Reverse engineering rendering "The Witcher 3"
The first part of the translation is here . In this part we will talk about the effect of sharpness, average brightness, phases of the moon and atmospheric phenomena during the rain.
In this section, we take a closer look at another post-processing effect from The Witcher 3 - Sharpen.
Sharpening makes the output image a little clearer. This effect is known to us from Photoshop and other graphic editors.
In The Witcher 3, sharpening has two options: low and high. I will tell about the difference between them below, but for now let's take a look at the screenshots:

Option "Low" - to

“Low” option - after

Option "High" - to

Option “High” - after
If you want to take a look at more detailed (interactive) comparisons, then look at the section in the Nvidia The Witcher 3 manual . As you can see, the effect is especially noticeable on grass and foliage.
In this part of the post we will study the frame from the very beginning of the game: I chose it intentionally, because here we see the relief (the long distance of drawing) and the dome of the sky.

From the point of view of input data, sharpening requires a color buffer t0 (LDR after tone correction and lens flares) and a depth buffer t1 .
Let's examine the pixel shader assembler code:
50 lines of assembler code look like a feasible task. Let's get to its solution.
The first stage is to load ( Load ) the depth buffer (line 1). It is worth noting that the "Witcher 3" uses an inverted depth (1.0 - close, 0.0 - far). As you may know, the hardware depth is tied nonlinearly (see this article for details ).
Lines 3-6 perform a very interesting way of binding this hardware depth [1.0 - 0.0] to the values [near-far] (we set them at the MatrixPerspectiveFov stage). Consider the values from the constant buffer:

Having a “close” value of 0.2, and a “far” value of 5000, we can calculate the values of cb12_v21.xy as follows:
This code fragment is quite common in TW3 shaders, so I think this is just a function.
After obtaining the “depth of visibility pyramid” line 7 uses scale / distortion to create an interpolation coefficient (here we use saturate to limit the values to [0-1]).

cb3_v1.xy and cb3_v2.xy is the brightness of the sharpening effect at near and far distances. Let's call them "sharpenNear" and "sharpenFar". And this is the only difference between the “Low” and “High” options of this effect in The Witcher 3.
Now it is time to use the resulting coefficient. Lines 8-9 just perform

Perhaps this is barely noticeable, but here we interpolate, based on the distance, the brightness of the sharpen next to the player (2.177151) and the brightness of the effect very far (1.91303). After this calculation, we add to the brightness 1.0 (line 10). Why do you need it? Suppose that the operation lerp shown above gave us 0.0. After adding 1.0, we naturally get 1.0, and this value will not affect the pixel when performing sharpening. Read more about this below.
While adding sharpness, we do not want to affect the sky. This can be achieved by adding a simple conditional check:
In The Witcher 3, the pixel depth of the sky is 1.0, so we use it to get a kind of “binary filter” (interesting fact: in this case, step will not work properly).
Now we can multiply the interpolated brightness by the “sky filter”:

This multiplication is performed in line 13.
Shader code example:
In SV_Position there is an aspect that will be important here: an offset of half a pixel . It turns out that this pixel in the upper left corner (0, 0) has coordinates not (0, 0) from the point of view of SV_Position.xy, but (0.5, 0.5). Wow!
Here we want to take a sample in the center of the pixel, so let's look at lines 14-16. You can write them on HLSL:
And later, we sample the color input texture from texcoords uvCenter. Do not worry, the result of the sampling will be the same as in the “normal” method (SV_Position.xy / ViewportSize.xy).
The decision about whether to use sharpen depends on fSharpenAmount.
It's time to look at the insides of the algorithm itself.
In essence, it performs the following actions:
- samples four times the input color texture at the corners of the pixel,
- adds samples and calculates the average value,
- calculates the difference between "center" and "cornerAverage",
- finds the maximum absolute component of the difference,
- adjusts max. abs component using scale + bias values
- determines the effect size using max. abs component,
- calculates the brightness value (luma) for "centerColor" and "averageColor",
- divides the colorCenter into its luma,
- calculates a new, interpolated luma value based on the magnitude of the effect,
- multiplies the colorCenter by the new value of luma.
Quite a lot of work, and it was difficult for me to figure it out, because I never experimented with sharpness filters.
Let's start with the sampling pattern. As you can see in the assembly code, four texture reads are performed.
It would be best to show this with a pixel image as an example (the artist’s skill level is an expert ):
All reads in the shader use bilinear sampling (D3D11_FILTER_MIN_MAG_LINEAR_MIP_POINT).
The offset from the center to each of the angles is (± 0.5, ± 0.5), depending on the angle.
See how it can be implemented on HLSL? Let's get a look:
So now all four samples are summarized in the variable “colorCorners”. Let's follow these steps:
Edge recognition is performed by calculating max. abs the difference component. Smart move! See his visualization:

Visualization of the maximum absolute difference component.
Fine. Ready HLSL-shader posted here . Sorry for the pretty bad formatting. You can use my HLSLexplorer program and experiment with the code.
I am happy to say that the above code creates the same assembler code as in the game!
To summarize: The Witcher 3's sharpness shader is very well written (note that fPixelSharpenAmount is greater than 1.0! That's interesting ...). In addition, the main way to change the brightness of the effect is the brightness of near / far objects. In this game, they are not constants; I collected a few examples of the values:
Skellige:
Kaer Morhen:
The operation of calculating the average brightness of the current frame can be found in almost any modern video game. This value is often used later for the effect of eye adaptation and tonal correction (see the previous part of the post). In simple solutions, a brightness calculation is used for, say, a texture of 512 2 in size, then its mip-level calculation and application of the latter. This usually works, but it severely limits the possibilities. More complex solutions use computational shaders that perform, for example, parallel reduction .
Let's find out how the CD Projekt Red team solved this problem in The Witcher 3. In the previous part, I have already investigated the tonal correction and adaptation of the eye, so the only remaining piece of the puzzle remained the average brightness.
To begin with, the calculation of the average brightness of The Witcher 3 consists of two passes. For clarity, I decided to break them into separate parts, and first we will consider the first pass - “brightness distribution” (calculation of the brightness histogram).
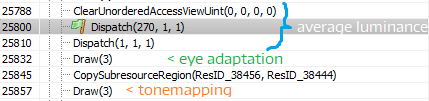
These two passes are fairly easy to find in any frame analyzer. These are proceeding calls to Dispatch right before the eye adapts:
Let's look at the input for this pass. He needs two textures:
1) HDR-buffer color, the scale of which is reduced to 1/4 x 1/4 (for example, from 1920x1080 to 480x270),
2) Full screen depth buffer

HDR color buffer with 1/4 x 1/4 resolution. Note the tricky trick - this buffer is part of a larger buffer. Reusing buffers is good practice.

Full screen depth buffer
Why scale down the color buffer? I think it's all about performance.
As for the output of this pass, it is a structured buffer. 256 elements of 4 bytes each.
Here, shaders have no debug information, so suppose that this is just a buffer of unsigned int values.
Important: the first stage of the calculation of the average brightness causes ClearUnorderedAccessViewUint to reset all the elements of the structured buffer.
Let's examine the assembler code of the computational shader (this is the first computational shader for our entire analysis!)
And the buffer of constants:

We already know that the first input is the HDR color buffer. With FullHD, its resolution is 480x270. Let's look at the Dispatch call.
Dispatch (270, 1, 1) - this means that we run 270 groups of threads. Simply put, we run one thread group for each row of the color buffer.
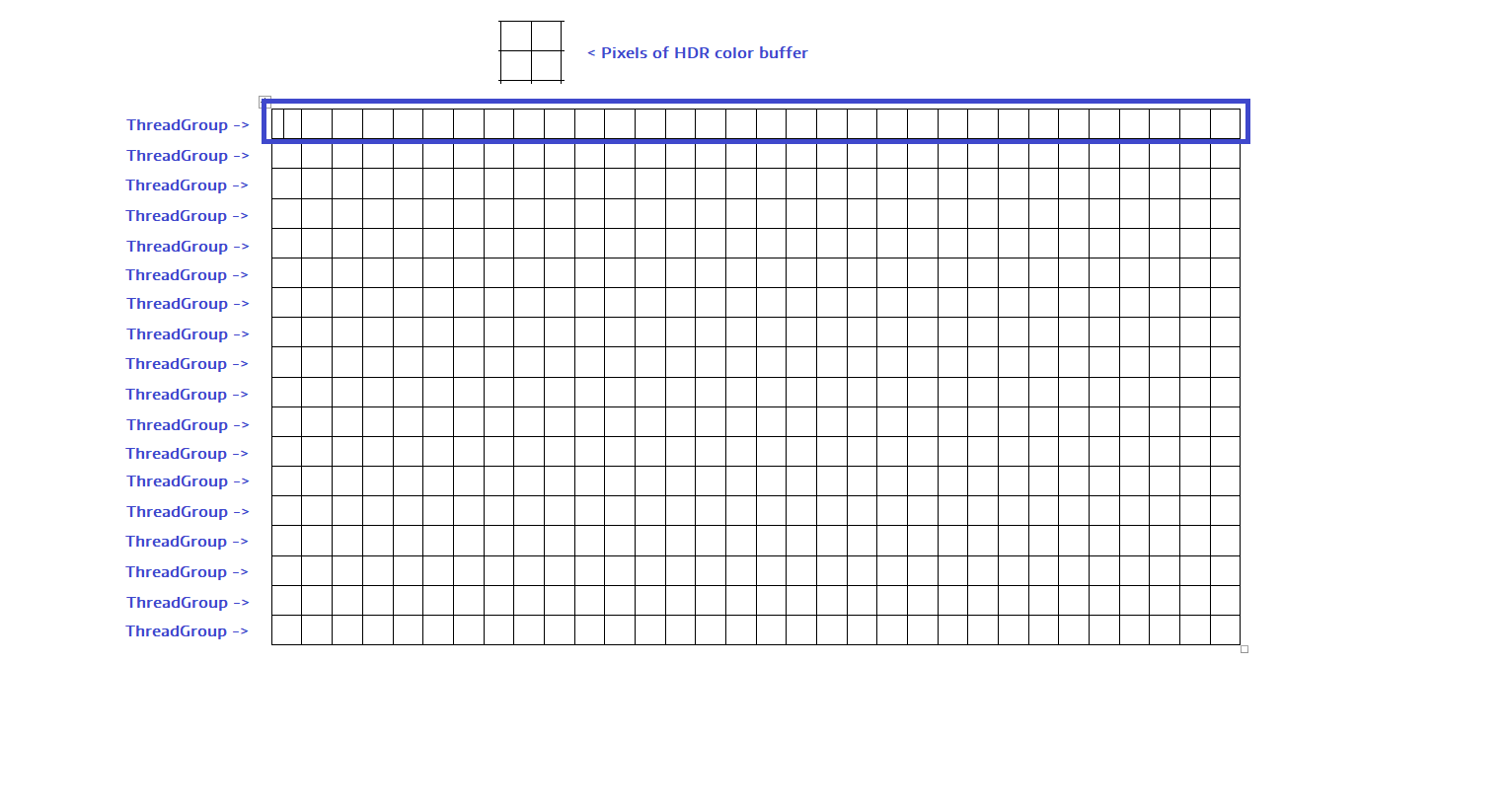
Each thread group executes one line of HDR buffer of colors.
Now that we have this context, let's try to figure out what the shader is doing.
Each thread group has 64 threads in the X direction (dcl_thread_group 64, 1, 1), as well as shared memory, 256 elements with 4 bytes each (dcl_tgsm_structured g0, 4, 256).
Note that in the shader we use SV_GroupThreadID (vThreadIDInGroup.x) [0-63] and SV_GroupID (vThreadGroupID.x) [0-269].
1) We begin by assigning zero values to all elements of shared memory. Since the total memory contains 256 elements and 64 threads per group, this can be conveniently done using a simple loop:
2) After that we set a barrier using GroupMemoryBarrierWithGroupSync (sync_g_t). We do this to ensure that all the threads in the shared memory of the groups are reset to zero before proceeding to the next stage.
3) Now we are performing a loop that can be roughly written like this:
This is a simple for loop with an increment of 64 (did you already understand why?).
The next step is the calculation of the position of the loaded pixel.
Let's think about it.
For the Y coordinate, we can use SV_GroupID.x, because we launched 270 thread groups.
For the X coordinate, we ... can take advantage of the current group flow! Let's try to do it.
Since there are 64 streams in each group, this solution will bypass all the pixels.
Consider a group of threads (0, 0, 0).
- The stream (0, 0, 0) will process the pixels (0, 0), (64, 0), (128, 0), (192, 0), (256, 0), (320, 0), (384, 0), (448, 0).
- The stream (1, 0, 0) will process the pixels (1, 0), (65, 0), (129, 0), (193, 0), (257, 0), (321, 0), (385, 0), (449, 0) ...
- The stream (63, 0, 0) will process the pixels (63, 0), (127, 0), (191, 0), (255, 0), (319, 0), (383, 0), (447, 0)
Thus, all pixels will be processed.
We also need to ensure that we do not load pixels from outside the color buffer:
Do you see? It's pretty simple!
I also calculated the brightness (line 21 of the assembler code).
Great, we've already calculated the brightness from the color pixel. The next step is to load (not sampling!) The corresponding depth value.
But here we have a problem, because we have connected a full resolution depth buffer. What to do with it?
It is surprisingly simple - just multiply the colorPos by some constant (cb0_v2.z). We reduced the HDR buffer color by a factor of four. so the value will be 4!
So far everything is great! But ... we reached lines 24-25 ...
So. First, we have a comparison of equality with a floating point, its result is written in r2.x, and immediately after that comes ... what? Bitwise And ?? Seriously? For floating point values? What the heck???
Problem 'eq + and'
Let me just say that for me it was the hardest part of the shader. I even tried strange combinations asint / asfloat ...
And if you use a slightly different approach? Let's just do the usual float-float comparison in HLSL.
And this is what output in assembly code looks like:
Interesting, right? I did not expect to see here "and".
0x3f800000 is just 1.0f ... It makes sense, because if we get a success, the comparison is 1.0 and 0.0 otherwise.
What if we "replace" 1.0 with some other value? For example:
We get the following result:
Ha! It worked. This is just the magic of the HLSL compiler. Note: if we replace 0.0 with something else, then we simply get movc.
Let's return to the computational shader. The next step is to check if the depth is equal to the value of cb0_v2.w. It is always 0.0 - in other words, we check whether the pixel is in the far plane (in the sky). If yes, then we assign some value to this coefficient, approximately 0.5 (I checked on several frames).
This calculated coefficient is used to interpolate between the brightness of the color and the brightness of the "sky" (the value of cb0_v2.x, which is often about 0.0). I assume that it is necessary to control the importance of the sky in calculating the average brightness. Usually the importance decreases. Very clever idea.
Since we have lumaOk, the next step is to calculate its natural logarithm to create a good distribution. But wait, say, lumaOk is 0.0. We know that the value of log (0) is undefined, so we add 1.0, because log (1) = 0.0.
After that, we scale the calculated logarithm by 128 to distribute it to 256 cells. Very clever!
And it is from here that this value is taken 88.722839. This is
This is just the way HLSL calculates logarithms.
In the HLSL assembly code, there is only one function that calculates logarithms: log , and it has base 2.
Finally, we calculate the cell index from the log-distributed brightness and add 1 to the corresponding cell in the shared memory.
The next step is to install the barrier again to ensure that all the pixels in the row were processed.
And the final step is to add values from shared memory to a structured buffer. This is done in the same way, through a simple loop:
After all 64 streams in a stream group fill the common data, each stream adds 4 values to the output buffer.
Consider an output buffer. Let's think about it. The sum of all values in the buffer is equal to the total number of pixels! (at 480x270 = 129 600). That is, we know how many pixels have a specific brightness value.
If you have little understanding of computational shaders (like me), then at first it may not be clear, so read the post a few more times, take paper and a pencil, and try to understand the concepts on which this technique is built.
That's all! That is how "The Witcher 3" calculates the brightness histogram. Personally, I have learned a lot when writing this part. Congratulations to the guys from Projekt Red CD with excellent work!
If you are interested in a full HLSL shader, then it is posted here . I always strive to get as close as possible to the game assembly code and I am absolutely happy that I succeeded again!
This is the second part of the analysis of average brightness calculations in “The Witcher 3: Wild Hunt”.
Before we fight another computational shader, let's briefly repeat what happened in the last part: we worked with an HDR color buffer with a scale reduced to 1 / 4x1 / 4. After the first pass, we got a histogram of brightness (structured buffer of 256 unsigned integer values). We calculated the logarithm for the brightness of each pixel, distributed it to 256 cells and increased the corresponding value of the structured buffer by 1 per pixel. Due to this, the total sum of all values in these 256 cells is equal to the number of pixels.
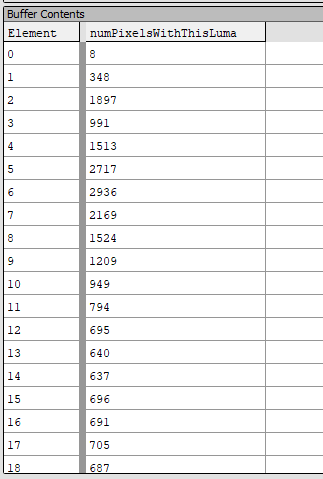
An example of the output of the first pass. Here are 256 elements.
For example, our fullscreen buffer is 1920x1080. After zooming out, the first pass used a 480x270 buffer. The sum of all 256 values in the buffer will be equal to 480 * 270 = 129 600.
After this brief introduction, we are ready to proceed to the next stage: to calculations.
This time only one thread group is used (Dispatch (1, 1, 1)).
Let's take a look at the compiler shader assembly code:
There is one constant buffer:

