Methods for recognizing 3D objects for unmanned vehicles. Yandex report
Unmanned cars can not do without understanding what is around and where exactly. In December last year, the developer Victor Othliga vitonka made a report on the detection of 3D objects on the Date-Tree . Viktor works in the direction of unmanned vehicles of Yandex, in the traffic handling group of the situation (and also teaches at the SAD). He explained how we solve the problem of recognizing other road users in a three-dimensional cloud of points, how this task differs from recognizing objects in an image and how to benefit from the joint use of different types of sensors.
- Hello! My name is Viktor otliga, I work in the Yandex office in Minsk, I develop unmanned vehicles. Today I will talk about quite an important task for UAVs - recognizing 3D objects around us.

To drive, you need to understand what is around. I will briefly describe what sensors and sensors are used on unmanned vehicles and which ones we use. I'll tell you what the task of detecting 3D-objects is and how to measure the quality of detection. Then I will tell you what this quality can be measured on. And then I will make a brief overview of good modern algorithms, including those based on the ideas from which our solutions are based. And in the end - small results, a comparison of these algorithms, including ours.

Something like this now looks like our working prototype of an unmanned vehicle. It is such a taxi that can drive anyone who wants it without a driver in the city of Innopolis in Russia, as well as in Skolkovo. And if you look closely, on top of a large die. What is there inside?

Inside a simple set of sensors. There is a GNSS and GSM antenna to determine where the car is and to communicate with the outside world. Where without such a classic sensor like a camera. But today we will be interested in lidars.


Lidar gives approximately such a cloud of points around itself, which have three coordinates. And you have to work with them. I will tell you how, using a camera image and a lidar cloud, recognize some objects.
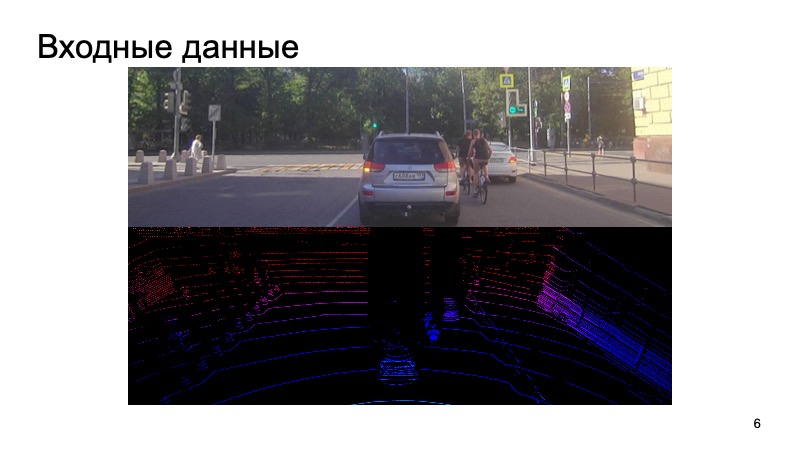
What is the problem? At the entrance comes a picture from the camera, the camera is synchronized with the lidar. It would be strange to use the camera image a second ago, to take a lidar cloud from a completely different moment and try to recognize objects on it.

We somehow synchronize cameras and lidars, this is a separate and not an easy task, but we successfully cope with it. Such data is received at the entrance, and in the end we want to get boxes, bounding boxes, which limit the object: pedestrians, cyclists, cars and other road users and not only.
Task set. How will we evaluate it?

