What is wrong with reinforcement learning (Reinforcement Learning)?

Back in the beginning of 2018, the Deep Reinforcement Learning Doesn't Work Yet article was published (" Reinforcement Training Doesn't Work Yet "). The main complaint of which was reduced to the fact that modern learning algorithms with reinforcement require approximately the same time to solve a problem as a normal random search.
Has anything changed since that time? Not.
Reinforcement training is considered one of the three main ways to build a strong AI. But the difficulties faced by this area of machine learning, and the methods by which scientists are trying to deal with these difficulties, suggest that, perhaps with the very approach, there are fundamental problems.
Wait, what does one of the three mean? And the other two are what?
Given the success of neural networks in recent years and an analysis of how they work with high-level cognitive abilities, previously considered characteristic only of humans and higher animals, today the scientific community has the opinion that there are three main approaches to creating a strong AI on based on neural networks that can be considered less realistic:
1. Text processing
The world has accumulated a huge number of books and text on the Internet, including textbooks and reference books. The text is convenient and fast for processing on the computer. Theoretically, this array of texts should be enough for learning a strong conversational AI.
In this case, it is implied that these text arrays reflect the complete structure of the world (at a minimum, it is described in textbooks and reference books). But this is absolutely not a fact. Texts as a type of representation of information are strongly separated from the real three-dimensional world and the flow of time in which we live.
Good examples of AI trained in text arrays are chat bots and automatic translators. Since the translation of the text you need to understand the meaning of the phrase and retell it with new words (in another language). There is a common misconception that the rules of grammar and syntax, including the description of all possible exceptions, completely describe a specific language. This is not true. Language is only an auxiliary tool in life, it changes easily and adapts to new situations.
The problem of word processing (even with expert systems, even with neural networks) is that there is no set of rules for which phrases in which situations to apply. Pay attention - not the rules for constructing the phrases themselves (what the grammar and syntax do), but exactly which phrases in which life situations. In the same situation, people pronounce phrases in different languages that are not related to each other at all in terms of the structure of the language. Compare phrases with extreme astonishment: "oh my God!" and "o, holy shit!". Well, and how between them to hold the correspondence, knowing the language model? Yes, nothing. It so happened historically. You need to know the situation and what is usually spoken in a particular language. It is precisely because of this that automatic translators are so imperfect.
Whether it is possible to isolate this knowledge purely from an array of texts is unknown. But if automatic translators start to translate perfectly, without making silly and ridiculous mistakes, then this will be proof that creating a strong AI based on text alone is possible.
2. Image recognition
Look at this image

Looking at this photo, we understand that the shooting was done at night. Judging by the flags, the wind blows from right to left. And judging by the right-hand traffic, the case does not occur in England or Australia. None of this information is explicitly indicated in the pixels of the picture, it is external knowledge. In the photo there are only signs on which we can use the knowledge obtained from other sources.
About that and speech ... And find yourself a girl, finally
Therefore, it is believed that if you train a neural network to recognize objects in the picture, then it will form an internal idea of how the real world works. And this view, obtained from photographs, will surely correspond to our real and real world. Unlike text arrays, where this is not guaranteed.
The value of neural networks trained on the ImageNet photo array (and now OpenImages V4 , COCO , KITTI , BDD100K, and others) is not at all in the fact of recognition of the cat in the photo. And that is stored in the penultimate layer. It is there that is a set of high-level features that describe our world. A vector of 1024 numbers is enough to get a description of 1000 different categories of objects with 80% accuracy (and in 95% of cases the correct answer will be in the 5 closest variants). Just think about it.
