DMA: Myths and Reality
Introduction
In the last article ( “Part 2: Using Cypress’s UDB PSoC controllers to reduce interruptions in a 3D printer” ), I noted one very interesting fact: if an automaton in UDB removed data from a FIFO too quickly, he managed to notice that There is no data in the FIFO, after which it went into a false Idle state. Of course, I was interested in this fact. I showed the revealed results to a group of friends. One person answered that it was all quite obvious, and even gave the reasons. The rest were no less surprised than I was at the beginning of the research. So some experts will not find anything new here, but it would be nice to convey this information to the general public so that all programmers for microcontrollers have it in mind.
Not that it was a breakdown of some covers. It turned out that all this is well documented, but the trouble is that it is not in the main documents, but in additional documents. And personally, I was in a happy ignorance, believing that DMA is a very smart subsystem that allows you to dramatically improve the efficiency of programs, since there goes a systematic transfer of data without distracting the register increments and cycle organization to the same commands. As for efficiency, that's all right, but at the expense of a few other things.
But first things first.
Cypress PSoC Experiments
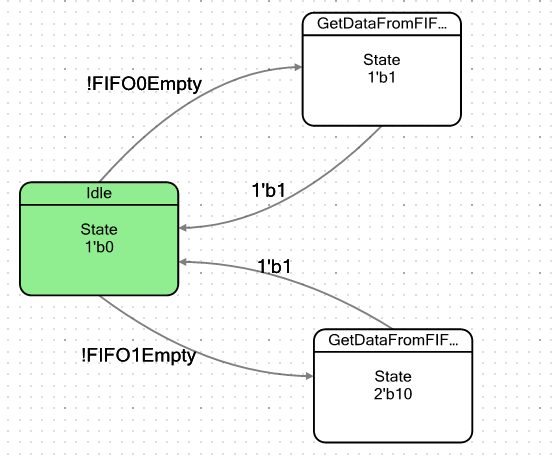
Let's make the simplest automaton. It will conditionally have two states: a state of rest and a state in which it will fall when there is at least one byte of data in the FIFO. Upon entering such a state, he will simply remove this data, after which he will again fall into a state of rest. The word "conditionally" I brought not by chance. We have two FIFOs, so I will make two such states, one for each FIFO, to make sure that they are completely identical in behavior. The transition graph of the machine turned out to be this:
Flags to exit from the Idle state are defined as:
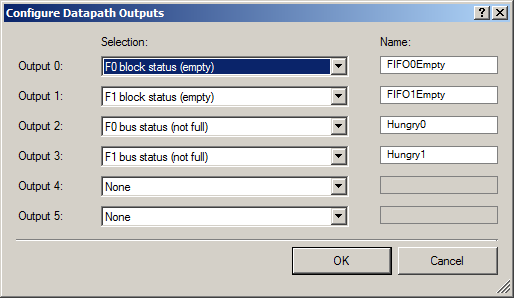
Do not forget on the inputs of Datapath to submit the status number bits:

Outward, we display two groups of signals: a couple of signals that there is free space in the FIFO (so that DMA can start uploading data to them), and a couple of signals that the FIFO is empty (to display this fact on an oscilloscope).

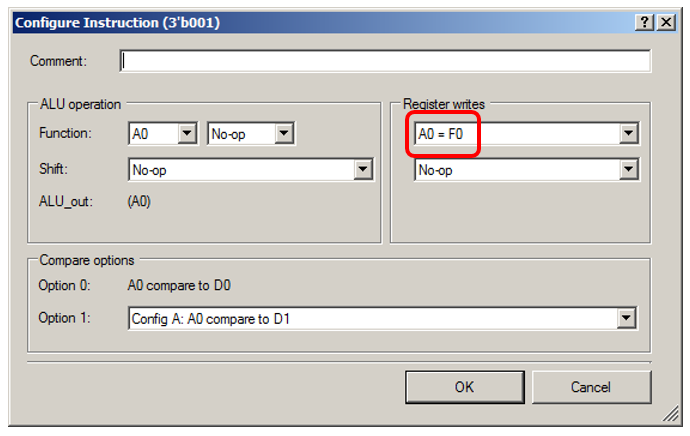
The ALU will simply fictitiously collect data from the FIFO:

Let me show you the details for the state “0001”:
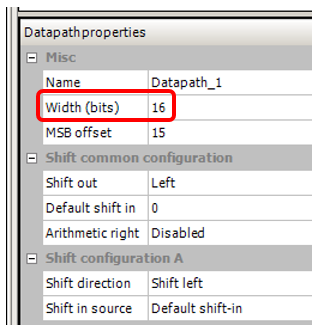
I also set the bus width, which was in the project on which I noticed this effect, 16 bits:
We turn to the scheme of the project itself. Outward, I give out not only signals that the FIFO is empty, but also clock pulses. This will allow me to do without cursor measurements on the oscilloscope. I can just count the finger strokes.