The task of 2D recognition of objects in an image is widely studied.
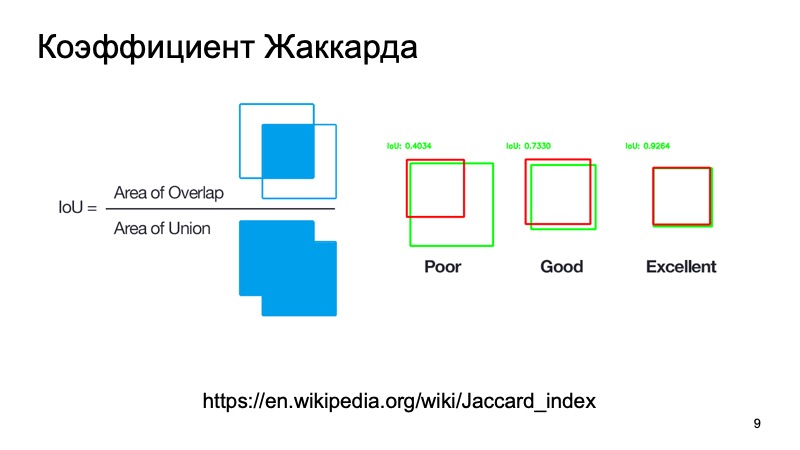
You can use the standard metrics or their analogues. There is a Jacquard coefficient or intersection over union, a remarkable coefficient that shows how well we are a target object. We can take the box, where, as we assume, the object is located, and the box, where it is actually located. Calculate this metric. There are standard thresholds - for example, for cars they often take a threshold of 0.7. If this value is greater than 0.7, we consider that the object was successfully detected, that the object is located there. We are great, we can go further.
In addition, in order to detect the object and understand that it exists somewhere, we would like to consider some kind of confidence that we actually see an object there, and measure it too. It is possible to measure uncomplicatedly, to consider the average accuracy. You can take a precision recall curve and the area under it and say: the bigger it is, the much better.
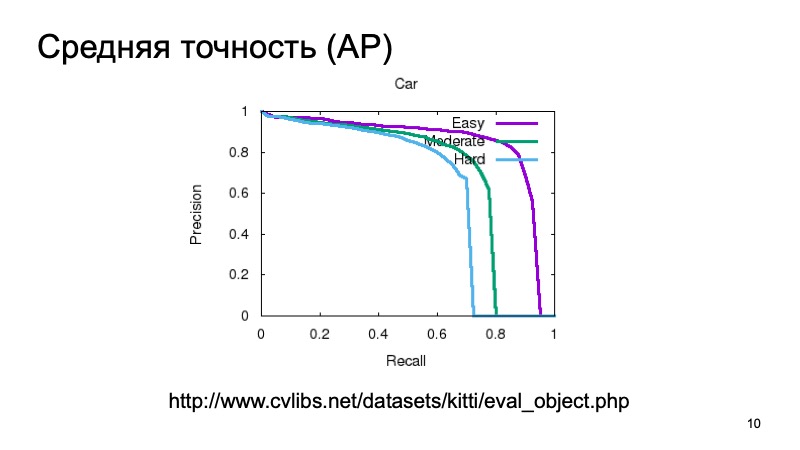
Usually, to measure the quality of 3D-detection, they take a dataset and divide it into several parts, because objects can be close or further, can be partially obscured by something else. Therefore, a validation sample is often divided into three parts. Objects that are easy to detect, of medium complexity and complex, far away or that are heavily obscured. And measure separately on three parts. And in the results of the comparison, we will also take such a partition.
You can measure quality as in 3D, analog of intersection over union, but not the ratio of areas, but, for example, volumes. But an unmanned vehicle, as a rule, is not very important what is happening on the Z coordinate. We can take a top view, the bird's eye view, and consider some kind of metric as if we are looking at it all in 2D. The man navigates more or less in 2D, and the unmanned car as well. How high the box is is not very often important.

What to measure?

Probably, everyone who has somehow come across the task of detecting in 3D on a lidar cloud has heard of such a dataset like KITTI.

In some cities in Germany, a dataset was recorded, a machine equipped with sensors went, she had GPS sensors, cameras and lidars. Then about 8,000 scenes were marked up and divided into two parts. One part is training, in which everyone can train, and the second is validation, in order to measure the results. KITTI validation sampling is considered a measure of quality. Firstly, there is a leaderboard on the KITTI dataset site, you can send your solution there, your results on the validation dataset, and compare it with the decisions of other market players or researchers. But also this dataset is available publicly, you can download it, don’t tell anyone, test your own, compare with competitors, but don’t publicly post it.

External datasets are good, you do not need to spend your time and resources on them, but as a rule, a car that went in Germany can be equipped with completely different sensors. And it is always good to have your own internal dataset. Moreover, the external data expansion at the expense of others is harder, and its simpler, you can manage this process. Therefore, we use the excellent Yandex.Toloka service.