That is why these features from the penultimate layer are so successfully used in completely different tasks in computer vision. Through Transfer Learning and Fine Tuning. From this vector in 1024 numbers you can get, for example, a depth map for the picture
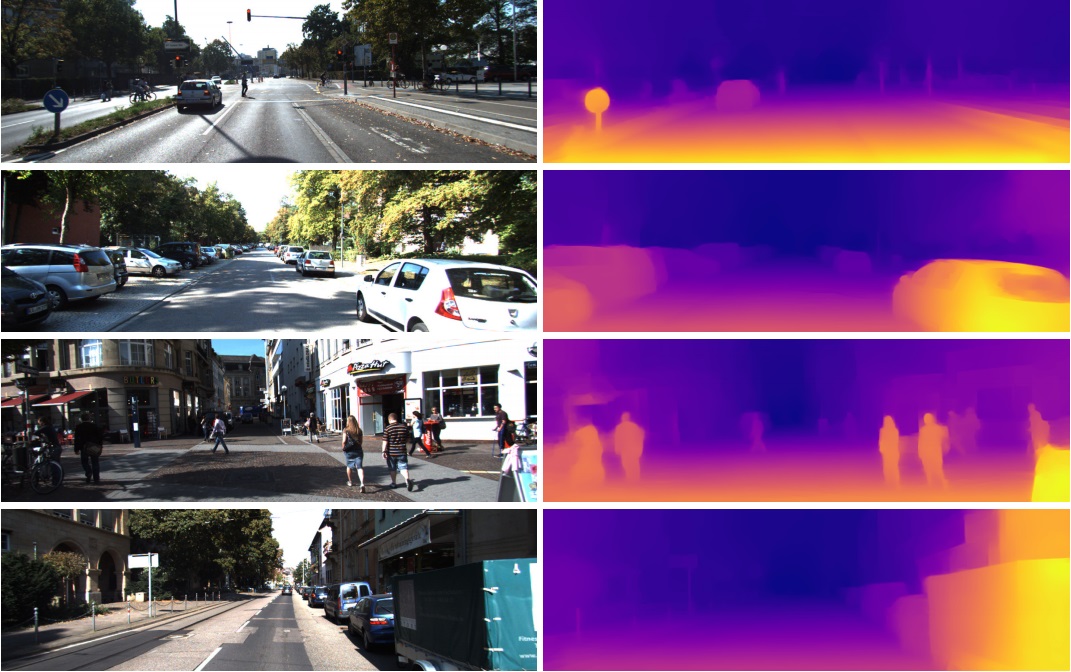
(example from the work where the practically unchanged pre-trained network Densenet-169 is used)
Or determine the posture of the person. There are many applications.
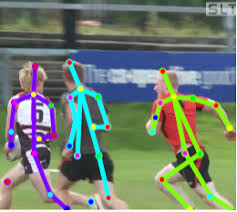
As a consequence, image recognition can potentially be used to create a strong AI, as it truly reflects the model of our real world. From photography to video is one step, and video is our life, since we receive about 99% of the information visually.
But the photograph is completely incomprehensible how to motivate the neural network to think and draw conclusions. She can be trained to answer questions like "how many pencils are on the table?" (this class of tasks is called Visual Question Answering, an example of such a dataset: https://visualqa.org ). Or give a text description of what is happening in the photo. This is the Image Captioning class of tasks.

But is this an intelligence? Having developed this approach, in the near future, neural networks will be able to answer video questions like "Two sparrows sat on wires, one of them flew away, how many sparrows left?". This is already real mathematics, in slightly more complicated cases inaccessible to animals and located at the level of human school education. Especially if, apart from sparrows, there will be titmouses sitting next to them, but they should not be taken into account, since the question was only about sparrows. Yes, it will definitely be intelligence.
3. Reinforcement Learning
The idea is very simple: to encourage actions that lead to reward, and to avoid leading to failure. This is a universal way of learning and, obviously, it can definitely lead to the creation of a strong AI. Therefore, to Reinforcement Learning such a great interest in recent years.
Of course, it is best to create a strong AI by combining all three approaches. The pictures and training with reinforcements can be obtained AI level of animals. And by adding text names of objects to pictures (joking, of course, by forcing AI to watch videos where people interact and talk, as when teaching a baby), and after training on a text array to get knowledge (analog of our school and university), in theory you can get AI human level. Able to talk.
Reinforcement training has one big plus. In the simulator, you can create a simplified model of the world. So, for a human figure, only 17 degrees of freedom are sufficient, instead of 700 in a living person (approximate number of muscles). Therefore, in the simulator, you can solve the problem in a very small dimension.
Looking ahead, modern Reinforcement Learning algorithms are not capable of arbitrarily controlling a person’s model, even with 17 degrees of freedom. That is, they cannot solve the optimization problem, where the input numbers are 44 and the output 17. It can only be done in very simple cases, with fine manual adjustment of the initial conditions and hyperparameters. And even in this case, for example, to teach a humanoid model with 17 degrees of freedom to run, and starting from a standing position (which is much simpler), you need several days of calculations on a powerful GPU. A little more complicated cases, such as learning how to get up from an arbitrary pose, can never learn at all. This is a failure.
In addition, all Reinforcement Learning algorithms work with disappointingly small neural networks, and with large learning can not cope. Large convolutional networks are used only to reduce the dimension of the picture to a few features, which are fed to the input of learning algorithms with reinforcement. The same running humanoid is controlled by a Feed Forward network with two or three layers of 128 neurons each. Seriously? And based on this, are we trying to build a strong AI?
To try to understand why this is happening and what is wrong with reinforcement training, you must first familiarize yourself with the main architectures in modern Reinforcement Learning.
