How to win in digital WorldSkills? On a practical example
Hi, Habr!
In December, our colleague from Advanced Analytics, Leonid Sherstyuk, took first place in the competence of Machine Learning and Big Data in the 2nd industry championship DigitalSkills. This is a “digital” branch of well-known professional contests, which are organized by WorldSkills Russia. More than 200 people took part in the championship, competed for leadership in 25 digital competencies - Corporate protection against internal threats to information security, Internet marketing, Development of computer games and multimedia applications, Quantum technologies, Internet of things, Industrial design, etc.

As a case for Machine Learning, the task of monitoring and detecting defects in NPP pipelines, oil and gas pipelines using a semi-automatic ultrasonic inspection system was proposed.
Leonid will tell about what was in the competition and how he managed to win under the cut.
WorldSkills is an international organization that organizes skills competitions around the world. Traditionally, representatives of industrial companies and students from relevant universities participated in these competitions, demonstrating their skills in working specialties. Recently, digital nominations began to appear in the competition, where young specialists compete in the skills of robot building, application development, information security, and in other professions that you can’t call workers. In one of these nominations - Machine learning and working with big data - I competed in Kazan at the DigitalSkills competition held under the auspices of WS.
Since the competence for the competition is new, it was hard for me to imagine what to expect. Just in case, I repeated everything I know about working with databases and distributed computing, metrics and learning algorithms, statistical criteria and preprocessing methods. Being familiar with approximate evaluation criteria, I did not understand how it was possible in 6 short sessions to get in the way of working with Hadoop and creating a chat bot.
The entire competition takes 3 days, for 6 sessions. Each session consists of 3 hours with a break, for which you need to complete several tasks, meaningfully related to each other. At first it may seem that time is quite enough, but in reality a frantic pace was needed in order to have time to do everything that was planned.
It was expected at the competition that it was not supposed to work with big data, and the entire task pool was reduced to analyzing a limited set of data.
In essence, we were asked to repeat the path of one of the organizers, to which the customers came with their problem and data, and from which they were waiting for a commercial offer within a few weeks.
We worked with the data of the LS (the system of semi-automatic ultrasonic testing). The system is designed to check the seams in the pipeline for cracks and defects. The installation itself goes on a rail installed on the pipe, and makes 16 measurements at each step. In ideal conditions and in the absence of defects, some sensors should have given the maximum signal, others - zero; in reality, the data were very noisy, and answering the question of whether there is a defect in a given place became a non-trivial task.

Installation of the BCD system
The first day was devoted to acquaintance with the data, their cleaning, compiling descriptive statistics. We were given minimal background information about the installation and the types of sensors attached to the device. In addition to data preprocessing, we needed to establish what type of sensors are and how they are located on the instrument.
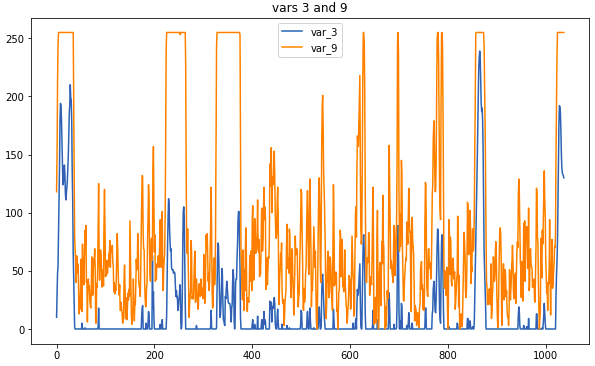
Sample data: related sensors
The main preprocessing operation is to replace measurements with a moving average. With too large a window, there was a risk of losing too much information, but correlations that would help determine the type would be more obvious. Some links were visible and without pretreatment; However, there was no time to attentively examine the raw data, therefore, it is impossible to do without using correlograms.