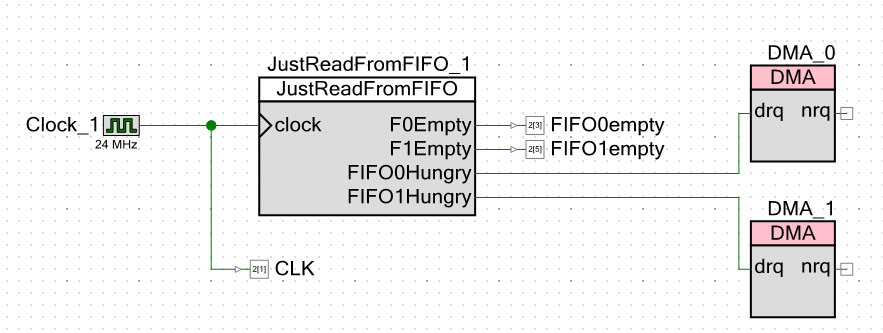
As you can see, I made a clock frequency of 24 megahertz. The processor core frequency is exactly the same. The lower the frequency, the less noise on the Chinese oscilloscope (officially it has a band of 250 MHz, but the Chinese megahertz), and all measurements will be carried out relative to the clock pulses. Whatever the frequency, the system will still work on them. I would put one megahertz, but the development environment forbade me to enter the value of the frequency of the processor core less than 24 MHz.
Now test things. To write to FIFO0, I made this function:
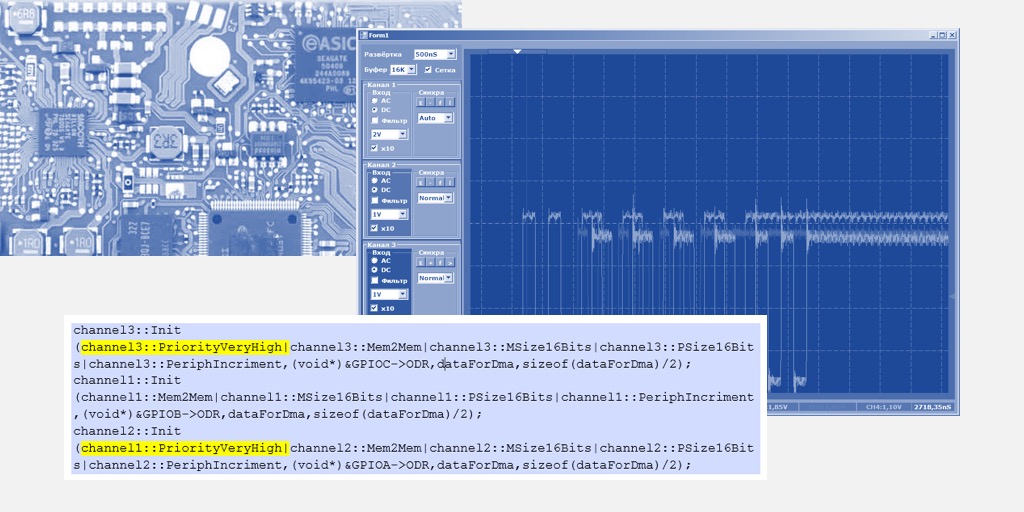
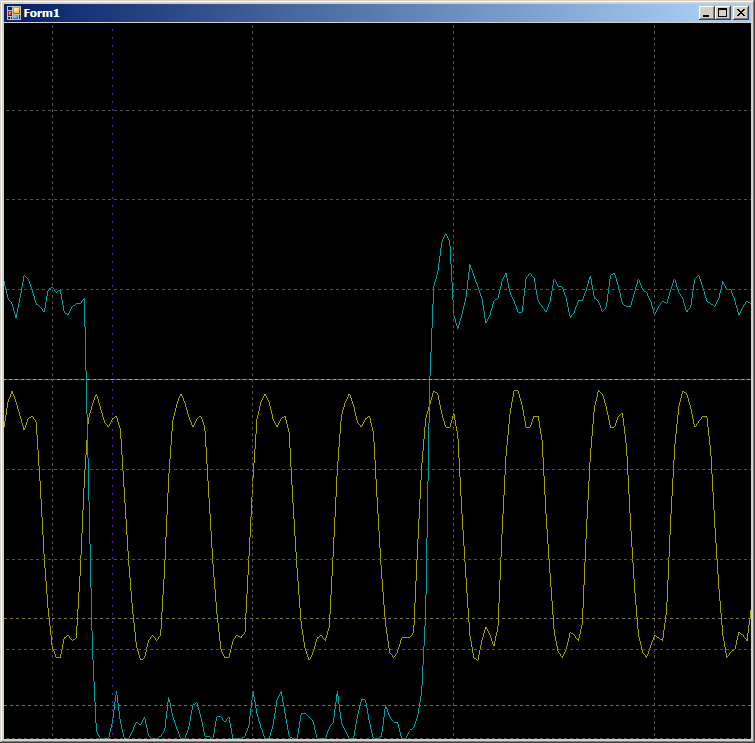
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // Инициализировали DMA прямо здесь, так как массив живёт здесь uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // Так как мы всё делаем для опытов, выделили дескриптор для задачи тоже здесь uint8 td = CyDmaTdAllocate(); // Задали параметры дескриптора и длину в байтах. Также сказали, что следующего дескриптора нет. CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // Теперь задали начальные адреса для дескриптора CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // Подключили этот дескриптор к каналу CyDmaChSetInitialTd(channel, td); // Запустили процесс с возвратом дескриптора к исходному виду CyDmaChEnable(channel, 1); } The word ROM in the function name is connected with the fact that the sent array is stored in the ROM area, and the Cortex M3 has a Harvard architecture. The speed of access to the RAM bus and the ROM bus can vary, I wanted to check this, so I have a similar function to send an array from RAM (the steps array in its body does not have the static const modifier). Well, there is the same pair of functions for sending to FIFO1, there the receiver register is different: not F0, but F1. Otherwise, all functions are identical. Since I didn’t notice much difference in the results, I’ll consider the results of calling the above function. Yellow beam - clock pulses, blue - output FIFO0empty .

