We make a rating of cities in Russia for the quality of roads

Once again, driving a car through my native city and going around the next hole, I thought: are there such “good” roads everywhere in our country and I decided - we need to objectively evaluate the situation with the quality of roads in our country.
Task formalization
In Russia, the requirements for the quality of roads are described in GOST R 50597-2017 “Roads and streets. Requirements for the operational state, acceptable under the terms of road safety. Control methods". This document defines the requirements for roadway coverage, roadsides, dividing lanes, sidewalks, footpaths, etc., as well as establishes the types of damage.
Since the task of determining all the parameters of the roads is quite extensive, I decided to narrow it down for myself and dwell only on the task of determining the roadway coverage defects. In GOST R 50597-2017, the following defects in roadway coverage are distinguished:
- potholes
- breaks
- drawdowns
- shifts
- combs
- track
- bleeding binder
Identifying these defects I decided to do.
Dataset collection
Where can I get photographs that show fairly large sections of the roadway, and even with reference to geolocation? The answer came to the rhinestone - panoramas on Yandex (or Google) maps, however, looking a bit, I found some more alternative options:
- issuance of search engines on the pictures for relevant requests;
- photos on the sites for receiving complaints (Rosyama, Angry citizen, Dobrodel, etc.)
- on Opendatascience suggested a project for detecting road defects with marked datasets - github.com/sekilab/RoadDamageDetector
Unfortunately, the analysis of these options showed that they are not very suitable for me: search engines have a lot of noise (many photos that are not roads, various renders, etc.), photos from the sites for receiving complaints contain only photos with large violations of the asphalt pavement , there are quite a few photos with small violations of coverage and without violations on these sites, datasets from the RoadDamageDetector project are assembled in Japan and do not contain samples with large violations of coverage, as well as no roads at all.
If alternative options are not suitable, we will use Yandex panoramas (I excluded the Google panoramas option, since the service is presented in a smaller number of Russian cities and is updated less frequently). I decided to collect data in cities with a population of more than 100 thousand people, as well as in federal centers. Compiled a list of names of cities - there were 176 of them, later it turns out that there are only 149 panoramas in them. I will not go deeper into the particular parsing of tiles, I’ll say that I ended up with 149 folders (one for each city) containing 1.7 million photos in total. For example, for Novokuznetsk, the folder looked like this:

By the number of downloaded photos of the city were as follows:
Table
| City | Number of photos, pcs |
|---|---|
| Moscow | 86048 |
| St. Petersburg | 41376 |
| Saransk | 18880 |
| Podolsk | 18560 |
| Krasnogorsk | 18208 |
| Lyubertsy | 17760 |
| Kaliningrad | 16928 |
| Kolomna | 16832 |
| Mytishchi | 16192 |
| Vladivostok | 16096 |
| Balashikha | 15968 |
| Petrozavodsk | 15968 |
| Yekaterinburg | 15808 |
| Velikiy Novgorod | 15744 |
| Naberezhnye Chelny | 15680 |
| Krasnodar | 15520 |
| Nizhny Novgorod | 15488 |
| Khimki | 15296 |
| Tula | 15296 |
| Novosibirsk | 15264 |
| Tver | 15200 |
| Miass | 15104 |
| Ivanovo | 15072 |
| Vologda | 15008 |
| Zhukovsky | 14976 |
| Kostroma | 14912 |
