How I taught the robot to run YouTube videos
We continue to talk about joint research projects of our students and JetBrains Research. In this article we will talk about the algorithms of deep learning with reinforcement, which are used to simulate the human motor apparatus.
To simulate all possible movements of a person and describe all the scenarios of behavior is a rather difficult task. If we learn to understand how a person moves, and we can reproduce his movements “in the image and likeness” - this will greatly facilitate the introduction of robots in many areas. Just so that robots learn to repeat and analyze the movements themselves, and machine learning is used.

My name is Alexander Malyshev, I am a graduate of a bachelor’s degree in Applied Mathematics and Informatics at St. Petersburg Academic University, and since this fall I am a first-year student at the St. Petersburg Higher School in Programming and Data Analysis. In addition, I work in the “Agent Systems and Reinforcement Training” laboratory at JetBrains Research, and I also teach classes - lectures and practices - at the undergraduate program at the St. Petersburg Higher School.
At the moment I am working on several projects in the field of deep learning with reinforcement (we started talking about this in the previous article). And today I want to show my first project, which smoothly emerged from my thesis.

To imitate the human musculoskeletal system, special environments are created that try to simulate the physical world as accurately as possible to solve a specific problem. For example, the NIPS 2017 competition focused on creating a humanoid robot that simulates human walking.
To solve this problem, commonly used methods of in-depth training with reinforcement, which lead to a good, but not optimal strategy. In addition, in most cases, the training time is too long.
As was rightly pointed out in the previous article , the main problem when moving from invented / simple tasks to real / practical tasks is that rewards in such tasks are usually very rare. For example, we can evaluate the passage of a long distance only in the case when the agent has reached the finish. For this, he needs to perform a complex and correct sequence of actions, which is not always the case. This problem can be solved by giving the agent at the start examples of how to “play” - the so-called expert demonstrations.
I used this approach to solve this problem. It turned out that to significantly improve the quality of training, we can use videos that show the movement of a person during a run. In particular, you can try to use the motion coordinates of specific body parts (for example, feet) taken from a video on YouTube.
In reinforcement learning tasks, the interaction of the agent and the environment is considered. One of the modern environments for modeling the human musculoskeletal system is the simulation environment OpenSim, using the physics engine Simbody.
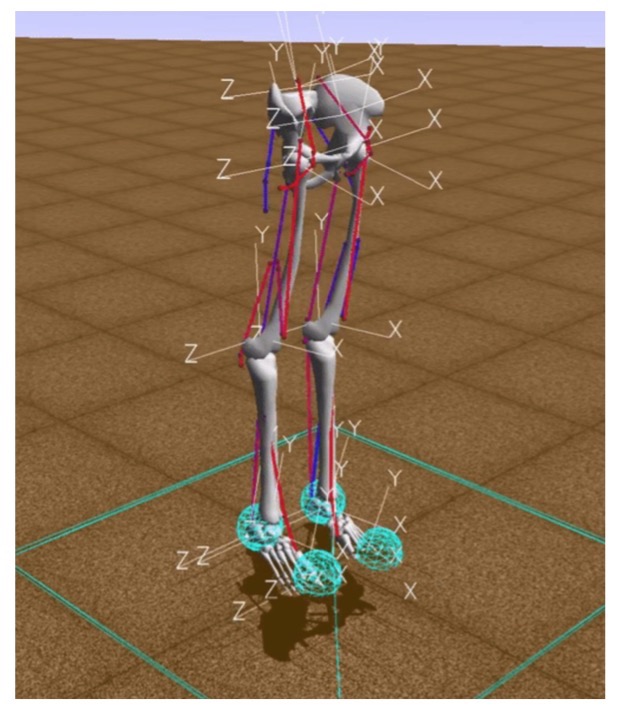
In this environment, the “environment” is a three-dimensional world with obstacles, the “agent” is a humanoid robot with six joints (ankle, knees and hips on two legs) and muscles that simulate the behavior of human muscles, and “agent action” is real values from 0 to 1, which determine the tension of the existing muscles.
