into a continuous vector with a predetermined dimension.
A canonical example of embedding is the embedding of a word (word embedding).
What usually acts as a discrete feature vector? A Boolean vector corresponding to all possible values of a category (for example, all possible parts of speech or all possible words from some limited vocabulary).
For word form embeddings, this category is usually the word index in the dictionary. Suppose there is a dictionary with a dimension of 100 thousand. Accordingly, each word has a discrete feature vector — a boolean vector of dimension 100 thousand, where in one place (the index of the word in our dictionary) is one, and the rest are zeros.
Why do we want to display our discrete feature vectors in continuous given dimensions? Because a vector with a dimension of 100 thousand is not very convenient to use for calculations, but a vector of integer numbers of dimension 100, 200 or, for example, 300, is much more convenient.
In principle, we can not try to impose any additional restrictions on such a mapping. But since we are building such a mapping, let's try to ensure that the vectors of words of similar meaning are also in some sense close. This is done using a simple feed-forward network.
Embedding Training
How embeds are trained? We are trying to solve the problem of recovering a word by context (or vice versa, restoring context by word). In the simplest case, we get the input into the index in the dictionary of the previous word (Boolean vector of the dictionary dimension) and try to define the index in the dictionary of our word. This is done using a grid with an extremely simple architecture: two fully connected layers. First comes a fully connected layer from the Boolean vector of the dictionary dimension to the hidden layer of the embedding dimension (i.e., simply multiplying the Boolean vector by the matrix of the desired dimension). And then on the contrary, a fully connected layer with softmax from a hidden layer of embedding dimension into a vector of dictionary dimension. Thanks to the softmax activation function, we get the probability distribution of our word and can choose the most likely option.
Embedding of the ith word is just the ith row in the transition matrix W.
In the models used in practice, the architecture is more complicated, but not by much. The main difference is that we use not one vector from the context to define our word, but several (for example, everything in a window of size 3). A somewhat more popular option is the situation when we are trying to predict not a word by context, but rather a context by word. This approach is called Skip-gram.
Let's give an example of the application of a problem that is solved during embedding training (in the variant of CBOW - prediction of a word in context). For example, let the token context consist of 2 previous words. If we studied on the corpus of texts about modern Russian literature and the context consists of the words “poet Marina”, then most likely the most likely next word will be the word “Tsvetaeva”.
We emphasize once again, embeddings are only trained in the task of predicting a word by context (or vice versa by the word), and they can be used in any situations where we need to calculate the token feature.
Whichever option we choose, the embedding architecture is very simple, and their big plus is that they can be trained on unallocated data (indeed, we only use information about our token’s neighbors, and only the text itself is used to define them). The resulting embeddings are the averaged context for exactly this body.
Embeddings of word forms, as a rule, are trained in the case that is as large and accessible for training. Usually this is all Wikipedia in the language, because you can deflate it all, and any other corps you can get.
Similar considerations are used in pre-learning for the modern architectures mentioned above - ELMo, ULMFit, BERT. They also use unpartitioned data when training, and therefore they study on the largest available case (although the architects themselves are, of course, more complicated than those of classical embeddings).
Why do we need embeddings?
As already mentioned, there are 2 main reasons for using embeddingings.
- First, we reduce the dimension of the feature space, because it is much more convenient to work with continuous vectors of several hundreds in dimension than with 100 thousand signs of Boolean vectors. Reducing the dimensionality of the attribute space is very important: it affects the speed, it is more convenient for learning, and therefore the algorithms learn better.
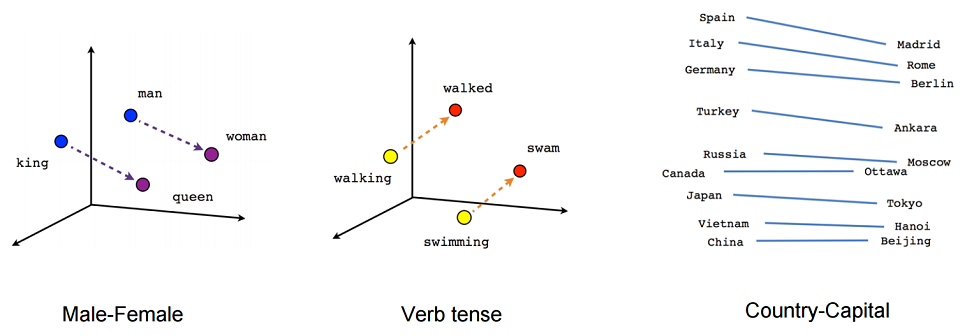
- Secondly, taking into account the proximity of elements in the original space. Words resemble each other in different ways. And different embedding coordinates are able to catch this similarity. I will cite a simple, rough and hackneyed example. Embedding is quite capable of detecting that a king is different from a queen in much the same way as a man is from a woman. Or vice versa, the king is different from a man, like a queen from a woman. The connections of different countries with their capitals are similarly similar. A well-trained model on a large enough case is able to understand that Moscow is different from Russia in the same way that Washington is from the United States.
But one should not think that such vector arithmetic works reliably. In the article where the embeddings were introduced, there were examples that Angela treats Merkel in much the same way as Barack towards Obama, Nicolas towards Sarkozy and Putin towards Medvedev. Therefore, relying on this arithmetic is not worth it, although it is still important, and the computer is much easier when it knows this information, even if it contains inaccuracies.
In the next part of this article we will talk about the NER task. We will talk about what the task is, why it is needed and what pitfalls can be hidden in its solution. We will tell in detail about how this problem was solved using classical methods, how it was solved using neural networks, and we describe the modern architectures created to solve it.
Source: https://habr.com/ru/post/437008/