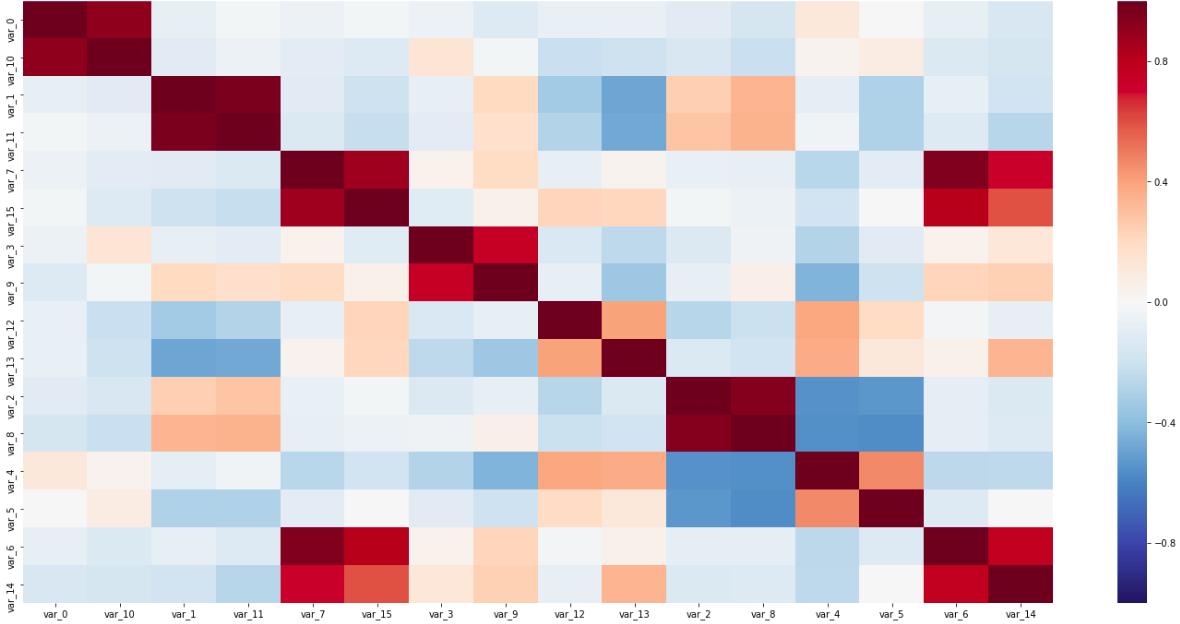
Correlation matrix
On this matrix are visible as a pair of sensors along the diagonal, closely related to each other, and inversely correlated variables; All this helped determine the types of sensors.
The last mandatory point was to reduce the sensors to one coordinate. Since the measuring device is substantially more than one measuring step, and the sensors were spread throughout the instrument, this was a mandatory step before further using the data for training.
 \
\
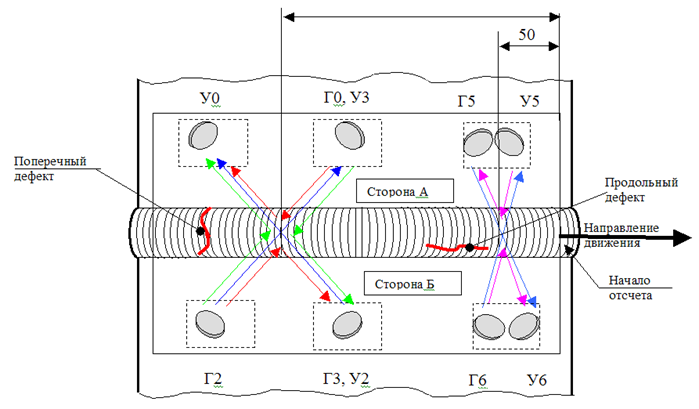
The layout of the sensors on the installation
The diagram of the installation of sensors on the device shows that we need to find the distances between the three groups of sensors. The easiest and fastest way here is to establish on which segment of the instrument each sensor should be located, and then search for the maximum correlation, shifting part of the measurements by one step.
This stage was complicated by the fact that my assumptions about the type of sensors were not guaranteed, so I had to look through all the correlations, types, scheme, and link it into a single consistent system.
For the second day, we had to prepare data for training and clustering on points, and then build a classifier.
During the preparation of the data, I removed too correlated readings, and as a synthetic feature I added a moving average, a derivative, and a z-score. Undoubtedly, in the synthesis of new variables it was possible to play out quite widely, but time imposed its own limitations.
Clustering could help separate the points of defects from all the others. I tried 3 methods: k-means, Birch and DBScan, but, unfortunately, none of them gave a good result.
For the predictive algorithm, we were given complete freedom; asked only the format that should be on the output. The algorithm was supposed to provide a table (or data, reducible to it), in which a row corresponds to one crack, and to the columns, its characteristics (such as length, width, type, and side). It seemed to me the simplest option in which we make a prediction for each point of the test sample, and then the neighboring ones are joined into one crack. As a result, I made 3 classifiers that answered the following questions: on which side of the seam is the defect, how deep does it go, and what type is it (longitudinal or transverse).
Here the depth that the regression should have predicted is striking; however, in the marked sample, I found only 5 unique depths, so I found this simplification valid.