The reward is calculated as changing the position of the pelvis along the x axis minus the penalty for using bundles. Thus, on the one hand, you need to go as far as possible for a certain time, and, on the other hand, you need to make sure that the muscles “work” as little as possible. The training episode ends when either 1000 iterations are reached, or the pelvis height is lower than 0.65 meters, which means the fall of the human model.
The main task of reinforcement learning is to teach the robot to move quickly and efficiently in the environment.
To test the hypothesis of whether learning at demonstrations helps, it was necessary to implement a basic algorithm that would learn to run fast, but suboptimally, like many already existing examples.
To do this, we applied several tricks:

This graph shows the improvement after each of the above optimizations, it shows the reward received for the epoch from the time of study.
After developing the base model, we added the formation of a reward based on a potential function. A potential function is introduced in order to give the robot useful information about the world around us: we say that some body positions that the running character took on the video are more “beneficial” (that is, it receives a greater reward for them) than others.
We built the function on the basis of video data taken from YouTube-videos with the image of the running of real people and human characters of cartoons and computer games. The total potential function was defined as the sum of the potential functions for each body part: a pelvis, two knees, and two feet. Following the potential-based approach to the formation of remuneration, at each iteration of the algorithm, the agent is provided with an additional remuneration corresponding to changes in the potentials of the previous and current state. Potential functions of separate parts of the body were built using the inverse distances between the corresponding coordinate of the body part in the video-generated data and the humanoid robot.
We looked at three data sources:

Becker Alan. Animating Walk Cycles - 2010

ProcrastinatorPro. QWOP Speedrun - 2010

ShvetsovLeonid.HumanSpeedrun - 2015
... and three different distance functions:
Here dx (dy) is the absolute difference between the x (y) coordinate of the corresponding body parts taken from the video data and the x (y) coordinate of the agent.
Below are the results obtained when comparing various data sources for a potential function based on PF2:

Comparison of performance between the baseline and the approach to the formation of remuneration:

It turned out that the formation of remuneration significantly accelerates learning, reaching double speed in 12 hours of training. The end result after 24 hours still shows a significant advantage of the approach using the potential functions method.
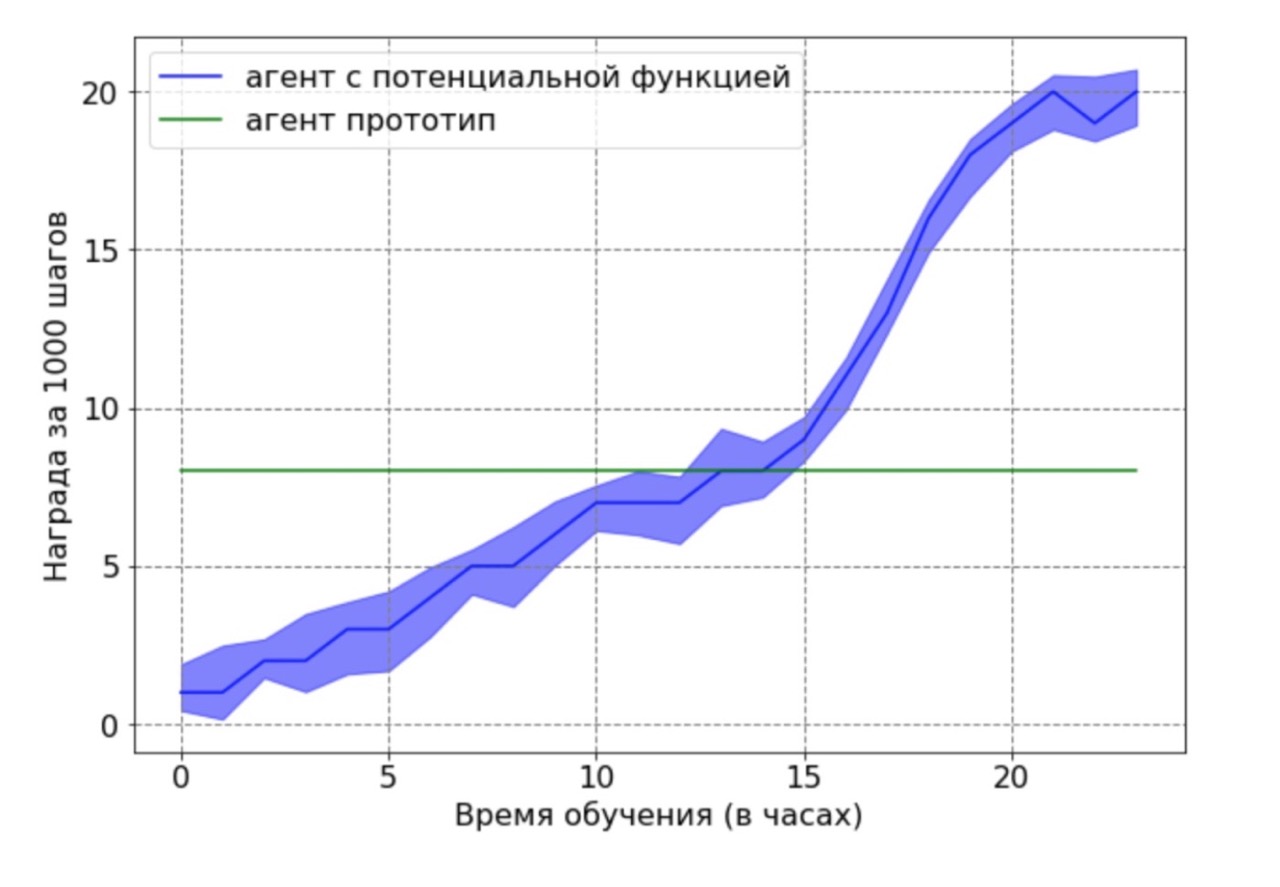
Separately, I would like to note the following important result: we were able to theoretically prove that a reward based on a potential function does not impair the optimal policy. In order to demonstrate this advantage in this context, we used a suboptimal agent generated by the base agent after 12 hours of training. The resulting prototype agent was used as a data source for a potential function. Obviously, the resulting agent with this approach will not work optimally, and the position of the feet and knees in most cases will not be in optimal positions. Then the agent trained by the DDPG algorithm using the potential function was trained on the data obtained. Next, a comparison was made of the learning outcomes of an agent with a potential function with a prototype agent. The agent training schedule demonstrates that the RL agent is able to overcome the suboptimal performance of the data source.
I completed my graduation project quite early. It should be noted that we have a very responsible approach to the protection of a diploma. Already in September, students know the topic, the evaluation criteria, and when to do it. When everything is so clear, it is very convenient to work, there is no feeling “I have a whole year ahead, I can start doing it from the next week / month / half-year”. As a result, if you work effectively, you can get the final results of the thesis by the New Year, and spend the remaining time on setting up the model, collecting statistically significant results and writing the text of the diploma. That is exactly what happened to me.
Two months before the diploma defense, I already had the text of the work ready, and my supervisor, Alexey Alexandrovich Shpilman, offered to write an article at Workshop on Adaptive and Learning Agents (ALA) at ICML-AAMAS. The only thing I had to do was translate and repack thesis. As a result, we sent an article to the conference and ... she was accepted! This was my first publication and I was extremely happy when I saw in my mail a letter with the word “Accepted”. Unfortunately, at the same time I was training in South Korea and could not personally attend the conference.
In addition to the publication and recognition of the work done, the first conference brought me another pleasant result. Alexey Alexandrovich began to involve me in writing reviews for other people's work. It seems to me that this is very useful for gaining experience in evaluating new ideas: this way you can learn to analyze existing works, check the idea for originality and relevance.