The physical structure of the brain and nervous system is tuned by evolution to a specific animal species and its habitat conditions. Thus, in the process of evolution, a fly developed such a nervous system and such work of neurotransmitters in the ganglia (analogous to the brain in insects) in order to quickly dodge the fly swatter. Well, not from a fly swatter, but from birds that caught them 400 million years (joke, the birds themselves appeared 150 million years ago, rather from frogs 360 million years). And the rhinoceros has enough of such a nervous system and brain to slowly turn towards the goal and start running. And there, as they say, the rhino has poor eyesight, but these are not his problems.
But besides evolution, it is the usual mechanism of reinforcement learning that works for each individual individual, starting at birth and throughout life. In the case of mammals and insects, too , this work is done by the dopamine system. Her work is full of secrets and nuances, but it all comes down to the fact that in the case of receiving an award, the dopamine system, through memory mechanisms, somehow fixes the connections between neurons that were active just before. This is how the associative memory is formed.
Which, by virtue of its associativity, is then used in decision making. Simply put, if the current situation (the current active neurons in this situation) activate the neurons of the memory of pleasure by associative memory, then the individual chooses the actions that she did in a similar situation and which she remembered. "Choosing actions" is a bad definition. No choice. Simply activated neurons of the memory of pleasure, fixed by the dopamine system for this situation, automatically activate the motor neurons, leading to muscle contraction. This is if immediate action is needed.
Artificial learning with reinforcement, as a field of knowledge, needs to solve both of these tasks:
1. Choose the neural network architecture (which evolution has already done for us)
The good news is that the higher cognitive functions performed in the neocortex in mammals (and in the corpus striatum of corvids ) are performed in an approximately homogeneous structure. Apparently, this does not need some kind of rigidly prescribed "architecture".
The diversity of brain areas is probably due to purely historical reasons. When, as evolution progressed, new parts of the brain grew on top of the base ones left over from the very first animals. By the principle works - do not touch. On the other hand, in different people, the same parts of the brain react to the same situations. This can be explained both by associativity (features and "grandmother's neurons" naturally formed in these places in the learning process) and by physiology. That the signal paths encoded in the genes lead precisely to these areas. There is no consensus here, but you can read, for example, this recent article: "Biological and artificial intelligence" .
2. Learn to teach neural networks on the principles of learning with reinforcement
This is precisely what modern Reinforcement Learning is doing. And what is the success? Not really.
Naive approach
It would seem that it is very simple to train a neural network with reinforcements: we do random actions, and if we receive an award, we consider the actions made as “reference”. We put them on the output of the neural network as standard labels and train the neural network using the method of back propagation of an error, so that it would give just such an output. Well, the most common learning neural network. And if actions lead to failure, then either we ignore this case, or we suppress these actions (we put some others as a reference at the output, for example, any other random action). In general, this idea repeats the dopamine system.
But if you try to train any neural network in this way, no matter how complex the architecture is, recurrent, convolutional, or regular direct propagation, then ... It won't work!
Why? Unknown.
It is believed that the useful signal is so small that it is lost against the background of noise. Therefore, the network does not learn the standard back propagation method. Reward happens very rarely, maybe once out of hundreds or even thousands of steps. And even LSTM remembers a maximum of 100-500 points of history, and then only in very simple tasks. And on more complex ones, if there are 10-20 points of history, then this is already good.
But the root of the problem is in very rare rewards (at least in tasks of practical value). At the moment, we are not able to train neural networks that would memorize isolated cases. What the brain copes with shine. You can remember something just once, remember for a lifetime. And, by the way, most of the training and work of the intellect is based on such cases.
This is something like a terrible imbalance of classes from the field of image recognition. There is simply no way to deal with this. The best that we could come up with so far is simply to submit to the input of the network along with new situations, successful situations from the past saved in an artificial special buffer. That is, constantly teach not only new cases, but also successful old ones. Naturally, it is impossible to infinitely increase such a buffer, and it is not clear what exactly to store in it. They are still trying to fix the paths within the neural network for some time, which were active during the successful event so that the subsequent training would not overwrite them. A rather close analogy to what is happening in the brain, in my opinion, although we have not yet achieved much success in this direction either. Since the new trained tasks in their calculation use the results of the output of neurons from the frozen paths, as a result, the signal only over these frozen interferes with the new ones, and the old tasks stop working. There is another interesting approach: to teach the network new examples / tasks only in the orthogonal direction to the previous tasks ( https://arxiv.org/abs/1810.01256 ). This does not overwrite previous experience, but drastically limits network capacity.
