How we migrated the database from Redis and Riak KV to PostgreSQL. Part 1: the process
This is the first part of the article, in which I will talk about how we built the process of working on a large database migration project: about safe experiments, team planning and cross-team interaction. In the following articles I will talk in more detail about the technical problems that we solved: scaling and fault tolerance of PostgreSQL and load testing.
For a long time, the main database in RealtimeBoard was Redis. We stored in it all the basic information: data about users, accounts, boards, etc. Everything worked quickly, but we faced a number of problems.
Problems with redis
These problems, along with the increasing amount of data on the servers, caused the database to be migrated.
The decision on migration is made. The next step is to understand which of the databases is suitable for our data model.
We conducted a study to select the optimal database for us, and stopped at PostgreSQL. Our data model fits well with a relational database: PostgreSQL has built-in tools for data consistency, JSONB type, and the ability to index certain fields in JSONB. It suits us.
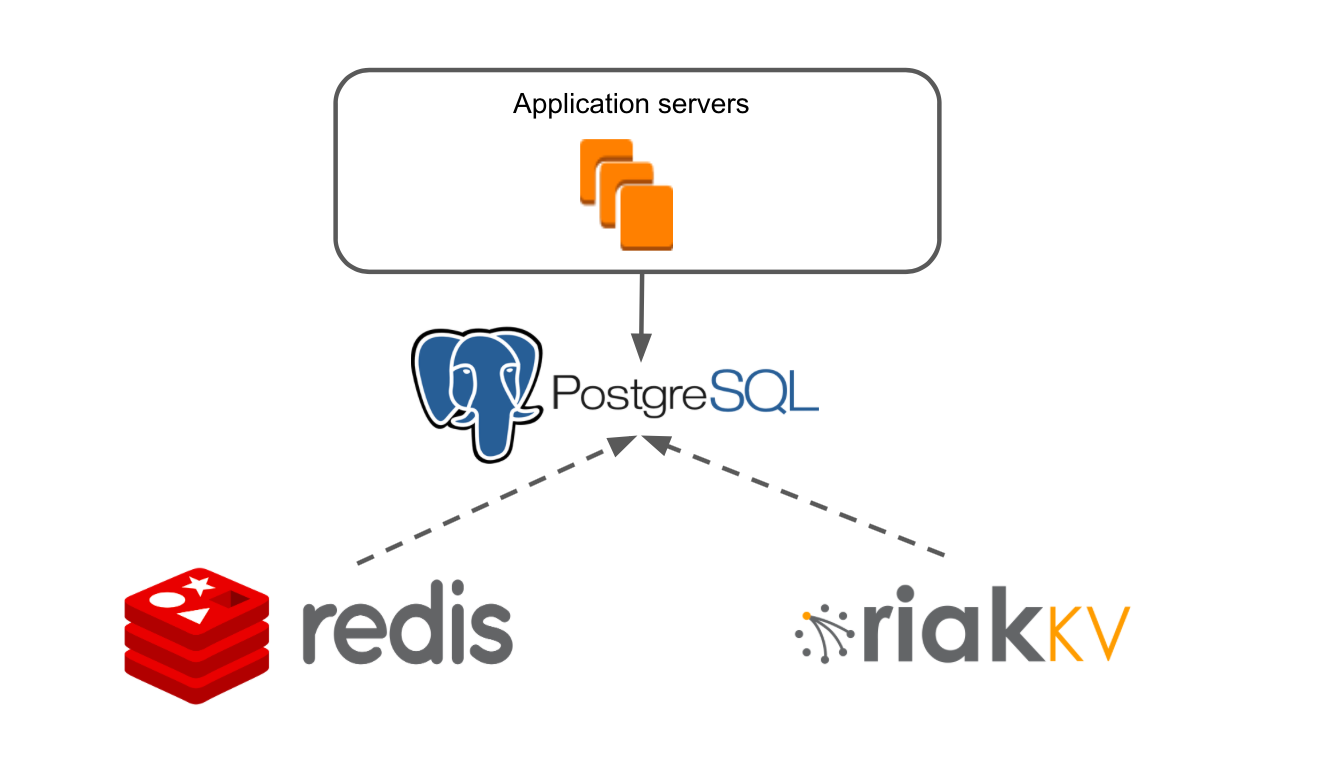
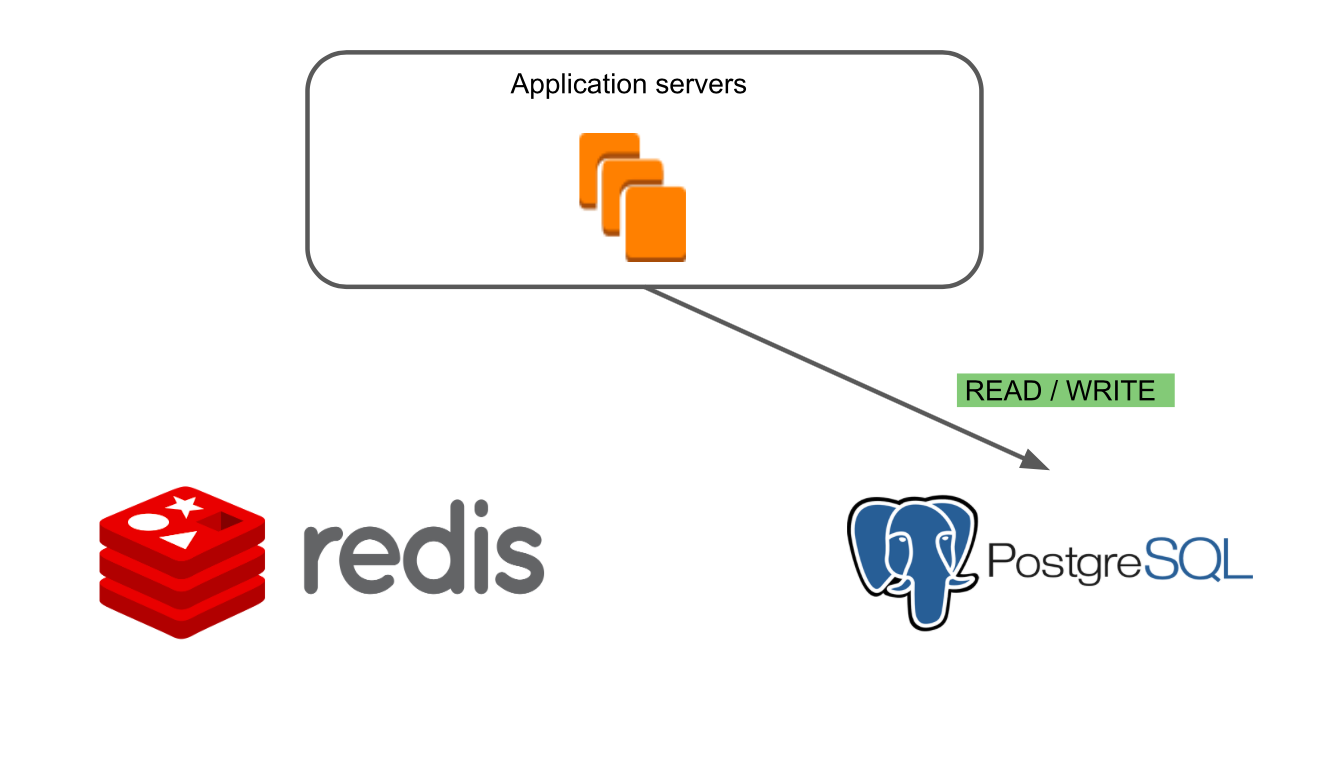
Simplified, the architecture of our application looked like this: there are Application Servers, which turn to Redis and RiakKV through the data processing layer.
Our Application Server is a monolithic Java application. Business logic is written on a framework that is adapted for NoSQL. The application has its own transactional system that allows you to ensure the work of many users on any of our boards.
RiakKV we used to store data archive boards, which did not open within 7 days.
Add PostgreSQL to this schema. We make it so that Application servers work with a new database. Copy data from Redis and RiakKV to PostgreSQL. Problem solved!
Nothing complicated, but there are nuances:
We had a choice of two data migration options:
Stopping the development of the service is a waste of time that we could use for growth, which means the loss of users and market share. For us, this is critical, so we chose the option with a smooth migration. Despite the fact that, in terms of complexity, this process can be compared with the replacement of wheels on a car while driving.
