How to speed up work with APIs in the R language using parallel computing, using the Yandex.Direct API as an example
The R language today is one of the most powerful and multifunctional tools for working with data, but as we know almost always, in any barrel of honey there is a fly in the ointment. The fact is that R is single stream by default.
Most likely, it will not disturb you for quite a long time, and you are unlikely to ask this question. But for example, if you are faced with the task of collecting data from a large number of advertising accounts from an API, such as Yandex.Direct, then you can significantly, at least two or three times, reduce the time for data collection using multithreading.

The theme of multithreading in R is not new, and has repeatedly raised Habré here , here and here , but the latest publication dates from 2013, and as they say everything new is well forgotten old. In addition, multithreading was previously discussed for calculating models and teaching neural networks, and we will talk about the use of asynchrony to work with the API. Nevertheless, I would like to take this opportunity to thank the authors of the above articles because in writing this article they helped me a lot with their publications.
Content
- What is multithreading
- What packages will we use
- Task
- Authorization in Yandex.Direct, ryandexdirect package
- Solution in a single-threaded, sequential mode, using a for loop
- Solution using multithreading in R
- Speed test between the three approaches reviewed, rbenchmark package
- Conclusion
What is multithreading
Singleline (Sequential Computing) - the calculation mode in which all actions (tasks) are performed sequentially, the total duration of all specified operations in this case will be equal to the sum of the duration of all operations.
Multithreading (Parallel Computing) is a computation mode in which the specified actions (tasks) are performed in parallel, i.e. at the same time, the total time for performing all operations will not be equal to the sum of the duration of all operations.
To simplify the perception, let's consider the following table:
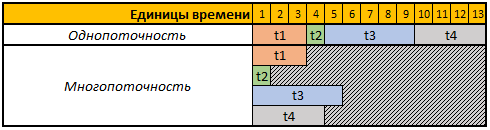
The first line of the table is conditional time units, in this case, it does not matter to us that it is seconds, minutes, or any other time intervals.
In this example, we need to perform 4 operations, each operation has a different calculation duration, in single-threaded mode, all 4 operations will be performed sequentially one after the other, therefore the total time for their execution will be t1 + t2 + t3 + t4, 3 + 1 + 5 + 4 = 13.
In multithreaded mode, all 4 tasks will be executed in parallel, i.e. to start the next task, there is no need to wait until the previous one is completed, so if we start the execution of our task in 4 threads, then the total calculation time will be equal to the calculation time of the largest task, in our case this is task t3, the duration of which is in our example 5 time units, respectively, and the execution time of all 4x operations in this case will be equal to 5 time units.
What packages will we use
For calculations in multi-thread mode, we will use the foreach , doSNOW and doParallel .
The foreach package allows you to use the foreach construct, which is an advanced for loop.
The doSNOW and doParallel are essentially twin brothers that allow you to create virtual clusters and perform parallel computing with them.
At the end of the article using the rbenchmark package rbenchmark we measure and compare the duration of data collection operations from the Yandex.Direct API using all the methods described below.
To work with the Yandex.Direct API, we will use the ryandexdirect package, in this article we use it as an example, you can learn more about its capabilities and functions from the official documentation .
Code to install all the necessary packages:
install.packages("foreach") install.packages("doSNOW") install.packages("doParallel") install.packages("rbenchmark") install.packages("devtools") devtools::install_github("selesnow/ryandexdirect") Task
You need to write a code that will request a list of keywords from any number of advertising accounts Yandex.Direct. The result must be collected in a single date frame in which there will be an additional field with the login account of the advertising account to which the keyword belongs.
In this case, our task is to write the code that will perform this operation as quickly as possible on any number of advertising accounts.
Authorization in Yandex.Direct
To work with the API of the Yandex.Direct advertising platform, you initially need to be authorized under each account from which we plan to request a list of keywords.
All the code given in this article reflects an example of working with regular Yandex.Direct advertising accounts, if you work under an agent account, then you need to use the AgencyAccount argument and pass the login name of the agency account to it. You can learn more about working with Yandex.Direct agent accounts using ryandexdirect package here .
For authorization, you need to execute the yadirAuth function from the yadirAuth package ryandexdirect you need to repeat the code below for each account from which you will request a list of keywords and their parameters.
ryandexdirect::yadirAuth(Login = "логин рекламного аккаунта на Яндексе") The Yandex.Direct authorization process through the ryandexdirect package ryandexdirect completely secure, despite the fact that it passes through a third-party site. In detail about the safety of its use, I have already told in the article "How safe is it to use R packages for working with the API of advertising systems" .
After logging in , under each account in your working directory will be created file login.yadirAuth.RData , which will store the credentials for each account. The file name will begin with the login specified in the Login argument. If you need to save files not in the current working directory, but in any other folder, use the TokenPath argument, but in this case, when requesting keywords using the yadirGetKeyWords function yadirGetKeyWords you also need to use the TokenPath argument and specify the path to the folder where you saved the files. with credentials.