Algorithm performance evaluation metrics
Of all the algorithms (I managed to try logistic regression, a decision tree and a gradient boost), the best, as expected, was the boost. The metrics are undoubtedly very pleasant, but it is quite difficult to evaluate the performance of algorithms without results on a new, test sample. The organizers never returned with specific metrics, limiting themselves only to a general comment that no one coped with the test as well as on a delayed sample.
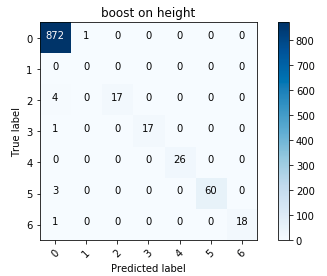
Error Matrix for Boosting
Overall, I was pleased with the results; in particular, the reduction of height to a categorical variable has proved itself.
For the last day we had to wrap up the trained algorithms in a product that a potential customer could use and prepare a presentation of our enterprise-ready solution.
Here perfectionism helped me in writing relatively clean code, not missing even in limited time. From ready-made pieces of code, the prototype came together quickly, and I had time to debug errors. In contrast to the previous stages, here the more important role was played by the workability of the decision, and not by meeting the formal criteria.

The finished product is a CLI utility.
By the end of the session, I had a CLI utility that takes the source folder as an input and returns the tables with the results of the prediction in a form suitable for the technologist.
At the final stage, I was given the opportunity to tell about my successes and see what other participants came to. Even in conditions of strict criteria, our solutions were completely different - someone successfully clustering, others skillfully used linear methods. During the presentations, the contestants focused on their strengths - some put on the sale of the product, others more deeply immersed in technical details; there were beautiful graphics and adaptive interfaces to the solution.

The main advantage of my solution is placed on one slide.
What can you say about the competition in general?
Competitions of this type are a great opportunity to find out how quickly you can perform tasks typical for your specialty. The criteria were drawn up in such a way that not the one who got the best results (as it happens, for example, at Kaggle), but who is quicker able to perform operations typical for daily work in the industry, earns more points. In my opinion, participation and victory in such competitions can tell a potential employer as much as experience in the industry, on hackathons and Kaggle.
Lenonid Sherstyuk,
Data Analyst, Advanced Analytics, SIBUR
In December, our colleague from Advanced Analytics, Leonid Sherstyuk, took first place in the competence of Machine Learning and Big Data in the 2nd industry championship DigitalSkills. This is a “digital” branch of well-known professional contests, which are organized by WorldSkills Russia. More than 200 people took part in the championship, competed for leadership in 25 digital competencies - Corporate protection against internal threats to information security, Internet marketing, Development of computer games and multimedia applications, Quantum technologies, Internet of things, Industrial design, etc.
As a case for Machine Learning, the task of monitoring and detecting defects in NPP pipelines, oil and gas pipelines using a semi-automatic ultrasonic inspection system was proposed.
Leonid will tell about what was in the competition and how he managed to win under the cut.
WorldSkills is an international organization that organizes skills competitions around the world. Traditionally, representatives of industrial companies and students from relevant universities participated in these competitions, demonstrating their skills in working specialties. Recently, digital nominations began to appear in the competition, where young specialists compete in the skills of robot building, application development, information security, and in other professions that you can’t call workers. In one of these nominations - Machine learning and working with big data - I competed in Kazan at the DigitalSkills competition held under the auspices of WS.
Since the competence for the competition is new, it was hard for me to imagine what to expect. Just in case, I repeated everything I know about working with databases and distributed computing, metrics and learning algorithms, statistical criteria and preprocessing methods. Being familiar with approximate evaluation criteria, I did not understand how it was possible in 6 short sessions to get in the way of working with Hadoop and creating a chat bot.
The entire competition takes 3 days, for 6 sessions. Each session consists of 3 hours with a break, for which you need to complete several tasks, meaningfully related to each other. At first it may seem that time is quite enough, but in reality a frantic pace was needed in order to have time to do everything that was planned.
It was expected at the competition that it was not supposed to work with big data, and the entire task pool was reduced to analyzing a limited set of data.
In essence, we were asked to repeat the path of one of the organizers, to which the customers came with their problem and data, and from which they were waiting for a commercial offer within a few weeks.
We worked with the data of the LS (the system of semi-automatic ultrasonic testing). The system is designed to check the seams in the pipeline for cracks and defects. The installation itself goes on a rail installed on the pipe, and makes 16 measurements at each step. In ideal conditions and in the absence of defects, some sensors should have given the maximum signal, others - zero; in reality, the data were very noisy, and answering the question of whether there is a defect in a given place became a non-trivial task.
