RedisPipe - more fun together
When I think about how naive RPC clients work, I am reminded of a joke:
Court.
- Defendant, why did you kill a woman?
- I'm on the bus, the conductor approaches the woman, demanding to buy a ticket. A woman opened her purse, took out her purse, closed her purse, opened her purse, took out her purse, closed her purse, opened her purse, put her purse in there, closed her purse, opened her purse, took out money, opened her purse, opened her purse, closed her purse, opened her purse, put there purse , closed the purse, opened her purse, put the purse in there.
- So what?
- The controller gave her a ticket. A woman opened her purse, took out her purse, closed her purse, opened her purse, took out her purse, closed her purse, opened her purse, put her purse in there, closed her purse, opened her purse, put there ticket, closed her purse, opened her purse, opened her purse , put the purse in there, closed the purse, opened the purse, put the purse in there, closed the purse.
“Take the change,” came the voice of the controller. A woman ... opened her purse ...
- Yes, it is not enough to kill her, - the prosecutor does not stand up.
- So I did it.
© S.Altov

Approximately the same thing happens in the "request-response" process, if this is not taken seriously:
- the user process writes a serialized request "to the socket", actually copying it into the socket buffer at the OS level;
This is a rather difficult operation. it is necessary to make a context switch (even if it can be “easy”); - when it seems to OSes that something can be written to the network, a packet is formed (the request is copied again) and sent to the network card;
- the network card writes the packet to the network (possibly, pre-buffering);
- (along the way, the packet may be buffered several times in routers);
- finally, the packet arrives at the destination host and is buffered on the network card;
- the network card sends a notification to the operating system, and when the operating system finds the time, it copies the packet to its buffer and sets the ready flag on the file descriptor;
- (we must still remember to send an ACK in response);
- after some time, the server application realizes that readiness is on the descriptor (using epoll), and someday copies the request to the application buffer;
- and finally, the server application handles the request.
As you understand, the transmission of the answer occurs in exactly the same way only in the opposite direction. Thus, each request spends a considerable amount of time on the operating system for its service, and each answer spends the same time again.
This became especially noticeable after Meltdown / Specter, since the released patches led to a strong increase in the cost of system calls. In early January 2018, our Redis cluster suddenly began to consume a half to two times more CPU. Amazon has applied the appropriate kernel patches to close these vulnerabilities. (True, Amazon later applied a new version of the patch, and the CPU consumption decreased almost to previous levels. But the connector has already begun to be born.)
Unfortunately, all the widely known Go connectors to Redis and Memcached work this way: the connector creates a pool of connections, and when you need to send a request, it pulls the connection from the pool, writes one request to it, and then waits for a response. (It’s especially sad that the memcached connector was written by Brad Fitzpatrick himself.) And some connectors have such an unsuccessful implementation of this pool that the process of withdrawing a connection from the pool becomes a botnet itself.
There are two ways to alleviate this hard work of sending a request / response in several ways:
- Use direct access to the network map: DPDK, netmap, PF_RING, etc.
- Do not send each request / response in a separate package, but combine them into larger packages if possible, that is, spread out the overhead of working with the network on several requests. Together more fun!
The first option, of course, is possible. But, first, it is for the brave in spirit, because you have to write the TCP / IP implementation yourself (for example, as in ScyllaDB). And secondly, in this way we facilitate the situation only on one side - on the one we write ourselves. I still do not want to rewrite Redis (for now), so the servers will consume as much, even if the client uses the cool DPDK.
The second option is much simpler, and most importantly, it eases the situation immediately, both on the client and on the server. For example, one in-memory database boasts that it can serve millions of RPS, while Redis cannot serve a couple of hundreds of thousands . However, this success is not so much the realization of that in-memory database as the decision taken once that the protocol will be completely asynchronous, and clients should use this asynchrony whenever possible. What many clients (especially used in benchmarks) successfully implement by sending requests through one TCP connection and, if possible, sending them to the network together.