We have finalized our special task system. To the user who wants to help in the markup and get a reward for it, we issue a picture from the camera, issue a lidar cloud that can be rotated, zoom in, move away, and ask him to put boxes that limit our space bounding boxes to get a car or a pedestrian , or something different. Thus, we collect the inner sample for personal use.
Suppose we have decided what task we will solve, how we will assume that we did it well or badly. Took somewhere data.
What are the algorithms? Let's start with 2D. The 2D detection task is very well known and studied.
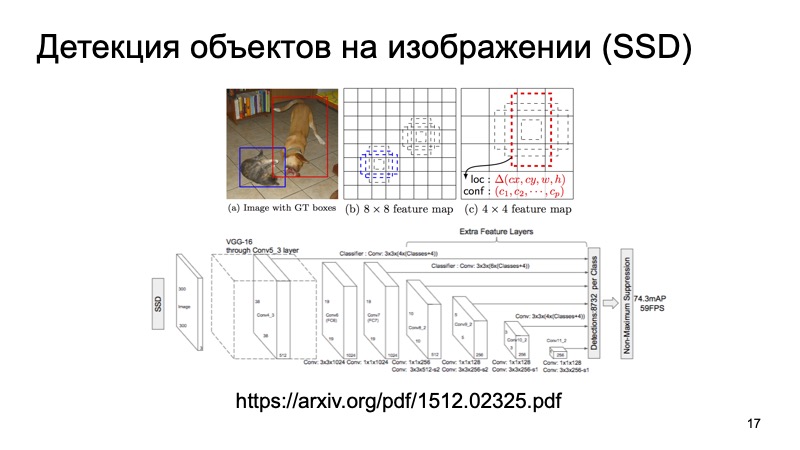
Surely, many people know about the SSD algorithm, which is one of the state of the art methods for detecting 2D objects, and in principle it can be considered that, in some way, the problem of detecting objects in an image has been solved quite well. If anything, we can use these results as some additional information.
But our lidar cloud has its own features, which greatly distinguish it from the image. First, it is very rarefied. If the picture is a dense structure, the pixels are near, everything is dense, then the cloud is very sparse, there are not so many points there, and it does not have a regular structure. Purely physically, there are much more points near there than in the distance, and the farther away, the fewer the points, the less accuracy, the harder it is to determine something.
Well, the points in principle come from the cloud in an incomprehensible order. No one guarantees that one point will always be before another. They come in a relatively random order. You can somehow agree to sort or reorder them in advance, and only then submit them to the model input, but this will be quite inconvenient, you need to spend time changing them, and so on.
We would like to come up with a system that is invariant to our problems, will solve all these problems. Fortunately, the CVPR last year presented such a system. There was such an architecture - PointNet. How does she work?

At the entrance comes a cloud, n points, each has three coordinates. Then each point is somehow standardized by a special small transform. Further it runs through a fully connected network in order to enrich these points with signs. Then the transformation occurs again, and at the end it is additionally enriched. At some point, n points are obtained, but each has approximately 1024 signs, they are somehow standardized. But so far we have not solved the problem regarding the invariance of shifts, turns, and so on. Here it is proposed to make max-pooling, take a maximum among the points for each channel and get some vector of 1024 signs, which will be a certain descriptor of our cloud, which will contain information about the whole cloud. And then with this handle, you can do a lot of different things.
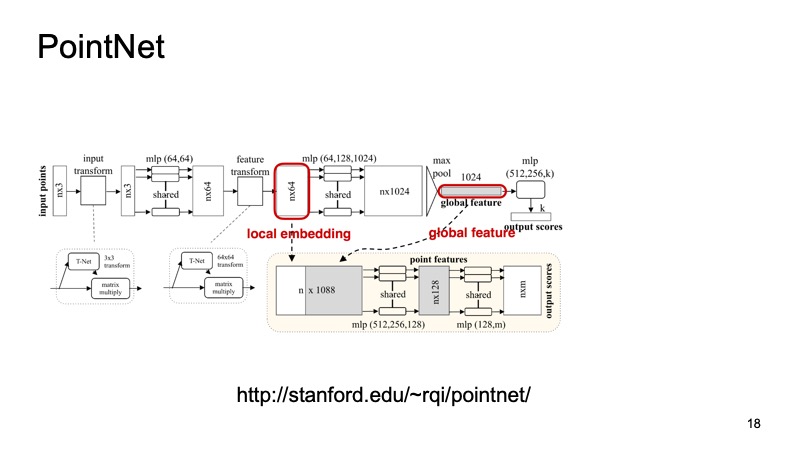
For example, you can glue it to descriptors of individual points and solve the segmentation problem, for each point, determine which object it belongs to. It is just a road or a man or a car. And here are the results from the article.