A separate class of algorithms designed to deal with this disaster (and at the same time giving hope to achieve a strong AI), are being developed in Meta-Learning. These are attempts to teach a neural network several tasks at once. Not in the sense of recognizing different pictures in the same task, namely, different tasks in different domains (each with its own distribution and landscape of solutions). Say, recognize pictures and simultaneously ride a bike. Successes are not very good either, as it usually all comes down to preparing a neural network with common universal weights in advance, and then quickly, in just a few steps of a gradient descent, to adapt them to a specific task. Examples of meta-learning algorithms are MAML and Reptile .
In general, only this problem (the inability to learn from single successful examples) puts an end to modern training with reinforcement. All the power of neural networks before this sad fact is powerless.
This fact that the easiest and most obvious way does not work, forced the researchers to return to the classic tabular Reinforcement Learning. Which as a science appeared in antiquity, when neural networks were not even in the project. But now, instead of manually counting the values in the tables and in the formulas, let's use such a powerful approximator as neural networks as target functions! This is the essence of modern Reinforcement Learning. And its main difference from the usual learning neural networks.
Q-learning and DQN
Reinforcement Learning (even before neural networks) was born as a fairly simple and original idea: let's do, again, random actions, and then for each cell in the table and each direction of movement, we calculate using a special formula (called Bellman’s equation, you’ll be to meet in virtually every training activity with reinforcement) how good this cell and the chosen direction are. The higher this number is, the more likely this path leads to victory.
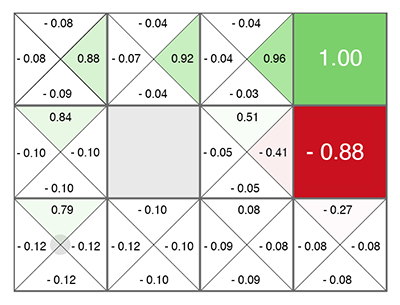
Whatever cell you are in, move upwards in green! (towards the maximum number on the sides of the current cell).
This number is called Q (from the word quality is the quality of choice, obviously), and the method is Q-learning. Replacing the formula for calculating this number on a neural network, or rather, teaching the neural network using this formula (plus a couple of tricks related purely to the math of learning neural networks), Deepmind obtained the DQN method. This is which in 2015 won the Atari pile of games and marked the beginning of a revolution in Deep Reinforcement Learning.
Unfortunately, this method in its architecture only works with discrete discrete actions. In DQN, the current state (current situation) is fed to the input of the neural network, and the neural network predicts the Q number at the output. And since all the possible actions are listed at the output of the network (each with its predicted Q), it turns out that the neural network in DQN implements the classic Q function (s, a) from Q-learning. Returns Q for state and action (therefore, Q (s, a) as a function of s and a). We are simply looking for the usual argmax by array among the network outputs of the cell with the maximum number Q and do the action that corresponds to the index of this cell.
And you can always choose an action with a maximum Q, then this policy will be called deterministic. And you can choose an action as random from the available ones, but in proportion to their Q-values (that is, actions with high Q will be chosen more often than with low). This policy is called stochastic. The stochastic choice plus is that the search and exploration of the world is automatically realized (Exploration), since each time different actions are selected, sometimes not seemingly the most optimal, but which can lead to a big reward in the future. And then we will learn and increase the probability of these actions, so that now they are more often chosen according to their probability.
But what if options are endless? If this is not the 5 buttons on the joystick in Atari, but the continuous torque control of the robot engine? Of course, the moment in the range -1..1 can be divided into subranges of 0.1, and at each moment of time you can choose one of these subranges, like pressing a joystick in Atari. But not always the right number can be discretized at intervals. Imagine that you are riding a bike through a mountain peak. And you can only turn the steering wheel 10 degrees left or right. At some point, the peak may become so narrow that turning 10 degrees in both directions will result in a fall. This is the fundamental problem of discrete actions. Moreover, DQN does not work with large dimensions, and even with 17 degrees of freedom it simply does not converge on a robot. Everything is good, but there is a small nuance, as they say.
Later, many original and sometimes ingenious algorithms based on DQN were developed, which allowed, among other things, to work with continuous actions (due to tricks and introduction of additional neural networks): DDQN, DuDQN, BDQN, CDQN, NAF, Rainbow. Perhaps, here you can also include Direct Future Prediction (DFP) , which is related to the DQN network architecture and discrete actions. Instead of predicting the Q number for all actions, DFP directly predicts how much health or ammo will be in the next step if you choose this action. And one step forward and several steps forward. We can only go through all the network outputs and find the maximum value of the parameter of interest to us and choose the appropriate action for this element of the array, depending on current priorities. For example, if we are injured, we can look for an action among the exits of the network leading to the maximum increase in health.
But more importantly, in the ensuing time, new architectures were developed specifically for Reinforcement Learning.