A well-known article shows that Redis can also give a million responses per second if pipelining is used. Personal experience in the development of in-memory storadzhey also suggests that pipelining significantly reduces the consumption of SYS CPU and allows much more efficient use of the processor and the network.
The only question is how to use pipelining, if in the application requests to Redis are often received one at a time? And if one server is missing and Redis Cluster is used with a large number of shards, then even when a packet of requests is encountered, it splits into single requests for each shard.
The answer, of course, is “obvious”: do implicit pipelaying by collecting requests from all parallel working gorutin to one Redis server and sending them through one connection.
By the way, implicit pipelining is not so rare in connectors in other languages: nodejs node_redis , C # RedisBoost , python's aioredis, and many others. Many of these connectors are written on top of event loops, and therefore the collection of requests from parallel “calculation threads” looks natural there. Go also promotes the use of synchronous interfaces, and apparently because very few people decide to organize their own loops.
We wanted to use Redis as efficiently as possible and therefore we decided to write a new “better” (tm) connector: RedisPipe .
How to make implicit paylayning?
Basic scheme:
- application logic of gorutin do not write requests directly to the network, but transfer them to the gorutine-collector;
- the collector collects a packet of requests whenever possible, writes them to the network, and transfers them to the gorutine reader;
- Goretin-reader reads the answers from the network, compares them with the corresponding requests, and notifies the logic of the arrived answer.
You must somehow notify the reply. A smart programmer on Go will of course say: “Through the channel!”
But this is not the only possible synchronization primitive and not the most efficient even in the Go environment. And since the needs of different people are different, we will make the mechanism extensible, allowing the user to implement the interface (let's call it Future ):
type Future interface { Resolve(val interface{}) } And then the basic scheme will look like this:
type future struct { req Request fut Future } type Conn struct { c net.Conn futmtx sync.Mutex wfutures []future futtimer *time.Timer rfutures chan []future } func (c *Conn) Send(r Request, f Future) { c.futmtx.Lock() defer c.futmtx.Unlock() c.wfutures = append(c.wfutures, future{req: r, fut: f}) if len(c.wfutures) == 1 { futtimer.Reset(100*time.Microsecond) } } func (c *Conn) writer() { for range c.futtimer.C { c.futmtx.Lock() futures, c.wfutures = c.wfutures, nil c.futmtx.Unlock() var b []byte for _, ft := range futures { b = AppendRequest(b, ft.req) } _, _err := ccWrite(b) c.rfutures <- futures } } func (c *Conn) reader() { rd := bufio.NewReader(cc) var futures []future for { response, _err := ParseResponse(rd) if len(futures) == 0 { futures = <- c.rfutures } futures[0].fut.Resolve(response) futures = futures[1:] } } Of course, this is a very simplified code. Omitted:
- connection setup;
- I / O timeouts;
- error handling on read / write;
- re-establishing the connection;
- the ability to cancel the request before sending it to the network;
- optimization of memory allocation (reuse of the buffer and futures arrays).
Any input-output error (including timeout) in the real code leads to a rezolv error of all Future, the corresponding send and waiting for sending requests.
The connection layer does not re-request requests, and if you need (and can) re-repeat the request, it can be done at the higher level of abstraction (for example, in the implementation of Redis Cluster support described below).
Remark. Initially, the scheme looked a little more complicated. But in the process of experiments simplified to this option.
Remark 2. There are very strict requirements for the Future.Resolve method: it should be as fast as possible, almost non-blocking and in no case panic. This is due to the fact that it is called synchronously in the reader cycle, and any “brakes” will inevitably lead to degradation. The implementation of Future.Resolve should do the necessary minimum of linear actions: to awaken the waiting; it is possible to handle the error and send an asynchronous repeat (used in the implementation of cluster support).
Effect
A good benchmark is half the article!
A good benchmark is one that is as close as possible to combat use by the observed effects. And this is not easy to do.
Option benchmark , which, I think, looks quite similar to this:
- the main “script” emulates 5 parallel clients,
- in each “client” for every 300-1000 “desired” rps is launched on a gorutina (3 gorutins are launched for 1000 rps, 124 gorutins for 128,000 rps),
- Gorutina uses a separate instance of the limiter and sends requests with random batches - from 5 to 15 requests.