Briefly take a look at the assembler code: two UAVs are attached (u0: input buffer from the first part and u1: output texture of 1x1 format R32_FLOAT). We also see that there are 64 streams per group and 256 elements of 4-byte shared group memory.
Let's start by filling the shared memory with data from the input buffer. We have 64 threads, so we have to do almost the same thing as before.
To be absolutely sure that all data is loaded for further processing, after that we put a barrier.
All calculations are performed only in one thread, all others are used simply to load values from the buffer into the common memory.
The “computational” flow has index 0. Why? Theoretically, we can use any stream from the interval [0-63], but thanks to a comparison with 0, we can avoid additional integer-integer comparison ( ieq instructions).
The algorithm is based on specifying the interval of pixels that will be taken into account in the operation.
In line 11, we multiply the width * height to get the total number of pixels and multiply them by two numbers from the interval [0.0f-1.0f], denoting the beginning and end of the interval. Further restrictions are used to ensure that
As you can see, there are two cycles below. The problem with them (or with their assembly code) is that there are strange conditional jumps at the ends of the cycles. It was very difficult for me to recreate them. Also take a look at line 21. Why is there a -1? I will explain this below.
The task of the first cycle is to drop pixelsToConsiderStart and give us the buffer cell index, in which pixel pixelsToConsiderStart +1 is present (as well as the number of all pixels in the previous cells).
Suppose that pixelsToConsiderStart is approximately equal to 30000, and in the buffer there are 37000 pixels in the “zero” cell (this happens in a game at night). Therefore, we want to start analyzing the brightness at about pixel 30001, which is present in the “zero” cell. In this case, we immediately exit the loop, getting the initial index '0' and zero dropped pixels.
Look at the HLSL code:
The mysterious number "-1" from line 21 of the assembler code is associated with a boolean condition for executing a loop (I discovered this almost by accident).
Having obtained the number of pixels from the lumaValue cells and the lumaValue itself, we can proceed to the second cycle.
The task of the second cycle is the calculation of the effect of pixels and average brightness.
We start with lumaValue , calculated in the first loop.
At this stage, we obtained the brightness value encoded in the interval [0.0f-255.f].
The decoding process is quite simple - you need to reverse the calculations of the encoding stage.
Briefly repeat the coding process:
To decode the brightness, we reverse the encoding process, like this:
Then we calculate the distribution, multiplying the number of pixels with a given brightness by the decoded brightness, and adding them together until we reach the processing pixelsToConsiderEnd pixels.
After that, we divide the total effect by the number of pixels analyzed.
Here is the rest of the loop (and the shader): The full shader is posted here . It is fully compatible with my HLSLexplorer program , without which I could not effectively recreate the calculation of the average brightness in The Witcher 3 (and all the other effects too!). In conclusion, a few thoughts. From the point of view of calculating the average brightness, this shader was difficult to recreate. The main reasons are: 1) Strange "deferred" checks on the execution of the cycle, it took much longer than I expected earlier. 2) Problems with debugging this computational shader in RenderDoc (v. 1.2).
The “ld_structured_indexable” operations are not fully supported, although the reading result from the index 0 gives the correct value, all the others return zeroes, because of which the cycles continue indefinitely.
Although I was not able to achieve the same assembler code as in the original (see the screenshot below for differences), with the help of RenderDoc I was able to inject this shader into the pipeline - and the results were the same!

The result of the battle. On the left - my shader, on the right - the original assembly code.
In the eighth part of the article, I explore the Moon's shader from The Witcher 3 (and more specifically from the Blood and Wine extension).
The moon is an important element of the night sky, and it can be quite difficult to make it believable, but for me walking at night in TW3 became a real pleasure.
Just look at this scene!

Before we take on the pixel shader, I’ll say a few words about the nuances of rendering. Geometrically, the Moon is just a sphere (see below), which has texture coordinates, normal vectors, and tangent vectors. The vertex shader calculates the position in world space, as well as the normalized normal vectors, tangents and tangents to two points (using the vector product) multiplied by the world matrix.
To ensure that the moon completely lies on a distant plane, the MinDepth and MaxDepth fields of the D3D11_VIEWPORT structure are set to 0.0 (the same trick used for the dome of the sky). The moon is rendered immediately after the sky.

The sphere used to draw the moon.
Well, everything, I think you can proceed. Let's take a look at the pixel shader: The main reason that I chose the shader from “Blood and Wine” is simple - it’s shorter. First we calculate the offset for texture sampling. cb0 [0] .w is used as an X-axis offset. With this simple trick, we can simulate the rotation of the moon around its axis.

Examples of values from the buffer of constants
One texture (1024x512) is attached as input. The normal map is encoded in the RGB channels, and the color of the moon's surface is encoded in the alpha channel. Clever!

The alpha channel of the texture is the color of the surface of the moon.

Texture RGB channels are a normal map.
Having the correct texture coordinates, we will sample the RGBA channels. We need to unpack the normal map and perform a gamma correction of the surface color. Currently, the HLSL shader can be written like this, for example: The next step is to bind the normals, but only in the XY components. (In The Witcher 3, the Z axis is pointing up, and the entire Z-channel of the texture is 1.0). We can do it this way: Now it’s time for my favorite part of this shader. Take another look at lines 15-16: What is this mysterious 0.033864? At first it seems that there is no point in it, but if we calculate the inverse of it, we will get approximately 29.53, which is equal to the duration of the synodic month.
in the day! This is what I call attention to detail!
We can reliably assume that cb0 [0] .y is the number of days that have passed during the gameplay. Here, an additional deviation is used, which is used as an offset along the X axis of the texture.
Having received this coefficient, we multiply it by 2 * Pi.
Then, using sincos, we compute another 2d vector.
The calculation of the scalar product between the normal vector and the "lunar" vector simulates one phase of the moon. Look at the screenshots with different phases of the moon:


The final stage is a series of multiplication operations to calculate the final color. Perhaps you do not understand why this shader sends the alpha value 0.0 to the output. This is because the moon is rendered with blending turned on:

This approach allows you to get the color of the background (sky), if this shader returns black.
If you are interested in a complete shader, you can take it here . It has large constant buffers and it should already be ready for injection into RenderDoc instead of the original shader (just rename “MoonPS” to “EditedShaderPS”).
One last thing: I wanted to share the results with you:
On the left, my shader, on the right, the original shader from the game.
The difference is minimal and does not affect the results.

As you can see, this shader was pretty easy to recreate.
In this part, I’ll cover some of the details of the gbuffer in The Witcher 3.
We’ll assume that you know the basics of deferred shading.
A brief repetition: the idea of postponing is not to calculate all the finished lighting and shading at once, but to divide the calculations into two steps.
In the first (geometry pass) we fill the GBuffer with surface data (position, normals, specular color, etc ...), and in the second (illumination pass) we combine everything and calculate the illumination.
Deferred shading is a very popular approach because it allows you to calculate techniques such as tile deferred shading in a single full-screen pass , which greatly improves performance.
Simply put, GBuffer is a set of textures with geometry properties. It is very important to create the right structure for it. As an example from real life, you can explore Crysis 3 rendering technologies .
After this brief introduction, let's look at an example of a frame from The Witcher 3: Blood and Wine:

One of the many hotels in Tussent
The main GBuffer consists of three full-screen render target format DXGI_FORMAT_R8G8B8A8_UNORM and depth buffer + stencil format DXGI_FORMAT_D24_UNORM_S8_UINT.
Here are their screenshots:

Render Target 0 - RGB channels, surface color

Render Target 0 - alpha channel. Honestly, I have no idea what this information is.

Render Target 1 - RGB channels. Here we write the normal vectors in the interval [0-1].

Render Target 1 - alpha channel. It looks like reflectivity!

Render Target 2 - RGB channels. Looks like a specular color!
In this scene, the alpha channel is black (but later it is used).

Depth buffer Notice that the inverted depth is used here.

Stencil buffer used to mark a certain type of pixel (for example, skin, vegetation, etc.)
This is not the whole GBuffer. The lighting pass also uses lighting probes and other buffers, but I will not consider them in this article.
Before proceeding to the "main" part of the post, I will give general observations:
1) The only buffer to be cleared is the depth / stencil buffer.
If you analyze the above-mentioned textures in a good frame analyzer, then you will be a little surprised, because the “Clear” call is not used for them, with the exception of Depth / Stencil.
That is, in reality, RenderTarget1 looks like this (note the “blurry” pixels on the far plane):

This is a simple and smart optimization.
Important lesson: you need to waste resources on calls to ClearRenderTargetView , so use them only when necessary.
2) Inverted depth - it is cool
in many articles already written about the accuracy of the depth buffer with floating point. Witcher 3 uses reversed-z. This is a natural choice for such an open-world game and long-distance rendering.
It will be easy to switch to DirectX:
a) Clear the depth buffer with the entry “0”, not “1”.
In the traditional approach, the remote value “1” was used to clean the depth buffer. After the reversal of the depth, the new "long-range" value became 0, so you need to change everything.
b) Swap the near and far boundaries when calculating the projection matrix
c) Change the depth check from “less” to “more”
For OpenGL, a little more work needs to be done (see the articles mentioned above), but it's worth it.
3) Do not keep a position in the world
Yes, everything is so simple. In the aisle of the lighting position in the world recreate from the depths.
In this part, I wanted to show exactly the pixel shader that supplies surface data to GBuffer.
So now we already know how to store color, normals and specular.
Of course, everything is not as simple as you might think.
The problem with the pixel shader is that it has many options. They differ in the number of textures transferred to them and the number of parameters used from the buffer of constants (probably from the buffer of constants describing the material).
For analysis, I decided to use this beautiful barrel:

Our heroic barrel!
Please welcome textures:

So we have albedo, normal map and specular color. Pretty standard case.
Before we begin, a few words about the geometry input data:
Geometry is transmitted with position, texcoords, normal buffers, and tangents.
The vertex shader displays at least texcoords, normalized tangent / normal / tangent two-point vectors, previously multiplied by the world matrix. For more complex materials (for example, with two diffuse maps or two normal maps), the vertex shader can output other data, but I wanted to show a simple example here.
Pixel shader in assembler code: The shader consists of several stages. I will describe each major part of this shader separately.
But first, as usual - a screenshot with the values from the buffer of constants:

We start with complex things. This is not just“OutputColor.rgb = Texture.Sample (uv) .rgb”
After sampling the RGB texture of the color (line 1), the next 14 lines are what I call the “saturation reduction buffer”. Let me show the HLSL code: For most objects, this code does nothing but return the original color from the texture. This is achieved by the corresponding values of "material cbuffer". cb4_v1.x is set to 1.0, which returns a mask of 0.0, and returns the input color from the lerp instruction . However, there are some exceptions. The highest desaturationFactor I found is 4.0 (it is never less than 1.0), and desaturatedColor
depends on the material. It can be something like (0.2, 0.3, 0.4); there are no strict rules. Of course, I could not refrain from implementing this in my own DX11 framework, and here are the results, where all values of desaturatedColor are equal to float3 (0.25, 0.3, 0.45)

desaturationFactor = 1.0 (no effect)

desaturationFactor = 2.0

desaturationFactor = 3.0

desaturationFactor = 4.0
I’m sure it’s just the application of material parameters, but not the end of the part with albedo.
Lines 15-20 add the final touches: v0.z is the output from the vertex shader, and they are zero. Do not forget about this, because v0.z will be used a couple of times later. It seems that this is some kind of coefficient, and the whole code looks like a slight darkening of albedo, but since v0.z is 0, the color remains the same. HLSL: As for RT0.a, then, as we see, it is taken from the buffer of material constants, but since the shader does not have debugging information, it is difficult to say what it is. Possible translucency? We are done with the first render target!
Let's start by unpacking the normal map, and then, as usual, we will bind the normals: So far, nothing surprising. Look at lines 28-33: We can roughly write them as follows: Not sure if it is the right way to write. If you know what this mathematical operation is, let me know. We see that the pixel shader uses SV_IsFrontFace.
What it is?Documentation comes to help (I wanted to write “msdn”, but ...):
I wanted to check it out by myself. And in fact, the effect is noticeable only in wireframe mode. I suppose this code fragment is needed to correctly calculate the normals (and hence the lighting) in wireframe mode.
Here is a comparison: both colors of the frame of the finished scene with this enabled / disabled trick, as well as the texture normals of gbuffer [0-1] with the enabled / disabled trick:

Scene color without stunt

Color scene with a gimmick

Normals [0-1] without stunt

Normals [0-1] with a stunt.
Have you noticed that each render target in GBuffer has the format R8G8B8A8_UNORM? This means that there are 256 possible values per component. Is this enough to store normals?
Storing high-quality normals with enough bytes in Gbuffer is a well-known problem, but fortunately there are a lot of different materials to learn from .
Perhaps some of you already know which technique is used here. It must be said that in the whole passage of geometry there is one additional texture attached to slot 13 ...:

Ha! The Witcher 3 uses a technique called " Best Fit Normals ". Here I will not explain it in detail (see the presentation). It was invented by Crytek around 2009-2010, and since CryEngine is open source, BFN is also open source .
BFN gives the normal texture a “grainy” look.
After scaling the normals with BFN, we recode them from the interval [-1; 1] to [0, 1].
Let's start with line 34, and sample the specular texture: As you can see, here we have the “dimming” filter familiar to us from Albedo: Calculate the component with max. value, and then we calculate the “darkened” color and interpolate it with the original specular color, taking the parameter from the vertex shader ... which is 0, so at the output we get the color from the texture. HLSL:
I have no idea if this name is appropriate for this parameter, because I don’t know how it affects the lighting passage. The fact is that the alpha channel of the input normal map contains additional data:

Alpha channel texture "normal maps".
Assembler code: Say hello to our old friend - v0.z! Its meaning is similar to albedo and specular:
Fine!This is the end of the analysis of the first variant of the pixel shader.
Here is a comparison of my shader (left) with the original (right):

These differences do not affect the calculations, so my work here is finished.
I decided to show another option, now only with albedo maps and normals, without a specular texture. The assembler code is slightly longer: The difference between this and the previous versions is as follows: a) lines 1, 19 : the interpolation parameter v0.z is multiplied by cb4 [0] .x from the constant buffer, but this product is used only for the interpolation albedo in line 19. For other outputs, the “normal” value of v0.z is used. b) lines 54-55 : o2.w is now set, provided that (cb4 [7] .x> 0.0) We already recognize this pattern “some comparison - AND” from the calculation of the brightness histogram. It can be written like this: c) lines 34-42 : a completely different specular calculation.
There is no specular texture here. Let's take a look at the assembly code responsible for this part: Notice what we used here (1 is the reflected ability). Fortunately, in HLSL it is quite simple to write: I will add that in this variant the buffer of constants with these materials is slightly more. Here, these additional values are used to emulate a specular color. The rest of the shader is the same as in the previous version. 72 lines of assembly code is too much to display in WinMerge, so take my word for it: my code is almost the same as in the original. Or you can download my HLSLexplorer and see for yourself!
... and if you have read this far, then you may want to go a bit more deeply.
What seems simple in real life is often not so, and data transfer to the gbuffer The Witcher 3 is no exception. I showed you only the simplest versions of pixel shaders responsible for it, and also cited general observations that relate to deferred shadowing in general.
For the most patient, there are two options for pixel shaders in pastebin:
Option 1 - with a specular texture
Option 2 - without a specular texture
In this part, we will look at a wonderful atmospheric effect, which I like very much - the distant rain / light curtains near the horizon. In the game they are easiest to meet on the Skellige Islands.
Personally, I really like this atmospheric phenomenon and was curious how the graphics programmers CD Projekt Red implemented it. Let's figure it out!
Here are two screenshots before and after applying rain curtains:

Before the rain curtains

After the rain curtains
First we will focus on geometry. The idea is to use a small cylinder:

A cylinder in a local space
From the point of view of its position in a local space, it is small enough - its position is in the interval (0.0 - 1.0).
The input scheme for this render call looks like this ...