You may notice that this algorithm works very well. In particular, I really like the table in which part of the data on the tabletop was thrown out, and he, nevertheless, determined where the legs were and where the tabletop was. And this algorithm, in particular, can be used as a brick for building further systems.
One approach that uses this is the Frustum PointNets approach or the truncated pyramid approach. The idea is something like this: let's recognize objects in 2D, we can do this well.
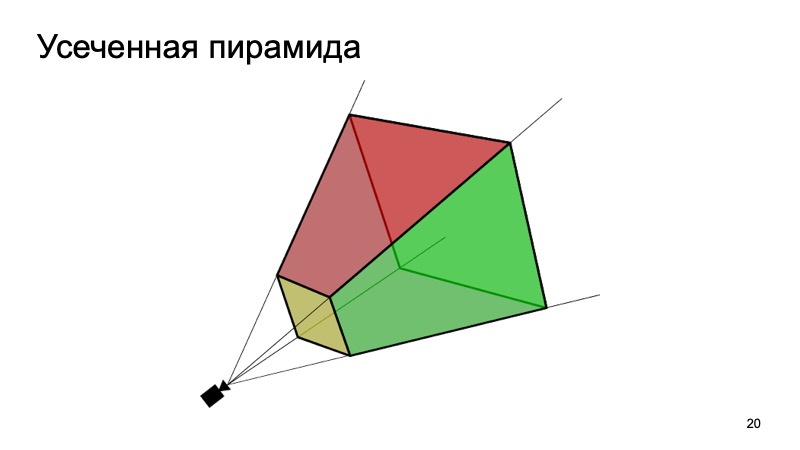
Then, knowing how the camera works, we can figure out in which area the object of interest to us, the machine, can lie. To project, cut only this area, and on it solve the problem of finding an interesting object, for example, a car. It is much easier than to look for any number of cars around the cloud. Looking for one car in exactly one cloud seems to be much clearer and more efficient.
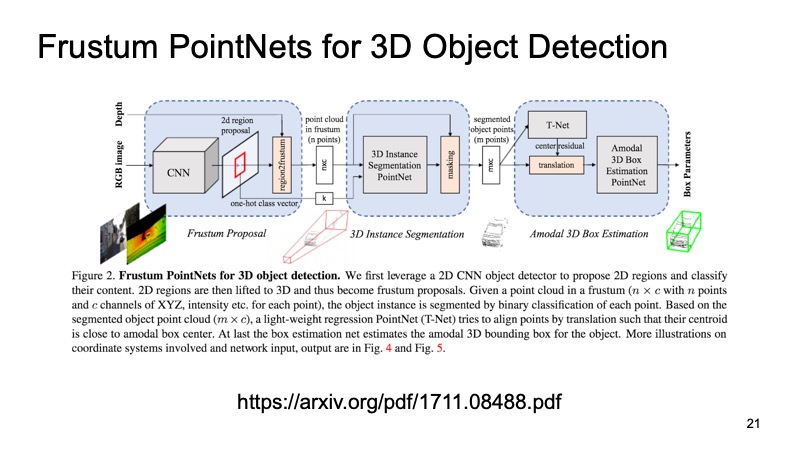
The architecture looks like this. First, we somehow single out the regions that interest us, do segmentation in each region, and then solve the problem of finding the bounding box, which limits the object that interests us.