First, let's check the plausibility, why the FIFO is filled for two cycles. Let's look at this site in more detail:
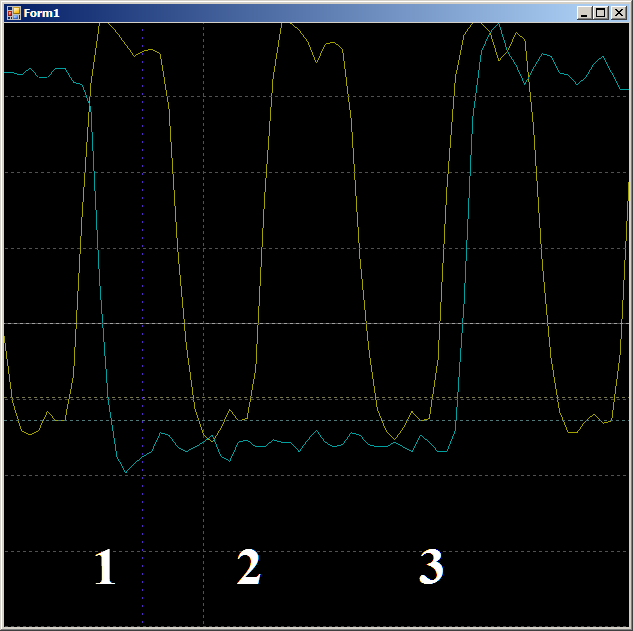
On front 1, the data falls into the FIFO, the flag FIFO0enmpty drops. On the front 2, the automaton enters the state GetDataFromFifo1 . On the front 3 in this state, the data from the FIFO is copied to the ALU register, the FIFO is empty, the FIFO0empty flag is set again. That is, the oscillogram behaves plausibly, you can count on it the cycles per cycle. We get 9 pieces.
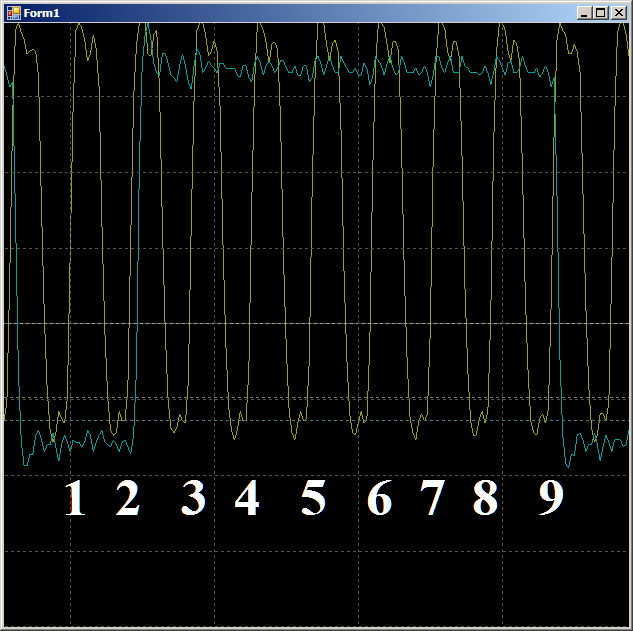
In total, in the surveyed area, it takes 9 clocks to copy one word of data from RAM to UDB using DMA.
And now the same thing, but by the processor core. First - the ideal code, poorly achievable in real life:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0; that will turn into assembly code:
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] bn 8e <main+0xa> .word 0x40006898 No breaks, no extra cycles. Two pairs of bars in a row ...
Let's make the code a little more real (with the overhead of organizing a cycle for retrieving data and incrementing pointers):
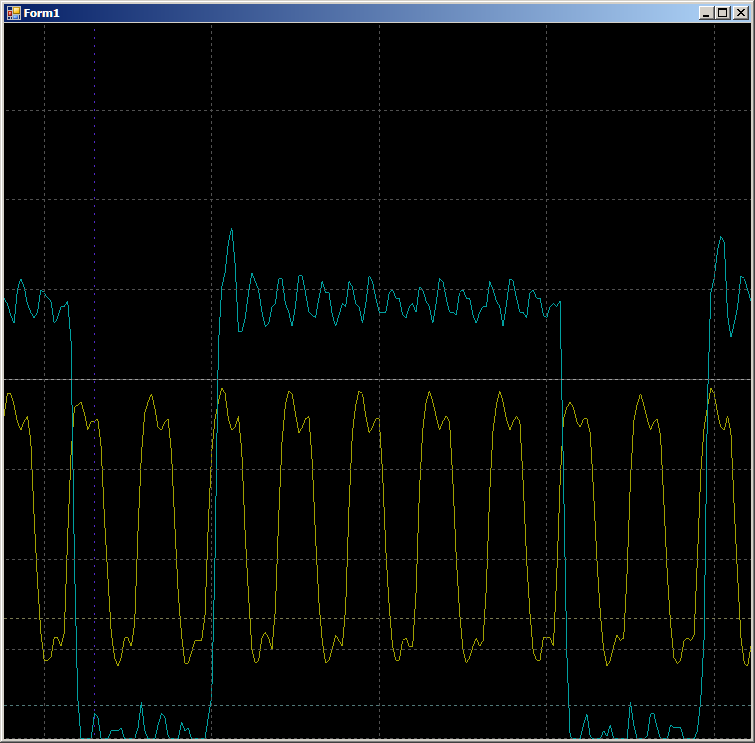
void SoftWriteTo0FromROM() { // В этом тесте просто шлём массив из двадцати шагов. // Хитрый алгоритм с упаковкой будем проверять чуть позже static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } } Received assembly code:
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa> On the oscillogram we see only 7 cycles per cycle against nine in the case of DMA:
Little about the myth
To be honest, for me it was originally a shock. I somehow used to assume that the DMA mechanism allows you to quickly and efficiently transfer data. 1/9 of the bus frequency is not that fast. But it turned out that no one is hiding it. The TRM document for PSoC 5LP even contains a number of theoretical calculations, and the document “AN84810 - PSoC 3 and PSoC 5LP Advanced DMA Topics” describes in detail the process of accessing DMA. Blame the latency. The cycle of exchange with the bus takes a certain number of cycles. Actually, it is these bars that play a crucial role in the occurrence of a delay. In general, no one hides anything, but you need to know.