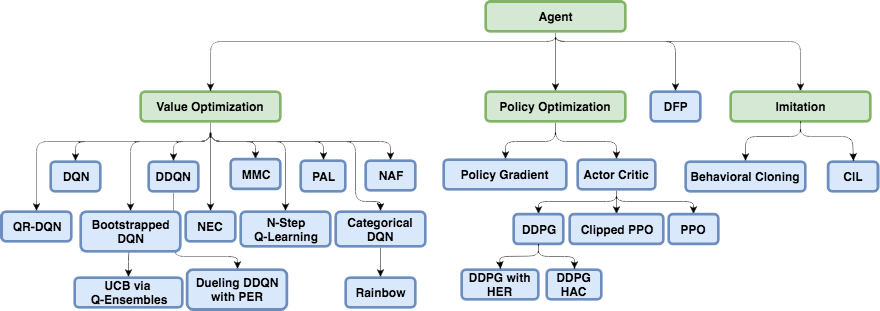
Policy gradient
Let's input the current state to the network input, and immediately predict actions at the output (either the actions themselves or the probability distribution for them in a stochastic policy). We simply act using actions predicted by the neural network. And then we look, what reward R has typed for an episode. This award can be either higher than the initial (when won in the game) or lower (lost in the game). You can also compare the reward with a certain average reward. Above it is average or lower.
Actually, the dynamics of the received award R as a result of actions that the neural network prompted can be used to calculate the gradient using a special formula. And apply this gradient to the weights of the neural network! And then use the usual reverse error propagation. Simply, instead of "reference" actions at the exit of the network as labels (we do not know what they should be), we use the change of the reward to calculate the gradient. According to this gradient, the network will learn to predict actions that lead to an increase in the R award.
This is a classic policy gradient. But he has a drawback - you have to wait until the end of the episode to calculate the cumulative reward R before changing the weights of the network according to its change. And of the advantages - a flexible system of rewards and punishments, which not only works in both directions, but also depends on the size of the reward. A big reward more strongly encourages the actions that led to it.
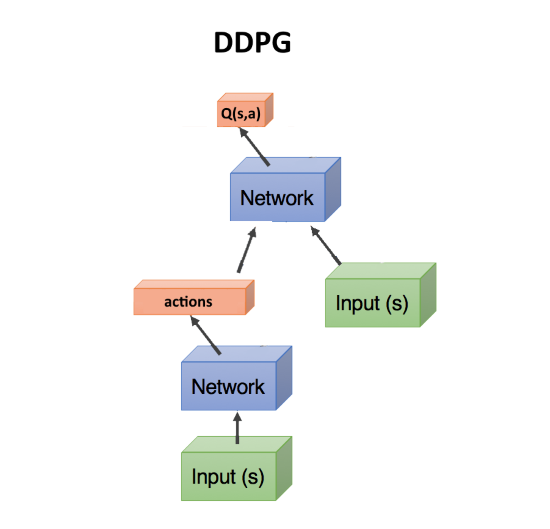
Actor-critic, DDPG
Now imagine that we have two networks - one predicts what actions to take, and the second assesses how good these actions are. That is, it gives a Q-number for these actions, as in the DQN algorithm. The state is fed to the input of the first network, and it predicts action (s). The second network also receives state at the input, but also the action actions predicted by the first network, and the output gives the number Q as a function of both of them: Q (s, a).
Actually, this number Q (s, a), issued by the second network (it is called a critic, critic), can also be used to calculate the gradient, which updates the weights of the first network (which is called an actor), as we did above with the award R Well, the second network is updated in the usual way, according to the actual passage of the episode. This method is called actor-critic. Its plus in comparison with the classical Policy Gradient, that the weights of the network can be updated at each step, without waiting for the end of the episode. What speeds up learning.
As such, it is a DDPG network. Since it directly predicts the actions of actions, it works great with continuous actions. DDPG is a direct continuous competitor of DQN with its discrete actions.
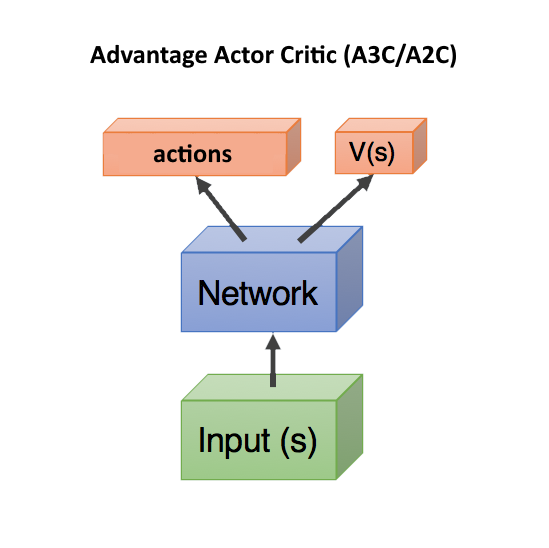
Advantage Actor Critic (A3C / A2C)
The next step was to use the number of Q (s, a) for teaching the first network not just the critic's predictions — how good the actions predicted by the actor actor, as it was in the DDPG. And how much these predicted actions turned out to be better or worse than we expected.
