MPLS is everywhere. How is the network infrastructure of Yandex.Oblaka
Post prepared: Alexander Virilin xscrew - author, head of network infrastructure services, Leonid Klyuev - editor
 We continue to acquaint you with the internal device Yandeks.Oblaka . Today we will talk about networks - let's tell you how the network infrastructure is arranged, why it uses the MPLS paradigm unpopular for data centers, what other complex decisions we had to make in the process of building a cloud network, how we manage it and what monitoring we use.
We continue to acquaint you with the internal device Yandeks.Oblaka . Today we will talk about networks - let's tell you how the network infrastructure is arranged, why it uses the MPLS paradigm unpopular for data centers, what other complex decisions we had to make in the process of building a cloud network, how we manage it and what monitoring we use.The network in the Cloud consists of three layers. The bottom layer is the already mentioned infrastructure. This is a physical "iron" network inside data centers, between data centers and in places of connection to external networks. A virtual network is built on top of the network infrastructure, and network services are built on top of the virtual network. This structure is not monolithic: the layers overlap, the virtual network and network services directly interact with the network infrastructure. Since the virtual network is often called overlay, we usually call the network infrastructure underlay.

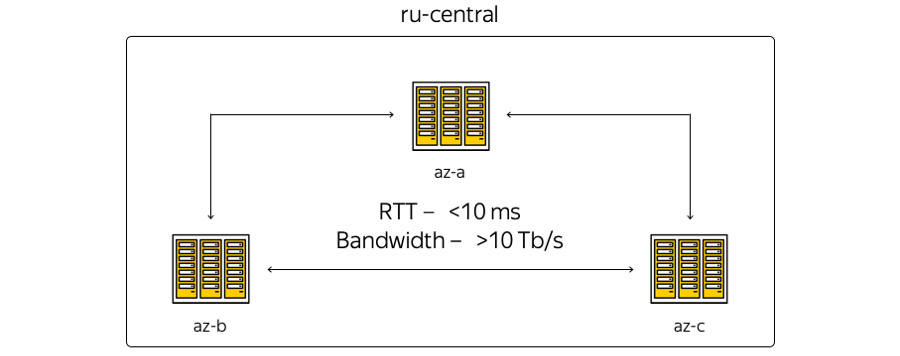
Now the Cloud infrastructure is based in the Central region of Russia and includes three accessibility zones - that is, three geographically distributed independent data centers. Independent - independent of each other in the context of networks, engineering and electrical systems, etc.
