Everyone scolds samopisnye test frameworks. And we are happy

My name is Elena Rastorgueva, I am responsible for the “Factor” product in HFLabs . “Factor” is a damn complex algorithmic enterprise, it processes data on an industrial scale.
In the article I will tell you how we started to test "Factor", how we developed autotests and why we came up with self-written frameworks.
What kind of product is this - "Factor"
"Factor" cleans up data in databases with millions of customers: it removes typos in name, phone numbers and emails, checks passports, does a whole lot more. The most difficult thing is to correct postal addresses.

Addresses are written in hundreds of ways, so under the hood of the "Factor" is not weak algorithmic apparatus
"Factor" works as a service: input data - data output.
This is a stateless system, where each appeal does not depend on previous ones. Stateless greatly simplifies the life of a tester. It is much more difficult to test a stateful system when the sequence of actions is important.
The product must be reliable as the MKS, because it is used by banks, mobile operators, insurance, retailers of the “Ribbon” level. For errors, we are responsible for the fact that the absence of errors is part of the SLA in the contract with the customer.
Because of the reliability requirements of autotests, we wrote from the very beginning of development. One of the criteria for the readiness of the task is “AutoTests added”.
Started with manual checks and autotests.
We released "Factor" in 2005 and first tested it with our hands. In the morning, the tester ran autotests on a case file and compared the result of data processing with the result of the previous day: what changed after yesterday's code commit.
The process could take half a day, this alignment was no good. Therefore, we took the minimum set of tests for key functionality and wrapped it in unit tests. These tests are fast, and the developer himself started them before the commit.
Unit tests are so comfortable and work so fast that we add thousands of them. And then they came up against it: when the tests look like a sheet of thousands of pieces of code, it is not easy even to reach the right place. Not to mention adding or updating.

Unit test for checking the format of SNILS
In addition, in the industrial data regularly there is something sudden that does not cover unit tests. For example, a new customer has come with new features in the addresses, unit tests do not cover these features. We need to sit down and see which tests to add for new data. We still did it manually.
Created your own framework
In traditional unit tests, the data and code go interspersed, trying to find the right parts is difficult.
Therefore, we tried autotests in the Data Driven Testing (DDT) paradigm. DDT is when data for testing is stored separately from code for testing.
Cases were loaded from an excel-file, they lay in the columns "Unclean data" and "Expected result". DDT has become a breakthrough: updating cases in an exelnik is unspeakably simpler.
Little by little, we developed an approach and developed our own framework for testing. It accepts text files as input, inside them the source data and the expected result.

We refused excel files as storage: text files open faster, do not change content, it is easier to take data from them
Standard tools help the framework:
- TeamCity automatically runs tests every night;
- testNG compares the expected and actual results.

If the result is different from the expected one, the test turns red in TeamCity. If everything is as it should, the test is green.
Finished the framework for themselves
12 years have passed since then. During this time, the framework has acquired capabilities that are not found in standard solutions.
Accounting for task status in Jira. HFLabs adheres to Test Driven Development : first write a test or add test cases to a new behavior, and only then change the functionality.
We have disabled new cases by commenting on the line. Otherwise, at first they fell and interfered, because cases added before features or bug fixes.
But the corresponding test case may not be completed: the bug will be extremely rare, or the customer will bring something more important. Some tasks hung for months with low priority, and disconnected cases accumulated. In this case, it is not clear to which task each case belongs, whether it is possible to delete this case.
Therefore, we added a task number to the disconnected cases and screwed in some automation. Now everything works like this:
- the test case is disabled by matching the open task in Jira;

To bind the case to the task, we write in front of it # and the number of the task - The framework runs tests even on disconnected cases. But it ignores crashes, as long as the task is open in Jira;
- as soon as the task is closed, the test begins to fall on the cases attached to it. This is a signal: the task was passed, and the cases were forgotten to be included;
- if suddenly the test for a disconnected case began to take place with an open task, the framework also reports this. Perhaps it's time to turn on the case or close the task attached to it (plus update the release notes and inform customers).

The framework says that the disconnected case passes. Perhaps someone corrected the code in another task, and now everything is working.
So we kept the TDD and won the forgetfulness while managing the test cases.
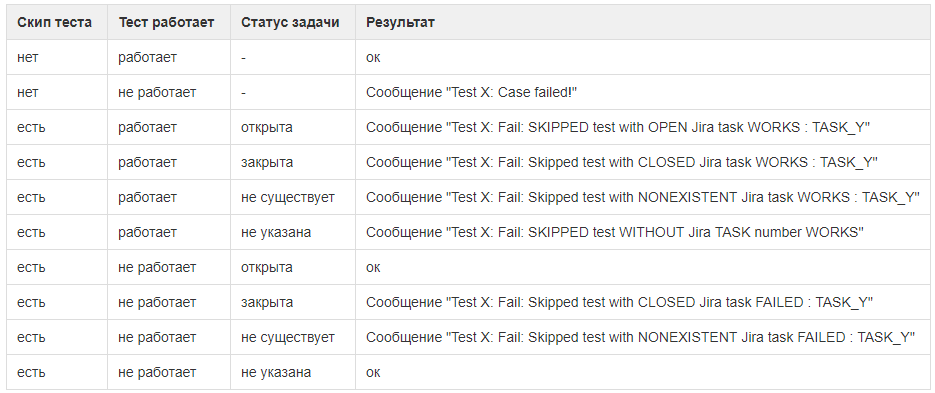
We documented all the options with the status of test cases and related tasks in order not to forget
Actualization of test cases in semi-automatic mode. It would seem that if the test fails, look for an error in the code. But for us this is not always the case. It happens that it is necessary to update the test cases, because the requirements for the result have changed.
For example, in the past, the customer wanted “Mr. Moscow "one field. Now he has changed the architecture of the database, wants a “city” in one field, “Moscow” in another. It's time to change test cases.
For the fallen test TeamCity shows the difference between the expected and actual results. We used to copy this difference and update test cases with our hands. For massive changes - a very costly undertaking.