This is very close to what happens in the biological brain. Из экспериментов известно, что максимальный выброс дофамина происходит не во время самого получения удовольствия, а во время ожидания , что скоро получим удовольствие. Впрочем, если ожидания не оправдались, то наступают ужасные последствия, большие чем в обычном случае (в организме присутствует специальная система наказания, обратная системе вознаграждения).
Для этого для расчета градиентов стали использовать не число Q(s,a), а так называемое Advantage: A(s,a) = Q(s,a) — V(s). Число A(s,a) показывает не абсолютное качество Q(s,a) выбранных действий, а относительное преимущество — насколько после предпринятых действий станет лучше, чем текущая ситуация V(s). Если A(s,a) > 0, то градиент будет изменять веса нейросети, поощряя предсказанные сетью действия. Если A(s,a) < 0, то градиент будет изменять веса так, что предсказанные действия будут подавляться, т.к. они оказались плохие.
В этой формуле V(s) показывает насколько хорош текущий state сам по себе, без привязки к действиям (поэтому зависит только от s, без a). Если мы стоим в шаге от вершины Эвереста — это очень хорошая ситуация state, с большим V(s). А если мы уже сорвались и падаем, то это офигеть какой плохой state, с низким V(s).
К счастью, при таком подходе Q(s,a) можно заменить на награду r, которую получим после совершения действия, и тогда формула преимущества для расчета градиентов получается A = r — V(s).
В таком случае, достаточно предсказывать только V(s) (а награду мы посмотрим уже по факту что получится в реальности), и две сети — actor и critic, можно объединить в одну! Которая получает на вход state, а на выходе разделяется на две головы head: одна предсказывает действия actions, а другая предсказывает V(s). Такое объединение помогает лучше переиcпользовать веса, т.к. обе сети должны на входе получать state. Впрочем, можно использовать и две отдельные сети.
Учет и предсказание сетью качества текущей ситуации V(s) в любом случае помогает ускорить обучение. Так как при плохом V(s), где уже ничего нельзя исправить ни при каких действиях action (мы летим вниз головой с Эвереста), можно не искать дальше пути решения. Это используется в Dueling Q-Network (DuDQN), где Q(s,a) внутри сети специально раскладывается на Q(s,a) = V(s) + A(a), а потом собирается обратно.
Asynchronous Advantage Actor Critic (A3C) означает всего лишь, что есть сервер, собирающий результаты от множества actor. И обновляющий веса как только набирается батч batch нужного размера. Поэтому асинхронный, что не ждет каждого actor. Это вроде как разбавляет примеры, убирая из них ненужную корреляцию, что улучшает обучение. С другой стороны, потом появился A2C — синхронная версия A3C, в которой сервер дожидается окончания эпизодов у всех actor и только после этого обновляет веса (поэтому синхронный). A2C тоже показывает хорошие результаты, поэтому применяются обе версии, в зависимости от вкуса разработчика.
TRPO, PPO, SAC
Собственно, на этом прогресс закончился.
Не смотря на красивое и выглядящее логичным описание, все это работает не очень. Даже лучшие Reinforcement Learning алгоритмы требуют десятки миллионов примеров, сравнимы по эффективности со случайным поиском, а самое печальное, что не позволяет с их помощью создать сильный ИИ — работают лишь на крайне низких размерностях, исчисляемых единицами. Даже не десятками.
Дальнейшее улучшение — TRPO и PPO, являющиеся сейчас state-of-the-art, являются разновидностью Actor-Critic. На PPO в настоящее время обучают большинство агентов в мире RL. К примеру, им обучали OpenAI Five для игры в Dota 2.
Вы будете смеяться, но все что придумали в методах TRPO и PPO — это ограничивать изменение нейронной сети при каждом обновлении, чтобы веса резко не менялись. Дело в том, что в A3C/A2C бывают резкие изменения, которые портят предыдущий опыт. Если сделать, чтобы новая policy не слишком отличалась от предыдущей, то можно избежать таких выбросов. Что-то вроде gradient clipping в рекуррентных сетях для защиты от взрывающихся градиентов, только на другом математическом аппарате. Сам факт того, что приходится так грубо обрезать и ухудшать обучение (большие градиенты там ведь не просто так появились, они нужны для вызвавшего их примера), и что это дает положительный эффект, говорит о том, что мы свернули куда-то не туда.