The randomness of a series of queries allows you to achieve a random distribution of series in the time scale, which more correctly reflects the actual load.
Wrong options were:
a) use one rate-limiter for all “client” gorutinas and contact him for every request - this leads to excessive CPU consumption by the rate-limiter himself, as well as increased time-sequence alternation of gorutin, which degrades the characteristics of RedisPipe at medium rps (but inexplicably improves on high);
b) use one rate-limiter on all the “client” gorutines and send requests in series - the rate-limiter no longer eats the CPU so much, but the alternation of the gorutins in time only increases;
c) use a rate limiter for each gorutina, but send the same series of 10 requests, - in this scenario, the gorutines wake up too simultaneously, which unfairly improves the results of RedisPipe.
Testing took place on the quad-core AWS c5-2xlarge instance. Redis Version 5.0.
The ratio of the desired intensity of requests, the resulting total intensity and consumed by radish cpu:
| intended rps | redigo rps /% cpu | redispipe no wait rps /% cpu | redispipe 50µs rps /% cpu | redispipe 150µs rps /% cpu |
|---|---|---|---|---|
| 1000 * 5 | 5015/7% | 5015/6% | 5015/6% | 5015/6% |
| 2000 * 5 | 10022/11% | 10022/10% | 10022/10% | 10022/10% |
| 4000 * 5 | 20036/21% | 20036/18% | 20035/17% | 20035/15% |
| 8000 * 5 | 40020/45% | 40062/37% | 40060/26% | 40056/19% |
| 16000 * 5 | 79994/71% | 80102/58% | 80096/33% | 80090/23% |
| 32,000 * 5 | 159590/96% | 160180/80% | 160167/39% | 160150/29% |
| 64000 * 5 | 187774/99% | 320313/98% | 320283/47% | 320258/37% |
| 92000 * 5 | 183206/99% | 480443/97% | 480407/52% | 480366/42% |
| 128,000 * 5 | 179744/99% | 640484/97% | 640488/55% | 640428/46% |
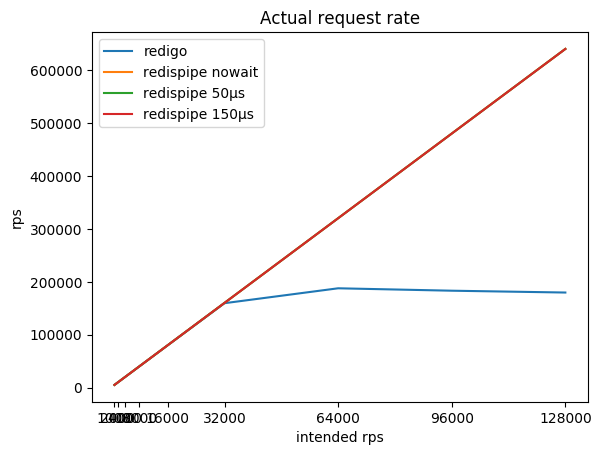
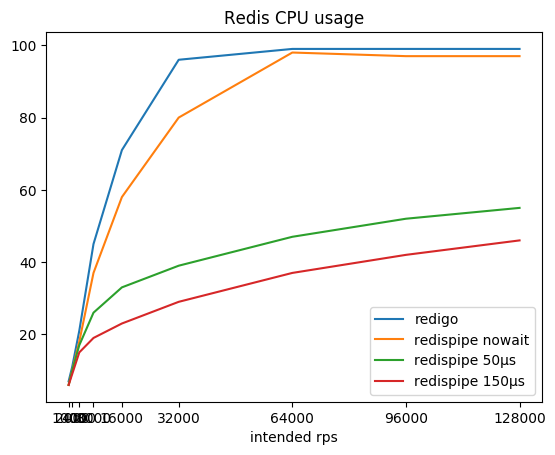
You can see that with the connector working in the classical scheme (request / answer + connection pool), the Redis pretty quickly survives the processor core, after which getting more than 190 krps becomes an impossible task.