In evaluating the work, we broke our product into basic blocks: users, accounts, boards, and so on. Separately carried out work on the creation of infrastructure PostgreSQL. And they put the risks in the assessment in case something goes wrong (this is how it happened).
The next step is to build the work of a team of five people so that everyone moves at the right speed towards a common goal.
We have two points: the beginning of work on the task and the final goal. Ideally, when we move to the goal in a direct way. But it often happens that we want to go straight, but it turns out like this:
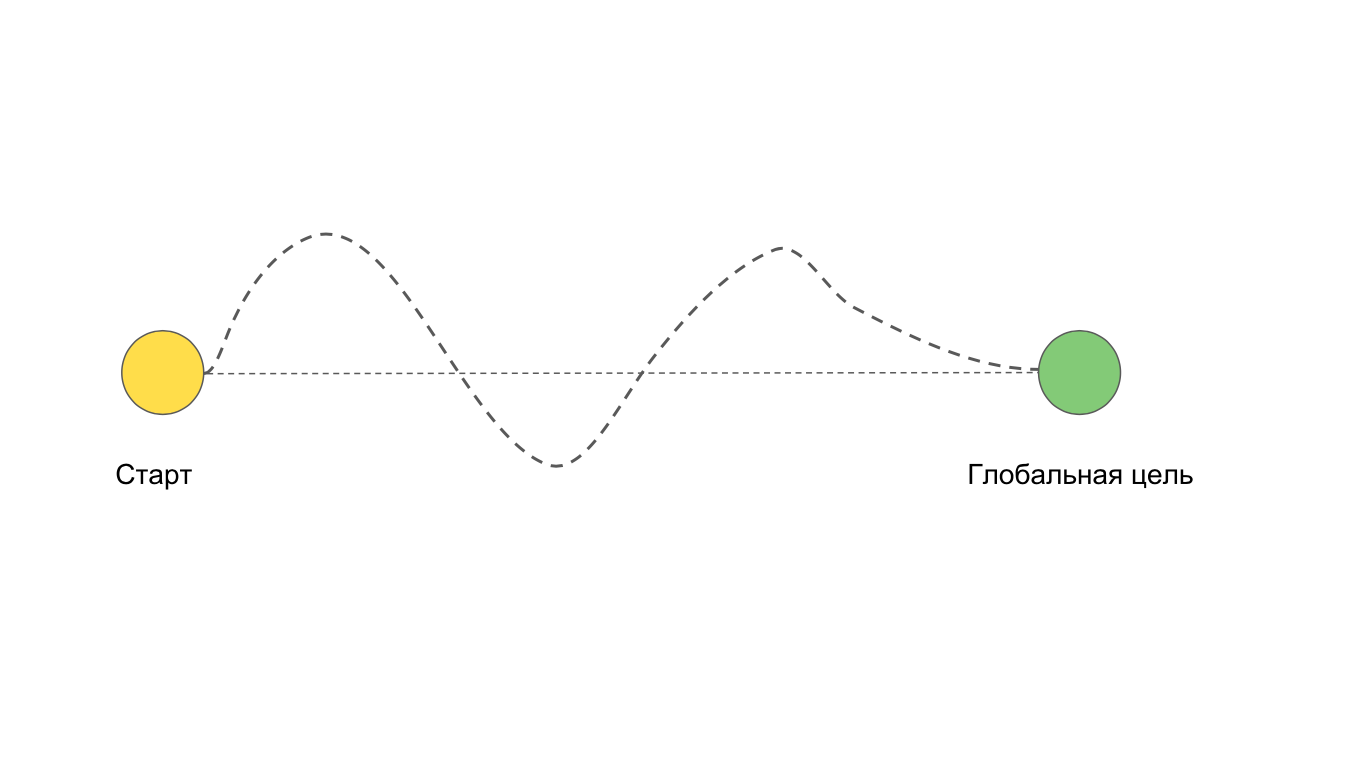
For example, due to difficulties and problems that could not have been foreseen.
A situation is possible in which we generally do not come to the goal. For example, if we go into deep refactoring or rewriting the entire application.