About the characteristics. The geography of the location of data centers is such that round-trip time (RTT) is always 6–7 ms. The total capacity of the channels has already exceeded 10 terabits and is constantly growing, because Yandex has its own fiber-optic network between the zones. Since we are not renting communication channels, we can quickly increase the capacity of the strip between the DCs: each of them uses spectral compaction equipment.
Here is the most schematic representation of the zones:
The reality, in turn, is slightly different:
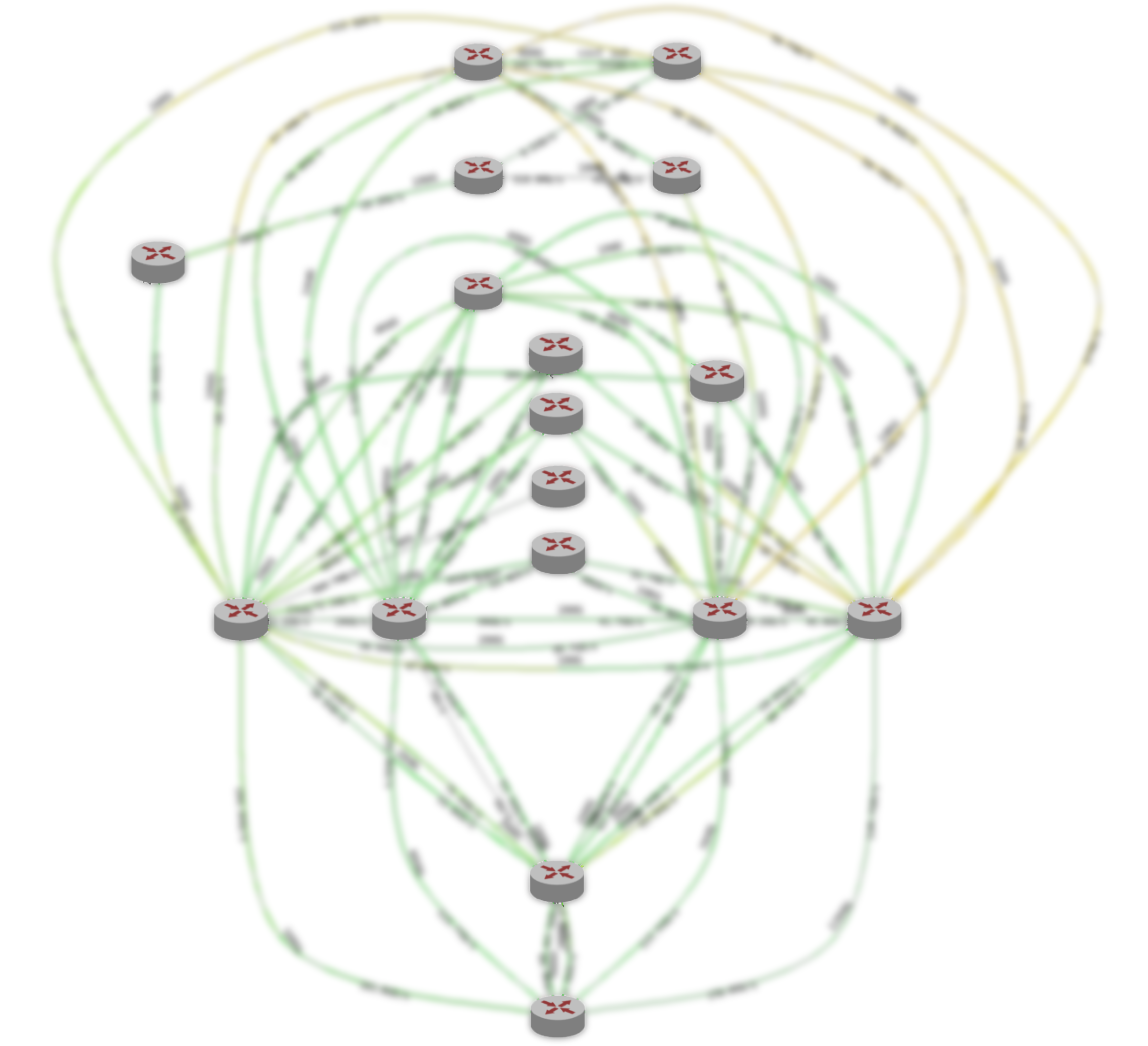
This shows the current core network of Yandex in the region. All Yandex services work on top of it, part of the network is used by the Cloud. (This is a picture for internal use, so the service information is deliberately hidden. Nevertheless, you can estimate the number of nodes and connections.) The decision to use the backbone network was logical: we could not invent anything, but re-use the current infrastructure - the “gained” over the years.
What is the difference between the first picture and the second? First of all, the access zones are not directly interconnected: technical sites are located between them. Sites do not contain server hardware - they are only network devices to ensure connectivity. The points of presence are connected to the technical platforms, where Yandex and Clouds dock with the outside world. All points of presence work for the entire region. By the way, it is important to note that in terms of external access from the Internet, all access zones of the Cloud are equivalent. In other words, they provide the same connectivity — that is, the same speed and throughput, as well as equally low delays.
In addition, at the points of presence there is equipment to which - if there are on-premise-resources and a desire to expand the local infrastructure with cloud capacity - clients can connect via a guaranteed channel. This can be done with the help of partners or independently.
The core network is used by the Cloud as an MPLS transport.