The approach has proven itself. In the pictures you can see that it works well enough, but there are drawbacks in it. The approach is two-level, because of this, it can be slow. We need to first apply the network and recognize 2D-objects, then cut, and then solve the problem of segmentation and selection of a bounding box on a piece of cloud, so it can work a little slow.
Another approach. Why don't we turn our cloud into some kind of structure similar to the picture? The idea is this: let's look at the top and sample our lidar cloud. We get the cubes of spaces.
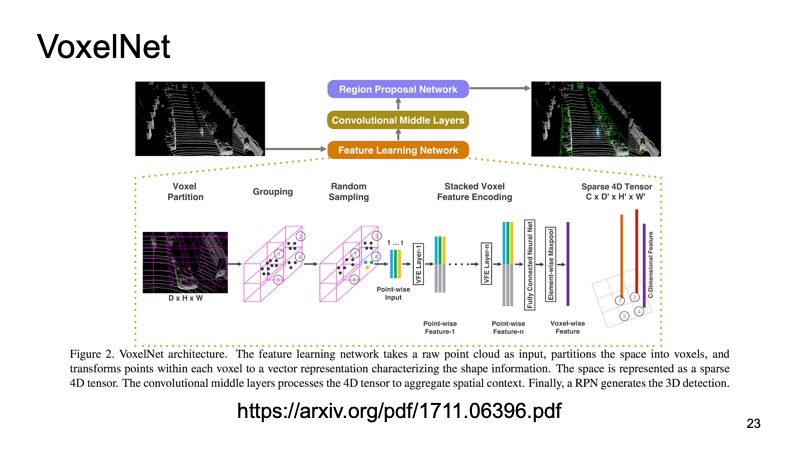
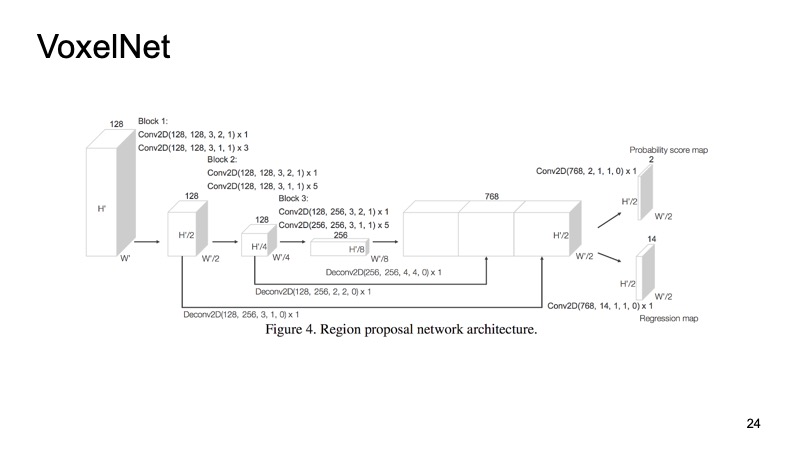
Inside each cube we got some points. We can count some features on them, but we can use PointNet, which for each piece of space will be counted by some kind of descriptor. We will have a voxel, each voxel has a characteristic description, and it will be more or less similar to a dense structure, like in the picture. We can already do different architectures, for example, SSD-like architecture for object detection.
The latter approach, which was one of the very first approaches to combining data from several sensors. It would be a sin to use only lidar data when we also have data from cameras. One of these approaches is called the Multi-View 3D Object Detection Network. His idea is as follows: let's feed three channels of input data to the input of a large network.