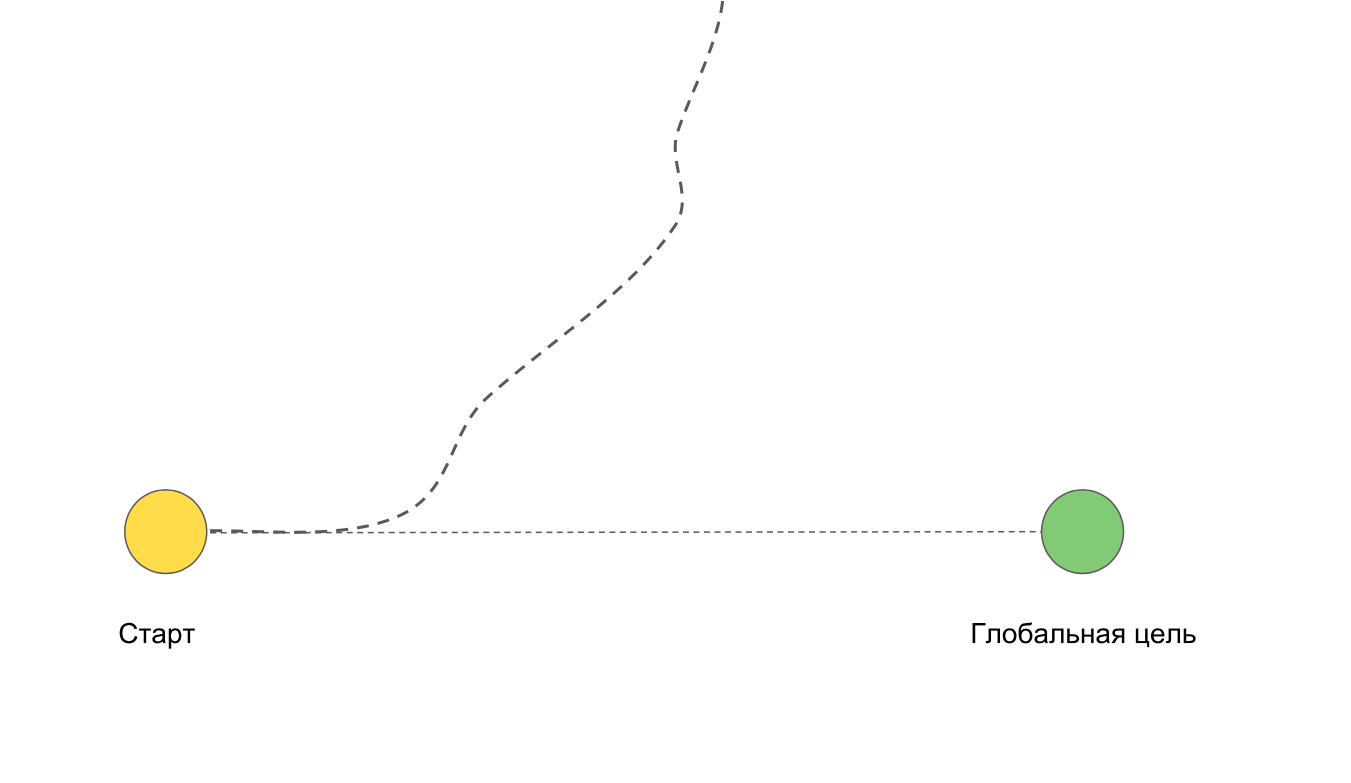
We split the task into weekly sprints to minimize the difficulties described above. If suddenly the team leaves aside, it can quickly return back with minimal losses for the project, since short iterations do not allow to go too far "not there".
Each iteration has its own goal, which moves the team to the final big result.

If during the sprint there is a new task, we estimate whether it brings us closer to the goal of its implementation. Yes - we take the next sprint or change priorities in the current, if not - we don’t take it. If errors appear, we set them high priority and quickly fix them.
It happens that developers within a sprint must perform tasks in a strictly defined sequence. Or, for example, the developer sends the finished task to the QA-engineer for urgent testing. At the planning stage, we try to build similar dependencies between tasks for each team member. This allows the entire team to see who will do what and when, without forgetting dependence on others.
The team has daily and weekly synchronous. Every morning in the morning we discuss who will do what and in what priority today. After each sprint we synchronize with each other to make sure that everyone is moving in the right direction. Be sure to make plans for large or complex releases. We assign duty developers who, if necessary, are present during the release and monitor that everything is in order.