If the famous GPIF, used in FX2LP (another architecture manufactured by Cypress), does not limit the speed, then the speed limit is due to latencies that occur when accessing the bus.
Check DMA on STM32
I was so impressed that I decided to conduct an experiment on STM32. The STM32F103 was used as a guinea pig, having the same Cortex M3 processor core. It does not have a UDB from which it would be possible to derive overhead signals, but it is quite possible to check DMA. What is GPIO? This is a set of registers in a shared address space. That's fine. We configure DMA in the “memory-memory” copying mode, specifying the actual memory (ROM or RAM) as the source, and the data register GPIO without the address increment as the receiver. We will send there one by one, then 0, then 1, and the result will be recorded with an oscilloscope. For a start, I chose port B, it was easier to connect to it on the breadboard.

I really liked counting bars with a finger, not cursors. Can I do the same on this controller? Completely! We take the reference clock frequency for the oscilloscope from the leg of the MCO, which in the STM32F10C8T6 is connected to the PA8 port. The choice of sources for this cheap crystal is not great (the same STM32F103, but more impressive, gives much more options), let us send a SYSCLK signal to this output. Since the frequency at the MCO cannot be higher than 50 MHz, we will reduce the total system clock frequency to 48 MHz. We will multiply the frequency of 8 MHz quartz not by 9, but by 6 (since 6 * 8 = 48):

Same text:
void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); } The MCO will be programmed by the means of the mcucpp library of Konstantin Chizhov (I will continue to refer to the hardware through this wonderful library):
// Настраиваем MCO Mcucpp::Clock::McoBitField::Set (0x4); // Подключаем ногу MCO к альтернативному порту Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Программируем скорость выходного каскада Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest); Well, now we set the output of the data array to GPIOB:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // Запускаем GPIOB и настраиваем биты на выход dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // Передёргиваем голубой луч dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // Всё, настроили и запустили DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } } The resulting waveform is very similar to the one that was on PSoC.

In the middle of a big blue hump. This is the DMA initialization process. The blue pulses on the left are obtained purely by software on PB1. Stretch them wider:

2 bars per pulse. System performance is as expected. But now let's take a closer look at the area marked on the main oscillogram with a dark blue background. At this point, the DMA block is already running.
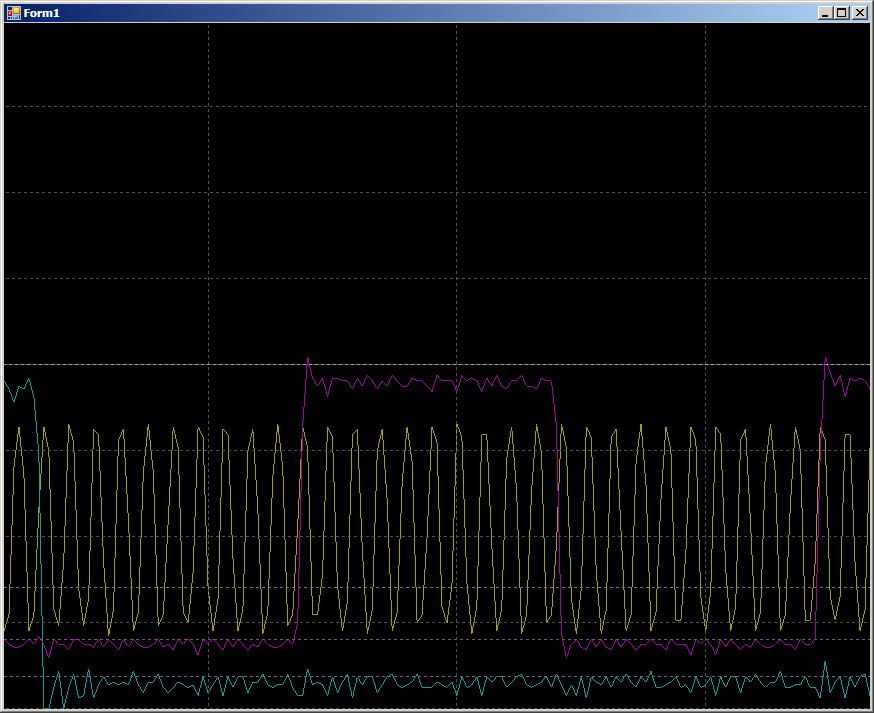
10 clocks per change GPIO line. In fact, the work goes on with RAM, and the program loops in a constant loop. There are no calls to RAM from the processor core. The bus is completely at the disposal of the DMA block, but 10 clocks. But in fact, the results are not very different from what they saw on PSoC, so we are just starting to look for Application Notes related to DMA on STM32. They turned out to be several. There is AN2548 on F0 / F1, there is AN3117 on L0 / L1 / L3, there is AN4031 on F2 / F4 / F77. Perhaps there are some more ...