The following is important to us here: Texcoords and Instance_Transform.
Texcoords are wrapped quite simply: U of the upper and lower bases are in the interval [0.02777 - 1.02734]. V on the bottom base is 1.0, and on the top base 0.0. As you can see, you can quite simply create this mesh, even procedurally.
After receiving this small cylinder in local space, we multiply it by the world matrix provided for each instance of the INSTANCE_TRANSFORM input element. Let's check the values of this matrix:



Looks pretty scary, right? But do not worry, we will analyze this matrix and see what it hides! The results are very interesting: It is important to know the position of the camera in this particular frame: (-116.5338, 234.8695, 2.09) As you can see, we scaled the cylinder to make it quite large in global space (in TW3, the Z axis is up), moved it relative to the camera position and turned. Here is what the cylinder looks like after the vertex shader transforms:

Cylinder after conversion by vertex shader. See how it is located relative to the visibility pyramid.
The input geometry and the vertex shader are strictly dependent on each other.
Let's take a closer look at the vertex shader assembler code: Along with the simple transfer Texcoords (line 0) and Instance_LOD_Params (line 8), two more elements are needed for output: SV_Position (obviously) and Height (component .z) of the world's position. Remember that local space is in the range [0-1]? So, right before applying the world matrix, the vertex shader uses scale and deflection to change the local position. Smart move! In this case, scale = float3 (4, 4, 2), and bias = float3 (-2, -2, -1). < The pattern that is visible between lines 9 and 28 is the multiplication of two row-major-matrices. Let's just look at the finished vertex shader on HLSL:
Comparison of my shader (left) and original (right):

Differences do not affect calculations. I performed an injection of my shader into the frame and everything was still fine!
Finally! First, I’ll show you the input data:
Two textures are used here: the noise texture and the depth buffer:


Values from constant buffers:




And pixel shader assembly code:
Wow!Quite a large amount, but in fact everything is not so bad.
What is going on here? First, we calculate animated UV using the elapsed time from the cbuffer (cb0 [0] .x) and scale / offset. These texcoords are used for sampling from the noise texture (line 2).
Having obtained the noise value from the texture, we interpolate between the min / max values (usually 0 and 1).
Then we perform multiplications, for example, on the coordinate of the texture V (remember that the coordinate V goes from 1 to 0?) - line 5.
Thus, we calculated the “brightness mask” - it looks like this:

Note that distant objects (lighthouse, mountains ...) are gone. This happened because the cylinder passes the depth test - the cylinder is not in the far plane and is drawn over these objects:

Depth test
We want to simulate the fact that the rain curtain is on (but not necessarily on the far plane). To do this, we compute another mask, the “mask of distant objects.”
It is calculated by the following formula:
(0.001 is taken from the buffer), which gives us the necessary mask:

(In the part about the Sharpen effect, I have already superficially explained how the depth of the pyramid of visibility is retrieved from the depth buffer.)
Personally, it seems to me that this effect could be implemented less costly without calculating the height in global space by multiplying the depth of the pyramid of visibility by a smaller number, 0.0004.
By multiplying both masks, the final is obtained:

After receiving this final mask (line 16), we perform another interpolation, doing almost nothing (at least in the tested case), and then multiply the final mask by the curtain color (line 19), perform gamma correction (line 20 -22) and final multiplications (23-24).
At the end, we return a color with zero alpha value. This is done because mixing is enabled on this aisle:
If you are not quite
sure how mixing works, here’s a brief explanation: SourceColor is the output RGB data from the pixel shader, and DestColor is the current RGB color of the pixel in the render target . Since SourceAlpha always equal to 0.0, the above equation reduces to:
Simply put, here we do additive blending. If the pixel shader returns (0, 0, 0), then the color will remain the same.
Here is the ready HLSL code - I think that after the explanation it will be much easier to understand it: I can happily say that my pixel shader creates the same assembler code as in the original. I hope you enjoyed the article. Thanks for reading!
Part 6. Sharpen
In this section, we take a closer look at another post-processing effect from The Witcher 3 - Sharpen.
Sharpening makes the output image a little clearer. This effect is known to us from Photoshop and other graphic editors.
In The Witcher 3, sharpening has two options: low and high. I will tell about the difference between them below, but for now let's take a look at the screenshots:
Option "Low" - to
“Low” option - after
Option "High" - to
Option “High” - after
If you want to take a look at more detailed (interactive) comparisons, then look at the section in the Nvidia The Witcher 3 manual . As you can see, the effect is especially noticeable on grass and foliage.
In this part of the post we will study the frame from the very beginning of the game: I chose it intentionally, because here we see the relief (the long distance of drawing) and the dome of the sky.
From the point of view of input data, sharpening requires a color buffer t0 (LDR after tone correction and lens flares) and a depth buffer t1 .
Let's examine the pixel shader assembler code:
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb3[3], immediateIndexed
dcl_constantbuffer cb12[23], immediateIndexed
dcl_sampler s0, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_input_ps_siv v0.xy, position
dcl_output o0.xyzw
dcl_temps 7
0: ftoi r0.xy, v0.xyxx
1: mov r0.zw, l(0, 0, 0, 0)
2: ld_indexable(texture2d)(float,float,float,float) r0.x, r0.xyzw, t1.xyzw
3: mad r0.x, r0.x, cb12[22].x, cb12[22].y
4: mad r0.y, r0.x, cb12[21].x, cb12[21].y
5: max r0.y, r0.y, l(0.000100)
6: div r0.y, l(1.000000, 1.000000, 1.000000, 1.000000), r0.y
7: mad_sat r0.y, r0.y, cb3[1].z, cb3[1].w
8: add r0.z, -cb3[1].x, cb3[1].y
9: mad r0.y, r0.y, r0.z, cb3[1].x
10: add r0.y, r0.y, l(1.000000)
11: ge r0.x, r0.x, l(1.000000)
12: movc r0.x, r0.x, l(0), l(1.000000)
13: mul r0.z, r0.x, r0.y
14: round_z r1.xy, v0.xyxx
15: add r1.xy, r1.xyxx, l(0.500000, 0.500000, 0.000000, 0.000000)
16: div r1.xy, r1.xyxx, cb3[0].zwzz
17: sample_l(texture2d)(float,float,float,float) r2.xyz, r1.xyxx, t0.xyzw, s0, l(0)
18: lt r0.z, l(0), r0.z
19: if_nz r0.z
20: div r3.xy, l(0.500000, 0.500000, 0.000000, 0.000000), cb3[0].zwzz
21: add r0.zw, r1.xxxy, -r3.xxxy
22: sample_l(texture2d)(float,float,float,float) r4.xyz, r0.zwzz, t0.xyzw, s0, l(0)
23: mov r3.zw, -r3.xxxy
24: add r5.xyzw, r1.xyxy, r3.zyxw
25: sample_l(texture2d)(float,float,float,float) r6.xyz, r5.xyxx, t0.xyzw, s0, l(0)
26: add r4.xyz, r4.xyzx, r6.xyzx
27: sample_l(texture2d)(float,float,float,float) r5.xyz, r5.zwzz, t0.xyzw, s0, l(0)
28: add r4.xyz, r4.xyzx, r5.xyzx
29: add r0.zw, r1.xxxy, r3.xxxy
30: sample_l(texture2d)(float,float,float,float) r1.xyz, r0.zwzz, t0.xyzw, s0, l(0)
31: add r1.xyz, r1.xyzx, r4.xyzx
32: mul r3.xyz, r1.xyzx, l(0.250000, 0.250000, 0.250000, 0.000000)
33: mad r1.xyz, -r1.xyzx, l(0.250000, 0.250000, 0.250000, 0.000000), r2.xyzx
34: max r0.z, abs(r1.z), abs(r1.y)
35: max r0.z, r0.z, abs(r1.x)
36: mad_sat r0.z, r0.z, cb3[2].x, cb3[2].y
37: mad r0.x, r0.y, r0.x, l(-1.000000)
38: mad r0.x, r0.z, r0.x, l(1.000000)
39: dp3 r0.y, l(0.212600, 0.715200, 0.072200, 0.000000), r2.xyzx
40: dp3 r0.z, l(0.212600, 0.715200, 0.072200, 0.000000), r3.xyzx
41: max r0.w, r0.y, l(0.000100)
42: div r1.xyz, r2.xyzx, r0.wwww
43: add r0.y, -r0.z, r0.y
44: mad r0.x, r0.x, r0.y, r0.z
45: max r0.x, r0.x, l(0)
46: mul r2.xyz, r0.xxxx, r1.xyzx
47: endif
48: mov o0.xyz, r2.xyzx
49: mov o0.w, l(1.000000)
50: ret50 lines of assembler code look like a feasible task. Let's get to its solution.
Sharpen value generation
The first stage is to load ( Load ) the depth buffer (line 1). It is worth noting that the "Witcher 3" uses an inverted depth (1.0 - close, 0.0 - far). As you may know, the hardware depth is tied nonlinearly (see this article for details ).
Lines 3-6 perform a very interesting way of binding this hardware depth [1.0 - 0.0] to the values [near-far] (we set them at the MatrixPerspectiveFov stage). Consider the values from the constant buffer:
Having a “close” value of 0.2, and a “far” value of 5000, we can calculate the values of cb12_v21.xy as follows:
cb12_v21.y = 1.0 / near
cb12_v21.x = - (1.0 / near) + (1.0 / near) * (near / far)This code fragment is quite common in TW3 shaders, so I think this is just a function.
After obtaining the “depth of visibility pyramid” line 7 uses scale / distortion to create an interpolation coefficient (here we use saturate to limit the values to [0-1]).
cb3_v1.xy and cb3_v2.xy is the brightness of the sharpening effect at near and far distances. Let's call them "sharpenNear" and "sharpenFar". And this is the only difference between the “Low” and “High” options of this effect in The Witcher 3.
Now it is time to use the resulting coefficient. Lines 8-9 just perform
lerp(sharpenNear, sharpenFar, interpolationCoeff) . What is it for? Due to this we get different brightness near Geralt and far from it. Take a look:Perhaps this is barely noticeable, but here we interpolate, based on the distance, the brightness of the sharpen next to the player (2.177151) and the brightness of the effect very far (1.91303). After this calculation, we add to the brightness 1.0 (line 10). Why do you need it? Suppose that the operation lerp shown above gave us 0.0. After adding 1.0, we naturally get 1.0, and this value will not affect the pixel when performing sharpening. Read more about this below.
While adding sharpness, we do not want to affect the sky. This can be achieved by adding a simple conditional check:
// Не выполнять sharpen для неба
float fSkyboxTest = (fDepth >= 1.0) ? 0 : 1;In The Witcher 3, the pixel depth of the sky is 1.0, so we use it to get a kind of “binary filter” (interesting fact: in this case, step will not work properly).
Now we can multiply the interpolated brightness by the “sky filter”:
This multiplication is performed in line 13.
Shader code example:
// Вычисление финального значения sharpen
float fSharpenAmount = fSharpenIntensity * fSkyboxTest;Pixel Sampling Center
In SV_Position there is an aspect that will be important here: an offset of half a pixel . It turns out that this pixel in the upper left corner (0, 0) has coordinates not (0, 0) from the point of view of SV_Position.xy, but (0.5, 0.5). Wow!
Here we want to take a sample in the center of the pixel, so let's look at lines 14-16. You can write them on HLSL:
// Сэмплируем центр пикселя.
// Избавляемся от "половинопиксельного" смещения в SV_Position.xy.
float2 uvCenter = trunc( Input.Position.xy );
// Прибавляем половину пикселя, чтобы мы сэмплировали именно центр пикселя
uvCenter += float2(0.5, 0.5);
uvCenter /= g_Viewport.xyAnd later, we sample the color input texture from texcoords uvCenter. Do not worry, the result of the sampling will be the same as in the “normal” method (SV_Position.xy / ViewportSize.xy).
To sharpen or not to sharpen
The decision about whether to use sharpen depends on fSharpenAmount.
// Получаем значение текущего пикселя
float3 colorCenter = TexColorBuffer.SampleLevel( samplerLinearClamp, uvCenter, 0 ).rgb;
// Финальный результат
float3 finalColor = colorCenter;
if ( fSharpenAmount > 0 )
{
// здесь выполняем sharpening...
}
return float4( finalColor, 1 );Sharpen
It's time to look at the insides of the algorithm itself.
In essence, it performs the following actions:
- samples four times the input color texture at the corners of the pixel,
- adds samples and calculates the average value,
- calculates the difference between "center" and "cornerAverage",
- finds the maximum absolute component of the difference,
- adjusts max. abs component using scale + bias values
- determines the effect size using max. abs component,
- calculates the brightness value (luma) for "centerColor" and "averageColor",
- divides the colorCenter into its luma,
- calculates a new, interpolated luma value based on the magnitude of the effect,
- multiplies the colorCenter by the new value of luma.
Quite a lot of work, and it was difficult for me to figure it out, because I never experimented with sharpness filters.
Let's start with the sampling pattern. As you can see in the assembly code, four texture reads are performed.
It would be best to show this with a pixel image as an example (the artist’s skill level is an expert ):
All reads in the shader use bilinear sampling (D3D11_FILTER_MIN_MAG_LINEAR_MIP_POINT).
The offset from the center to each of the angles is (± 0.5, ± 0.5), depending on the angle.
See how it can be implemented on HLSL? Let's get a look:
float2 uvCorner;
float2 uvOffset = float2( 0.5, 0.5 ) / g_Viewport.xy; // remember about division!
float3 colorCorners = 0;
// Верхний левый угол
// -0,5, -0.5
uvCorner = uvCenter - uvOffset;
colorCorners += TexColorBuffer.SampleLevel( samplerLinearClamp, uvCorner, 0 ).rgb;
// Верхний правый угол
// +0.5, -0.5
uvCorner = uvCenter + float2(uvOffset.x, -uvOffset.y);
colorCorners += TexColorBuffer.SampleLevel( samplerLinearClamp, uvCorner, 0 ).rgb;
// Нижний левый угол
// -0.5, +0.5
uvCorner = uvCenter + float2(-uvOffset.x, uvOffset.y);
colorCorners += TexColorBuffer.SampleLevel( samplerLinearClamp, uvCorner, 0 ).rgb;
// Нижний правый угол
// +0.5, +0.5
uvCorner = uvCenter + uvOffset;
colorCorners += TexColorBuffer.SampleLevel( samplerLinearClamp, uvCorner, 0 ).rgb;So now all four samples are summarized in the variable “colorCorners”. Let's follow these steps:
// Вычисляем среднее четырёх углов
float3 averageColorCorners = colorCorners / 4.0;
// Вычисляем разность цветов
float3 diffColor = colorCenter - averageColorCorners;
// Находим макс. абс. RGB-компонент разности
float fDiffColorMaxComponent = max( abs(diffColor.x), max( abs(diffColor.y), abs(diffColor.z) ) );
// Корректируем этот коэффициент
float fDiffColorMaxComponentScaled = saturate( fDiffColorMaxComponent * sharpenLumScale + sharpenLumBias );
// Вычисляем необходимую величину резкости пикселя.
// Заметьте здесь "1.0" - именно поэтому мы прибавили в fSharpenIntensity значение 1.0.
float fPixelSharpenAmount = lerp(1.0, fSharpenAmount, fDiffColorMaxComponentScaled);
// Вычисляем яркость "центра" пикселя и яркость среднего значения.
float lumaCenter = dot( LUMINANCE_RGB, finalColor );
float lumaCornersAverage = dot( LUMINANCE_RGB, averageColorCorners );
// делим "centerColor" на его яркость
float3 fColorBalanced = colorCenter / max( lumaCenter, 1e-4 );
// Вычисляем новую яркость
float fPixelLuminance = lerp(lumaCornersAverage, lumaCenter, fPixelSharpenAmount);
// Вычисляем цвет на выходе
finalColor = fColorBalanced * max(fPixelLuminance, 0.0);
}
return float4(finalColor, 1.0);Edge recognition is performed by calculating max. abs the difference component. Smart move! See his visualization:
Visualization of the maximum absolute difference component.
Fine. Ready HLSL-shader posted here . Sorry for the pretty bad formatting. You can use my HLSLexplorer program and experiment with the code.
I am happy to say that the above code creates the same assembler code as in the game!
To summarize: The Witcher 3's sharpness shader is very well written (note that fPixelSharpenAmount is greater than 1.0! That's interesting ...). In addition, the main way to change the brightness of the effect is the brightness of near / far objects. In this game, they are not constants; I collected a few examples of the values:
Skellige:
| sharpenNear | sharpenFar | sharpenDistanceScale | sharpenDistanceBias | sharpenLumScale | sharpenLumBias | |
|---|---|---|---|---|---|---|
| low | ||||||
| high | 2.0 | 1.8 | 0.025 | -0.25 | -13.33333 | 1.33333 |
Kaer Morhen:
| sharpenNear | sharpenFar | sharpenDistanceScale | sharpenDistanceBias | sharpenLumScale | sharpenLumBias | |
|---|---|---|---|---|---|---|
| low | 0.57751 | 0.31303 | 0.06665 | -0.33256 | -1.0 | 2.0 |
| high | 2.17751 | 1.91303 | 0.06665 | -0.33256 | -1.0 | 2.0 |
Part 7. Average brightness
The operation of calculating the average brightness of the current frame can be found in almost any modern video game. This value is often used later for the effect of eye adaptation and tonal correction (see the previous part of the post). In simple solutions, a brightness calculation is used for, say, a texture of 512 2 in size, then its mip-level calculation and application of the latter. This usually works, but it severely limits the possibilities. More complex solutions use computational shaders that perform, for example, parallel reduction .
Let's find out how the CD Projekt Red team solved this problem in The Witcher 3. In the previous part, I have already investigated the tonal correction and adaptation of the eye, so the only remaining piece of the puzzle remained the average brightness.
To begin with, the calculation of the average brightness of The Witcher 3 consists of two passes. For clarity, I decided to break them into separate parts, and first we will consider the first pass - “brightness distribution” (calculation of the brightness histogram).
Brightness distribution
These two passes are fairly easy to find in any frame analyzer. These are proceeding calls to Dispatch right before the eye adapts:
Let's look at the input for this pass. He needs two textures:
1) HDR-buffer color, the scale of which is reduced to 1/4 x 1/4 (for example, from 1920x1080 to 480x270),
2) Full screen depth buffer
HDR color buffer with 1/4 x 1/4 resolution. Note the tricky trick - this buffer is part of a larger buffer. Reusing buffers is good practice.
Full screen depth buffer
Why scale down the color buffer? I think it's all about performance.
As for the output of this pass, it is a structured buffer. 256 elements of 4 bytes each.
Here, shaders have no debug information, so suppose that this is just a buffer of unsigned int values.
Important: the first stage of the calculation of the average brightness causes ClearUnorderedAccessViewUint to reset all the elements of the structured buffer.
Let's examine the assembler code of the computational shader (this is the first computational shader for our entire analysis!)
cs_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[3], immediateIndexed
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_uav_structured u0, 4
dcl_input vThreadGroupID.x
dcl_input vThreadIDInGroup.x
dcl_temps 6
dcl_tgsm_structured g0, 4, 256
dcl_thread_group 64, 1, 1
0: store_structured g0.x, vThreadIDInGroup.x, l(0), l(0)
1: iadd r0.xyz, vThreadIDInGroup.xxxx, l(64, 128, 192, 0)
2: store_structured g0.x, r0.x, l(0), l(0)
3: store_structured g0.x, r0.y, l(0), l(0)
4: store_structured g0.x, r0.z, l(0), l(0)
5: sync_g_t
6: ftoi r1.x, cb0[2].z
7: mov r2.y, vThreadGroupID.x
8: mov r2.zw, l(0, 0, 0, 0)
9: mov r3.zw, l(0, 0, 0, 0)
10: mov r4.yw, l(0, 0, 0, 0)
11: mov r1.y, l(0)
12: loop
13: utof r1.z, r1.y
14: ge r1.z, r1.z, cb0[0].x
15: breakc_nz r1.z
16: iadd r2.x, r1.y, vThreadIDInGroup.x
17: utof r1.z, r2.x
18: lt r1.z, r1.z, cb0[0].x
19: if_nz r1.z
20: ld_indexable(texture2d)(float,float,float,float) r5.xyz, r2.xyzw, t0.xyzw
21: dp3 r1.z, r5.xyzx, l(0.212600, 0.715200, 0.072200, 0.000000)
22: imul null, r3.xy, r1.xxxx, r2.xyxx
23: ld_indexable(texture2d)(float,float,float,float) r1.w, r3.xyzw, t1.yzwx
24: eq r1.w, r1.w, cb0[2].w
25: and r1.w, r1.w, cb0[2].y
26: add r2.x, -r1.z, cb0[2].x
27: mad r1.z, r1.w, r2.x, r1.z