RedisPipe also allows you to squeeze out all the required power from Redis. And the more we pause to collect parallel requests, the less Redis consumes CPU. The tangible benefit is obtained already at 4krps from the client (20krps in total), if a pause of 150 microseconds is used.
Even if the pause is clearly not used when Redis runs into the CPU, the delay appears by itself. In addition, requests begin to be buffered by the operating system. This allows RedisPipe to increase the number of successfully executed requests when the classic connector is already lowering the legs.
This is the main result for which it was required to create a new connector.
What happens with the consumption of CPU on the client and with the delay of requests?
| intended rps | redigo % cpu / ms | redispipe nowait % cpu / ms | redispipe 50ms % cpu / ms | redispipe 150ms % cpu / ms |
|---|---|---|---|---|
| 1000 * 5 | 13 / 0.03 | 20 / 0.04 | 46 / 0.16 | 44 / 0.26 |
| 2000 * 5 | 25 / 0.03 | 33 / 0.04 | 77 / 0.16 | 71 / 0.26 |
| 4000 * 5 | 48 / 0.03 | 60 / 0.04 | 124 / 0.16 | 107 / 0.26 |
| 8000 * 5 | 94 / 0.03 | 119 / 0.04 | 178 / 0.15 | 141 / 0.26 |
| 16000 * 5 | 184 / 0.04 | 206 / 0.04 | 228 / 0.15 | 177 / 0.25 |
| 32,000 * 5 | 341 / 0.08 | 322 / 0.05 | 280 / 0.15 | 226 / 0.26 |
| 64000 * 5 | 316 / 1.88 | 469 / 0.08 | 345 / 0.16 | 307 / 0.26 |
| 92000 * 5 | 313 / 2.88 | 511 / 0.16 | 398 / 0.17 | 366 / 0.27 |
| 128,000 * 5 | 312 / 3.54 | 509 / 0.37 | 441 / 0.19 | 418 / 0.29 |
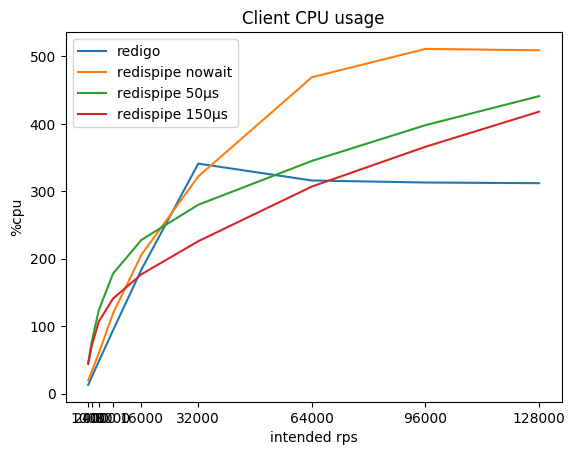
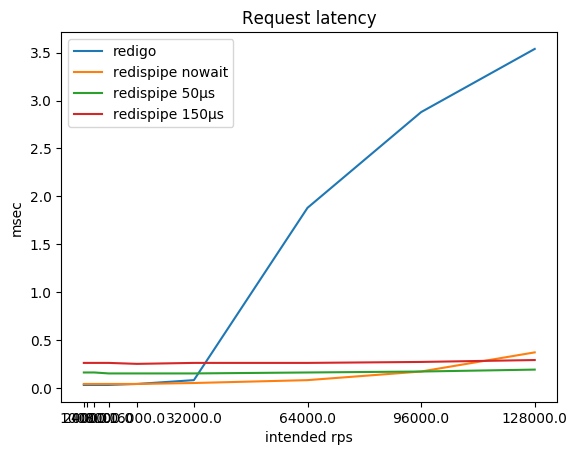
You may notice that on small rps RedisPipe itself consumes more CPU than the "competitor", especially if a short pause is used. This is mainly due to the implementation of timers in Go and the implementation of the system calls used in the operating system (on Linux, this is futexsleep), since the difference is noticeably smaller in the “no pause” mode.