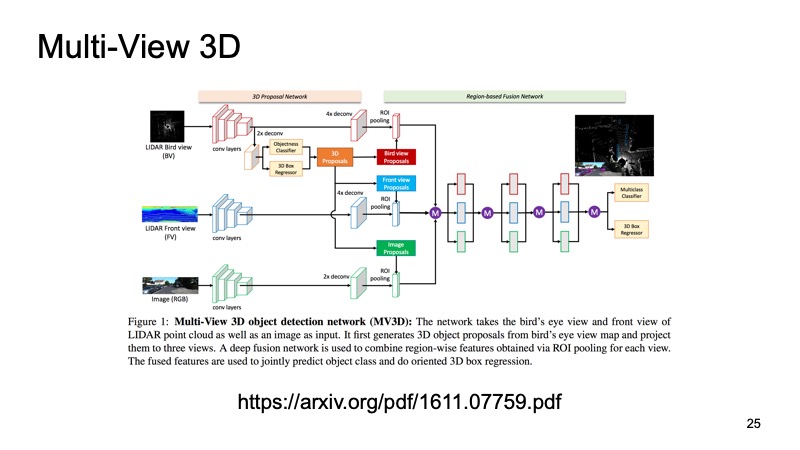
This is a picture from the camera and, in two versions, a lidar cloud: from above, with a bird's-eye view, and some kind of front view, what we see in front of us. We give this to the input of the neuron, and it configures everything inside itself, it will give us the final result - the object.
I want to compare these models. On KITTI dataset, on validation passages, quality is estimated as percentages on average precision.
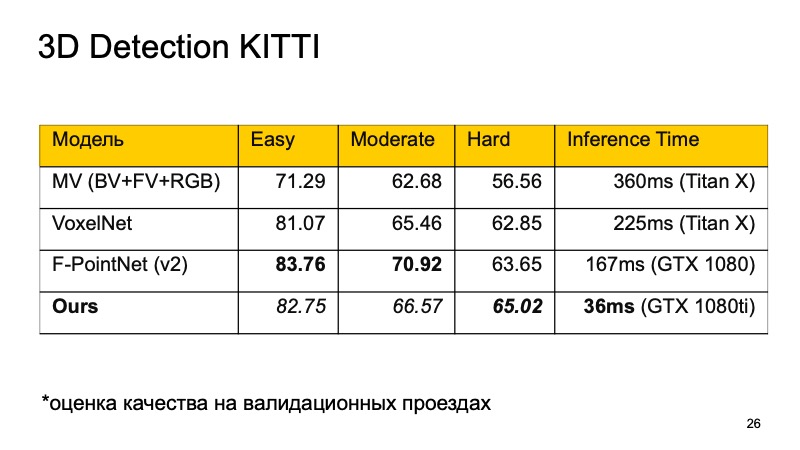
It can be noted that F-PointNet works quite well and quickly enough, wins all the rest in different areas - at least according to the authors.
Our approach is based on more or less all the ideas that I have listed. If to compare, the following picture turns out approximately. If we do not occupy the first place, then at least the second. And on those objects that are difficult to detect, we break out into the lead. And most importantly, our approach works quickly enough. This means that it is already quite well applicable for real-time systems, but an unmanned vehicle is especially important to monitor what is happening on the road and select all these objects.