В последнее время возрастающей популярность пользуется алгоритм Soft-Actor-Critic (SAC). Он не сильно отличается от PPO, только добавлена цель при обучении повышать энтропию в policy. Делать поведение агента более случайным. Нет, не так. Чтобы агент был способен действовать в более случайных ситуациях. Это автоматически повышает надежность политики, раз агент готов к любым случайным ситуациям. Кроме того, SAC требует немного меньше примеров для обучения, чем PPO, и менее чувствителен к настройке гиперпараметров, что тоже плюс. Однако даже с SAC, чтобы обучить бегать гуманоида с 17 степенями свободы, начиная с позиции стоя, нужно около 20 млн кадров и примерно сутки расчета на одном GPU. Более сложные начальные условия, скажем, научить вставать гуманоида из произвольной позы, может вообще не обучиться.
Итого, общая рекомендация в современном Reinforcement Learning: использовать SAC, PPO, DDPG, DQN (в таком порядке, по убыванию).
Model-Based
Существует еще один интересный подход, косвенно касающийся обучения с подкреплением. Это построить модель окружающей среды, и использовать ее для прогнозирования, что произойдет если мы предпримем какие-то действия.
Его недостатком является то, что он никак не говорит, какие действия нужно предпринять. Лишь об их результате. Но зато такую нейронную сеть легко обучать — просто обучаем на любой статистике. Получается что-то вроде симулятора мира на основе нейронной сети.
После этого генерируем огромное количество случайных действий, и каждое прогоняем через этот симулятор (через нейронную сеть). И смотрим, какое из них принесет максимальную награду. Есть небольшая оптимизация — генерировать не просто случайные действия, а отклоняющиеся по нормальном закону от текущей траектории. И действительно, если мы поднимаем руку, то с большой вероятностью нужно продолжать ее поднимать. Поэтому в первую очередь нужно проверить минимальные отклонения от текущей траектории.
Здесь фокус с том, что даже примитивный физический симулятор вроде MuJoCo или pyBullet выдает около 200 FPS. А если обучить нейронную сеть прогнозировать вперед хотя бы на несколько шагов, то для простых окружений легко можно за один раз получать батчи по 2000-5000 предсказаний. В зависимости от мощности GPU, в секунду можно получить прогноз для десятков тысяч случайных действий благодаря параллелизации в GPU и сжатости вычислений в нейросети. Нейросеть здесь просто выполняет роль очень быстрого симулятора реальности.
Кроме того, раз уж нейросеть может прогнозировать реальный мир (это и есть model-based подход, в общем смысле), то можно проводить обучение целиком в воображении, так сказать. Эта концепция в Reinforcement Learning получила название Dream Worlds, или World Models. Это неплохо работает, хорошее описание есть тут: https://worldmodels.imtqy.com . Кроме того, это имеет природный аналог — обычные сны. И многократная прокрутка недавних или планируемых событий в голове.
Imitation Learning
От бессилия, что алгоритмы Reinforcement Learning не работают на больших размерностях и сложных задачах, народ задался целью хотя бы повторить действия за экспертами в виде людей. Здесь удалось достичь неплохих результатов (недостижимых обычным Reinforcement Learning). Так, OpenAI получилось пройти игру Montezuma's Revenge . Фокус оказался прост — помещать агента сразу в конец игры (в конец показанной человеком траектории). Там с помощью PPO, благодаря близости финальной награды, агент быстро учится идти вдоль траектории. После этого помещаем его немного назад, где он быстро учится доходить до того места, которое он уже изучил. И так постепенно сдвигая точку "респавна" вдоль траектории до самого начала игры, агент учится проходить/имитировать траекторию эксперта в течении всей игры.
Другой впечатляющий результат — повторение движений за людьми, снятые на Motion Capture: DeepMimic . Рецепт аналогичен методу OpenAI: каждый эпизод начинаем не с начала траектории, а со случайной точки вдоль траектории. Тогда PPO успешно изучает окрестности этой точки.
Надо сказать, что нашумевший алгоритм Go-Explore от Uber, прошедший с рекордными очками игру Montezuma's Revenge, вообще не является алгоритмом Reinforcement Learning. Это обычный случайный поиск, но начиная со случайной посещенной ранее ячейки cell (огрубленной ячейки, в которую попадают несколько state). И только когда таким случайным поиском будет найдена траектория до конца игры, уже по ней с помощью Imitation Learning обучается нейросеть. Способом, аналогичным как в OpenAI, т.е. начиная с конца траектории.