| Samara | 14880 |
| Korolev | 14784 |
| Kaluga | 14720 |
| Cherepovets | 14720 |
| Sevastopol | 14688 |
| Pushkino | 14528 |
| Yaroslavl | 14464 |
| Ulyanovsk | 14400 |
| Rostov-on-Don | 14368 |
| Domodedovo | 14304 |
| Kamensk-Uralsky | 14208 |
| Pskov | 14144 |
| Yoshkar-Ola | 14080 |
| Kerch | 14080 |
| Murmansk | 13920 |
| Tolyatti | 13920 |
| Vladimir | 13792 |
| Eagle | 13792 |
| Syktyvkar | 13728 |
| Dolgoprudny | 13696 |
| Khanty-Mansiysk | 13664 |
| Kazan | 13600 |
| Engels | 13440 |
| Arkhangelsk | 13280 |
| Bryansk | 13216 |
| Omsk | 13120 |
| Sizran | 13088 |
| Krasnoyarsk | 13056 |
| Schyolkovo | 12928 |
| Penza | 12864 |
| Chelyabinsk | 12768 |
| Cheboksary | 12768 |
| Nizhny Tagil | 12672 |
| Stavropol | 12672 |
| Ramenskoye | 12640 |
| Irkutsk | 12608 |
| Angarsk | 12608 |
| Tyumen | 12512 |
| Odintsovo | 12512 |
| Ufa | 12512 |
| Magadan | 12512 |
| Permian | 12448 |
| Kirov | 12256 |
| Nizhnekamsk | 12224 |
| Makhachkala | 12096 |
| Nizhnevartovsk | 11936 |
| Kursk | 11904 |
| Sochi | 11872 |
| Tambov | 11840 |
| Pyatigorsk | 11808 |
| Volgodonsk | 11712 |
| Ryazan | 11680 |
| Saratov | 11616 |
| Dzerzhinsk | 11456 |
| Orenburg | 11456 |
| Mound | 11424 |
| Volgograd | 11264 |
| Izhevsk | 11168 |
| Chrysostom | 11136 |
| Lipetsk | 11072 |
| Kislovodsk | 11072 |
| Surgut | 11040 |
| Magnitogorsk | 10912 |
| Smolensk | 10784 |
| Khabarovsk | 10752 |
| Kopeisk | 10688 |
| Maykop | 10656 |
| Petropavlovsk-Kamchatsky | 10624 |
| Taganrog | 10560 |
| Barnaul | 10528 |
| Sergiev Posad | 10368 |
| Elista | 10304 |
| Sterlitamak | 9920 |
| Simferopol | 9824 |
| Tomsk | 9760 |
| Orekhovo-Zuyevo | 9728 |
| Astrakhan | 9664 |
| Evpatoria | 9568 |
| Noginsk | 9344 |
| Chita | 9216 |
| Belgorod | 9120 |
| Biysk | 8928 |
| Rybinsk | 8896 |
| Severodvinsk | 8832 |
| Voronezh | 8768 |
| Blagoveshchensk | 8672 |
| Novorossiysk | 8608 |
| Ulan-Ude | 8576 |
| Serpukhov | 8320 |
| Komsomolsk-on-Amur | 8192 |
| Abakan | 8128 |
| Norilsk | 8096 |
| Yuzhno-Sakhalinsk | 8032 |
| Obninsk | 7904 |
| Essentuki | 7712 |
| Bataysk | 7648 |
| Volzhsky | 7584 |
| Novocherkassk | 7488 |
| Berdsk | 7456 |
| Arzamas | 7424 |
| Pervouralsk | 7392 |
| Kemerovo | 7104 |
| Elektrostal | 6720 |
| Derbent | 6592 |
| Yakutsk | 6528 |
| Moore | 6240 |
| Nefteyugansk | 5792 |
| Reutov | 5696 |
| Birobidzhan | 5440 |
| Novokuibyshevsk | 5248 |
| Salekhard | 5184 |
| Novokuznetsk | 5152 |
| New Urengoy | 4736 |
| Noyabrsk | 4416 |
| Novocheboksarsk | 4352 |
| Dace | 3968 |
| Kaspiysk | 3936 |
| Stary Oskol | 3840 |
| Artyom | 3744 |
| Zheleznogorsk | 3584 |
| Salavat | 3584 |
| Prokopyevsk | 2816 |
| Gorno-Altaisk | 2464 |
Preparation of dataset for training
And so, it is assembled, how now, having a photo of the road section and the attached objects, find out the quality of the asphalt depicted on it? I decided to cut a piece of a photo of 350 * 244 pixels in the center of the original photo just below the middle. Then reduce the cut piece horizontally to the size of 244 pixels. The resulting image (244 * 244 in size) will be the input for a convolutional encoder:

In order to better understand what data I deal with the first 2000 pictures I have marked myself, the rest of the pictures were marked up by Yandex.Toloki employees. Before them I put the question in the following formulation.
Indicate which road surface you see in the photo:
- Ground / Rubble
- Stone blocks, tile, pavement
- Rails, railway tracks
- Water, large puddles
- Asphalt
- There is no road on the picture / Foreign objects / The coating is not visible because of the cars.