Installation of the BCD system
The first day was devoted to acquaintance with the data, their cleaning, compiling descriptive statistics. We were given minimal background information about the installation and the types of sensors attached to the device. In addition to data preprocessing, we needed to establish what type of sensors are and how they are located on the instrument.
Sample data: related sensors
The main preprocessing operation is to replace measurements with a moving average. With too large a window, there was a risk of losing too much information, but correlations that would help determine the type would be more obvious. Some links were visible and without pretreatment; However, there was no time to attentively examine the raw data, therefore, it is impossible to do without using correlograms.
Correlation matrix
On this matrix are visible as a pair of sensors along the diagonal, closely related to each other, and inversely correlated variables; All this helped determine the types of sensors.
The last mandatory point was to reduce the sensors to one coordinate. Since the measuring device is substantially more than one measuring step, and the sensors were spread throughout the instrument, this was a mandatory step before further using the data for training.
\The layout of the sensors on the installation
The diagram of the installation of sensors on the device shows that we need to find the distances between the three groups of sensors. The easiest and fastest way here is to establish on which segment of the instrument each sensor should be located, and then search for the maximum correlation, shifting part of the measurements by one step.
This stage was complicated by the fact that my assumptions about the type of sensors were not guaranteed, so I had to look through all the correlations, types, scheme, and link it into a single consistent system.
For the second day, we had to prepare data for training and clustering on points, and then build a classifier.
During the preparation of the data, I removed too correlated readings, and as a synthetic feature I added a moving average, a derivative, and a z-score. Undoubtedly, in the synthesis of new variables it was possible to play out quite widely, but time imposed its own limitations.
Clustering could help separate the points of defects from all the others. I tried 3 methods: k-means, Birch and DBScan, but, unfortunately, none of them gave a good result.
For the predictive algorithm, we were given complete freedom; asked only the format that should be on the output. The algorithm was supposed to provide a table (or data, reducible to it), in which a row corresponds to one crack, and to the columns, its characteristics (such as length, width, type, and side). It seemed to me the simplest option in which we make a prediction for each point of the test sample, and then the neighboring ones are joined into one crack. As a result, I made 3 classifiers that answered the following questions: on which side of the seam is the defect, how deep does it go, and what type is it (longitudinal or transverse).
Here the depth that the regression should have predicted is striking; however, in the marked sample, I found only 5 unique depths, so I found this simplification valid.
Algorithm performance evaluation metrics
Of all the algorithms (I managed to try logistic regression, a decision tree and a gradient boost), the best, as expected, was the boost. The metrics are undoubtedly very pleasant, but it is quite difficult to evaluate the performance of algorithms without results on a new, test sample. The organizers never returned with specific metrics, limiting themselves only to a general comment that no one coped with the test as well as on a delayed sample.
Error Matrix for Boosting
Overall, I was pleased with the results; in particular, the reduction of height to a categorical variable has proved itself.
For the last day we had to wrap up the trained algorithms in a product that a potential customer could use and prepare a presentation of our enterprise-ready solution.
Here perfectionism helped me in writing relatively clean code, not missing even in limited time. From ready-made pieces of code, the prototype came together quickly, and I had time to debug errors. In contrast to the previous stages, here the more important role was played by the workability of the decision, and not by meeting the formal criteria.
The finished product is a CLI utility.
By the end of the session, I had a CLI utility that takes the source folder as an input and returns the tables with the results of the prediction in a form suitable for the technologist.
At the final stage, I was given the opportunity to tell about my successes and see what other participants came to. Even in conditions of strict criteria, our solutions were completely different - someone successfully clustering, others skillfully used linear methods. During the presentations, the contestants focused on their strengths - some put on the sale of the product, others more deeply immersed in technical details; there were beautiful graphics and adaptive interfaces to the solution.
The main advantage of my solution is placed on one slide.
What can you say about the competition in general?
Competitions of this type are a great opportunity to find out how quickly you can perform tasks typical for your specialty. The criteria were drawn up in such a way that not the one who got the best results (as it happens, for example, at Kaggle), but who is quicker able to perform operations typical for daily work in the industry, earns more points. In my opinion, participation and victory in such competitions can tell a potential employer as much as experience in the industry, on hackathons and Kaggle.
Lenonid Sherstyuk,
Data Analyst, Advanced Analytics, SIBUR
Source: https://habr.com/ru/post/437974/