MPLS
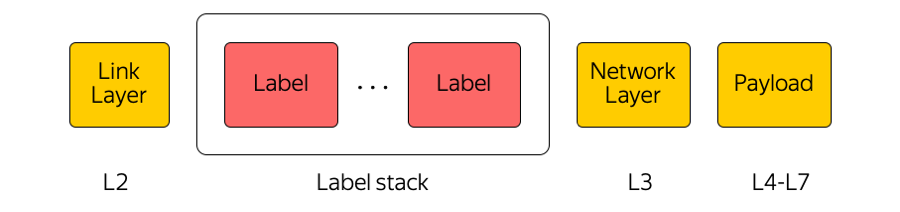
Multi protocol label switching (multi-protocol label switching) is an extremely widely used technology in our industry. For example, when a package is transmitted between accessibility zones or between the accessibility zone and the Internet, the transit equipment only draws attention to the top tag, “not thinking” about what is under it. Thus, MPLS allows you to hide the complexity of the Cloud from the transport layer. In general, we in the Cloud love MPLS very much. We even made it a part of the lower level and use it directly at the switching factory in the data center:

(In fact, between Leaf-switches and Spines a huge number of parallel links.)
Why MPLS?
MPLS is really not often found in the networks of data centers. Often used completely different technology.
We use MPLS for several reasons. First, we found it convenient to unify the control plane and data plane. That is, instead of some protocols in the network of the data center, other protocols in the core network and the junction points of these protocols - single MPLS. Thus, we have unified the technological stack and reduced the complexity of the network.
Secondly, we use various network appliances in the Cloud, such as Cloud Gateway and Network Load Balancer. They need to communicate with each other, send traffic to the Internet and vice versa. These network appliances can scale horizontally as the load grows, and since the Cloud is built on the hyperconvergence model, they can be launched in absolutely any place from the point of view of the network in the data center, that is, in the general pool of resources.
Thus, these appliances can be launched behind any port of the rack switch where the server is located, and begin to communicate via MPLS with the rest of the infrastructure. The only problem in building such an architecture was the alarm.
Signaling
The classic MPLS protocol stack is quite complex. This, by the way, is one of the reasons for the non-proliferation of MPLS in data center networks.
We, in turn, did not use either the IGP (Interior Gateway Protocol), or the LDP (Label Distribution Protocol), or other label distribution protocols. Only BGP (Border Gateway Protocol) Label-Unicast is used. Each appliance that runs, for example, in the form of a virtual machine, builds a BGP session to a rack-mount Leaf switch.
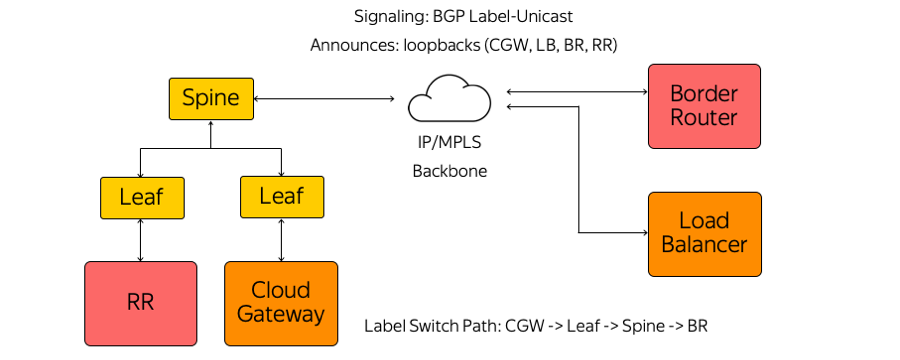
BGP session is based on a previously known address. There is no need to automatically configure the switch to run each appliance. All switches are configured in advance and uniformly.
During a BGP session, each appliance sends its loopback and receives loopbacks from the rest of the devices with which it will need to exchange traffic. Examples of such devices are several types of route reflectors, border routers, and other appliances. As a result, information appears on the devices on how they reach each other. From Cloud Gateway through Leaf-switch, Spine-switch and network to the border router is built Label Switch Path. Switches are L3 switches that behave like a Label Switch Router and do not know about the complexity surrounding them.
MPLS at all levels of our network, among other things, allowed us to use the concept of Eat your own dogfood.
Eat your own dogfood
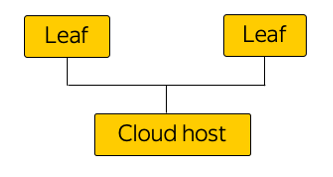
From the point of view of the network, this concept implies that we live in the same infrastructure that we provide to the user. Here are schematically depicted racks in areas of accessibility:

Cloud host takes over the load from the user, contains his virtual machines. And literally a neighboring host in a rack can carry the load from the infrastructure point of view of the network, which includes route reflectors, a management server, monitoring, etc.