Planning and synchronization within the team allows you to involve all participants in all phases of the project. Plans and estimates do not come to us from above, we make them ourselves. This increases the responsibility and interest of the team in performing tasks.
This is one of our sprints. We conduct everything on the RealtimeBoard board:

During the migration, we had to guarantee the stable operation of the service in combat conditions. To do this, you need to be sure that everything has been tested and there are no errors anywhere. To achieve this goal, we decided to make our smooth migration even smoother.
The idea was to gradually switch the blocks of the product to the new database. To do this, we came up with a sequence of modes.
In the first “Redis Read / Write” mode, only the old Redis database is running.

In the second mode “PostgreSQL Passive Write” we can make sure that writing to the new database is correct and the databases are consistent.
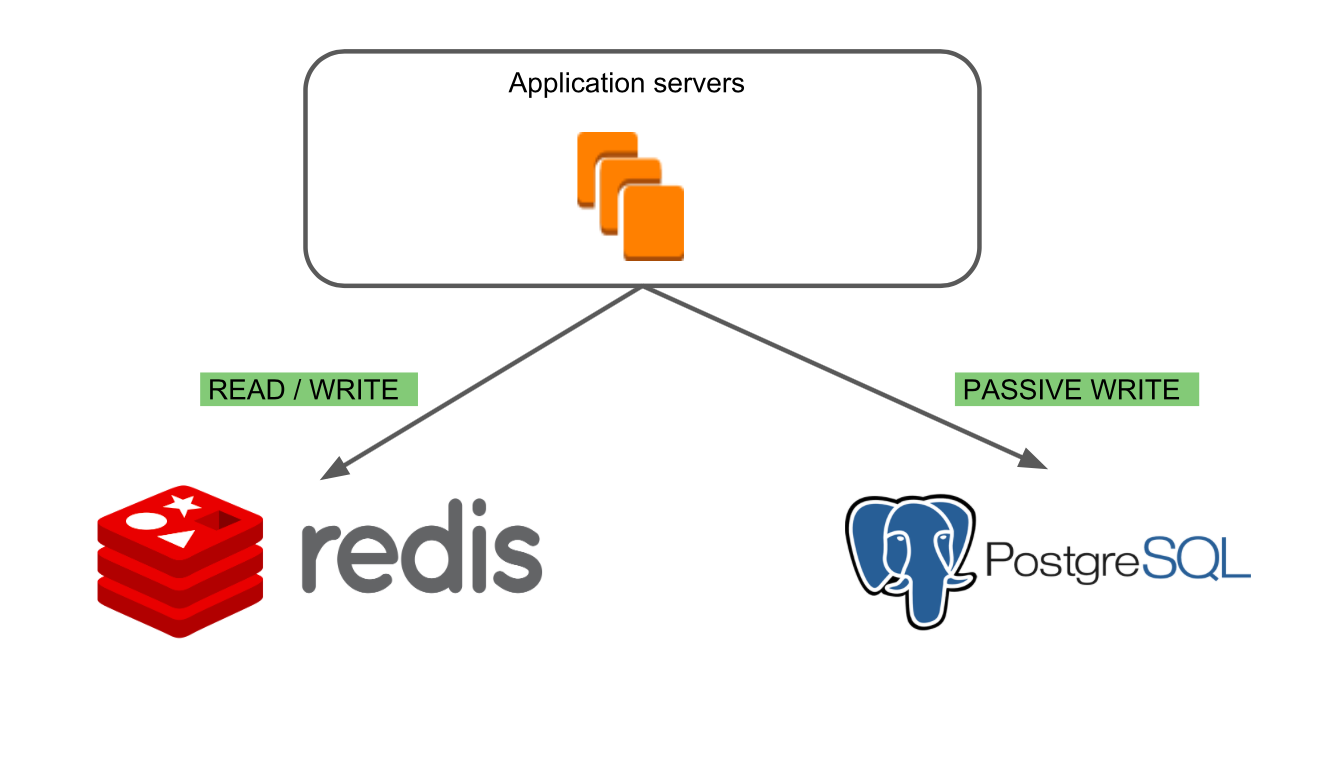
The third mode “PostgreSQL Read / Write, Redis Passive Write” allows you to ensure the correctness of reading data from PostgreSQL and see how the new database behaves in combat conditions. Redis remains the main base, which enabled us to find specific cases of working with boards that could lead to errors.