But, nevertheless, from them we see that here the latency is to blame for everything. And with the F103 batch calls to the DMA bus are impossible. They are possible for F4, but no more than four words. Next comes the latency problem.
Let's try to perform the same actions, but with the help of program recording. Above, we have seen that direct recording to ports is instant. But there was more of a perfect record. Lines:
// Передёргиваем голубой луч dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); subject to such optimization settings (be sure to specify the optimization for the time):

turned into the following assembly code:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00] In real copying there will be an appeal to the source, to the receiver, changing the loop variable, branching ... In general, the mass of overhead costs (from which, it is believed, just relieves DMA). What will be the speed of change in the port? So, we write:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; } This C ++ code turns into such an assembler code:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8 And we get:
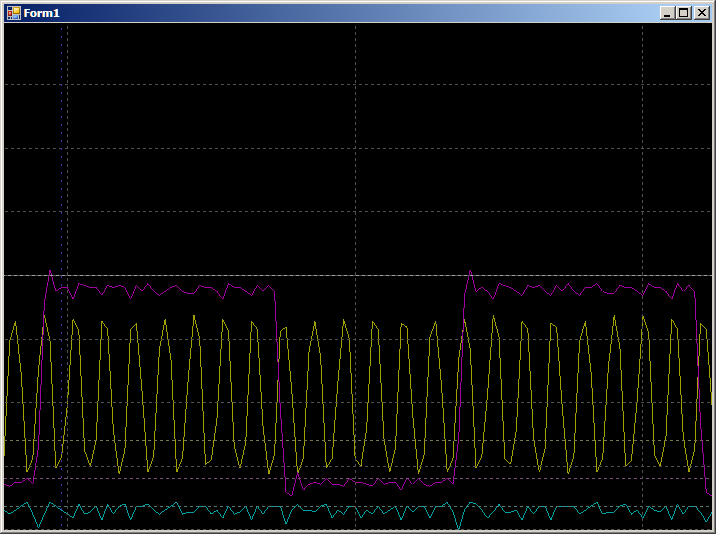
8 cycles in the upper half-cycle and 6 - in the lower (I checked, the result is repeated for all half-periods). The difference arose because the optimizer made 2 copies for each iteration. Therefore, 2 bars in one of the half periods are added to the branch operation.
Roughly speaking, during software copying, 14 cycles are spent on copying two words versus 20 cycles on the same thing, but by DMA. The result is completely documented, but very unexpected for those who have not yet read the extended literature.
Good. And what will happen if you start writing data in two DMA streams at once? How much speed will fall? Connect the blue ray to PA0 and rewrite the program as follows:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // Всё, настроили и запустили DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); First, examine the nature of the pulses:
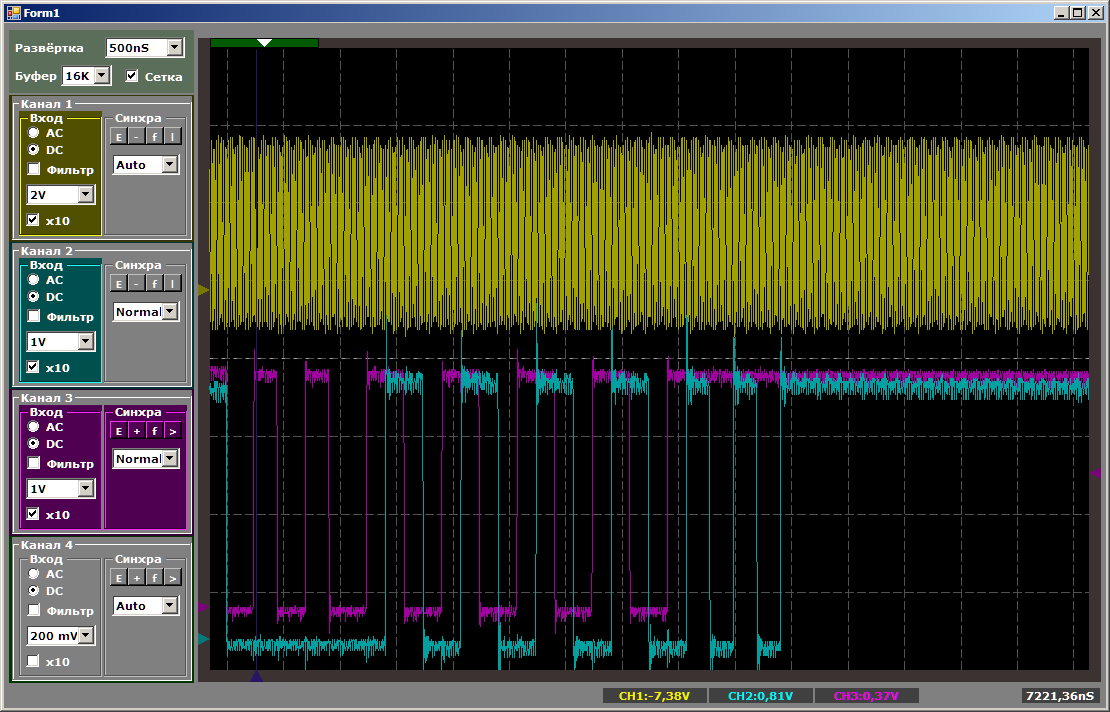
While the second channel is setting up, the copy speed for the first is higher. Then, when copying in pairs, speed drops. When the first channel has finished work, the second starts to work faster. Everything is logical, it remains only to find out how much speed drops.