28: add r1.z, r1.z, l(1.000000)
29: log r1.z, r1.z
30: mul r1.z, r1.z, l(88.722839)
31: ftou r1.z, r1.z
32: umin r4.x, r1.z, l(255)
33: atomic_iadd g0, r4.xyxx, l(1)
34: endif
35: iadd r1.y, r1.y, l(64)
36: endloop
37: sync_g_t
38: ld_structured r1.x, vThreadIDInGroup.x, l(0), g0.xxxx
39: mov r4.z, vThreadIDInGroup.x
40: atomic_iadd u0, r4.zwzz, r1.x
41: ld_structured r1.x, r0.x, l(0), g0.xxxx
42: mov r0.w, l(0)
43: atomic_iadd u0, r0.xwxx, r1.x
44: ld_structured r0.x, r0.y, l(0), g0.xxxx
45: atomic_iadd u0, r0.ywyy, r0.x
46: ld_structured r0.x, r0.z, l(0), g0.xxxx
47: atomic_iadd u0, r0.zwzz, r0.x
48: retAnd the buffer of constants:
We already know that the first input is the HDR color buffer. With FullHD, its resolution is 480x270. Let's look at the Dispatch call.
Dispatch (270, 1, 1) - this means that we run 270 groups of threads. Simply put, we run one thread group for each row of the color buffer.
Each thread group executes one line of HDR buffer of colors.
Now that we have this context, let's try to figure out what the shader is doing.
Each thread group has 64 threads in the X direction (dcl_thread_group 64, 1, 1), as well as shared memory, 256 elements with 4 bytes each (dcl_tgsm_structured g0, 4, 256).
Note that in the shader we use SV_GroupThreadID (vThreadIDInGroup.x) [0-63] and SV_GroupID (vThreadGroupID.x) [0-269].
1) We begin by assigning zero values to all elements of shared memory. Since the total memory contains 256 elements and 64 threads per group, this can be conveniently done using a simple loop:
// Первый шаг - присвоение всем общим данным нулевых значений.
// Так как в каждой группе потоков есть 64 потока, каждый из них может с помощью простого смещения обнулить 4 элемента.
[unroll] for (uint idx=0; idx < 4; idx++)
{
const uint offset = threadID + idx*64;
shared_data[ offset ] = 0;
}2) After that we set a barrier using GroupMemoryBarrierWithGroupSync (sync_g_t). We do this to ensure that all the threads in the shared memory of the groups are reset to zero before proceeding to the next stage.
3) Now we are performing a loop that can be roughly written like this:
// cb0_v0.x - это ширина буфера цветов уменьшенного масштаба. Для 1920x1080 она равна 1920/4 = 480;
float ViewportSizeX = cb0_v0.x;
[loop] for ( uint PositionX = 0; PositionX < ViewportSizeX; PositionX += 64 )
{
...This is a simple for loop with an increment of 64 (did you already understand why?).
The next step is the calculation of the position of the loaded pixel.
Let's think about it.
For the Y coordinate, we can use SV_GroupID.x, because we launched 270 thread groups.
For the X coordinate, we ... can take advantage of the current group flow! Let's try to do it.
Since there are 64 streams in each group, this solution will bypass all the pixels.
Consider a group of threads (0, 0, 0).
- The stream (0, 0, 0) will process the pixels (0, 0), (64, 0), (128, 0), (192, 0), (256, 0), (320, 0), (384, 0), (448, 0).
- The stream (1, 0, 0) will process the pixels (1, 0), (65, 0), (129, 0), (193, 0), (257, 0), (321, 0), (385, 0), (449, 0) ...
- The stream (63, 0, 0) will process the pixels (63, 0), (127, 0), (191, 0), (255, 0), (319, 0), (383, 0), (447, 0)
Thus, all pixels will be processed.
We also need to ensure that we do not load pixels from outside the color buffer:
// Мы попиксельно перемещаемся вдоль оси X. Значение Y равно GroupID.
uint CurrentPixelPositionX = PositionX + threadID;
uint CurrentPixelPositionY = groupID;
if ( CurrentPixelPositionX < ViewportSizeX )
{
// HDR-буфер цветов.
// Вычисляем позицию HDR-буфера цветов в экранном пространстве, загружаем его и вычисляем яркость.
uint2 colorPos = uint2(CurrentPixelPositionX, CurrentPixelPositionY);
float3 color = texture0.Load( int3(colorPos, 0) ).rgb;
float luma = dot(color, LUMA_RGB);Do you see? It's pretty simple!
I also calculated the brightness (line 21 of the assembler code).
Great, we've already calculated the brightness from the color pixel. The next step is to load (not sampling!) The corresponding depth value.
But here we have a problem, because we have connected a full resolution depth buffer. What to do with it?
It is surprisingly simple - just multiply the colorPos by some constant (cb0_v2.z). We reduced the HDR buffer color by a factor of four. so the value will be 4!
const int iDepthTextureScale = (int) cb0_v2.z;
uint2 depthPos = iDepthTextureScale * colorPos;
float depth = texture1.Load( int3(depthPos, 0) ).x;So far everything is great! But ... we reached lines 24-25 ...
24: eq r2.x, r2.x, cb0[2].w
25: and r2.x, r2.x, cb0[2].ySo. First, we have a comparison of equality with a floating point, its result is written in r2.x, and immediately after that comes ... what? Bitwise And ?? Seriously? For floating point values? What the heck???
Problem 'eq + and'
Let me just say that for me it was the hardest part of the shader. I even tried strange combinations asint / asfloat ...
And if you use a slightly different approach? Let's just do the usual float-float comparison in HLSL.
float DummyPS() : SV_Target0
{
float test = (cb0_v0.x == cb0_v0.y);
return test;
}And this is what output in assembly code looks like:
0: eq r0.x, cb0[0].y, cb0[0].x
1: and o0.x, r0.x, l(0x3f800000)
2: retInteresting, right? I did not expect to see here "and".
0x3f800000 is just 1.0f ... It makes sense, because if we get a success, the comparison is 1.0 and 0.0 otherwise.
What if we "replace" 1.0 with some other value? For example:
float DummyPS() : SV_Target0
{
float test = (cb0_v0.x == cb0_v0.y) ? cb0_v0.z : 0.0;
return test;
}We get the following result:
0: eq r0.x, cb0[0].y, cb0[0].x
1: and o0.x, r0.x, cb0[0].z
2: retHa! It worked. This is just the magic of the HLSL compiler. Note: if we replace 0.0 with something else, then we simply get movc.
Let's return to the computational shader. The next step is to check if the depth is equal to the value of cb0_v2.w. It is always 0.0 - in other words, we check whether the pixel is in the far plane (in the sky). If yes, then we assign some value to this coefficient, approximately 0.5 (I checked on several frames).
This calculated coefficient is used to interpolate between the brightness of the color and the brightness of the "sky" (the value of cb0_v2.x, which is often about 0.0). I assume that it is necessary to control the importance of the sky in calculating the average brightness. Usually the importance decreases. Very clever idea.
// Проверяем, лежит ли пиксель на дальней плоскости (в небе). Если да, то мы можем указать, как он будет
// смешиваться с нашими значениями.
float value = (depth == cb0_v2.w) ? cb0_v2.y : 0.0;
// Если 'value' равно 0.0, то эта lerp просто даёт нам 'luma'. Однако если 'value' отличается
// (часто около 0.50), то вычисленное luma имеет гораздо меньший вес. (cb0_v2.x обычно близко к 0.0).
float lumaOk = lerp( luma, cb0_v2.x, value );Since we have lumaOk, the next step is to calculate its natural logarithm to create a good distribution. But wait, say, lumaOk is 0.0. We know that the value of log (0) is undefined, so we add 1.0, because log (1) = 0.0.
After that, we scale the calculated logarithm by 128 to distribute it to 256 cells. Very clever!
And it is from here that this value is taken 88.722839. This is
128 * натуральный логарифм (2) .This is just the way HLSL calculates logarithms.
In the HLSL assembly code, there is only one function that calculates logarithms: log , and it has base 2.
// Предположим, что lumaOk равно 0.0.
// log(0) имеет значение undefined
// log(1) = 0.
// вычисляем натуральный логарифм яркости
lumaOk = log(lumaOk + 1.0);
// Масштабируем логарифм яркости на 128
lumaOk *= 128;Finally, we calculate the cell index from the log-distributed brightness and add 1 to the corresponding cell in the shared memory.
// Вычисляем правильный индекс. Значение имеет формат Uint, поэтому в массиве 256 элементов,
// нужно убедиться, что мы не вышли за границы.
uint uLuma = (uint) lumaOk;
uLuma = min(uLuma, 255);
// Прибавляем 1 к соответствующему значению яркости.
InterlockedAdd( shared_data[uLuma], 1 );The next step is to install the barrier again to ensure that all the pixels in the row were processed.
And the final step is to add values from shared memory to a structured buffer. This is done in the same way, through a simple loop:
// Ждём, пока обработаются все пиксели в строке
GroupMemoryBarrierWithGroupSync();
// Прибавление вычисленных значений в структурированный буфер.
[unroll] for (uint idx = 0; idx < 4; idx++)
{
const uint offset = threadID + idx*64;
uint data = shared_data[offset];
InterlockedAdd( g_buffer[offset], data );
}After all 64 streams in a stream group fill the common data, each stream adds 4 values to the output buffer.
Consider an output buffer. Let's think about it. The sum of all values in the buffer is equal to the total number of pixels! (at 480x270 = 129 600). That is, we know how many pixels have a specific brightness value.
If you have little understanding of computational shaders (like me), then at first it may not be clear, so read the post a few more times, take paper and a pencil, and try to understand the concepts on which this technique is built.
That's all! That is how "The Witcher 3" calculates the brightness histogram. Personally, I have learned a lot when writing this part. Congratulations to the guys from Projekt Red CD with excellent work!
If you are interested in a full HLSL shader, then it is posted here . I always strive to get as close as possible to the game assembly code and I am absolutely happy that I succeeded again!
Average brightness calculation
This is the second part of the analysis of average brightness calculations in “The Witcher 3: Wild Hunt”.
Before we fight another computational shader, let's briefly repeat what happened in the last part: we worked with an HDR color buffer with a scale reduced to 1 / 4x1 / 4. After the first pass, we got a histogram of brightness (structured buffer of 256 unsigned integer values). We calculated the logarithm for the brightness of each pixel, distributed it to 256 cells and increased the corresponding value of the structured buffer by 1 per pixel. Due to this, the total sum of all values in these 256 cells is equal to the number of pixels.
An example of the output of the first pass. Here are 256 elements.
For example, our fullscreen buffer is 1920x1080. After zooming out, the first pass used a 480x270 buffer. The sum of all 256 values in the buffer will be equal to 480 * 270 = 129 600.
After this brief introduction, we are ready to proceed to the next stage: to calculations.
This time only one thread group is used (Dispatch (1, 1, 1)).
Let's take a look at the compiler shader assembly code:
cs_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[1], immediateIndexed
dcl_uav_structured u0, 4
dcl_uav_typed_texture2d (float,float,float,float) u1
dcl_input vThreadIDInGroup.x
dcl_temps 4
dcl_tgsm_structured g0, 4, 256
dcl_thread_group 64, 1, 1
0: ld_structured_indexable(structured_buffer, stride=4)(mixed,mixed,mixed,mixed) r0.x, vThreadIDInGroup.x, l(0), u0.xxxx
1: store_structured g0.x, vThreadIDInGroup.x, l(0), r0.x
2: iadd r0.xyz, vThreadIDInGroup.xxxx, l(64, 128, 192, 0)
3: ld_structured_indexable(structured_buffer, stride=4)(mixed,mixed,mixed,mixed) r0.w, r0.x, l(0), u0.xxxx
4: store_structured g0.x, r0.x, l(0), r0.w
5: ld_structured_indexable(structured_buffer, stride=4)(mixed,mixed,mixed,mixed) r0.x, r0.y, l(0), u0.xxxx
6: store_structured g0.x, r0.y, l(0), r0.x
7: ld_structured_indexable(structured_buffer, stride=4)(mixed,mixed,mixed,mixed) r0.x, r0.z, l(0), u0.xxxx
8: store_structured g0.x, r0.z, l(0), r0.x
9: sync_g_t
10: if_z vThreadIDInGroup.x
11: mul r0.x, cb0[0].y, cb0[0].x
12: ftou r0.x, r0.x
13: utof r0.y, r0.x
14: mul r0.yz, r0.yyyy, cb0[0].zzwz
15: ftoi r0.yz, r0.yyzy
16: iadd r0.x, r0.x, l(-1)
17: imax r0.y, r0.y, l(0)
18: imin r0.y, r0.x, r0.y
19: imax r0.z, r0.y, r0.z
20: imin r0.x, r0.x, r0.z
21: mov r1.z, l(-1)
22: mov r2.xyz, l(0, 0, 0, 0)
23: loop
24: breakc_nz r2.x
25: ld_structured r0.z, r2.z, l(0), g0.xxxx
26: iadd r3.x, r0.z, r2.y
27: ilt r0.z, r0.y, r3.x
28: iadd r3.y, r2.z, l(1)
29: mov r1.xy, r2.yzyy
30: mov r3.z, r2.x
31: movc r2.xyz, r0.zzzz, r1.zxyz, r3.zxyz
32: endloop
33: mov r0.w, l(-1)
34: mov r1.yz, r2.yyzy
35: mov r1.xw, l(0, 0, 0, 0)
36: loop
37: breakc_nz r1.x
38: ld_structured r2.x, r1.z, l(0), g0.xxxx
39: iadd r1.y, r1.y, r2.x
40: utof r2.x, r2.x
41: utof r2.w, r1.z
42: add r2.w, r2.w, l(0.500000)
43: mul r2.w, r2.w, l(0.011271)
44: exp r2.w, r2.w
45: add r2.w, r2.w, l(-1.000000)
46: mad r3.z, r2.x, r2.w, r1.w
47: ilt r2.x, r0.x, r1.y
48: iadd r2.w, -r2.y, r1.y
49: itof r2.w, r2.w
50: div r0.z, r3.z, r2.w
51: iadd r3.y, r1.z, l(1)
52: mov r0.y, r1.z
53: mov r3.w, r1.x
54: movc r1.xzw, r2.xxxx, r0.wwyz, r3.wwyz
55: endloop
56: store_uav_typed u1.xyzw, l(0, 0, 0, 0), r1.wwww
57: endif
58: retThere is one constant buffer:
Briefly take a look at the assembler code: two UAVs are attached (u0: input buffer from the first part and u1: output texture of 1x1 format R32_FLOAT). We also see that there are 64 streams per group and 256 elements of 4-byte shared group memory.
Let's start by filling the shared memory with data from the input buffer. We have 64 threads, so we have to do almost the same thing as before.
To be absolutely sure that all data is loaded for further processing, after that we put a barrier.
// Первый этап - заполнение всех общих данных данными из предыдущего этапа.
// Так как в каждой группе потоков по 64 потока, каждый может заполнить 4 элемента в одном потоке
// с помощью простого смещения.
[unroll] for (uint idx=0; idx < 4; idx++)
{
const uint offset = threadID + idx*64;
shared_data[ offset ] = g_buffer[offset];
}
// Здесь мы устанавливаем барьер, то есть блокируем выполнение всех потоков группы, пока не будет завершён
// весь общий доступ групп и все потоки в группе не достигнут этого вызова.
GroupMemoryBarrierWithGroupSync();All calculations are performed only in one thread, all others are used simply to load values from the buffer into the common memory.
The “computational” flow has index 0. Why? Theoretically, we can use any stream from the interval [0-63], but thanks to a comparison with 0, we can avoid additional integer-integer comparison ( ieq instructions).
The algorithm is based on specifying the interval of pixels that will be taken into account in the operation.
In line 11, we multiply the width * height to get the total number of pixels and multiply them by two numbers from the interval [0.0f-1.0f], denoting the beginning and end of the interval. Further restrictions are used to ensure that
0 <= Start <= End <= totalPixels - 1 :// Выполняем вычисления только для потока с индексом 0.
[branch] if (threadID == 0)
{
// Общее количество пикселей в буфере с уменьшенным масштабом
uint totalPixels = cb0_v0.x * cb0_v0.y;
// Интервал пикселей (или, если конкретнее, интервал яркости на экране),
// который мы хотим задействовать в вычислении средней яркости.
int pixelsToConsiderStart = totalPixels * cb0_v0.z;
int pixelsToConsiderEnd = totalPixels * cb0_v0.w;
int pixelsMinusOne = totalPixels - 1;
pixelsToConsiderStart = clamp( pixelsToConsiderStart, 0, pixelsMinusOne );
pixelsToConsiderEnd = clamp( pixelsToConsiderEnd, pixelsToConsiderStart, pixelsMinusOne );As you can see, there are two cycles below. The problem with them (or with their assembly code) is that there are strange conditional jumps at the ends of the cycles. It was very difficult for me to recreate them. Also take a look at line 21. Why is there a -1? I will explain this below.
The task of the first cycle is to drop pixelsToConsiderStart and give us the buffer cell index, in which pixel pixelsToConsiderStart +1 is present (as well as the number of all pixels in the previous cells).
Suppose that pixelsToConsiderStart is approximately equal to 30000, and in the buffer there are 37000 pixels in the “zero” cell (this happens in a game at night). Therefore, we want to start analyzing the brightness at about pixel 30001, which is present in the “zero” cell. In this case, we immediately exit the loop, getting the initial index '0' and zero dropped pixels.
Look at the HLSL code:
// Количество уже обработанных пикселей
int numProcessedPixels = 0;