Curiosity (любопытство)
Очень важным понятием в Reinforcement Learning является любопытство (Curiosity). В природе оно является двигателем для исследования окружающей среды.
Проблема в том, что в качестве оценки любопытства нельзя использовать простую ошибку предсказания сети, что будет дальше. Иначе такая сеть зависнет перед первым же деревом с качающейся листвой. Или перед телевизором со случайным переключением каналов. Так как результат из-за сложности будет невозможно предсказать и ошибка всегда будет большой. Впрочем, именно это и является причиной, почему мы (люди) так любим смотреть на листву, воду и огонь. И на то, как другие люди работают =). Но у нас есть защитные механизмы, чтобы не зависнуть навечно.
Один из таких механизмов придумали как Inverse Model в работе Curiosity-driven Exploration by
Self-supervised Prediction . Если коротко, агент (нейронная сеть) кроме того, что предсказывает какие действия лучше всего совершить в данной ситуации, дополнительно пытается предсказать что будет с миром после совершенных действий. И использует это свое предсказание мира для следующего шага, чтобы по нему и по текущему шагу обратно предсказать свои же предпринятые ранее действия (да, сложно, без поллитра не разобраться).
Это приводит к любопытному эффекту: агент становится любопытным только к тому, на что он может повлиять своими действиями. На качающиеся ветки дерева он никак не может повлиять, поэтому они становятся ему неинтересны. А вот походить по округе он может, поэтому ему любопытно ходить и исследовать мир.
Однако если у агента будет пульт от телевизора, переключающий случайные каналы, то он может на него повлиять! И ему будет любопытно щелкать каналы до бесконечности (так как не может предсказать, какой будет следующий канал, т.к. он случайный). Попытка обойти эту проблему предпринята в Google в работе Episodic Curiosity through Reachability .
Но, пожалуй, лучший state-of-the-art результат по любопытству, на данный момент принадлежит OpenAI с идеей Random Network Distillation (RND) . Ее суть в том, что берется вторая, совершенно случайно инициализированная сеть, и ей на вход подается текущий state. А наша основная рабочая нейросеть пытается угадать выход этой нейросети. Вторая сеть не обучается, она остается все время фиксированной как была инициализирована.
В чем смысл? Смысл в том, что если какой-либо state уже был посещен и изучен нашей рабочей сетью, то она более менее успешно сможет предсказывать выход той второй сети. А если это новый state, где мы никогда не были, то наша нейросеть не сможет предсказать выход той RND сети. Эта ошибка в предсказании выхода той случайно инициализированной сети используется как показатель любопытства (дает высокие награды, если в данной ситуации не можем предсказать ее выход).
Почему это работает, не совсем понятно. Но пишут, что это устраняет проблему когда цель предсказания стохастическая и когда недостаточно данных, чтобы самому сделать предсказание что будет дальше (что дает большую ошибку предсказания в обычных алгоритмах любопытства). Так или иначе, но RND реально показал отличные результаты по исследованию на основе любопытства в играх. И справляется с проблемой случайного телевизора.
С помощью RND любопытства в OpenAI впервые честно (а не через предварительный случайный поиск, как в Uber) прошли первый уровень Montezuma's Revenge. Не каждый раз и ненадежно, но время от времени получается.

What is the result?
Как видите, всего за несколько лет Reinforcement Learning прошел долгий путь. Не просто несколько удачных решений, как в сверточных сетях, где resudal и skip connections позволили тренировать сети глубиной в сотни слоев, вместо десятка слоев с одной только функцией активации Relu, поборовшей проблему исчезающих градиентов в сигмоиде и tanh. В обучении с подкреплением произошел прогресс в концепциях и понимании причин, почему не заработал тот или иной наивный вариант реализации. Ключевое слово "не заработал".
Но с технической стороны все по прежнему упирается в предсказания все тех же Q, V или A значений. Ни временных зависимостей на разных масштабах, как в мозге (Hierarchical Reinforcement Learning не в счет, уж больно примитивная в нем иерархия по сравнению с ассоциативностью в живом мозге). Ни попыток придумать архитектуру сети, заточенную именно под обучение с подкреплением, как это произошло с LSTM и другими рекуррентными сетями для временных последовательностей. Reinforcement Learning либо топчется на месте, радуясь небольшим успехам, либо движется в каком-то совсем уж неправильном направлении.
I want to believe that one day in the training with reinforcement there will be a breakthrough in the architecture of neural networks, similar to what happened in convolutional networks. And we will see truly working reinforcement training. Studying on single examples, with a working associative memory and working on different time scales.
Source: https://habr.com/ru/post/437020/