While the channel is one, the recording takes from 10 to 12 cycles (the numbers are floating).

During collaboration, we get 16 cycles for one record in each port:
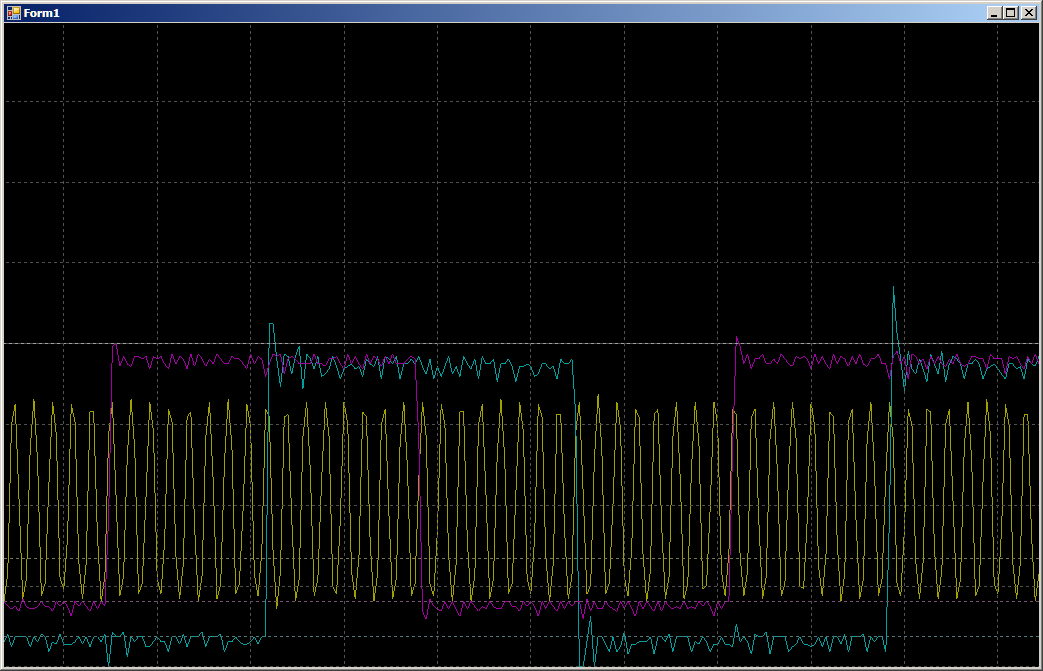
That is, the speed does not fall twice. And what if you start writing in three streams at once? We add work with PC15, since PC0 is not displayed (that is why it is not 0, 1, 0, 1 ... issued in the array, but 0x0000.0x8001, 0x0000, 0x8001 ...).
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // Всё, настроили и запустили DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); Here the result is so unexpected that I will turn off the beam that displays the clock frequency. We are not up to measurement. We look at the logic of work.

Until the first channel finished, the third one did not start. Three channels do not work at the same time! Something on this topic can be derived from AppNote on DMA, it says that the F103 has only two Engine in one block (and we copy by means of one DMA block, the second one is now idle, and the volume of the article is such that I let it go I will not). Let's rewrite the sample program so that the third channel starts up before everyone else:

Same text:
// Всё, настроили и запустили DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); The picture will change as follows:

The third channel was launched, it even worked together with the first, but as it entered the second one, the third one was pushed out until the first channel finished its work.
A little bit about priorities
Actually, the previous picture is related to the priorities of the DMA, there are some. If all working channels have the same priority, their numbers come into play. Within the limits of one given priority, who has a smaller number, that is more important. Let's try to indicate to the third channel a different global priority, raising it above all others (at the same time we will raise the priority to the second channel):

Same text:
channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); Now the first will be infringed upon, which was the coolest before.
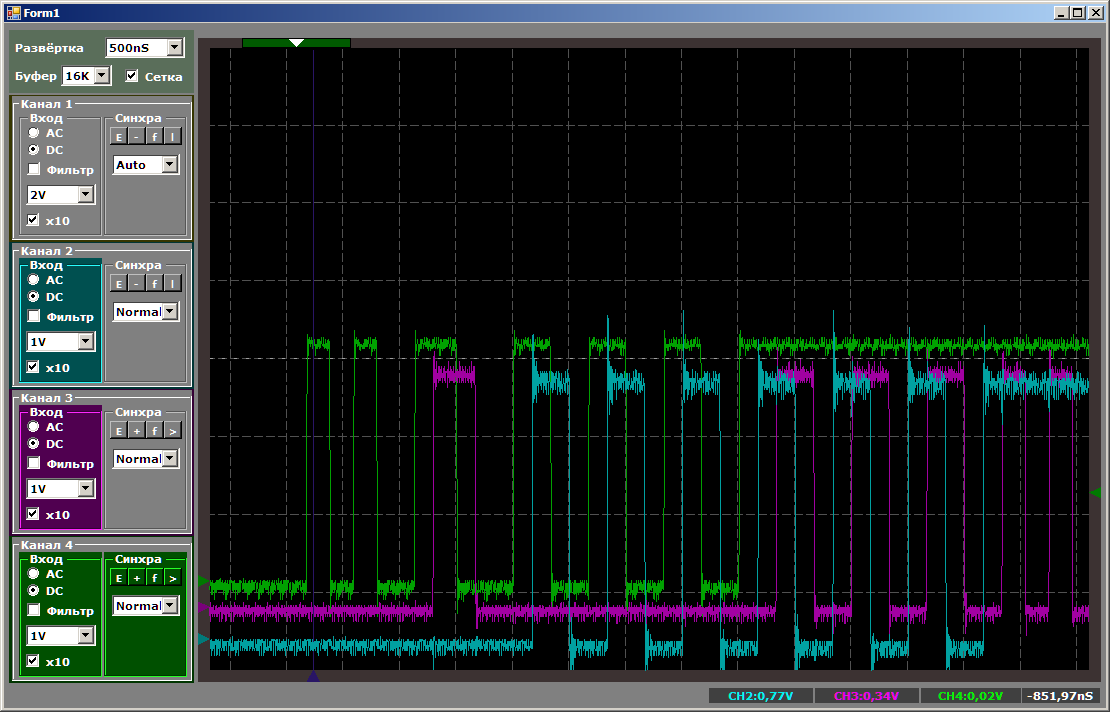
In total, we see that even playing in priorities, more than two streams on one DMA block in STM32F103 will not work. In principle, the third thread can be run on the processor core. This will allow us to compare performance.