If the performer chose “Asphalt”, then a menu appeared offering to evaluate its quality:
- Excellent coverage
- Minor single cracks / shallow single potholes
- Large cracks / Cracked mesh / single small gaps
- Large number of potholes / Deep potholes / Destroyed cover
As the test launches of tasks have shown, the performers of Ya. Toloki do not differ in the good faith of work - they accidentally click the mouse on the fields and consider the task to be completed. I had to add test questions (there were 46 photographs in the assignment, 12 of which were control ones) and to include pending acceptance. As control questions, I used those pictures that I marked out myself. I automated the delayed acceptance - Ya.Toloka allows you to upload the results of work to a CSV-file, and upload the results of checking the answers. Verification of answers worked as follows - if the task contains more than 5% of incorrect answers to test questions, then it is considered unfulfilled. In this case, if the performer indicated an answer logically close to the correct one, then his answer is considered correct.
As a result, I received about 30 thousand marked-up photos, which I decided to distribute in three classes for training:
- "Good" - photos with the tags "Asphalt: Excellent coverage" and "Asphalt: Minor single cracks"
- “Middle” - photos with the tags “Paving, tile, pavement”, “Rails, railway tracks” and “Asphalt: Large cracks / Cracking grid / single not significant hollows”
- “Large” - photos tagged “Ground / Crushed Stone”, “Water, Large Puddles” and “Asphalt: Large Number of Potholes / Deep Potholes / Destroyed Coverage”
- Photos with tags “There is no road on the photo / Foreign objects / Coverage is not visible because of the machines” turned out to be very small (22 pcs.) And I excluded them from further work
Development and training of the classifier
So, the data is collected and marked up, we proceed to the development of the classifier. Usually, for image classification tasks, especially when training on small datasets, a ready convolutional encoder is used, to the output of which a new classifier is connected. I decided to use a simple classifier without a hidden layer, an input layer of size 128 and an output layer of size 3. I chose to use several ready-made variants trained on ImageNet as encoders:
- Xception
- Resnet
- Inception
- Vgg16
- Densenet121
- Mobilenet
Here is the function that creates the Keras-model with a given encoder:
def createModel(typeModel): conv_base = None if(typeModel == "nasnet"): conv_base = keras.applications.nasnet.NASNetMobile(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "xception"): conv_base = keras.applications.xception.Xception(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "resnet"): conv_base = keras.applications.resnet50.ResNet50(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "inception"): conv_base = keras.applications.inception_v3.InceptionV3(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "densenet121"): conv_base = keras.applications.densenet.DenseNet121(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "mobilenet"): conv_base = keras.applications.mobilenet_v2.MobileNetV2(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "vgg16"): conv_base = keras.applications.vgg16.VGG16(include_top=False, input_shape=(224,224,3), weights='imagenet') conv_base.trainable = False model = Sequential() model.add(conv_base) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.0002))) model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model I used a generator with augmentation for training (since the augmentation built into Keras seemed to me insufficient, I used the Augmentor library):
- Slopes
- Random distortion
- Turns
- Color swap
- Shifts
- Change in contrast and brightness
- Adding random noise
- Crop
After augmentation, the photos were ironed like this:

Generator code:
def get_datagen(): train_dir='~/data/train_img' test_dir='~/data/test_img' testDataGen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=16, class_mode='categorical') p = Augmentor.Pipeline(train_dir) p.skew(probability=0.9) p.random_distortion(probability=0.9,grid_width=3,grid_height=3,magnitude=8) p.rotate(probability=0.9, max_left_rotation=5, max_right_rotation=5) p.random_color(probability=0.7, min_factor=0.8, max_factor=1) p.flip_left_right(probability=0.7) p.random_brightness(probability=0.7, min_factor=0.8, max_factor=1.2) p.random_contrast(probability=0.5, min_factor=0.9, max_factor=1) p.random_erasing(probability=1,rectangle_area=0.2) p.crop_by_size(probability=1, width=244, height=244, centre=True) train_generator = keras_generator(p,batch_size=16) test_generator = testDataGen.flow_from_directory( test_dir, target_size=img_size, batch_size=32, class_mode='categorical') return (train_generator, test_generator) The code shows that augmentation is not used for test data.
Having a tuned generator it is possible to study the model, we will carry it out in two stages: first, only our classifier will be trained, then the entire model will be completely.
def evalModelstep1(typeModel): K.clear_session() gc.collect() model=createModel(typeModel) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=4, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, ) return model def evalModelstep2(model): early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3) model.layers[0].trainable=True model.trainable=True model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=25, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, callbacks=[early_stopping_callback] ) return model def full_fit(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] for model_name in model_names: print("#########################################") print("#########################################") print("#########################################") print(model_name) print("#########################################") print("#########################################") print("#########################################") model = evalModelstep1(model_name) model = evalModelstep2(model) model.save("~/data/models/model_new_"+str(model_name)+".h5") Call full_fit () and wait. We wait for a long time.