Solution in a single-threaded, sequential mode, using a for loop
The easiest way to collect data from multiple accounts at once is to use a for loop. Simple but not the most effective, because One of the principles of R-language development is to avoid using loops in code.
Below is a sample code to collect data from 4 accounts using a for loop, in fact, you can use this example to collect data from any number of ad accounts.
library(ryandexdirect) # вектор логинов logins <- c("login_1", "login_2", "login_3", "login_4") # результирующий дата фрейм res1 <- data.frame() # цикл сбора данных for (login in logins) { temp <- yadirGetKeyWords(Login = login) temp$login <- login res1 <- rbind(res1, temp) } Measuring runtime using the system.time function showed the following result:
Working hours:
User: 178.83
system: 0.63
passed: 320.39
The collection of keywords for 4 accounts took 320 seconds, while from the informational messages that the yadirGetKeyWords function displays during the work, the largest account from which 5970 keywords were received was processed for 142 seconds.
Solution using multithreading in R
Above, I already wrote that for multithreading, we will use the doSNOW and doParallel .
I want to draw attention to the fact that almost any API has its limitations, and the Yandex.Direct API is not an exception. In fact, the help guide for the Yandex.Direct API says:
Allowed no more than five simultaneous requests to the API on behalf of one user.
Therefore, in spite of the fact that in this case we will consider an example with the creation of 4 threads, you can create 5 threads with Yandex.Direct, even if you send all requests under the same user. But the most efficient use of 1 thread per 1 core of your processor, you can determine the number of physical processor cores using the parallel::detectCores(logical = FALSE) command, the number of logical cores can be found using parallel::detectCores(logical = TRUE) . In more detail, it is possible to understand what a physical and logical core is on Wikipedia .
In addition to the limit on the number of requests, there is a daily limit on the number of points for accessing the Yandex.Direct API, it may be different for all accounts, each request also consumes a different number of points depending on the operation being performed. For example, for requesting a list of keywords, 15 points will be deducted from you for a completed request and 3 points for every 2000 words, you can learn about how points are written off in the official certificate . You can also see information about the number of points written and available, as well as about their daily limit in the informational messages returned to the console by the yadirGetKeyWords function.
Number of API points spent when executing the request: 60 Available balance of daily limit API points: 993530 Daily limit of API points:996000 Let's doSNOW at doSNOW and doParallel in order.
Package doSNOW and features work in multithreaded mode
Let's rewrite the same operation to the multithreaded mode of calculations, create 4 threads, and use the foreach construct instead of the for foreach .
library(foreach) library(doSNOW) # вектор логинов logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoSNOW(cl) res2 <- foreach(login=logins, .combine= 'rbind', .inorder=F ) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) } stopCluster(cl) I will give a small explanation of code 2 , the function makeCluster is responsible for the number of threads, in this case we created a cluster of 4 processor cores, but as I wrote earlier when working with the Yandex.Direct API, you can create 5 threads no matter how many accounts you need to process 5-15-100 or more, you can simultaneously send requests to API 5.
Next, the registerDoSNOW function starts the created cluster.
After that, we use the foreach construct, as I said earlier, this construct is an advanced for loop. You set the counter as the first argument, in the above example I called it login and it would iterate through the elements of the logins vector at each iteration, we would get the same result in the for loop if we wrote for ( login in logins) .
Next, you need to specify the function in the .combine argument, with which you will combine the results obtained at each iteration, the most frequent options are:
rbind- connect the resulting tables row by row under each other;cbind- join the resulting tables in columns;"+"- summarize the result obtained at each iteration.
You can also use any other function, even self-written.
The argument .inorder = F allows you to speed up the function a little more if you don’t fundamentally in what order to combine the results, in this case the order is not important to us.
Next comes the %dopar% that starts the loop in parallel computing mode, if you use the %do% statement, then the iterations will be executed sequentially, just like when using the usual for loop.
The stopCluster function stops the cluster.
Multithreading, or rather foreach constructs in multi-threaded mode, have some peculiarities, in fact in this case we start every parallel process in a new, clean R session, so you cannot use self-writing functions and objects inside it that are outside of the foreach construct. Below is an example of incorrect code that will not work.
library(foreach) library(doSNOW) myfun <- function(x, y) { return(x + y)} vec_x <- c(1:1000) cl <- makeCluster(4) registerDoSNOW(cl) result <- foreach(x = vec_x, .combine= '+', .inorder=F ) %dopar% {myfun(x, runif(1, 1, 100000))} This example will not work. the myfun self- myfun function myfun defined outside the foreach construct, and as I said, foreach runs every thread in a clean R session, with an empty working environment, and does not see the objects and functions that you created outside its scope.
Also, foreach does not see packages that were previously connected, so in order to use functions from any package, in our case ryandexdirect you need to either register its connection through foreach through the library function, or access its functions via package_name :: function_name, as I did in the example code above.