// Ячейка яркости [0-255]
int lumaValue = 0;
// Надо ли продолжать выполнение цикла
bool bExitLoop = false;
// Задача первого цикла - отбросить "pixelsToConsiderStart" пикселей.
// Мы сохраняем количество отброшенных пикселей из предыдущих ячеек и lumaValue, чтобы использовать их в следующем цикле.
[loop]
while (!bExitLoop)
{
// Получаем количество пикселей с заданным значением яркости.
uint numPixels = shared_data[lumaValue];
// Проверяем, сколько пикселей должно быть с lumaValue
int tempSum = numProcessedPixels + numPixels;
// Если больше, чем pixelsToConsiderStart, то выходим из цикла.
// Следовательно, мы начнём вычисление яркости из lumaValue.
// Проще говоря, pixelsToConsiderStart - это количество "затемнённых" пикселей, которые нужно отбросить, прежде чем начинать вычисления.
[flatten]
if (tempSum > pixelsToConsiderStart)
{
bExitLoop = true;
}
else
{
numProcessedPixels = tempSum;
lumaValue++;
}
}The mysterious number "-1" from line 21 of the assembler code is associated with a boolean condition for executing a loop (I discovered this almost by accident).
Having obtained the number of pixels from the lumaValue cells and the lumaValue itself, we can proceed to the second cycle.
The task of the second cycle is the calculation of the effect of pixels and average brightness.
We start with lumaValue , calculated in the first loop.
float finalAvgLuminance = 0.0f;
// Количество отброшенных в первом цикле пикселей
uint numProcessedPixelStart = numProcessedPixels;
// Задача этого цикла - вычисление влияния пикселей и средней яркости.
// Мы начинаем с точки, вычисленной в предыдущем цикле, сохраняя количество отброшенных пикселей и начальную позицию lumaValue.
// Декодируем значение яркости из интервала [0-255], умножаем его на количество пикселей, имеющих это значение яркости, и суммируем их, пока не дойдём
// до обработки пикселей pixelsToConsiderEnd.
// После этого мы делим общее влияние на количество проанализированных пикселей.
bExitLoop = false;
[loop]
while (!bExitLoop)
{
// Получаем количество пикселей с заданным значением яркости.
uint numPixels = shared_data[lumaValue];
// Прибавляем ко всем обработанным пикселям
numProcessedPixels += numPixels;
// Текущее обрабатываемое значение яркости, распределённое в интервале [0-255] (uint)
uint encodedLumaUint = lumaValue;
// Количество пикселей с текущим обрабатываемым значением яркости
float numberOfPixelsWithCurrentLuma = numPixels;
// Текущее обрабатываемое значение яркости, закодированное в интервале [0-255] (float)
float encodedLumaFloat = encodedLumaUint;At this stage, we obtained the brightness value encoded in the interval [0.0f-255.f].
The decoding process is quite simple - you need to reverse the calculations of the encoding stage.
Briefly repeat the coding process:
float luma = dot( hdrPixelColor, float3(0.2126, 0.7152, 0.0722) );
...
float outLuma;
// так как log(0) равен undef, а log(1) = 0
outLuma = luma + 1.0;
// распределяем логарифмически
outLuma = log( outLuma );
// масштабируем на 128, что означает log(1) * 128 = 0, log(2,71828) * 128 = 128, log(7,38905) * 128 = 256
outLuma = outLuma * 128
// преобразуем в uint
uint outLumaUint = min( (uint) outLuma, 255);To decode the brightness, we reverse the encoding process, like this:
// начинаем с прибавления 0.5f (мы не хотим, чтобы получился нулевой результат)
float fDecodedLuma = encodedLumaFloat + 0.5;
// и декоридуем яркость:
// Делим на 128
fDecodedLuma /= 128.0;
// exp(x), что отменяет log(x)
fDecodedLuma = exp(fDecodedLuma);
// Вычитаем 1.0
fDecodedLuma -= 1.0;Then we calculate the distribution, multiplying the number of pixels with a given brightness by the decoded brightness, and adding them together until we reach the processing pixelsToConsiderEnd pixels.
After that, we divide the total effect by the number of pixels analyzed.
Here is the rest of the loop (and the shader): The full shader is posted here . It is fully compatible with my HLSLexplorer program , without which I could not effectively recreate the calculation of the average brightness in The Witcher 3 (and all the other effects too!). In conclusion, a few thoughts. From the point of view of calculating the average brightness, this shader was difficult to recreate. The main reasons are: 1) Strange "deferred" checks on the execution of the cycle, it took much longer than I expected earlier. 2) Problems with debugging this computational shader in RenderDoc (v. 1.2).
// Вычисляем влияние этой яркости
float fCurrentLumaContribution = numberOfPixelsWithCurrentLuma * fDecodedLuma;
// (Временное) влияние от всех предыдущих проходов и текущего.
float tempTotalContribution = fCurrentLumaContribution + finalAvgLuminance;
[flatten]
if (numProcessedPixels > pixelsToConsiderEnd )
{
// чтобы выйти из цикла
bExitLoop = true;
// Мы уже обработали все нужные пиксели, поэтому выполняем здесь окончательное деление.
// Количество всех обработанных пикселей для выбранного пользователем начала
int diff = numProcessedPixels - numProcessedPixelStart;
// Вычисляем окончательную среднюю яркость
finalAvgLuminance = tempTotalContribution / float(diff);
}
else
{
// Передаём текущее влияние дальше и увеличиваем lumaValue
finalAvgLuminance = tempTotalContribution;
lumaValue++;
}
}
// Сохраняем среднюю яркость
g_avgLuminance[uint2(0,0)] = finalAvgLuminance;The “ld_structured_indexable” operations are not fully supported, although the reading result from the index 0 gives the correct value, all the others return zeroes, because of which the cycles continue indefinitely.
Although I was not able to achieve the same assembler code as in the original (see the screenshot below for differences), with the help of RenderDoc I was able to inject this shader into the pipeline - and the results were the same!
The result of the battle. On the left - my shader, on the right - the original assembly code.
Part 8. The moon and its phases
In the eighth part of the article, I explore the Moon's shader from The Witcher 3 (and more specifically from the Blood and Wine extension).
The moon is an important element of the night sky, and it can be quite difficult to make it believable, but for me walking at night in TW3 became a real pleasure.
Just look at this scene!
Before we take on the pixel shader, I’ll say a few words about the nuances of rendering. Geometrically, the Moon is just a sphere (see below), which has texture coordinates, normal vectors, and tangent vectors. The vertex shader calculates the position in world space, as well as the normalized normal vectors, tangents and tangents to two points (using the vector product) multiplied by the world matrix.
To ensure that the moon completely lies on a distant plane, the MinDepth and MaxDepth fields of the D3D11_VIEWPORT structure are set to 0.0 (the same trick used for the dome of the sky). The moon is rendered immediately after the sky.
The sphere used to draw the moon.
Well, everything, I think you can proceed. Let's take a look at the pixel shader: The main reason that I chose the shader from “Blood and Wine” is simple - it’s shorter. First we calculate the offset for texture sampling. cb0 [0] .w is used as an X-axis offset. With this simple trick, we can simulate the rotation of the moon around its axis.
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[1], immediateIndexed
dcl_constantbuffer cb2[3], immediateIndexed
dcl_constantbuffer cb12[267], immediateIndexed
dcl_sampler s0, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_input_ps linear v1.w
dcl_input_ps linear v2.xyzw
dcl_input_ps linear v3.xy
dcl_input_ps linear v4.xy
dcl_output o0.xyzw
dcl_temps 3
0: mov r0.x, -cb0[0].w
1: mov r0.y, l(0)
2: add r0.xy, r0.xyxx, v2.xyxx
3: sample_indexable(texture2d)(float,float,float,float) r0.xyzw, r0.xyxx, t0.xyzw, s0
4: add r0.xyz, r0.xyzx, l(-0.500000, -0.500000, -0.500000, 0.000000)
5: log r0.w, r0.w
6: mul r0.w, r0.w, l(2.200000)
7: exp r0.w, r0.w
8: add r0.xyz, r0.xyzx, r0.xyzx
9: dp3 r1.x, r0.xyzx, r0.xyzx
10: rsq r1.x, r1.x
11: mul r0.xyz, r0.xyzx, r1.xxxx
12: mul r1.xy, r0.yyyy, v3.xyxx
13: mad r0.xy, v4.xyxx, r0.xxxx, r1.xyxx
14: mad r0.xy, v2.zwzz, r0.zzzz, r0.xyxx
15: mad r0.z, cb0[0].y, l(0.033864), cb0[0].w
16: mul r0.z, r0.z, l(6.283185)
17: sincos r1.x, r2.x, r0.z
18: mov r2.y, r1.x
19: dp2_sat r0.x, r0.xyxx, r2.xyxx
20: mul r0.xyz, r0.xxxx, cb12[266].xyzx
21: mul r0.xyz, r0.xyzx, r0.wwww
22: mul r0.xyz, r0.xyzx, cb2[2].xyzx
23: add_sat r0.w, -v1.w, l(1.000000)
24: mul r0.w, r0.w, cb2[2].w
25: mul o0.xyz, r0.wwww, r0.xyzx
26: mov o0.w, l(0)
27: retExamples of values from the buffer of constants
One texture (1024x512) is attached as input. The normal map is encoded in the RGB channels, and the color of the moon's surface is encoded in the alpha channel. Clever!
The alpha channel of the texture is the color of the surface of the moon.
Texture RGB channels are a normal map.
Having the correct texture coordinates, we will sample the RGBA channels. We need to unpack the normal map and perform a gamma correction of the surface color. Currently, the HLSL shader can be written like this, for example: The next step is to bind the normals, but only in the XY components. (In The Witcher 3, the Z axis is pointing up, and the entire Z-channel of the texture is 1.0). We can do it this way: Now it’s time for my favorite part of this shader. Take another look at lines 15-16: What is this mysterious 0.033864? At first it seems that there is no point in it, but if we calculate the inverse of it, we will get approximately 29.53, which is equal to the duration of the synodic month.
float4 MoonPS(in InputStruct IN) : SV_Target0
{
// Смещения Texcoords
float2 uvOffsets = float2(-cb0_v0.w, 0.0);
// Готовые texcoords
float2 uv = IN.param2.xy + uvOffsets;
// Сэмплирование текстуры
float4 sampledTexture = texture0.Sample( sampler0, uv);
// Цвет поверхности Луны - выполняем гамма-коррекцию
float moonColorTex = pow(sampledTexture.a, 2.2 );
// Распаковываем нормали из интервала [0,1] в интервал [-1,1].
// Примечание: sampledTexture.xyz * 2.0 - 1.0 работает аналогичным образом
float3 sampledNormal = normalize((sampledTexture.xyz - 0.5) * 2);// Векторы касательного пространства
float3 Tangent = IN.param4.xyz;
float3 Normal = float3(IN.param2.zw, IN.param3.w);
float3 Bitangent = IN.param3.xyz;
// Матрица TBN
float3x3 TBN = float3x3(Tangent, Bitangent, Normal);
// Вычисление вектора нормали XY
// Ужимаем матрицу TBN во float3x2: 3 строки, 2 столбца
float2 vNormal = mul(sampledNormal, (float3x2)TBN).xy;15: mad r0.z, cb0[0].y, l(0.033864), cb0[0].w
16: mul r0.z, r0.z, l(6.283185)in the day! This is what I call attention to detail!
We can reliably assume that cb0 [0] .y is the number of days that have passed during the gameplay. Here, an additional deviation is used, which is used as an offset along the X axis of the texture.
Having received this coefficient, we multiply it by 2 * Pi.
Then, using sincos, we compute another 2d vector.
The calculation of the scalar product between the normal vector and the "lunar" vector simulates one phase of the moon. Look at the screenshots with different phases of the moon:
// Лунная фаза.
// Мы вычисляем days/29.53 + bias.
float phase = cb0_v0.y * (1.0 / SYNODIC_MONTH_LENGTH) + cb0_v0.w;
// Умножаем на 2*PI. Таким образом, 29.53 будет равно полному периоду
// для функций sin/cos.
phase *= TWOPI;
// Вычисляем синус и косинус лунной фазы.
float outSin = 0.0;
float outCos = 0.0;
sincos(phase, outSin, outCos);
// Вычисляем лунную фазу
float lunarPhase = saturate( dot(vNormal, float2(outCos, outSin)) );The final stage is a series of multiplication operations to calculate the final color. Perhaps you do not understand why this shader sends the alpha value 0.0 to the output. This is because the moon is rendered with blending turned on:
// Выполняем серию операций умножения для вычисления окончательного цвета.
// cb12_v266.xyz используется, чтобы усилить свечение и цвет Луны.
// например (1.54, 2.82, 4.13)
float3 moonSurfaceGlowColor = cb12_v266.xyz;
float3 moonColor = lunarPhase * moonSurfaceGlowColor;
moonColor = moonColorTex * moonColor;
// cb_v2.xyz - это, вероятно, фильтр, например (1.0, 1.0, 1.0)
moonColor *= cb2_v2.xyz;
// Не совсем понимаю, что делает этот фрагмент, возможно. это какое-то значение непрозрачности горизонта.
// Как бы то ни было, он имеет не такое большое влияние на окончательный цвет,
// как параметры выше.
float paramHorizon = saturate(1.0 - IN.param1.w);
paramHorizon *= cb2_v2.w;
moonColor *= paramHorizon;
// Выводим окончательный цвет с нулевым значением альфы
return float4(moonColor, 0.0);This approach allows you to get the color of the background (sky), if this shader returns black.
If you are interested in a complete shader, you can take it here . It has large constant buffers and it should already be ready for injection into RenderDoc instead of the original shader (just rename “MoonPS” to “EditedShaderPS”).
One last thing: I wanted to share the results with you:
On the left, my shader, on the right, the original shader from the game.
The difference is minimal and does not affect the results.
As you can see, this shader was pretty easy to recreate.
Part 9. G-buffer
In this part, I’ll cover some of the details of the gbuffer in The Witcher 3.
We’ll assume that you know the basics of deferred shading.
A brief repetition: the idea of postponing is not to calculate all the finished lighting and shading at once, but to divide the calculations into two steps.
In the first (geometry pass) we fill the GBuffer with surface data (position, normals, specular color, etc ...), and in the second (illumination pass) we combine everything and calculate the illumination.
Deferred shading is a very popular approach because it allows you to calculate techniques such as tile deferred shading in a single full-screen pass , which greatly improves performance.
Simply put, GBuffer is a set of textures with geometry properties. It is very important to create the right structure for it. As an example from real life, you can explore Crysis 3 rendering technologies .
After this brief introduction, let's look at an example of a frame from The Witcher 3: Blood and Wine:
One of the many hotels in Tussent
The main GBuffer consists of three full-screen render target format DXGI_FORMAT_R8G8B8A8_UNORM and depth buffer + stencil format DXGI_FORMAT_D24_UNORM_S8_UINT.
Here are their screenshots:
Render Target 0 - RGB channels, surface color
Render Target 0 - alpha channel. Honestly, I have no idea what this information is.
Render Target 1 - RGB channels. Here we write the normal vectors in the interval [0-1].
Render Target 1 - alpha channel. It looks like reflectivity!
Render Target 2 - RGB channels. Looks like a specular color!
In this scene, the alpha channel is black (but later it is used).
Depth buffer Notice that the inverted depth is used here.
Stencil buffer used to mark a certain type of pixel (for example, skin, vegetation, etc.)
This is not the whole GBuffer. The lighting pass also uses lighting probes and other buffers, but I will not consider them in this article.
Before proceeding to the "main" part of the post, I will give general observations:
General observations
1) The only buffer to be cleared is the depth / stencil buffer.
If you analyze the above-mentioned textures in a good frame analyzer, then you will be a little surprised, because the “Clear” call is not used for them, with the exception of Depth / Stencil.
That is, in reality, RenderTarget1 looks like this (note the “blurry” pixels on the far plane):
This is a simple and smart optimization.
Important lesson: you need to waste resources on calls to ClearRenderTargetView , so use them only when necessary.
2) Inverted depth - it is cool
in many articles already written about the accuracy of the depth buffer with floating point. Witcher 3 uses reversed-z. This is a natural choice for such an open-world game and long-distance rendering.
It will be easy to switch to DirectX:
a) Clear the depth buffer with the entry “0”, not “1”.
In the traditional approach, the remote value “1” was used to clean the depth buffer. After the reversal of the depth, the new "long-range" value became 0, so you need to change everything.
b) Swap the near and far boundaries when calculating the projection matrix