After Korea, I got an internship at JetBrains Research and continued working on the project. It was at this point that we checked three different formulas for the potential function and made a comparison. We really wanted to share the results of our work, so we decided to write a full-fledged article on the main track ICARCV conference in Singapore.
Write an article on the workshop is good, but on the main track - better. And, of course, I was very glad when I learned that the article was accepted! Moreover, our colleagues and sponsors from JetBrains agreed to pay for my trip to the conference. A great bonus was the opportunity to get acquainted with Singapore.
When the tickets were already purchased, the hotel was booked and all I could do was get a visa, a letter arrived in the mail:

I was not given a visa despite the fact that I had documents confirming the presentation at the conference! It turns out that the Embassy of Singapore does not accept applications from unmarried and unemployed girls under 35 years of age. And even if the girl works, but not married, the chance to get a waiver is still very great.
Fortunately, I learned that citizens of the Russian Federation traveling in transit can stay in Singapore for up to 96 hours. As a result, I flew to Malaysia via Singapore, where I spent a total of almost eight days. The conference itself lasted six days. Due to restrictions, I attended the first four, then I had to leave to return to the closing. After the conference, I decided to feel like a tourist and just walked around the city for two days and visited museums.
I prepared a speech at the ICARCV in advance, back in St. Petersburg. Rehearsed him at a reinforcement training workshop. Therefore, speaking at the conference was exciting, but not scary. The speech itself lasted 15 minutes, but after it there was a section of questions, which seemed to me very useful.
I was asked some pretty interesting questions that pushed new ideas. For example, about how we tagged data. In our work, we labeled the data manually, and we were offered to use a library that automatically understands where the parts of the human body are. Now we have just begun to implement this idea. Read the entire work can be on the link .
At ICARCV, I enjoyed talking with scientists and learned a lot of new ideas. The number of interesting articles that I met in these few days was more than in the previous four years. Now there is a machine learning “HYIP” in the world, and every day dozens of new articles appear on the Internet, among which it is very difficult to find something worthwhile. It is for this, I think, that it is worth going to conferences: to find communities that discuss new interesting topics, learn about new ideas and share their own. And make friends!
To simulate all possible movements of a person and describe all the scenarios of behavior is a rather difficult task. If we learn to understand how a person moves, and we can reproduce his movements “in the image and likeness” - this will greatly facilitate the introduction of robots in many areas. Just so that robots learn to repeat and analyze the movements themselves, and machine learning is used.
About myself
My name is Alexander Malyshev, I am a graduate of a bachelor’s degree in Applied Mathematics and Informatics at St. Petersburg Academic University, and since this fall I am a first-year student at the St. Petersburg Higher School in Programming and Data Analysis. In addition, I work in the “Agent Systems and Reinforcement Training” laboratory at JetBrains Research, and I also teach classes - lectures and practices - at the undergraduate program at the St. Petersburg Higher School.
At the moment I am working on several projects in the field of deep learning with reinforcement (we started talking about this in the previous article). And today I want to show my first project, which smoothly emerged from my thesis.
Task Description
To imitate the human musculoskeletal system, special environments are created that try to simulate the physical world as accurately as possible to solve a specific problem. For example, the NIPS 2017 competition focused on creating a humanoid robot that simulates human walking.
To solve this problem, commonly used methods of in-depth training with reinforcement, which lead to a good, but not optimal strategy. In addition, in most cases, the training time is too long.
As was rightly pointed out in the previous article , the main problem when moving from invented / simple tasks to real / practical tasks is that rewards in such tasks are usually very rare. For example, we can evaluate the passage of a long distance only in the case when the agent has reached the finish. For this, he needs to perform a complex and correct sequence of actions, which is not always the case. This problem can be solved by giving the agent at the start examples of how to “play” - the so-called expert demonstrations.
I used this approach to solve this problem. It turned out that to significantly improve the quality of training, we can use videos that show the movement of a person during a run. In particular, you can try to use the motion coordinates of specific body parts (for example, feet) taken from a video on YouTube.