// Всё, настроили и запустили DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; } First, the general picture, which shows that everything works in parallel and the copy speed of the processor core is the highest:
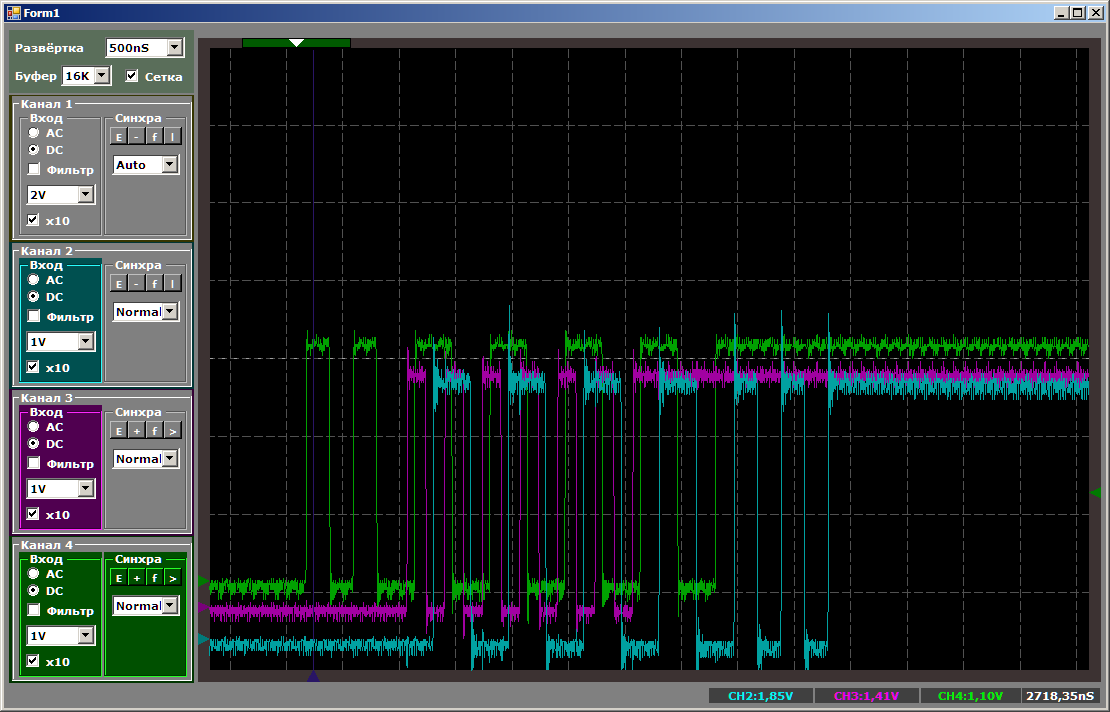
And now I will give everyone the opportunity to count the bars at a time when all the copy streams are active:
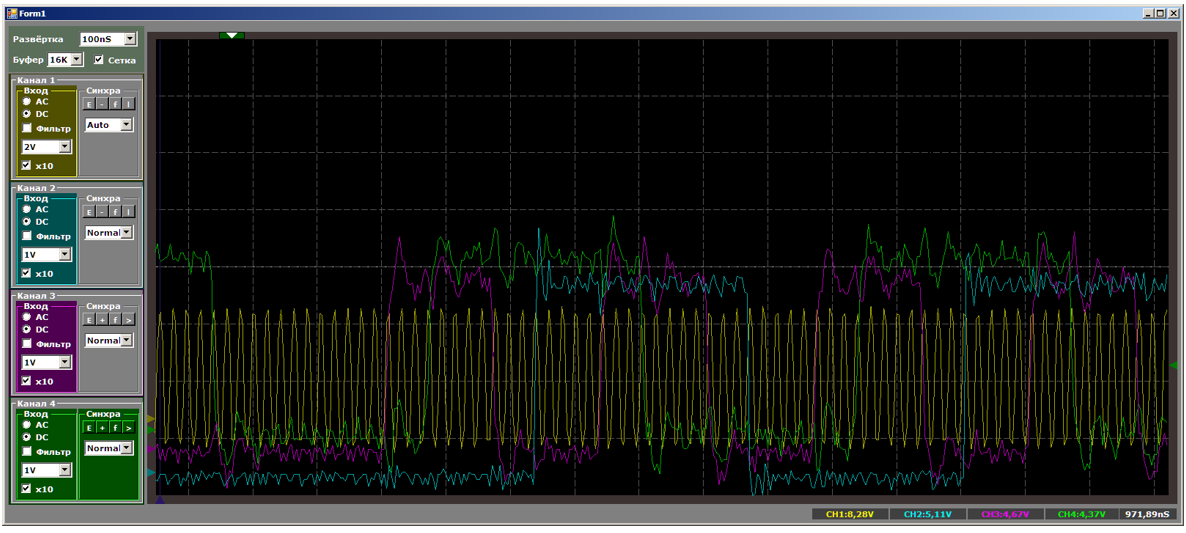
The processor core is the top priority
Now back to the fact that in a two-stream operation, while the second channel was tuned, the first one gave out data for a different number of cycles. This fact is also well documented in AppNote on DMA. The fact is that during the setup of the second channel, there were periodic requests to the RAM, and the processor core has a higher priority when accessing the RAM than the DMA core. When the processor requested some data, DMA took the clock cycles, it received data with a delay, so it copied more slowly. Let's do the last experiment for today. Let's work more real. After starting DMA, we will not go into an empty cycle (when there are definitely no calls to RAM), but perform the copy operation from RAM to RAM, but this operation will not relate to the operation of DMA cores:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } } 
In some places the cycle stretched from 16 to 17 cycles. I was afraid it would be worse.