In the latter mode, “PostgreSQL Read / Write” , only the new database works.
The migration work could affect the main functions of the product, so we had to be 100% sure that we would not break anything and the new database is at least as slow as the old one. Therefore, we began to conduct safe experiments with switching modes.
Switching modes began on our corporate account, which we use daily in work. After we were convinced that there were no errors in it, we began to switch modes on a small sample of external users.
Timeline run experiments with modes turned out like this:
When errors occurred, we had the opportunity to quickly correct them, because we ourselves could make releases to the servers where the users participating in the experiment worked. We did not depend on the main release in any way, so we corrected errors quickly and at any time.
During migration, we often overlapped with the teams that released new features. We have a single code base, and as part of their work, the teams could change existing structures in the new database or create new ones. In this case, there could be intersections of teams for the development and withdrawal of new features. For example, one of the product teams promised the marketing team to release a new feature by a specific date; marketing team has planned an advertising campaign for this period; the sales team is waiting for the feature and campaign to start communicating with new customers. It turns out that everyone is dependent on each other, and delaying the deadlines by one team disrupts the plans of another.
To avoid such situations, we, together with other teams, compiled a single grocery roadmap, according to which we synchronized several times a quarter, and with some teams weekly.
What we have learned during this project:
In the following articles I will talk in more detail about the technical problems that we solved during the migration.
For a long time, the main database in RealtimeBoard was Redis. We stored in it all the basic information: data about users, accounts, boards, etc. Everything worked quickly, but we faced a number of problems.
Problems with redis
- Dependence on network latency. Now in our cloud it is about 20 Moscow time, but as it increases, the application will start working very slowly.
- The lack of indexes that we need at the level of business logic. Their independent implementation can complicate business logic and lead to inconsistency of data.
- The complexity of the code also complicates the maintenance of data consistency.
- Resource intensity queries with samples.
These problems, along with the increasing amount of data on the servers, caused the database to be migrated.
Formulation of the problem
The decision on migration is made. The next step is to understand which of the databases is suitable for our data model.
We conducted a study to select the optimal database for us, and stopped at PostgreSQL. Our data model fits well with a relational database: PostgreSQL has built-in tools for data consistency, JSONB type, and the ability to index certain fields in JSONB. It suits us.
Simplified, the architecture of our application looked like this: there are Application Servers, which turn to Redis and RiakKV through the data processing layer.
Our Application Server is a monolithic Java application. Business logic is written on a framework that is adapted for NoSQL. The application has its own transactional system that allows you to ensure the work of many users on any of our boards.
RiakKV we used to store data archive boards, which did not open within 7 days.
Add PostgreSQL to this schema. We make it so that Application servers work with a new database. Copy data from Redis and RiakKV to PostgreSQL. Problem solved!
Nothing complicated, but there are nuances:
- We have 2.2 million registered users. Every day 50,000 users work in RealtimeBoard, the peak load is up to 14,000 at a time. Users should not encounter errors due to our work, they should not notice at all the moment of moving to a new base.
- 1 TB of data in the database or 410 million objects.
- Continuous release of new features by other teams, whose work we should not interfere.
Solutions to the problem
We had a choice of two data migration options:
- Stop the development of the service → rewrite the code on the server → test the functionality → launch a new version.
- Conduct a smooth migration: gradually transfer parts of the product to a new database, while simultaneously supporting PostgreSQL and Redis without interrupting the development of new features.
Stopping the development of the service is a waste of time that we could use for growth, which means the loss of users and market share. For us, this is critical, so we chose the option with a smooth migration. Despite the fact that, in terms of complexity, this process can be compared with the replacement of wheels on a car while driving.
In evaluating the work, we broke our product into basic blocks: users, accounts, boards, and so on. Separately carried out work on the creation of infrastructure PostgreSQL. And they put the risks in the assessment in case something goes wrong (this is how it happened).
Sprints and goals
The next step is to build the work of a team of five people so that everyone moves at the right speed towards a common goal.
We have two points: the beginning of work on the task and the final goal. Ideally, when we move to the goal in a direct way. But it often happens that we want to go straight, but it turns out like this:
For example, due to difficulties and problems that could not have been foreseen.