Environment
In reinforcement learning tasks, the interaction of the agent and the environment is considered. One of the modern environments for modeling the human musculoskeletal system is the simulation environment OpenSim, using the physics engine Simbody.
In this environment, the “environment” is a three-dimensional world with obstacles, the “agent” is a humanoid robot with six joints (ankle, knees and hips on two legs) and muscles that simulate the behavior of human muscles, and “agent action” is real values from 0 to 1, which determine the tension of the existing muscles.
The reward is calculated as changing the position of the pelvis along the x axis minus the penalty for using bundles. Thus, on the one hand, you need to go as far as possible for a certain time, and, on the other hand, you need to make sure that the muscles “work” as little as possible. The training episode ends when either 1000 iterations are reached, or the pelvis height is lower than 0.65 meters, which means the fall of the human model.
Base implementation
The main task of reinforcement learning is to teach the robot to move quickly and efficiently in the environment.
To test the hypothesis of whether learning at demonstrations helps, it was necessary to implement a basic algorithm that would learn to run fast, but suboptimally, like many already existing examples.
To do this, we applied several tricks:
- To begin with, it was necessary to adapt the OpenSim environment in order to effectively use reinforcement learning algorithms. In particular, in the description of the environment, we added the two-dimensional coordinates of the positions of body parts relative to the pelvis.
- The number of distance passing examples was increased due to the symmetry of the environment. In the initial position, the agent is absolutely symmetrical with respect to the left and right side of the body. Therefore, after one passage of the distance, two examples can be added at once: the one that occurred, and mirror-symmetrical with respect to the left or right side of the agent's body.
- To increase the speed of the algorithm, frame skipping was implemented: the launch of the algorithm for selecting the next agent action was performed only every third iteration, in other cases the last selected action was repeated. Thus, the number of iterations of the launch of the agent action selection algorithm was reduced from 1000 to 333, which reduced the number of required calculations.
- Previous modifications significantly accelerated learning, but the learning process was still slow. Therefore, an acceleration method was additionally implemented, associated with a decrease in the accuracy of the calculations: the type of values used in the agent state vector was changed from double to float.
This graph shows the improvement after each of the above optimizations, it shows the reward received for the epoch from the time of study.
So what's the deal with YouTube?
After developing the base model, we added the formation of a reward based on a potential function. A potential function is introduced in order to give the robot useful information about the world around us: we say that some body positions that the running character took on the video are more “beneficial” (that is, it receives a greater reward for them) than others.
We built the function on the basis of video data taken from YouTube-videos with the image of the running of real people and human characters of cartoons and computer games. The total potential function was defined as the sum of the potential functions for each body part: a pelvis, two knees, and two feet. Following the potential-based approach to the formation of remuneration, at each iteration of the algorithm, the agent is provided with an additional remuneration corresponding to changes in the potentials of the previous and current state. Potential functions of separate parts of the body were built using the inverse distances between the corresponding coordinate of the body part in the video-generated data and the humanoid robot.
We looked at three data sources:
Becker Alan. Animating Walk Cycles - 2010
ProcrastinatorPro. QWOP Speedrun - 2010
ShvetsovLeonid.HumanSpeedrun - 2015
... and three different distance functions:
Here dx (dy) is the absolute difference between the x (y) coordinate of the corresponding body parts taken from the video data and the x (y) coordinate of the agent.
Below are the results obtained when comparing various data sources for a potential function based on PF2:
results
Comparison of performance between the baseline and the approach to the formation of remuneration:
It turned out that the formation of remuneration significantly accelerates learning, reaching double speed in 12 hours of training. The end result after 24 hours still shows a significant advantage of the approach using the potential functions method.