We begin to draw conclusions
Actually, we proceed to what I wanted to say.
I'll start from afar. A few years ago, starting to learn STM32, I studied the MiddleWare versions for USB that existed at that time and wondered why the developers removed the data transfer through DMA. It was evident that initially such an option was visible, then it was removed to the back, and in the end only the rudiments of it remained. Now I begin to suspect that I understand the developers.
In the first article about UDB, I said that even though UDB can work with parallel data, it is unlikely to be able to replace GPIF with itself, since PSoC has a USB bus running at Full Speed speed versus High Speed for FX2LP. It turns out that there is a more serious limiting factor. DMA simply does not have time to deliver data at the same speed as it delivers its GPIF even within the controller, without taking into account the USB bus.
As you can see, there is no single entity DMA. First, each manufacturer makes it its own way. Moreover, even one manufacturer for different families can vary the approach to the construction of DMA. If you plan a serious load on this unit, you should carefully consider whether the needs will be met.
Probably, it is necessary to dilute the pessimistic flow with one optimistic remark. I will even highlight it.
DMA at the Cortex M controllers can improve system performance on the principle of the famous Javelin: "Launched and forgotten." Yes, software data copying is a little faster. But if you need to copy several threads, no optimizer will be able to make the processor drive all of them without the overhead of reloading registers and twisting loops. In addition, for slower ports, the processor must still wait for readiness, while DMA does it at the hardware level.
But even here various nuances are possible. If the port is only conditionally slow ... Well, let's say, SPI, working at the highest possible frequency, then theoretically there are situations when DMA does not have time to take data from the buffer, and an overflow will occur. Or vice versa - put the data in the buffer register. When there is only one stream of data, this is unlikely to happen, but when there are a lot of them, we have seen what amazing overlays can occur. To combat this, it is necessary to develop tasks not separately, but as a whole. And testers try to provoke similar problems (such as testers have destructive work).
I repeat once again that nobody hides this data. But for some reason, all this is usually contained not in the main document, but in Application Notes. So my task was precisely to draw the attention of programmers to the fact that DMA is not a panacea, but just a handy tool.
But, of course, not only programmers, but also hardware developers. For example, in our organization a large hardware and software complex is being developed for remote debugging of embedded systems. The idea is that someone is developing a device, and wants to order the firmware on the side. And for some reason can not provide equipment to the side. It can be cumbersome, it can be expensive, it can be unique and “need it yourself”, different groups can work with it in different time zones, providing such multi-shift work, it can be constantly brought to mind ... In general, you can think of reasons a lot, our group just lowered this task as a given.
Accordingly, the complex for debugging should be able to imitate as many external devices as possible, from the banal imitation of pressing buttons to various SPI, I2C, CAN, 4-20 mA protocols and other things, other things, so that emulators can recreate various external behavior through them. units connected to the equipment under development (I personally made many simulators for ground debugging of attachments for helicopters, we search for the corresponding cases on the site according to the word Cassel Aero ).
And so, in the TOR for the development of certain requirements are lowered. So much SPI, so much I2C, so much GPIO. They must operate at such a certain frequency limit. It seems that everything is clear. We put STM32F4 and ULPI to work with USB in HS mode. Technology waste. But here come the long weekend with the November holidays, on which I figured out with the UDB. Seeing something was amiss, in the evenings I got those practical results that are given at the beginning of this article. And I realized that everything, of course, is great, but not for this project. As I have already noted, when the possible peak performance of the system approaches the upper boundary, everything should be designed not separately, but in combination.
And here the complex design tasks can not be in principle.Today we are working with one third-party equipment, tomorrow - with a completely different one. Tires will be used by programmers for each emulation at their discretion. Therefore, the variant was rejected, a number of different FTDI bridges were added to the scheme. Within the bridge one or two or four functions will be destroyed according to a rigid scheme, and between the bridges everything will be settled by the USB host. Alas.In this task, I cannot trust DMA. You can, of course, say that programmers will then get out, but the clock on the process of frills is the work to be avoided.
But this is extreme. Most often, you should just keep the limitations of the DMA subsystem in your mind (for example, to introduce a correction factor of 10: if a flow of 1 million transactions per second is required, consider that it is not 1 million, but 10 million cycles) and consider the performance in the complex.
Source: https://habr.com/ru/post/437112/