As rps rises, the overhead of timers is compensated for by less network overhead, and after 16 krps per customer, using RedisPipe with a pause of 150 microseconds starts to bring tangible benefits.
Of course, after Redis rested in the CPU, the delay in requests using the classic connector begins to grow rampant. Not sure, though, that in practice you often reach 180 krps from a Redis instance. But if so, keep in mind that you may have problems.
While Redis does not run into the CPU, the delay in requests, of course, suffers from the use of a pause. This compromise is intentionally embedded in the connector. However, this trade-off is only noticeable if Redis and the client are on the same physical host. Depending on the network topology, a roundtrip to a neighboring host can be from one hundred microseconds to milliseconds. Accordingly, the difference in the delay, instead of nine times (0.26 / 0.03), becomes threefold (0.36 / 0.13) or measured only by a couple of tens of percent (1.26 / 1.03).
In our workload, when Redis is used as a cache, the total waiting for responses from the database with a cache miss is greater than the total waiting for responses from Redis, therefore it is considered that the increase in latency is not significant.
The main positive result is the tolerance to the growth of load: if suddenly the load on the service increases N times, Redis will not consume the CPU N times the same. To withstand load quadrupling from 160 krps to 640 krps, Redis spent only 1.6 times more CPU, increasing consumption from 29 to 46%. This allows us to not be afraid that Redis suddenly bends. The scalability of the application will also not be due to the work of the connector and the cost of networking (read: the cost of the SYS CPU).
Remark. The benchmark code operates on small values. To clear my conscience, I repeated the test with values of 768 bytes. The CPU consumption of “radish” has increased significantly (up to 66% at a pause of 150 µs), and the ceiling for the classic connector drops to 170 krps. But all the proportions seen remained the same, and therefore the conclusions.
Cluster
For scaling we use Redis Cluster . This allows us to use Redis not only as a cache, but also as a volatile storage and at the same time not losing data when expanding / compressing a cluster.
Redis Cluster uses the principle of a smart client, i.e. The client must monitor the status of the cluster on its own, as well as respond to auxiliary errors returned by the “radish” when the “bouquet” moves from the instance to the instance.
Accordingly, the client must keep connections to all Redis instances in the cluster and issue a connection to the necessary one for each request. And it is in this place that the client used before (we will not point with a finger) has screwed up badly. The author, who overestimated Go Marketing (CSP, channels, goroutines), implemented synchronization of work with the state of a cluster through sending callbacks to the central mountain. This has become a serious bottleneck for us. As a temporary patch, we had to run four clients to one cluster, each, in turn, lifted up to a hundred connections in the pool to each Redis instance.
Accordingly, in the new connector there was a task to prevent this error. All interaction with the state of the cluster in the path of the query is done as much as possible lock-free:
- the state of the cluster is made almost immutable, and not numerous mutations flavored with atoms
- access to the state occurs using atomic.StorePointer / atomic.LoadPointer, and therefore can be obtained without blocking.
Thus, even during a cluster state update, queries can use the previous state without fear of waiting for a lock.