c) Change the depth check from “less” to “more”
For OpenGL, a little more work needs to be done (see the articles mentioned above), but it's worth it.
3) Do not keep a position in the world
Yes, everything is so simple. In the aisle of the lighting position in the world recreate from the depths.
Pixel shader
In this part, I wanted to show exactly the pixel shader that supplies surface data to GBuffer.
So now we already know how to store color, normals and specular.
Of course, everything is not as simple as you might think.
The problem with the pixel shader is that it has many options. They differ in the number of textures transferred to them and the number of parameters used from the buffer of constants (probably from the buffer of constants describing the material).
For analysis, I decided to use this beautiful barrel:
Our heroic barrel!
Please welcome textures:
So we have albedo, normal map and specular color. Pretty standard case.
Before we begin, a few words about the geometry input data:
Geometry is transmitted with position, texcoords, normal buffers, and tangents.
The vertex shader displays at least texcoords, normalized tangent / normal / tangent two-point vectors, previously multiplied by the world matrix. For more complex materials (for example, with two diffuse maps or two normal maps), the vertex shader can output other data, but I wanted to show a simple example here.
Pixel shader in assembler code: The shader consists of several stages. I will describe each major part of this shader separately.
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb4[3], immediateIndexed
dcl_sampler s0, mode_default
dcl_sampler s13, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_resource_texture2d (float,float,float,float) t2
dcl_resource_texture2d (float,float,float,float) t13
dcl_input_ps linear v0.zw
dcl_input_ps linear v1.xyzw
dcl_input_ps linear v2.xyz
dcl_input_ps linear v3.xyz
dcl_input_ps_sgv v4.x, isfrontface
dcl_output o0.xyzw
dcl_output o1.xyzw
dcl_output o2.xyzw
dcl_temps 3
0: sample_indexable(texture2d)(float,float,float,float) r0.xyzw, v1.xyxx, t1.xyzw, s0
1: sample_indexable(texture2d)(float,float,float,float) r1.xyz, v1.xyxx, t0.xyzw, s0
2: add r1.w, r1.y, r1.x
3: add r1.w, r1.z, r1.w
4: mul r2.x, r1.w, l(0.333300)
5: add r2.y, l(-1.000000), cb4[1].x
6: mul r2.y, r2.y, l(0.500000)
7: mov_sat r2.z, r2.y
8: mad r1.w, r1.w, l(-0.666600), l(1.000000)
9: mad r1.w, r2.z, r1.w, r2.x
10: mul r2.xzw, r1.xxyz, cb4[0].xxyz
11: mul_sat r2.xzw, r2.xxzw, l(1.500000, 0.000000, 1.500000, 1.500000)
12: mul_sat r1.w, abs(r2.y), r1.w
13: add r2.xyz, -r1.xyzx, r2.xzwx
14: mad r1.xyz, r1.wwww, r2.xyzx, r1.xyzx
15: max r1.w, r1.z, r1.y
16: max r1.w, r1.w, r1.x
17: lt r1.w, l(0.220000), r1.w
18: movc r1.w, r1.w, l(-0.300000), l(-0.150000)
19: mad r1.w, v0.z, r1.w, l(1.000000)
20: mul o0.xyz, r1.wwww, r1.xyzx
21: add r0.xyz, r0.xyzx, l(-0.500000, -0.500000, -0.500000, 0.000000)
22: add r0.xyz, r0.xyzx, r0.xyzx
23: mov r1.x, v0.w
24: mov r1.yz, v1.zzwz
25: mul r1.xyz, r0.yyyy, r1.xyzx
26: mad r1.xyz, v3.xyzx, r0.xxxx, r1.xyzx
27: mad r0.xyz, v2.xyzx, r0.zzzz, r1.xyzx
28: uge r1.x, l(0), v4.x
29: if_nz r1.x
30: dp3 r1.x, v2.xyzx, r0.xyzx
31: mul r1.xyz, r1.xxxx, v2.xyzx
32: mad r0.xyz, -r1.xyzx, l(2.000000, 2.000000, 2.000000, 0.000000), r0.xyzx
33: endif
34: sample_indexable(texture2d)(float,float,float,float) r1.xyz, v1.xyxx, t2.xyzw, s0
35: max r1.w, r1.z, r1.y
36: max r1.w, r1.w, r1.x
37: lt r1.w, l(0.200000), r1.w
38: movc r2.xyz, r1.wwww, r1.xyzx, l(0.120000, 0.120000, 0.120000, 0.000000)
39: add r2.xyz, -r1.xyzx, r2.xyzx
40: mad o2.xyz, v0.zzzz, r2.xyzx, r1.xyzx
41: lt r1.x, r0.w, l(0.330000)
42: mul r1.y, r0.w, l(0.950000)
43: movc r1.x, r1.x, r1.y, l(0.330000)
44: add r1.x, -r0.w, r1.x
45: mad o1.w, v0.z, r1.x, r0.w
46: dp3 r0.w, r0.xyzx, r0.xyzx
47: rsq r0.w, r0.w
48: mul r0.xyz, r0.wwww, r0.xyzx
49: max r0.w, abs(r0.y), abs(r0.x)
50: max r0.w, r0.w, abs(r0.z)
51: lt r1.xy, abs(r0.zyzz), r0.wwww
52: movc r1.yz, r1.yyyy, abs(r0.zzyz), abs(r0.zzxz)
53: movc r1.xy, r1.xxxx, r1.yzyy, abs(r0.yxyy)
54: lt r1.z, r1.y, r1.x
55: movc r1.xy, r1.zzzz, r1.xyxx, r1.yxyy
56: div r1.z, r1.y, r1.x
57: div r0.xyz, r0.xyzx, r0.wwww
58: sample_l(texture2d)(float,float,float,float) r0.w, r1.xzxx, t13.yzwx, s13, l(0)
59: mul r0.xyz, r0.wwww, r0.xyzx
60: mad o1.xyz, r0.xyzx, l(0.500000, 0.500000, 0.500000, 0.000000), l(0.500000, 0.500000, 0.500000, 0.000000)
61: mov o0.w, cb4[2].x
62: mov o2.w, l(0)
63: retBut first, as usual - a screenshot with the values from the buffer of constants:
Albedo
We start with complex things. This is not just
After sampling the RGB texture of the color (line 1), the next 14 lines are what I call the “saturation reduction buffer”. Let me show the HLSL code: For most objects, this code does nothing but return the original color from the texture. This is achieved by the corresponding values of "material cbuffer". cb4_v1.x is set to 1.0, which returns a mask of 0.0, and returns the input color from the lerp instruction . However, there are some exceptions. The highest desaturationFactor I found is 4.0 (it is never less than 1.0), and desaturatedColor
float3 albedoColorFilter( in float3 color, in float desaturationFactor, in float3 desaturationValue )
{
float sumColorComponents = color.r + color.g + color.b;
float averageColorComponentValue = 0.3333 * sumColorComponents;
float oneMinusAverageColorComponentValue = 1.0 - averageColorComponentValue;
float factor = 0.5 * (desaturationFactor - 1.0);
float avgColorComponent = lerp(averageColorComponentValue, oneMinusAverageColorComponentValue, saturate(factor));
float3 desaturatedColor = saturate(color * desaturationValue * 1.5);
float mask = saturate( avgColorComponent * abs(factor) );
float3 finalColor = lerp( color, desaturatedColor, mask );
return finalColor;
}depends on the material. It can be something like (0.2, 0.3, 0.4); there are no strict rules. Of course, I could not refrain from implementing this in my own DX11 framework, and here are the results, where all values of desaturatedColor are equal to float3 (0.25, 0.3, 0.45)
desaturationFactor = 1.0 (no effect)
desaturationFactor = 2.0
desaturationFactor = 3.0
desaturationFactor = 4.0
I’m sure it’s just the application of material parameters, but not the end of the part with albedo.
Lines 15-20 add the final touches: v0.z is the output from the vertex shader, and they are zero. Do not forget about this, because v0.z will be used a couple of times later. It seems that this is some kind of coefficient, and the whole code looks like a slight darkening of albedo, but since v0.z is 0, the color remains the same. HLSL: As for RT0.a, then, as we see, it is taken from the buffer of material constants, but since the shader does not have debugging information, it is difficult to say what it is. Possible translucency? We are done with the first render target!
15: max r1.w, r1.z, r1.y
16: max r1.w, r1.w, r1.x
17: lt r1.w, l(0.220000), r1.w
18: movc r1.w, r1.w, l(-0.300000), l(-0.150000)
19: mad r1.w, v0.z, r1.w, l(1.000000)
20: mul o0.xyz, r1.wwww, r1.xyzx/* ALBEDO */
// опциональный фильтр снижения насыщенности (?)
float3 albedoColor = albedoColorFilter( colorTex, cb4_v1.x, cb4_v0.rgb );
float albedoMaxComponent = getMaxComponent( albedoColor );
// Понятия не имею, что это
// В большинстве случаев вершинный шейдер выводит "paramZ" со значением 0
float paramZ = Input.out0.z; // помните, чаще всего это 0
// Заметьте, что 0.70 и 0.85 отсутствуют в ассемблерном коде вывода
// Так как я хотел использовать здесь lerp, мне пришлось настроить их вручную.
float param = (albedoMaxComponent > 0.22) ? 0.70 : 0.85;
float mulParam = lerp(1, param, paramZ);
// Вывод
pout.RT0.rgb = albedoColor * mulParam;
pout.RT0.a = cb4_v2.x;Normals
Let's start by unpacking the normal map, and then, as usual, we will bind the normals: So far, nothing surprising. Look at lines 28-33: We can roughly write them as follows: Not sure if it is the right way to write. If you know what this mathematical operation is, let me know. We see that the pixel shader uses SV_IsFrontFace.
/* НОРМАЛИ */
float3 sampledNormal = ((normalTex.xyz - 0.5) * 2);
// Данные для создания матрицы TBN
float3 Tangent = Input.TangentW.xyz;
float3 Normal = Input.NormalW.xyz;
float3 Bitangent;
Bitangent.x = Input.out0.w;
Bitangent.yz = Input.out1.zw;
// в реальном сценарии это насыщение удаляется; это хак, для того, чтобы умножение normal-tbn
// давало в ассемблерном коде инструкции 'mad' вместо кучи 'mov'
Bitangent = saturate(Bitangent);
float3x3 TBN = float3x3(Tangent, Bitangent, Normal);
float3 normal = mul( sampledNormal, TBN );28: uge r1.x, l(0), v4.x
29: if_nz r1.x
30: dp3 r1.x, v2.xyzx, r0.xyzx
31: mul r1.xyz, r1.xxxx, v2.xyzx
32: mad r0.xyz, -r1.xyzx, l(2.000000, 2.000000, 2.000000, 0.000000), r0.xyzx
33: endif[branch] if (bIsFrontFace <= 0)
{
float cosTheta = dot(Input.NormalW, normal);
float3 invNormal = cosTheta * Input.NormalW;
normal = normal - 2*invNormal;
}What it is?Documentation comes to help (I wanted to write “msdn”, but ...):
Determines whether the triangle is looking into the camera. For lines and points, IsFrontFace is true. Exceptions are the lines drawn from triangles (wireframe mode), which set IsFrontFace in a way similar to rasterizing a triangle in solid mode. Writing to it can be done by a geometry shader, and reading from it can be done by a pixel shader.
I wanted to check it out by myself. And in fact, the effect is noticeable only in wireframe mode. I suppose this code fragment is needed to correctly calculate the normals (and hence the lighting) in wireframe mode.
Here is a comparison: both colors of the frame of the finished scene with this enabled / disabled trick, as well as the texture normals of gbuffer [0-1] with the enabled / disabled trick:
Scene color without stunt
Color scene with a gimmick
Normals [0-1] without stunt
Normals [0-1] with a stunt.
Have you noticed that each render target in GBuffer has the format R8G8B8A8_UNORM? This means that there are 256 possible values per component. Is this enough to store normals?
Storing high-quality normals with enough bytes in Gbuffer is a well-known problem, but fortunately there are a lot of different materials to learn from .
Perhaps some of you already know which technique is used here. It must be said that in the whole passage of geometry there is one additional texture attached to slot 13 ...:
Ha! The Witcher 3 uses a technique called " Best Fit Normals ". Here I will not explain it in detail (see the presentation). It was invented by Crytek around 2009-2010, and since CryEngine is open source, BFN is also open source .
BFN gives the normal texture a “grainy” look.
After scaling the normals with BFN, we recode them from the interval [-1; 1] to [0, 1].
Specular
Let's start with line 34, and sample the specular texture: As you can see, here we have the “dimming” filter familiar to us from Albedo: Calculate the component with max. value, and then we calculate the “darkened” color and interpolate it with the original specular color, taking the parameter from the vertex shader ... which is 0, so at the output we get the color from the texture. HLSL:
34: sample_indexable(texture2d)(float,float,float,float) r1.xyz, v1.xyxx, t2.xyzw, s0
35: max r1.w, r1.z, r1.y
36: max r1.w, r1.w, r1.x
37: lt r1.w, l(0.200000), r1.w
38: movc r2.xyz, r1.wwww, r1.xyzx, l(0.120000, 0.120000, 0.120000, 0.000000)
39: add r2.xyz, -r1.xyzx, r2.xyzx
40: mad o2.xyz, v0.zzzz, r2.xyzx, r1.xyzx/* SPECULAR */
float3 specularTex = texture2.Sample( samplerAnisoWrap, Texcoords ).rgb;
// Тот же алгоритм, что и в Albedo. Вычисляем макс. компонент, сравниваем его с
// каким-то пороговым значением и при необходимости вычисляем значение "минимума".
// Так как в анализируемой сцене paramZ имеет значение 0, окончательным результатом будет
//значение из текстуры.
float specularMaxComponent = getMaxComponent( specularTex );
float3 specB = (specularMaxComponent > 0.2) ? specularTex : float3(0.12, 0.12, 0.12);
float3 finalSpec = lerp(specularTex, specB, paramZ);
pout.RT2.xyz = finalSpec;Reflectivity
I have no idea if this name is appropriate for this parameter, because I don’t know how it affects the lighting passage. The fact is that the alpha channel of the input normal map contains additional data:
Alpha channel texture "normal maps".
Assembler code: Say hello to our old friend - v0.z! Its meaning is similar to albedo and specular:
41: lt r1.x, r0.w, l(0.330000)
42: mul r1.y, r0.w, l(0.950000)
43: movc r1.x, r1.x, r1.y, l(0.330000)
44: add r1.x, -r0.w, r1.x
45: mad o1.w, v0.z, r1.x, r0.w/* REFLECTIVITY */
float reflectivity = normalTex.a;
float reflectivity2 = (reflectivity < 0.33) ? (reflectivity * 0.95) : 0.33;
float finalReflectivity = lerp(reflectivity, reflectivity2, paramZ);
pout.RT1.a = finalReflectivity;Fine!This is the end of the analysis of the first variant of the pixel shader.
Here is a comparison of my shader (left) with the original (right):
These differences do not affect the calculations, so my work here is finished.
Pixel Shader: Albedo + Normals Option
I decided to show another option, now only with albedo maps and normals, without a specular texture. The assembler code is slightly longer: The difference between this and the previous versions is as follows: a) lines 1, 19 : the interpolation parameter v0.z is multiplied by cb4 [0] .x from the constant buffer, but this product is used only for the interpolation albedo in line 19. For other outputs, the “normal” value of v0.z is used. b) lines 54-55 : o2.w is now set, provided that (cb4 [7] .x> 0.0) We already recognize this pattern “some comparison - AND” from the calculation of the brightness histogram. It can be written like this: c) lines 34-42 : a completely different specular calculation.
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb4[8], immediateIndexed
dcl_sampler s0, mode_default
dcl_sampler s13, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_resource_texture2d (float,float,float,float) t13
dcl_input_ps linear v0.zw
dcl_input_ps linear v1.xyzw
dcl_input_ps linear v2.xyz
dcl_input_ps linear v3.xyz
dcl_input_ps_sgv v4.x, isfrontface
dcl_output o0.xyzw
dcl_output o1.xyzw
dcl_output o2.xyzw
dcl_temps 4
0: mul r0.x, v0.z, cb4[0].x
1: sample_indexable(texture2d)(float,float,float,float) r1.xyzw, v1.xyxx, t1.xyzw, s0
2: sample_indexable(texture2d)(float,float,float,float) r0.yzw, v1.xyxx, t0.wxyz, s0
3: add r2.x, r0.z, r0.y
4: add r2.x, r0.w, r2.x
5: add r2.z, l(-1.000000), cb4[2].x
6: mul r2.yz, r2.xxzx, l(0.000000, 0.333300, 0.500000, 0.000000)
7: mov_sat r2.w, r2.z
8: mad r2.x, r2.x, l(-0.666600), l(1.000000)
9: mad r2.x, r2.w, r2.x, r2.y
10: mul r3.xyz, r0.yzwy, cb4[1].xyzx
11: mul_sat r3.xyz, r3.xyzx, l(1.500000, 1.500000, 1.500000, 0.000000)
12: mul_sat r2.x, abs(r2.z), r2.x
13: add r2.yzw, -r0.yyzw, r3.xxyz
14: mad r0.yzw, r2.xxxx, r2.yyzw, r0.yyzw
15: max r2.x, r0.w, r0.z
16: max r2.x, r0.y, r2.x
17: lt r2.x, l(0.220000), r2.x
18: movc r2.x, r2.x, l(-0.300000), l(-0.150000)
19: mad r0.x, r0.x, r2.x, l(1.000000)
20: mul o0.xyz, r0.xxxx, r0.yzwy
21: add r0.xyz, r1.xyzx, l(-0.500000, -0.500000, -0.500000, 0.000000)
22: add r0.xyz, r0.xyzx, r0.xyzx
23: mov r1.x, v0.w
24: mov r1.yz, v1.zzwz
25: mul r1.xyz, r0.yyyy, r1.xyzx
26: mad r0.xyw, v3.xyxz, r0.xxxx, r1.xyxz
27: mad r0.xyz, v2.xyzx, r0.zzzz, r0.xywx
28: uge r0.w, l(0), v4.x
29: if_nz r0.w
30: dp3 r0.w, v2.xyzx, r0.xyzx
31: mul r1.xyz, r0.wwww, v2.xyzx
32: mad r0.xyz, -r1.xyzx, l(2.000000, 2.000000, 2.000000, 0.000000), r0.xyzx
33: endif
34: add r0.w, -r1.w, l(1.000000)
35: log r1.xyz, cb4[3].xyzx
36: mul r1.xyz, r1.xyzx, l(2.200000, 2.200000, 2.200000, 0.000000)
37: exp r1.xyz, r1.xyzx
38: mad r0.w, r0.w, cb4[4].x, cb4[5].x
39: mul_sat r1.xyz, r0.wwww, r1.xyzx
40: log r1.xyz, r1.xyzx
41: mul r1.xyz, r1.xyzx, l(0.454545, 0.454545, 0.454545, 0.000000)
42: exp r1.xyz, r1.xyzx
43: max r0.w, r1.z, r1.y
44: max r0.w, r0.w, r1.x
45: lt r0.w, l(0.200000), r0.w
46: movc r2.xyz, r0.wwww, r1.xyzx, l(0.120000, 0.120000, 0.120000, 0.000000)
47: add r2.xyz, -r1.xyzx, r2.xyzx
48: mad o2.xyz, v0.zzzz, r2.xyzx, r1.xyzx
49: lt r0.w, r1.w, l(0.330000)
50: mul r1.x, r1.w, l(0.950000)