Separately, I would like to note the following important result: we were able to theoretically prove that a reward based on a potential function does not impair the optimal policy. In order to demonstrate this advantage in this context, we used a suboptimal agent generated by the base agent after 12 hours of training. The resulting prototype agent was used as a data source for a potential function. Obviously, the resulting agent with this approach will not work optimally, and the position of the feet and knees in most cases will not be in optimal positions. Then the agent trained by the DDPG algorithm using the potential function was trained on the data obtained. Next, a comparison was made of the learning outcomes of an agent with a potential function with a prototype agent. The agent training schedule demonstrates that the RL agent is able to overcome the suboptimal performance of the data source.
The first steps in science
I completed my graduation project quite early. It should be noted that we have a very responsible approach to the protection of a diploma. Already in September, students know the topic, the evaluation criteria, and when to do it. When everything is so clear, it is very convenient to work, there is no feeling “I have a whole year ahead, I can start doing it from the next week / month / half-year”. As a result, if you work effectively, you can get the final results of the thesis by the New Year, and spend the remaining time on setting up the model, collecting statistically significant results and writing the text of the diploma. That is exactly what happened to me.
Two months before the diploma defense, I already had the text of the work ready, and my supervisor, Alexey Alexandrovich Shpilman, offered to write an article at Workshop on Adaptive and Learning Agents (ALA) at ICML-AAMAS. The only thing I had to do was translate and repack thesis. As a result, we sent an article to the conference and ... she was accepted! This was my first publication and I was extremely happy when I saw in my mail a letter with the word “Accepted”. Unfortunately, at the same time I was training in South Korea and could not personally attend the conference.
In addition to the publication and recognition of the work done, the first conference brought me another pleasant result. Alexey Alexandrovich began to involve me in writing reviews for other people's work. It seems to me that this is very useful for gaining experience in evaluating new ideas: this way you can learn to analyze existing works, check the idea for originality and relevance.
Write an article at the workshop is good, but on the main track - better
After Korea, I got an internship at JetBrains Research and continued working on the project. It was at this point that we checked three different formulas for the potential function and made a comparison. We really wanted to share the results of our work, so we decided to write a full-fledged article on the main track ICARCV conference in Singapore.
Write an article on the workshop is good, but on the main track - better. And, of course, I was very glad when I learned that the article was accepted! Moreover, our colleagues and sponsors from JetBrains agreed to pay for my trip to the conference. A great bonus was the opportunity to get acquainted with Singapore.
When the tickets were already purchased, the hotel was booked and all I could do was get a visa, a letter arrived in the mail:
I was not given a visa despite the fact that I had documents confirming the presentation at the conference! It turns out that the Embassy of Singapore does not accept applications from unmarried and unemployed girls under 35 years of age. And even if the girl works, but not married, the chance to get a waiver is still very great.
Fortunately, I learned that citizens of the Russian Federation traveling in transit can stay in Singapore for up to 96 hours. As a result, I flew to Malaysia via Singapore, where I spent a total of almost eight days. The conference itself lasted six days. Due to restrictions, I attended the first four, then I had to leave to return to the closing. After the conference, I decided to feel like a tourist and just walked around the city for two days and visited museums.
I prepared a speech at the ICARCV in advance, back in St. Petersburg. Rehearsed him at a reinforcement training workshop. Therefore, speaking at the conference was exciting, but not scary. The speech itself lasted 15 minutes, but after it there was a section of questions, which seemed to me very useful.
I was asked some pretty interesting questions that pushed new ideas. For example, about how we tagged data. In our work, we labeled the data manually, and we were offered to use a library that automatically understands where the parts of the human body are. Now we have just begun to implement this idea. Read the entire work can be on the link .
At ICARCV, I enjoyed talking with scientists and learned a lot of new ideas. The number of interesting articles that I met in these few days was more than in the previous four years. Now there is a machine learning “HYIP” in the world, and every day dozens of new articles appear on the Internet, among which it is very difficult to find something worthwhile. It is for this, I think, that it is worth going to conferences: to find communities that discuss new interesting topics, learn about new ideas and share their own. And make friends!
Source: https://habr.com/ru/post/437402/