// storeConfig atomically stores config func (c *Cluster) storeConfig(cfg *clusterConfig) { p := (*unsafe.Pointer)(unsafe.Pointer(&c.config)) atomic.StorePointer(p, unsafe.Pointer(cfg)) } // getConfig loads config atomically func (c *Cluster) getConfig() *clusterConfig { p := (*unsafe.Pointer)(unsafe.Pointer(&c.config)) return (*clusterConfig)(atomic.LoadPointer(p)) } func (cfg *clusterConfig) slot2shardno(slot uint16) uint16 { return uint16(atomic.LoadUint32(&cfg.slots[slot])) } func (cfg *clusterConfig) slotSetShard(slot, shard uint16) { atomic.StoreUint32(&cfg.slots[slot], shard) } The cluster status is updated every 5 seconds. But if there is a suspicion of cluster instability, the update is forced:
func (c *Cluster) control() { t := time.NewTicker(c.opts.CheckInterval) defer t.Stop() // main control loop for { select { case <-c.ctx.Done(): // cluster closed, exit control loop c.report(LogContextClosed{Error: c.ctx.Err()}) return case cmd := <-c.commands: // execute some asynchronous "cluster-wide" actions c.execCommand(cmd) continue case <-forceReload: // forced mapping reload c.reloadMapping() case <-tC: // regular mapping reload c.reloadMapping() } } } func (c *Cluster) ForceReloading() { select { case c.forceReload <- struct{}{}: default: } } If the answer MOVED or ASK, obtained from radish, contains an unknown address, it is initiated asynchronously added to the configuration. (I apologize, I didn’t think how to simplify the code, because here’s the link .) It’s not without the use of locks, but they are taken for a short period of time. The main expectation is realized through saving the callback in the array - the same future, side view.
Connections are established to all Redis instances, and to the masters, and to the slaves. Depending on the preferred policy and the type of request (read or write), the request can be sent both to the master and to the slave. This takes into account the "liveliness" of the instance, which consists of both the information obtained during the update of the cluster status and the current connection status.
func (c *Cluster) connForSlot(slot uint16, policy ReplicaPolicyEnum) (*redisconn.Connection, *errorx.Error) { var conn *redisconn.Connection cfg := c.getConfig() shard := cfg.slot2shard(slot) nodes := cfg.nodes var addr string switch policy { case MasterOnly: addr = shard.addr[0] // master is always first node := nodes[addr] if conn = node.getConn(c.opts.ConnHostPolicy, needConnected); conn == nil { conn = node.getConn(c.opts.ConnHostPolicy, mayBeConnected) } case MasterAndSlaves: n := uint32(len(shard.addr)) off := c.opts.RoundRobinSeed.Current() for _, needState := range []int{needConnected, mayBeConnected} { mask := atomic.LoadUint32(&shard.good) // load health information for ; mask != 0; off++ { bit := 1 << (off % n) if mask&bit == 0 { // replica isn't healthy, or already viewed continue } mask &^= bit addr = shard.addr[k] if conn = nodes[addr].getConn(c.opts.ConnHostPolicy, needState); conn != nil { return conn, nil } } } } if conn == nil { c.ForceReloading() return nil, c.err(ErrNoAliveConnection) } return conn, nil } func (n *node) getConn(policy ConnHostPolicyEnum, liveness int) *redisconn.Connection { for _, conn := range n.conns { switch liveness { case needConnected: if c.ConnectedNow() { return conn } case mayBeConnected: if c.MayBeConnected() { return conn } } } return nil } There is a mysterious RoundRobinSeed.Current() . This, on the one hand, is the source of chance, on the other - randomness that does not change often. If you choose a new connection for each request, it degrades the effectiveness of pipe-planning. That is why the default implementation changes the value of Current every several tens of milliseconds. In order for the time lags to be smaller, each host selects its own interval.
As you remember, the connection uses the concept of Future for asynchronous requests. The cluster uses the same concept: the user Future turns into a cluster one, and that one is fed to the connection.