What was it done for? There was a temptation to run route reflectors and all infrastructure elements in a separate failover segment. Then, if the user segment had broken somewhere in the data center, the infrastructure servers would continue to manage the entire network infrastructure. But such an approach seemed to us vicious - if we do not trust our own infrastructure, how can we provide it to our customers? After all, absolutely everything Cloud works on top of it, all virtual networks, user and cloud services.
Therefore, we abandoned a separate segment. Our infrastructure elements run in the same network topology and with the same network connectivity. Naturally, they run in a triple instance - just as our clients launch their services in the Cloud.
IP / MPLS factory
Here is an example of one of the access zones:
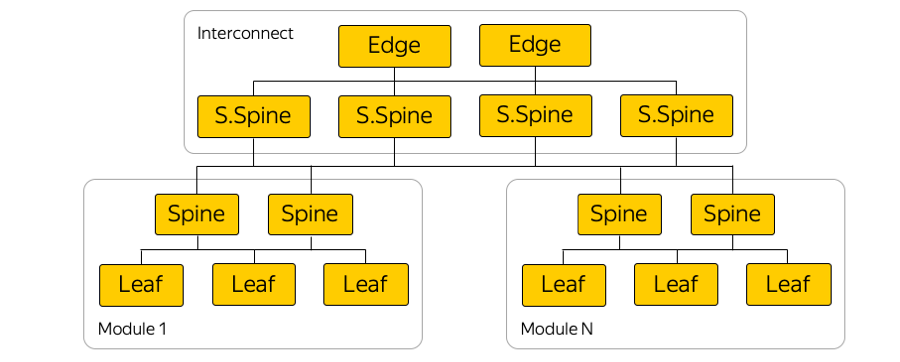
There are about five modules in each access area, and about a hundred racks in each module. Leaf - rack-mount switches, they are connected within their module by the Spine level, and inter-module connectivity is provided via network Interconnect. This is the next level, which includes the so-called Super-Spines and Edge-switches, which already connect accessibility zones. We deliberately refused to L2, we are talking only about L3 IP / MPLS-connectivity. BGP is used to distribute routing information.
In fact, parallel connections are much more than in the picture. Such a large number of ECMP connections (Equal-сost multi-path) imposes special monitoring requirements. In addition, there appear unexpected, at first glance, limits in equipment — for example, the number of ECMP groups.
Connecting servers
Yandex, at the expense of powerful investments, builds services in such a way that the failure of one server, server rack, module or even the whole data center never leads to a complete stop of the service. If we have any network problems - suppose the rack switch is broken, external users never see it.
Yandex.Oblako - a special case. We cannot dictate to the client how to build his own services, and decided to level this possible single point of failure. Therefore, all servers in the Cloud are connected to two rack switches.
In the same way, we do not use any redundancy protocols at the L2 level, but immediately started using only L3 with BGP - again, for reasons of protocol unification. This connection provides each service with IPv4 and IPv6 connectivity: some services work on IPv4, and some work on IPv6.
Physically, each server is connected by two 25-gigabit interfaces. Here is a photo from the data center:

Here you see two rack-mount switches with 100-gigabit ports. One can see diverging breakout cables dividing the 100-gigabit port of the switch into 4 ports of 25 gigabits per server. We call these cables "hydra."
Infrastructure Management
Cloud Network Infrastructure does not contain any proprietary management solutions: all systems or open source with customization for the Cloud, or completely self-written.
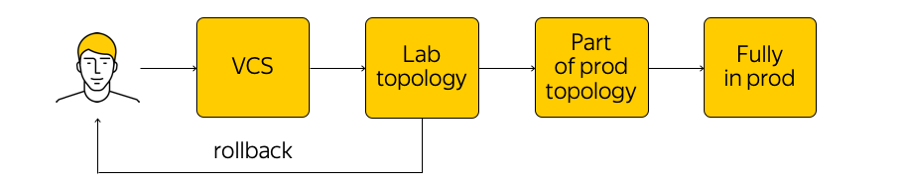
How is this infrastructure managed? In the Cloud, it is not that forbidden, but it is highly discouraged to go to the network device and make some adjustments. There is a current state of the system, and we need to apply changes: to come to some new, target state. "Run through the script" for all the glands, to change something in the configuration - this is not worth doing. Instead, we make changes to the templates, to a single source of truth system and commit our change to the version control system. This is very convenient, because you can always make a rollback, see the history, find out who is responsible for the commit, etc.