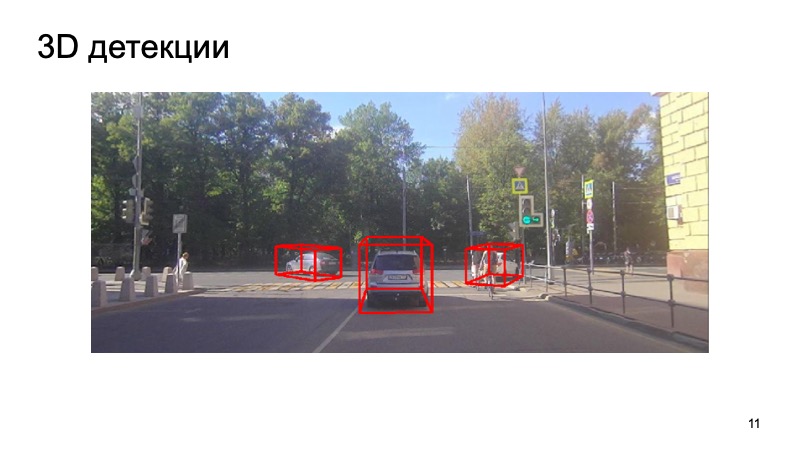
At the end - an example of the work of our detector:
It can be seen that the situation is complex: some of the objects are closed, some are not visible to the camera. Pedestrians, cyclists. But the detector copes quite well. Thank!
- Hello! My name is Viktor otliga, I work in the Yandex office in Minsk, I develop unmanned vehicles. Today I will talk about quite an important task for UAVs - recognizing 3D objects around us.
To drive, you need to understand what is around. I will briefly describe what sensors and sensors are used on unmanned vehicles and which ones we use. I'll tell you what the task of detecting 3D-objects is and how to measure the quality of detection. Then I will tell you what this quality can be measured on. And then I will make a brief overview of good modern algorithms, including those based on the ideas from which our solutions are based. And in the end - small results, a comparison of these algorithms, including ours.
Something like this now looks like our working prototype of an unmanned vehicle. It is such a taxi that can drive anyone who wants it without a driver in the city of Innopolis in Russia, as well as in Skolkovo. And if you look closely, on top of a large die. What is there inside?
Inside a simple set of sensors. There is a GNSS and GSM antenna to determine where the car is and to communicate with the outside world. Where without such a classic sensor like a camera. But today we will be interested in lidars.
Lidar gives approximately such a cloud of points around itself, which have three coordinates. And you have to work with them. I will tell you how, using a camera image and a lidar cloud, recognize some objects.
What is the problem? At the entrance comes a picture from the camera, the camera is synchronized with the lidar. It would be strange to use the camera image a second ago, to take a lidar cloud from a completely different moment and try to recognize objects on it.
We somehow synchronize cameras and lidars, this is a separate and not an easy task, but we successfully cope with it. Such data is received at the entrance, and in the end we want to get boxes, bounding boxes, which limit the object: pedestrians, cyclists, cars and other road users and not only.
Task set. How will we evaluate it?
The task of 2D recognition of objects in an image is widely studied.
Link from the slide
You can use the standard metrics or their analogues. There is a Jacquard coefficient or intersection over union, a remarkable coefficient that shows how well we are a target object. We can take the box, where, as we assume, the object is located, and the box, where it is actually located. Calculate this metric. There are standard thresholds - for example, for cars they often take a threshold of 0.7. If this value is greater than 0.7, we consider that the object was successfully detected, that the object is located there. We are great, we can go further.
In addition, in order to detect the object and understand that it exists somewhere, we would like to consider some kind of confidence that we actually see an object there, and measure it too. It is possible to measure uncomplicatedly, to consider the average accuracy. You can take a precision recall curve and the area under it and say: the bigger it is, the much better.
Link from the slide
Usually, to measure the quality of 3D-detection, they take a dataset and divide it into several parts, because objects can be close or further, can be partially obscured by something else. Therefore, a validation sample is often divided into three parts. Objects that are easy to detect, of medium complexity and complex, far away or that are heavily obscured. And measure separately on three parts. And in the results of the comparison, we will also take such a partition.
You can measure quality as in 3D, analog of intersection over union, but not the ratio of areas, but, for example, volumes. But an unmanned vehicle, as a rule, is not very important what is happening on the Z coordinate. We can take a top view, the bird's eye view, and consider some kind of metric as if we are looking at it all in 2D. The man navigates more or less in 2D, and the unmanned car as well. How high the box is is not very often important.
What to measure?
Probably, everyone who has somehow come across the task of detecting in 3D on a lidar cloud has heard of such a dataset like KITTI.
Link from the slide
In some cities in Germany, a dataset was recorded, a machine equipped with sensors went, she had GPS sensors, cameras and lidars. Then about 8,000 scenes were marked up and divided into two parts. One part is training, in which everyone can train, and the second is validation, in order to measure the results. KITTI validation sampling is considered a measure of quality. Firstly, there is a leaderboard on the KITTI dataset site, you can send your solution there, your results on the validation dataset, and compare it with the decisions of other market players or researchers. But also this dataset is available publicly, you can download it, don’t tell anyone, test your own, compare with competitors, but don’t publicly post it.
External datasets are good, you do not need to spend your time and resources on them, but as a rule, a car that went in Germany can be equipped with completely different sensors. And it is always good to have your own internal dataset. Moreover, the external data expansion at the expense of others is harder, and its simpler, you can manage this process. Therefore, we use the excellent Yandex.Toloka service.
We have finalized our special task system. To the user who wants to help in the markup and get a reward for it, we issue a picture from the camera, issue a lidar cloud that can be rotated, zoom in, move away, and ask him to put boxes that limit our space bounding boxes to get a car or a pedestrian , or something different. Thus, we collect the inner sample for personal use.
Suppose we have decided what task we will solve, how we will assume that we did it well or badly. Took somewhere data.
What are the algorithms? Let's start with 2D. The 2D detection task is very well known and studied.
Link from the slide