Why wrap a custom future? Firstly, in Cluster mode, “radish” returns wonderful “errors” of MOVED and ASK with information where you need to go for the key you need, and, having received such an error, you need to repeat the request to another host. Secondly, since we still need to implement the redirection logic, then why not embed and re-repeat the request in case of an I / O error (of course, only if the read request):
type request struct { c *Cluster req Request cb Future slot uint16 policy ReplicaPolicyEnum mayRetry bool } func (c *Cluster) SendWithPolicy(policy ReplicaPolicyEnum, req Request, cb Future) { slot := redisclusterutil.ReqSlot(req) policy = c.fixPolicy(slot, req, policy) conn, err := c.connForSlot(slot, policy, nil) if err != nil { cb.Resolve(err) return } r := &request{ c: c, req: req, cb: cb, slot: slot, policy: policy, mayRetry: policy != MasterOnly || redis.ReplicaSafe(req.Cmd), } conn.Send(req, r, 0) } func (r *request) Resolve(res interface{}, _ uint64) { err := redis.AsErrorx(res) if err == nil { r.resolve(res) return } switch { case err.IsOfType(redis.ErrIO): if !r.mayRetry { // It is not safe to retry read-write operation r.resolve(err) return } fallthrough case err.HasTrait(redis.ErrTraitNotSent): // It is request were not sent at all, it is safe to retry both readonly and write requests. conn, err := rcconnForSlot(r.slot, r.policy, r.seen) if err != nil { r.resolve(err) return } conn.Send(r.req, r) return case err.HasTrait(redis.ErrTraitClusterMove): addr := movedTo(err) ask := err.IsOfType(redis.ErrAsk) rcensureConnForAddress(addr, func(conn *redisconn.Connection, cerr error) { if cerr != nil { r.resolve(cerr) } else { r.lastconn = conn conn.SendAsk(r.req, r, ask) } }) return default: // All other errors: just resolve. r.resolve(err) } } This is also a simplified code. Omitted a restriction in the number of replays, memorization of problem connections, etc.
Comfort
Asynchronous requests, Future is a superkul! But terribly uncomfortable.
The interface is the most important thing. You can sell anything if he has a nyashny interface. That is why Redis and MongoDB gained their popularity.
So, it is required to turn our asynchronous requests into synchronous ones.
// Sync provides convenient synchronous interface over asynchronous Sender. type Sync struct { S Sender } // Do is convenient method to construct and send request. // Returns value that could be either result or error. func (s Sync) Do(cmd string, args ...interface{}) interface{} { return s.Send(Request{cmd, args}) } // Send sends request to redis. // Returns value that could be either result or error. func (s Sync) Send(r Request) interface{} { var res syncRes res.Add(1) sSSend(r, &res) res.Wait() return res.r } type syncRes struct { r interface{} sync.WaitGroup } // Resolve implements Future.Resolve func (s *syncRes) Resolve(res interface{}) { sr = res s.Done() } // Usage func get(s redis.Sender, key string) (interface{}, error) { res := redis.Sync{s}.Do("GET", key) if err := redis.AsError(res); err != nil { return nil, err } return res, nil } AsError does not look like a native go-way to get an error. But I like, because in my view, the result is Result<T,Error> , and AsError is an ersatz match pattern.
disadvantages
But, unfortunately, there is a spoon of tar in this well-being.
Redis protocol does not involve reordering requests. And at the same time, it has blocking queries of the type BLPOP, BRPOP.
This is a failure.
As you understand, if such a request is blocked, it will block all requests following it. And nothing can be done about it.
After a long discussion, it was decided to prohibit the use of these requests in RedisPipe.
Of course, if you really need to, you can: set the ScriptMode: true parameter ScriptMode: true , and everything is on your conscience.
Alternatives
In fact, there is another alternative, which I did not mention, but which the well-informed readers thought about - the king of cluster twemproxy caches.
It does what Reds does for Redis: it transforms a rude and soulless “request / response” into a gentle “pipeline”.
But twemproxy itself will suffer from the fact that he will have to work on the system "request / response." This time. And secondly, we use “radishes” including as “unreliable storage” and sometimes change the size of the cluster. And twemproxy does not facilitate the task of rebalancing in any way and, moreover, requires a reboot when changing the cluster configuration.
Influence
I did not have time to write an article, and the waves from RedisPipe have already gone. In Radix.v3, a patch was adopted, adding pipelaying to their Pool:
Impact redisPipe and figure out
Automatic pipelining for commands in Pool
In speed, they are slightly inferior (judging by their benchmarks; but I will not say for sure). But their advantage is that they can send blocking commands to other connections from the pool.
Conclusion
Soon a year, as RedisPipe contributes to the effectiveness of our service.
And on the threshold of any “hot days”, one of the resources whose capacity does not cause concern is the CPU on the Redis servers.
Source: https://habr.com/ru/post/438026/