According to the result, we will have six trained models, we will check the accuracy of these models on a separate portion of the marked ones: I received the following:
Model name | Accuracy,% |
Xception | 87.3 |
Resnet | 90.8 |
Inception | 90.2 |
Vgg16 | 89.2 |
Densenet121 | 90.6 |
Mobilenet | 86.5 |
In general, it is not thick, but with such a small training sample one should not expect more. To further improve the accuracy I combined the outputs of the models by averaging:
def create_meta_model(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] model_input = Input(shape=(244,244,3)) submodels=[] i=0; for model_name in model_names: filename= "~/data/models/model_new_"+str(model_name)+".h5" submodel = keras.models.load_model(filename) submodel.name = model_name+"_"+str(i) i+=1 submodels.append(submodel(model_input)) out=average(submodels) model = Model(inputs = model_input,outputs=out) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model The final accuracy was 91.3%. At this result, I decided to stop.
Classifier use
At last the classifier is ready and it can be launched into the business! I prepare the input data and run the classifier - a little more than a day and 1.7 million photos processed. Now the most interesting is the results. Immediately quote the first and last ten cities on the relative number of roads with good coverage:

Full table (clickable image)
But the rating of the quality of roads by regions of the federation:
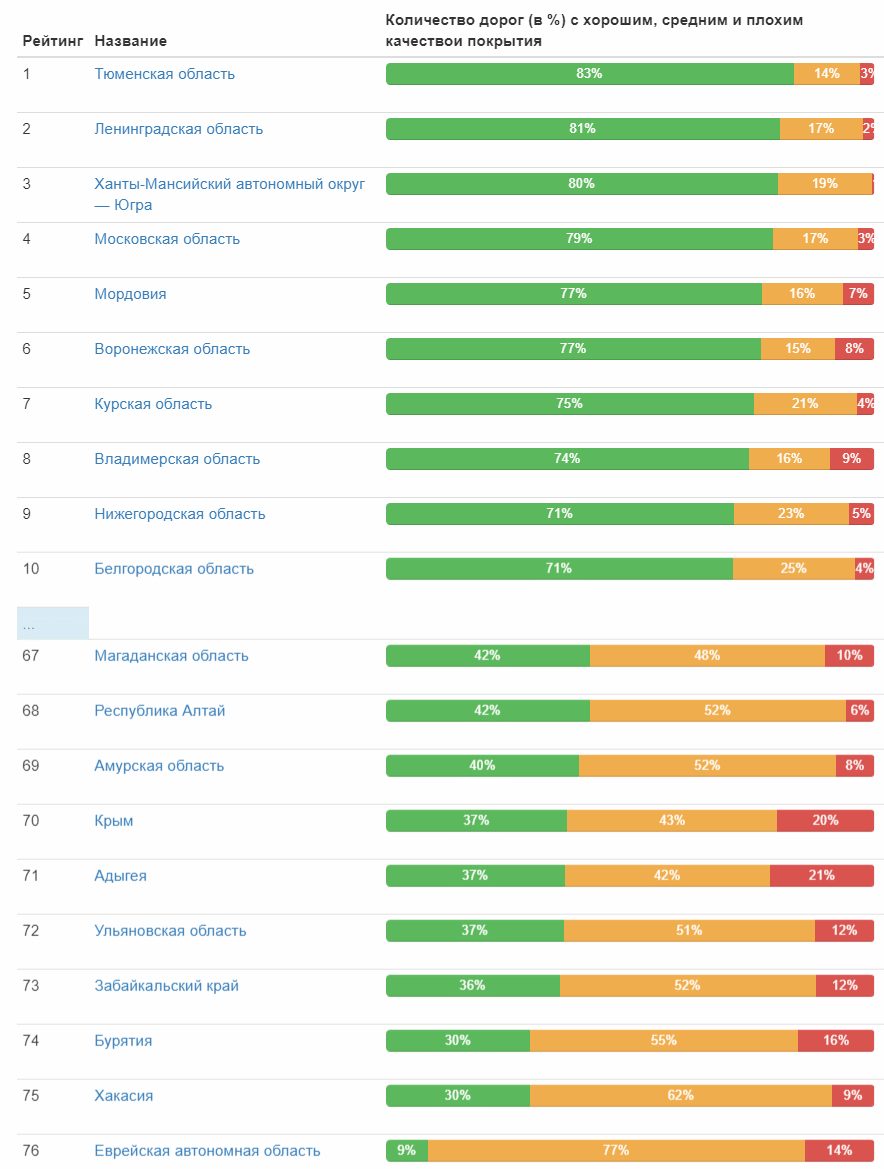
Full table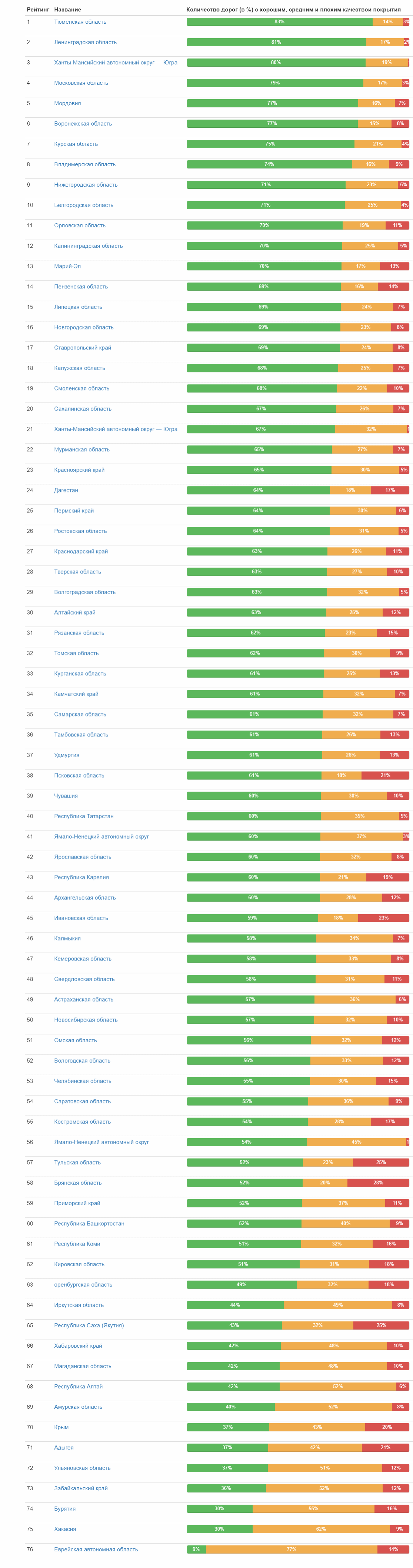
Rating by Federal Districts:
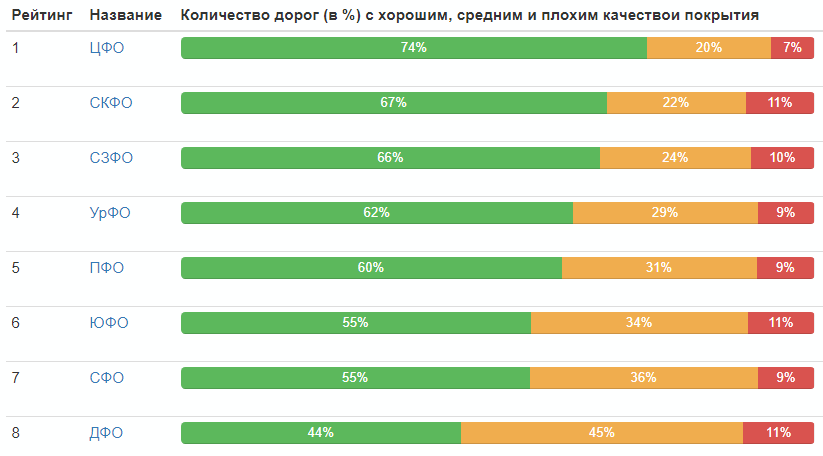
The quality distribution of roads in Russia as a whole:

Well, that's all, everyone can draw conclusions himself.
Finally, I will give the best photos in each category (which received the maximum value in its class):
Picture
PS In the comments quite rightly pointed out the lack of statistics on the years of receiving photographs. Correct and quote the table:
Year | Number of photos, pcs |
| 2008 | 37 |
| 2009 | 13 |
| 2010 | 157030 |
| 2011 | 60724 |
| 2012 | 42387 |
| 2013 | 12148 |
| 2014 | 141021 |
| 2015 | 46143 |
| 2016 | 410385 |
| 2017 | 324279 |
| 2018 | 581961 |
Source: https://habr.com/ru/post/437542/