A situation is possible in which we generally do not come to the goal. For example, if we go into deep refactoring or rewriting the entire application.
We split the task into weekly sprints to minimize the difficulties described above. If suddenly the team leaves aside, it can quickly return back with minimal losses for the project, since short iterations do not allow to go too far "not there".
Each iteration has its own goal, which moves the team to the final big result.
If during the sprint there is a new task, we estimate whether it brings us closer to the goal of its implementation. Yes - we take the next sprint or change priorities in the current, if not - we don’t take it. If errors appear, we set them high priority and quickly fix them.
It happens that developers within a sprint must perform tasks in a strictly defined sequence. Or, for example, the developer sends the finished task to the QA-engineer for urgent testing. At the planning stage, we try to build similar dependencies between tasks for each team member. This allows the entire team to see who will do what and when, without forgetting dependence on others.
The team has daily and weekly synchronous. Every morning in the morning we discuss who will do what and in what priority today. After each sprint we synchronize with each other to make sure that everyone is moving in the right direction. Be sure to make plans for large or complex releases. We assign duty developers who, if necessary, are present during the release and monitor that everything is in order.
Planning and synchronization within the team allows you to involve all participants in all phases of the project. Plans and estimates do not come to us from above, we make them ourselves. This increases the responsibility and interest of the team in performing tasks.
This is one of our sprints. We conduct everything on the RealtimeBoard board:
Modes and safe experiments
During the migration, we had to guarantee the stable operation of the service in combat conditions. To do this, you need to be sure that everything has been tested and there are no errors anywhere. To achieve this goal, we decided to make our smooth migration even smoother.
The idea was to gradually switch the blocks of the product to the new database. To do this, we came up with a sequence of modes.
In the first “Redis Read / Write” mode, only the old Redis database is running.
In the second mode “PostgreSQL Passive Write” we can make sure that writing to the new database is correct and the databases are consistent.
The third mode “PostgreSQL Read / Write, Redis Passive Write” allows you to ensure the correctness of reading data from PostgreSQL and see how the new database behaves in combat conditions. Redis remains the main base, which enabled us to find specific cases of working with boards that could lead to errors.
In the latter mode, “PostgreSQL Read / Write” , only the new database works.
The migration work could affect the main functions of the product, so we had to be 100% sure that we would not break anything and the new database is at least as slow as the old one. Therefore, we began to conduct safe experiments with switching modes.
Switching modes began on our corporate account, which we use daily in work. After we were convinced that there were no errors in it, we began to switch modes on a small sample of external users.
Timeline run experiments with modes turned out like this:
- January-February: Redis read / write
- March-April: PostgreSQL passive write
- May-June: PostgreSQL read / write, the main base is Redis
- July-August: PostgreSQL read / write
- September-December: full migration.
When errors occurred, we had the opportunity to quickly correct them, because we ourselves could make releases to the servers where the users participating in the experiment worked. We did not depend on the main release in any way, so we corrected errors quickly and at any time.
Cross-team interaction
During migration, we often overlapped with the teams that released new features. We have a single code base, and as part of their work, the teams could change existing structures in the new database or create new ones. In this case, there could be intersections of teams for the development and withdrawal of new features. For example, one of the product teams promised the marketing team to release a new feature by a specific date; marketing team has planned an advertising campaign for this period; the sales team is waiting for the feature and campaign to start communicating with new customers. It turns out that everyone is dependent on each other, and delaying the deadlines by one team disrupts the plans of another.
To avoid such situations, we, together with other teams, compiled a single grocery roadmap, according to which we synchronized several times a quarter, and with some teams weekly.
findings
What we have learned during this project:
- Do not be afraid to take on complex projects. After decomposition, evaluation and development of approaches to work, complex projects cease to seem overwhelming.
- Do not spare the time and effort on the preliminary estimates, decomposition and planning. This helps to better understand the task before you start working on it, and to understand the volume and complexity of the work.
- Lay risks in heavy technical and organizational projects. In the process of work, you are sure to encounter a problem that was not taken into account when planning.
- Do not migrate if it is not necessary.
In the following articles I will talk in more detail about the technical problems that we solved during the migration.
Source: https://habr.com/ru/post/437826/