If you want to use any samopny functions inside the foreach , then either declare them inside the foreach or first save their code to the .R file and read it inside the foreach using the source function. The same applies to any other objects created during the R session in your working environment outside of the foreach structure, if you plan to use them inside %dopar% you need to save them before running the structure using the save or saveRDS , and inside %dopar% load on each iteration using the load or readRDS . Below is an example of proper work with objects created in the working environment before running foreach .
library(foreach) library(doSNOW) mydata <- read.csv("data.csv") cl <- makeCluster(4) registerDoSNOW(cl) saveRDS(mydata, file = "mydata.rds") result <- foreach(data_row = 1:nrow(mydata), .combine= 'rbind', .inorder=F ) %dopar% { mydata <- readRDS("mydata.rds") ... ТЕЛО ЦИКЛА ПЕРЕБИРАЮЩЕГО СТРОКИ ТАБЛИЦЫ mydata ЧЕРЕЗ mydata[ data_row, ] ... } In this case, the execution time measurement using the system.time function showed the following result:
Working hours:
User: 0.17
system: 0.08
passed: 151.47
The same result, i.e. we got a collection of keywords from 4 Yandex.Direct accounts in 151 seconds, i.e. 2 times faster. Besides, it’s not just in the past example that I wrote how long it took to load a list of keywords from the largest account (142 seconds), i.e. in this example, the total time is almost identical to the processing time of the largest account. The fact is that with the help of the foreach function we simultaneously launched the process of collecting data in 4 streams, i.e. simultaneously collected data from all 4 accounts, respectively, the total work time is equal to the processing time of the largest account.
DoParallel package
As I wrote above, the doSNOW and doParallel are twins, so the syntax is the same.
library(foreach) library(doParallel) logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoParallel(cl) res3 <- data.frame() res3 <- foreach(login=logins, .combine= 'rbind', .inorder=F) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) stopCluster(cl) Working hours:
User: 0.25
system: 0.01
passed: 173.28
As you can see in this case, the execution time is slightly different from the past example of parallel computing code using the doSNOW package.
Speed test between the three approaches considered
Now run the speed test with the rbenchmark package.
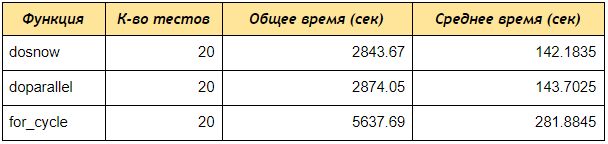
As you can see, even on a test of 4 accounts, doSNOW and doParallel received data on keywords 2 times faster than a consecutive for loop, if you create a cluster of 5 cores and process 50 or 100 accounts, the difference will be even more significant.
# подключаем библиотеки library(ryandexdirect) library(foreach) library(doParallel) library(doSNOW) library(rbenchmark) # создаём функцию сбора ключевых слов с использованием цикла for for_fun <- function(logins) { res1 <- data.frame() for (login in logins) { temp <- yadirGetKeyWords(Login = login) res1 <- rbind(res1, temp) } return(res1) } # создаём функцию сбора ключевых слов с использованием функции foreach и пакета doSNOW dosnow_fun <- function(logins) { cl <- makeCluster(4) registerDoSNOW(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login } }) stopCluster(cl) return(res2) } # создаём функцию сбора ключевых слов с использованием функции foreach и пакета doParallel dopar_fun <- function(logins) { cl <- makeCluster(4) registerDoParallel(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login) } }) stopCluster(cl) return(res2) } # запускаем тест скорости сбора данных по двум написанным функциям within(benchmark(for_cycle = for_fun(logins = logins), dosnow = dosnow_fun(logins = logins), doparallel = dopar_fun(logins = logins), replications = c(20), columns=c('test', 'replications', 'elapsed'), order=c('elapsed', 'test')), { average = elapsed/replications }) In conclusion, I will give an explanation of the above code 5 , with which we tested the speed of work.
Initially, we created three functions:
for_fun - a function requesting keywords from a variety of accounts, sequentially going through them in a normal cycle.
dosnow_fun is a function requesting a list of keywords in multi-threaded mode using the doSNOW package.
dopar_fun - function requesting a list of keywords in multi-threaded mode, using the doParallel package.
Next, inside the within construction, we run the benchmark function from the rbenchmark package, specify the test names (for_cycle, dosnow, doparallel), and specify the functions for each test, respectively: for_fun(logins = logins) ; dosnow_fun(logins = logins) ; dopar_fun(logins = logins) .
The replications argument is responsible for the number of tests, i.e. how many times we will run each function.
The columns argument allows you to specify which columns you want to get, in our case, 'test', 'replications', 'elapsed' means to return the columns: the name of the test, the number of tests, the total run time of all tests.
You can also add calculated columns, ( { average = elapsed/replications } ), i.e. in the output there will be an average column which divides the total time by the number of tests, so we will calculate the average execution time of each function.
The order is responsible for sorting the test results.
Conclusion
In this article, in principle, a fairly universal method for accelerating work with API is described, but each API has its limits, so specifically in this form, with so many threads, the given example is suitable for working with Yandex.Direct API, for using it with API Other services initially need to read the documentation about the limits in the API on the number of simultaneously sent requests, otherwise you may get an error Too Many Requests .
Source: https://habr.com/ru/post/437078/