51: movc r0.w, r0.w, r1.x, l(0.330000)
52: add r0.w, -r1.w, r0.w
53: mad o1.w, v0.z, r0.w, r1.w
54: lt r0.w, l(0), cb4[7].x
55: and o2.w, r0.w, l(0.064706)
56: dp3 r0.w, r0.xyzx, r0.xyzx
57: rsq r0.w, r0.w
58: mul r0.xyz, r0.wwww, r0.xyzx
59: max r0.w, abs(r0.y), abs(r0.x)
60: max r0.w, r0.w, abs(r0.z)
61: lt r1.xy, abs(r0.zyzz), r0.wwww
62: movc r1.yz, r1.yyyy, abs(r0.zzyz), abs(r0.zzxz)
63: movc r1.xy, r1.xxxx, r1.yzyy, abs(r0.yxyy)
64: lt r1.z, r1.y, r1.x
65: movc r1.xy, r1.zzzz, r1.xyxx, r1.yxyy
66: div r1.z, r1.y, r1.x
67: div r0.xyz, r0.xyzx, r0.wwww
68: sample_l(texture2d)(float,float,float,float) r0.w, r1.xzxx, t13.yzwx, s13, l(0)
69: mul r0.xyz, r0.wwww, r0.xyzx
70: mad o1.xyz, r0.xyzx, l(0.500000, 0.500000, 0.500000, 0.000000), l(0.500000, 0.500000, 0.500000, 0.000000)
71: mov o0.w, cb4[6].x
72: retpout.RT2.w = (cb4_v7.x > 0.0) ? (16.5/255.0) : 0.0;There is no specular texture here. Let's take a look at the assembly code responsible for this part: Notice what we used here (1 is the reflected ability). Fortunately, in HLSL it is quite simple to write: I will add that in this variant the buffer of constants with these materials is slightly more. Here, these additional values are used to emulate a specular color. The rest of the shader is the same as in the previous version. 72 lines of assembly code is too much to display in WinMerge, so take my word for it: my code is almost the same as in the original. Or you can download my HLSLexplorer and see for yourself!
34: add r0.w, -r1.w, l(1.000000)
35: log r1.xyz, cb4[3].xyzx
36: mul r1.xyz, r1.xyzx, l(2.200000, 2.200000, 2.200000, 0.000000)
37: exp r1.xyz, r1.xyzx
38: mad r0.w, r0.w, cb4[4].x, cb4[5].x
39: mul_sat r1.xyz, r0.wwww, r1.xyzx
40: log r1.xyz, r1.xyzx
41: mul r1.xyz, r1.xyzx, l(0.454545, 0.454545, 0.454545, 0.000000)
42: exp r1.xyz, r1.xyzxfloat oneMinusReflectivity = 1.0 - normalTex.a;
float3 specularTex = pow(cb4_v3.rgb, 2.2);
oneMinusReflectivity = oneMinusReflectivity * cb4_v4.x + cb4_v5.x;
specularTex = saturate(specularTex * oneMinusReflectivity);
specularTex = pow(specularTex, 1.0/2.2);
// продолжение как в первом варианте...
float specularMaxComponent = getMaxComponent( specularTex );
...Summarize
... and if you have read this far, then you may want to go a bit more deeply.
What seems simple in real life is often not so, and data transfer to the gbuffer The Witcher 3 is no exception. I showed you only the simplest versions of pixel shaders responsible for it, and also cited general observations that relate to deferred shadowing in general.
For the most patient, there are two options for pixel shaders in pastebin:
Option 1 - with a specular texture
Option 2 - without a specular texture
Part 10. Curtains of rain in the distance
In this part, we will look at a wonderful atmospheric effect, which I like very much - the distant rain / light curtains near the horizon. In the game they are easiest to meet on the Skellige Islands.
Personally, I really like this atmospheric phenomenon and was curious how the graphics programmers CD Projekt Red implemented it. Let's figure it out!
Here are two screenshots before and after applying rain curtains:
Before the rain curtains
After the rain curtains
Geometry
First we will focus on geometry. The idea is to use a small cylinder:
A cylinder in a local space
From the point of view of its position in a local space, it is small enough - its position is in the interval (0.0 - 1.0).
The input scheme for this render call looks like this ...
The following is important to us here: Texcoords and Instance_Transform.
Texcoords are wrapped quite simply: U of the upper and lower bases are in the interval [0.02777 - 1.02734]. V on the bottom base is 1.0, and on the top base 0.0. As you can see, you can quite simply create this mesh, even procedurally.
After receiving this small cylinder in local space, we multiply it by the world matrix provided for each instance of the INSTANCE_TRANSFORM input element. Let's check the values of this matrix:
Looks pretty scary, right? But do not worry, we will analyze this matrix and see what it hides! The results are very interesting: It is important to know the position of the camera in this particular frame: (-116.5338, 234.8695, 2.09) As you can see, we scaled the cylinder to make it quite large in global space (in TW3, the Z axis is up), moved it relative to the camera position and turned. Here is what the cylinder looks like after the vertex shader transforms:
XMMATRIX mat( -227.7472, 159.8043, 374.0736, -116.4951,
-194.7577, -173.3836, -494.4982, 238.6908,
-14.16466, -185.4743, 784.564, -1.45565,
0.0, 0.0, 0.0, 1.0 );
mat = XMMatrixTranspose( mat );
XMVECTOR vScale;
XMVECTOR vRotateQuat;
XMVECTOR vTranslation;
XMMatrixDecompose( &vScale, &vRotateQuat, &vTranslation, mat );
// Матрица поворота...
XMMATRIX matRotate = XMMatrixRotationQuaternion( vRotateQuat );vRotateQuat: (0.0924987569, -0.314900011, 0.883411944, -0.334462732)
vScale: (299.999969, 300.000000, 1000.00012)
vTranslation: (-116.495102, 238.690796, -1.45564997)Cylinder after conversion by vertex shader. See how it is located relative to the visibility pyramid.
Vertex shader
The input geometry and the vertex shader are strictly dependent on each other.
Let's take a closer look at the vertex shader assembler code: Along with the simple transfer Texcoords (line 0) and Instance_LOD_Params (line 8), two more elements are needed for output: SV_Position (obviously) and Height (component .z) of the world's position. Remember that local space is in the range [0-1]? So, right before applying the world matrix, the vertex shader uses scale and deflection to change the local position. Smart move! In this case, scale = float3 (4, 4, 2), and bias = float3 (-2, -2, -1). < The pattern that is visible between lines 9 and 28 is the multiplication of two row-major-matrices. Let's just look at the finished vertex shader on HLSL:
vs_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb1[7], immediateIndexed
dcl_constantbuffer cb2[6], immediateIndexed
dcl_input v0.xyz
dcl_input v1.xy
dcl_input v4.xyzw
dcl_input v5.xyzw
dcl_input v6.xyzw
dcl_input v7.xyzw
dcl_output o0.xyz
dcl_output o1.xyzw
dcl_output_siv o2.xyzw, position
dcl_temps 2
0: mov o0.xy, v1.xyxx
1: mul r0.xyzw, v5.xyzw, cb1[6].yyyy
2: mad r0.xyzw, v4.xyzw, cb1[6].xxxx, r0.xyzw
3: mad r0.xyzw, v6.xyzw, cb1[6].zzzz, r0.xyzw
4: mad r0.xyzw, cb1[6].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
5: mad r1.xyz, v0.xyzx, cb2[4].xyzx, cb2[5].xyzx
6: mov r1.w, l(1.000000)
7: dp4 o0.z, r1.xyzw, r0.xyzw
8: mov o1.xyzw, v7.xyzw
9: mul r0.xyzw, v5.xyzw, cb1[0].yyyy
10: mad r0.xyzw, v4.xyzw, cb1[0].xxxx, r0.xyzw
11: mad r0.xyzw, v6.xyzw, cb1[0].zzzz, r0.xyzw
12: mad r0.xyzw, cb1[0].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
13: dp4 o2.x, r1.xyzw, r0.xyzw
14: mul r0.xyzw, v5.xyzw, cb1[1].yyyy
15: mad r0.xyzw, v4.xyzw, cb1[1].xxxx, r0.xyzw
16: mad r0.xyzw, v6.xyzw, cb1[1].zzzz, r0.xyzw
17: mad r0.xyzw, cb1[1].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
18: dp4 o2.y, r1.xyzw, r0.xyzw
19: mul r0.xyzw, v5.xyzw, cb1[2].yyyy
20: mad r0.xyzw, v4.xyzw, cb1[2].xxxx, r0.xyzw
21: mad r0.xyzw, v6.xyzw, cb1[2].zzzz, r0.xyzw
22: mad r0.xyzw, cb1[2].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
23: dp4 o2.z, r1.xyzw, r0.xyzw
24: mul r0.xyzw, v5.xyzw, cb1[3].yyyy
25: mad r0.xyzw, v4.xyzw, cb1[3].xxxx, r0.xyzw
26: mad r0.xyzw, v6.xyzw, cb1[3].zzzz, r0.xyzw
27: mad r0.xyzw, cb1[3].wwww, l(0.000000, 0.000000, 0.000000, 1.000000), r0.xyzw
28: dp4 o2.w, r1.xyzw, r0.xyzw
29: retcbuffer cbPerFrame : register (b1)
{
row_major float4x4 g_viewProjMatrix;
row_major float4x4 g_rainShaftsViewProjMatrix;
}
cbuffer cbPerObject : register (b2)
{
float4x4 g_mtxWorld;
float4 g_modelScale;
float4 g_modelBias;
}
struct VS_INPUT
{
float3 PositionW : POSITION;
float2 Texcoord : TEXCOORD;
float3 NormalW : NORMAL;
float3 TangentW : TANGENT;
float4 InstanceTransform0 : INSTANCE_TRANSFORM0;
float4 InstanceTransform1 : INSTANCE_TRANSFORM1;
float4 InstanceTransform2 : INSTANCE_TRANSFORM2;
float4 InstanceLODParams : INSTANCE_LOD_PARAMS;
};
struct VS_OUTPUT
{
float3 TexcoordAndZ : Texcoord0;
float4 LODParams : LODParams;
float4 PositionH : SV_Position;
};
VS_OUTPUT RainShaftsVS( VS_INPUT Input )
{
VS_OUTPUT Output = (VS_OUTPUT)0;
// простая передача данных
Output.TexcoordAndZ.xy = Input.Texcoord;
Output.LODParams = Input.InstanceLODParams;
// мировое пространство
float3 meshScale = g_modelScale.xyz; // float3( 4, 4, 2 );
float3 meshBias = g_modelBias.xyz; // float3( -2, -2, -1 );
float3 PositionL = Input.PositionW * meshScale + meshBias;
// Построение вручную матрицы instanceWorld из float4s:
float4x4 matInstanceWorld = float4x4(Input.InstanceTransform0, Input.InstanceTransform1,
Input.InstanceTransform2 , float4(0, 0, 0, 1) );
// Высота в мировом пространстве (.z)
float4x4 matWorldInstanceLod = mul( g_rainShaftsViewProjMatrix, matInstanceWorld );
Output.TexcoordAndZ.z = mul( float4(PositionL, 1.0), transpose(matWorldInstanceLod) ).z;
// SV_Posiiton
float4x4 matModelViewProjection = mul(g_viewProjMatrix, matInstanceWorld );
Output.PositionH = mul( float4(PositionL, 1.0), transpose(matModelViewProjection) );
return Output;
}Comparison of my shader (left) and original (right):
Differences do not affect calculations. I performed an injection of my shader into the frame and everything was still fine!
Pixel shader
Finally! First, I’ll show you the input data:
Two textures are used here: the noise texture and the depth buffer:
Values from constant buffers:
And pixel shader assembly code:
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[8], immediateIndexed
dcl_constantbuffer cb2[3], immediateIndexed
dcl_constantbuffer cb12[23], immediateIndexed
dcl_constantbuffer cb4[8], immediateIndexed
dcl_sampler s0, mode_default
dcl_sampler s15, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t15
dcl_input_ps linear v0.xyz
dcl_input_ps linear v1.w
dcl_input_ps_siv v2.xy, position
dcl_output o0.xyzw
dcl_temps 1
0: mul r0.xy, cb0[0].xxxx, cb4[5].xyxx
1: mad r0.xy, v0.xyxx, cb4[4].xyxx, r0.xyxx
2: sample_indexable(texture2d)(float,float,float,float) r0.x, r0.xyxx, t0.xyzw, s0
3: add r0.y, -cb4[2].x, cb4[3].x
4: mad_sat r0.x, r0.x, r0.y, cb4[2].x
5: mul r0.x, r0.x, v0.y
6: mul r0.x, r0.x, v1.w
7: mul r0.x, r0.x, cb4[1].x
8: mul r0.yz, v2.xxyx, cb0[1].zzwz
9: sample_l(texture2d)(float,float,float,float) r0.y, r0.yzyy, t15.yxzw, s15, l(0)
10: mad r0.y, r0.y, cb12[22].x, cb12[22].y
11: mad r0.y, r0.y, cb12[21].x, cb12[21].y
12: max r0.y, r0.y, l(0.000100)
13: div r0.y, l(1.000000, 1.000000, 1.000000, 1.000000), r0.y
14: add r0.y, r0.y, -v0.z
15: mul_sat r0.y, r0.y, cb4[6].x
16: mul_sat r0.x, r0.y, r0.x
17: mad r0.y, cb0[7].y, r0.x, -r0.x
18: mad r0.x, cb4[7].x, r0.y, r0.x
19: mul r0.xyz, r0.xxxx, cb4[0].xyzx
20: log r0.xyz, r0.xyzx
21: mul r0.xyz, r0.xyzx, l(2.200000, 2.200000, 2.200000, 0.000000)
22: exp r0.xyz, r0.xyzx
23: mul r0.xyz, r0.xyzx, cb2[2].xyzx
24: mul o0.xyz, r0.xyzx, cb2[2].wwww
25: mov o0.w, l(0)
26: retWow!Quite a large amount, but in fact everything is not so bad.
What is going on here? First, we calculate animated UV using the elapsed time from the cbuffer (cb0 [0] .x) and scale / offset. These texcoords are used for sampling from the noise texture (line 2).
Having obtained the noise value from the texture, we interpolate between the min / max values (usually 0 and 1).
Then we perform multiplications, for example, on the coordinate of the texture V (remember that the coordinate V goes from 1 to 0?) - line 5.
Thus, we calculated the “brightness mask” - it looks like this:
Note that distant objects (lighthouse, mountains ...) are gone. This happened because the cylinder passes the depth test - the cylinder is not in the far plane and is drawn over these objects:
Depth test
We want to simulate the fact that the rain curtain is on (but not necessarily on the far plane). To do this, we compute another mask, the “mask of distant objects.”
It is calculated by the following formula:
farObjectsMask = saturate( (FrustumDepth - CylinderWorldSpaceHeight) * 0.001 );(0.001 is taken from the buffer), which gives us the necessary mask:
(In the part about the Sharpen effect, I have already superficially explained how the depth of the pyramid of visibility is retrieved from the depth buffer.)
Personally, it seems to me that this effect could be implemented less costly without calculating the height in global space by multiplying the depth of the pyramid of visibility by a smaller number, 0.0004.
By multiplying both masks, the final is obtained:
After receiving this final mask (line 16), we perform another interpolation, doing almost nothing (at least in the tested case), and then multiply the final mask by the curtain color (line 19), perform gamma correction (line 20 -22) and final multiplications (23-24).
At the end, we return a color with zero alpha value. This is done because mixing is enabled on this aisle:
FinalColor = SourceColor * 1.0 + (1.0 - SourceAlpha) * DestColorIf you are not quite
sure how mixing works, here’s a brief explanation: SourceColor is the output RGB data from the pixel shader, and DestColor is the current RGB color of the pixel in the render target . Since SourceAlpha always equal to 0.0, the above equation reduces to:
FinalColor = SourceColor + DestColor.Simply put, here we do additive blending. If the pixel shader returns (0, 0, 0), then the color will remain the same.
Here is the ready HLSL code - I think that after the explanation it will be much easier to understand it: I can happily say that my pixel shader creates the same assembler code as in the original. I hope you enjoyed the article. Thanks for reading!
struct VS_OUTPUT
{
float3 TexcoordAndWorldspaceHeight : Texcoord0;
float4 LODParams : LODParams; // float4(1,1,1,1)
float4 PositionH : SV_Position;
};
float getFrustumDepth( in float depth )
{
// from [1-0] to [0-1]
float d = depth * cb12_v22.x + cb12_v22.y;
// special coefficents
d = d * cb12_v21.x + cb12_v21.y;
// return frustum depth
return 1.0 / max(d, 1e-4);
}
float4 EditedShaderPS( in VS_OUTPUT Input ) : SV_Target0
{
// * Input from Vertex Shader
float2 InputUV = Input.TexcoordAndWorldspaceHeight.xy;
float WorldHeight = Input.TexcoordAndWorldspaceHeight.z;
float LODParam = Input.LODParams.w;
// * Inputs
float elapsedTime = cb0_v0.x;
float2 uvAnimation = cb4_v5.xy;
float2 uvScale = cb4_v4.xy;
float minValue = cb4_v2.x; // 0.0
float maxValue = cb4_v3.x; // 1.0
float3 shaftsColor = cb4_v0.rgb; // RGB( 147, 162, 173 )
float3 finalColorFilter = cb2_v2.rgb; // float3( 1.175, 1.296, 1.342 );
float finalEffectIntensity = cb2_v2.w;
float2 invViewportSize = cb0_v1.zw;
float depthScale = cb4_v6.x; // 0.001
// sample noise
float2 uvOffsets = elapsedTime * uvAnimation;
float2 uv = InputUV * uvScale + uvOffsets;
float disturb = texture0.Sample( sampler0, uv ).x;
// * Intensity mask
float intensity = saturate( lerp(minValue, maxValue, disturb) );
intensity *= InputUV.y; // transition from (0, 1)
intensity *= LODParam; // usually 1.0
intensity *= cb4_v1.x; // 1.0
// Sample depth
float2 ScreenUV = Input.PositionH.xy * invViewportSize;
float hardwareDepth = texture15.SampleLevel( sampler15, ScreenUV, 0 ).x;
float frustumDepth = getFrustumDepth( hardwareDepth );
// * Calculate mask covering distant objects behind cylinder.
// Seems that the input really is world-space height (.z component, see vertex shader)
float depth = frustumDepth - WorldHeight;
float distantObjectsMask = saturate( depth * depthScale );
// * calculate final mask
float finalEffectMask = saturate( intensity * distantObjectsMask );
// cb0_v7.y and cb4_v7.x are set to 1.0 so I didn't bother with naming them :)
float paramX = finalEffectMask;
float paramY = cb0_v7.y * finalEffectMask;
float effectAmount = lerp(paramX, paramY, cb4_v7.x);
// color of shafts comes from contant buffer
float3 effectColor = effectAmount * shaftsColor;
// gamma correction
effectColor = pow(effectColor, 2.2);
// final multiplications
effectColor *= finalColorFilter;
effectColor *= finalEffectIntensity;
// return with zero alpha 'cause the blending used here is:
// SourceColor * 1.0 + (1.0 - SrcAlpha) * DestColor
return float4( effectColor, 0.0 );
}Source: https://habr.com/ru/post/437100/