Surely, many people know about the SSD algorithm, which is one of the state of the art methods for detecting 2D objects, and in principle it can be considered that, in some way, the problem of detecting objects in an image has been solved quite well. If anything, we can use these results as some additional information.
But our lidar cloud has its own features, which greatly distinguish it from the image. First, it is very rarefied. If the picture is a dense structure, the pixels are near, everything is dense, then the cloud is very sparse, there are not so many points there, and it does not have a regular structure. Purely physically, there are much more points near there than in the distance, and the farther away, the fewer the points, the less accuracy, the harder it is to determine something.
Well, the points in principle come from the cloud in an incomprehensible order. No one guarantees that one point will always be before another. They come in a relatively random order. You can somehow agree to sort or reorder them in advance, and only then submit them to the model input, but this will be quite inconvenient, you need to spend time changing them, and so on.
We would like to come up with a system that is invariant to our problems, will solve all these problems. Fortunately, the CVPR last year presented such a system. There was such an architecture - PointNet. How does she work?
At the entrance comes a cloud, n points, each has three coordinates. Then each point is somehow standardized by a special small transform. Further it runs through a fully connected network in order to enrich these points with signs. Then the transformation occurs again, and at the end it is additionally enriched. At some point, n points are obtained, but each has approximately 1024 signs, they are somehow standardized. But so far we have not solved the problem regarding the invariance of shifts, turns, and so on. Here it is proposed to make max-pooling, take a maximum among the points for each channel and get some vector of 1024 signs, which will be a certain descriptor of our cloud, which will contain information about the whole cloud. And then with this handle, you can do a lot of different things.
Link from the slide
For example, you can glue it to descriptors of individual points and solve the segmentation problem, for each point, determine which object it belongs to. It is just a road or a man or a car. And here are the results from the article.
Link from the slide
You may notice that this algorithm works very well. In particular, I really like the table in which part of the data on the tabletop was thrown out, and he, nevertheless, determined where the legs were and where the tabletop was. And this algorithm, in particular, can be used as a brick for building further systems.
One approach that uses this is the Frustum PointNets approach or the truncated pyramid approach. The idea is something like this: let's recognize objects in 2D, we can do this well.
Then, knowing how the camera works, we can figure out in which area the object of interest to us, the machine, can lie. To project, cut only this area, and on it solve the problem of finding an interesting object, for example, a car. It is much easier than to look for any number of cars around the cloud. Looking for one car in exactly one cloud seems to be much clearer and more efficient.
Link from the slide
The architecture looks like this. First, we somehow single out the regions that interest us, do segmentation in each region, and then solve the problem of finding the bounding box, which limits the object that interests us.
The approach has proven itself. In the pictures you can see that it works well enough, but there are drawbacks in it. The approach is two-level, because of this, it can be slow. We need to first apply the network and recognize 2D-objects, then cut, and then solve the problem of segmentation and selection of a bounding box on a piece of cloud, so it can work a little slow.
Another approach. Why don't we turn our cloud into some kind of structure similar to the picture? The idea is this: let's look at the top and sample our lidar cloud. We get the cubes of spaces.
Link from the slide
Inside each cube we got some points. We can count some features on them, but we can use PointNet, which for each piece of space will be counted by some kind of descriptor. We will have a voxel, each voxel has a characteristic description, and it will be more or less similar to a dense structure, like in the picture. We can already do different architectures, for example, SSD-like architecture for object detection.
The latter approach, which was one of the very first approaches to combining data from several sensors. It would be a sin to use only lidar data when we also have data from cameras. One of these approaches is called the Multi-View 3D Object Detection Network. His idea is as follows: let's feed three channels of input data to the input of a large network.
Link from the slide
This is a picture from the camera and, in two versions, a lidar cloud: from above, with a bird's-eye view, and some kind of front view, what we see in front of us. We give this to the input of the neuron, and it configures everything inside itself, it will give us the final result - the object.
I want to compare these models. On KITTI dataset, on validation passages, quality is estimated as percentages on average precision.
It can be noted that F-PointNet works quite well and quickly enough, wins all the rest in different areas - at least according to the authors.
Our approach is based on more or less all the ideas that I have listed. If to compare, the following picture turns out approximately. If we do not occupy the first place, then at least the second. And on those objects that are difficult to detect, we break out into the lead. And most importantly, our approach works quickly enough. This means that it is already quite well applicable for real-time systems, but an unmanned vehicle is especially important to monitor what is happening on the road and select all these objects.
At the end - an example of the work of our detector:
It can be seen that the situation is complex: some of the objects are closed, some are not visible to the camera. Pedestrians, cyclists. But the detector copes quite well. Thank!
Source: https://habr.com/ru/post/437674/