When we made changes, configs are generated and we roll them out to the lab test topology. From the point of view of the network, this is a small cloud that completely repeats all existing production. We will immediately see if the desired changes break something: firstly, by monitoring, and secondly, by feedback from our internal users.
If the monitoring says that everything is calm, then we continue rolling out - but applying the change only to a part of the topology (two or more accessibility "have no right" to break for the same reason). In addition, we continue to closely monitor the monitoring. This is a rather complicated process, which we will discuss below.
Making sure that everything is fine, we apply the change to the entire production. At any time, you can roll back and return to the previous state of the network, quickly track and fix the problem.
Monitoring
We need different monitoring. One of the most popular is monitoring end-to-end connectivity. At any time, each server should be able to communicate with any other server. The fact is that if somewhere there is a problem, then we want to find out as soon as possible exactly where (that is, which servers have problems accessing each other). End-to-end-connectivity is our primary concern.
Each server lists a set of all servers with which it should be able to communicate at any time. The server takes a random subset of this set and sends ICMP, TCP, and UDP packets to all selected machines. This verifies whether there is a loss on the network, whether the delay has increased, and so on. The entire network is paged within one of the accessibility zones and between them. The results are sent to a centralized system that visualizes them for us.
Here are the results when everything is not very good:
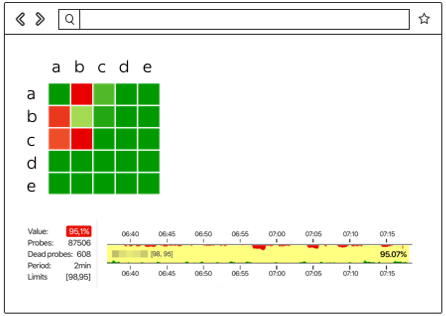
Here you can see between which network segments there is a problem (in this case, A and B) and where everything is fine (A and D). It can display specific servers, rack switches, modules, and entire availability zones. If any of the above becomes a source of the problem, we will see it in real time.
In addition, there is event monitoring. We closely monitor all connections, signal levels on transceivers, BGP sessions, etc. Suppose that three BGP sessions are being built from a certain network segment, one of which was interrupted at night. If we set up monitoring so that the fall of one BGP session is not critical for us and can wait until the morning, then monitoring does not wake network engineers. But if the second of three sessions falls, an automatic call to the engineer occurs.
In addition to End-to-End- and event-based monitoring, we use centralized log collection, their real-time analysis and subsequent analysis. You can look at the correlations, identify problems and find out what happened on the network equipment.
The topic of monitoring is quite large, there is a lot of room for improvement. I want to bring the system to greater automation and true self-healing.
What's next?
We have a lot of plans. It is necessary to improve management systems, monitoring, switching IP / MPLS-factory and much more.
We are also actively looking towards white box-switches. This is a ready-made "iron" device, a switch, on which you can roll your software. First, if everything is done correctly, it will be possible to “treat” switches as well as servers, build a truly convenient CI / CD process, incrementally roll out configs, and so on.
Secondly, if there are any problems, it is better to keep a group of engineers and developers who will fix these problems than to wait for a long time for the fix from the vendor.
To make it work, work is being done in two directions:
- We have significantly reduced the complexity of the IP / MPLS factory. On the one hand, the level of the virtual network and automation tools from this, on the contrary, became a bit more complicated. On the other hand, the underlay network itself has become easier. In other words, there is a certain “amount” of complexity that cannot be put anywhere. It can be “swapped” from one level to another - for example, between network levels or from network level to application level. And you can correctly distribute this complexity, which we are trying to do.
- And of course, we are finalizing our set of tools for managing the entire infrastructure.
That's all we wanted to talk about our network infrastructure. Here is a link to the Cloud Telegram channel with news and tips.
Source: https://habr.com/ru/post/437816/