A living example: we taught "Factor" to determine the country by phone number, tests in TeamCity fell. A new benchmark can be taken from the actual result, but it takes a long time.
We made it so that the framework itself updated the standard. To do this, after running the tests, it replaces in the benchmark the expected cleaning results with actual ones where they did not match. The result is saved in artifacts as a case update file.
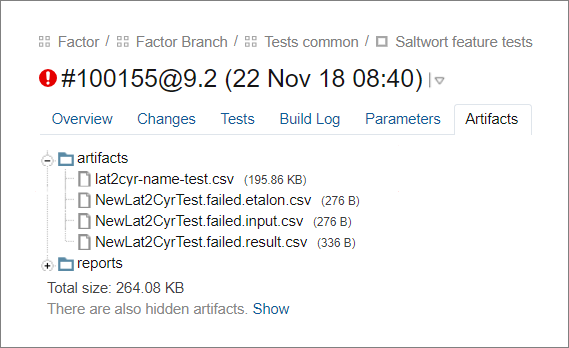
The first file is a new benchmark in which the framework updated the expected results. The remaining files are input data, the old standard and the actual data for the fallen cases.
With the new benchmark, the tester updates the cases in three steps.
- Downloads the generated file.
- Checks through any tool merging, what changes have fallen into the new standard. Leaves only the necessary.
- Commit

The tester checks if the updates in the new benchmark are correct and commits them.
Yes, if you update thoughtlessly, nothing good will come out. But the risk of mindless updating is also when working manually.
Stabilization of test data stubs. "Factor" returns the processed data in dozens of fields. In the address alone there are a lot of components: index, region, type of region, type of city, city, type of street, house, building, building, apartment. To them, "Factor" clings to the Federal Tax Service Inspectorate, OKATO, OKTMO and even small things. So from one line on an input tens values are obtained.
Not all fields from the result should be checked with test cases. For example, recognition of the same address directly depends on the state directory - FIAS. And in it fields regularly change, for our tasks absolutely strangers. Updating any KLADR codes for homes dropped hundreds of test cases.
We added stubs to the expected result when we realized that we were wasting time analyzing unimportant falls.
When the field does not need to be checked at all, the tester writes the following symbol to the expected result: $$ DNV $$ . When the field is to be filled, but the value itself is not important: $$ NE $$ .
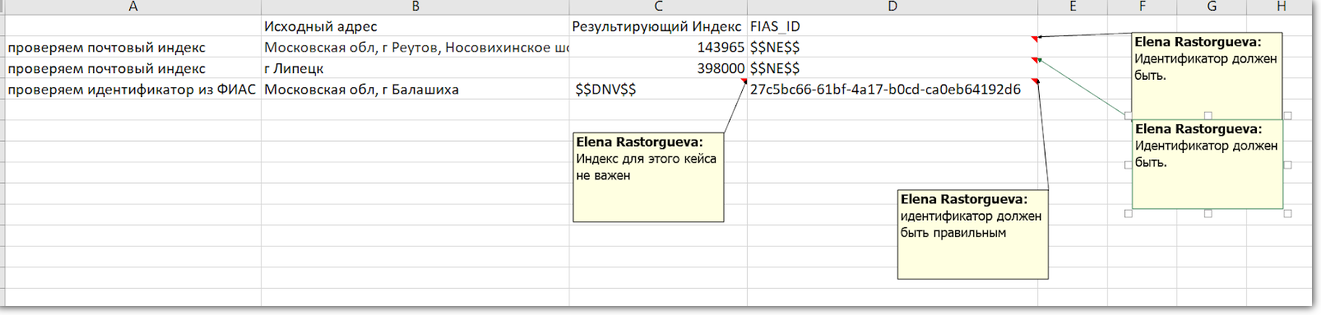
FIAS ID in the address is always there, so we check it on all tests. If the field is empty, something is wrong. But the index may not be, therefore, when checking the FIAS ID index, we ignore
It was possible to go the other way and divide the tests: on each field its own. But it is difficult, because not everything can be isolated. For example, the "city" and "street" are parts of the address and without each other does not make sense.
Self-written framework is more convenient
Therefore, I do not think that creating my own framework is a silly idea. If we didn’t create our own tool, we wouldn’t get so many new opportunities and such flexibility.
Turning off the text-case on the status of the task, the generation of a new standard, stubs on the result - these are the things that our testers are asking for in the other frameworks. If we had taken standard solutions, we would never have been able to do this.
If you like to do complex things in the enterprise, come to us. Now we are looking for a java-developer , salary from 135 000 ₽ without deduction of personal income tax.
Source: https://habr.com/ru/post/437380/