The evolution of context switching x86 in Linux

Last weekend, while studying the interesting facts about the 80386 hardware context switch, I suddenly remembered that the first versions of the Linux kernel relied on it. And I plunged into a code that I had not seen for many years. Now I decided to describe this wonderful journey through the history of Linux. I will show all the nuggets and funny artifacts that I found along the way.
Task: to trace how the context switch in the Linux kernel changed from the first (0.01) to the latest version of LTS (4.14.67), with particular emphasis on the first and last versions.
- Early Linux: Ancient History
- Linux 1.0: proof of concept
- Linux 2.0: Candidate
- Linux 2.6: popularity
- Linux 3.0: Modern OS
- Linux 4.14.67: Latest LTS
In fact, the story is not about context switching, but about the evolution of Linux from a small project to a modern operating system. The context switch simply reflects this story.
What kind of context switching are we talking about?
Although there is a lot that can be seen as context switching (for example, switching to kernel mode, switching to an interrupt handler), I mean the common meaning: switching between processes . In Linux, this is the macro
switch_to() and everything in it.This macro is a simple mechanical action between two much more interesting systems: a task scheduler and a CPU. OS developers have the ability to mix and align task scheduling strategies. CPU architectures are also wide open: Linux supports dozens of types. But the context switch is the gear between them. Its “design” depends on its neighbors, so the context switch claims to be the least interesting part of the OS. I repeat: he does only what needs to be done.
A short list of context switch tasks:
- Redesigning the workspace: restoring the stack (SS: SP).
- Search for the following instruction: IP recovery (CS: IP).
- Restore task status: restore general purpose registers.
- Swapping Memory Address Spaces: Updating Page Directory (CR3)
- ... and much more: FPU, OS data structures, debug registers, hardware workarounds, etc.
It is not always obvious when and where these tasks are performed, if another process captures the CPU. For example, hardware context switching before Linux 2.2 hides tasks 2, 3, and 4. Task 3 is limited, since switching occurs between kernel modes. Restoring a user thread is an
iret task after returning the scheduler. Many of these tasks in different versions of the kernel float between switch_to() and the scheduler. You can only guarantee that in each version we will always see a stack swap and FPU switching.Who is it for?
For no one specifically. To understand, you only need to know x86 assembler and, probably, have a minimal education in terms of OS design.
At once I will say that I am not a maintainer and a contributor to the Linux kernel. Any information from these comrades or from the kernel developer mailing list , which contradicts my information, should be taken seriously. I have a random personal project, not a scientific article in a peer-reviewed journal.
Early Linux up to 1.0: ancient history (1991)
The early Linux kernel is simple and functional, with a small list of key features:
- The only architecture (80386 / i386): only one type of context switch. Many features of the 80386 are hard coded across the core. For reference on these parts, I have taken the Intel 80386 Programmer's Guide (1986).
- Hardware context switching: the kernel uses 80386 built-in mechanisms to change tasks.
- One process with preemptive multitasking: only one CPU with one process is active at a time. However, another process may begin at any time. Thus, the usual synchronization rules apply: blocking shared resources (without spinlocks). In the extreme case, it is possible to disable interrupts, but first consider locking the mutex.

Without further ado, take a look at two early context switches. The code is formatted for better readability: one element per line without continuation characters (\).
Linux 0.01
/** include/linux/sched.h */ #define switch_to(n) { struct {long a,b;} __tmp; __asm__("cmpl %%ecx,_current\n\t" "je 1f\n\t" "xchgl %%ecx,_current\n\t" "movw %%dx,%1\n\t" "ljmp %0\n\t" "cmpl %%ecx,%2\n\t" "jne 1f\n\t" "clts\n" "1:" ::"m" (*&__tmp.a), "m" (*&__tmp.b), "m" (last_task_used_math), "d" _TSS(n), "c" ((long) task[n])); } Linux 0.11
/** include/linux/sched.h */ #define switch_to(n) { struct {long a,b;} __tmp; __asm__("cmpl %%ecx,_current\n\t" "je 1f\n\t" "movw %%dx,%1\n\t" "xchgl %%ecx,_current\n\t" "ljmp %0\n\t" "cmpl %%ecx,_last_task_used_math\n\t" "jne 1f\n\t" "clts\n" "1:" ::"m" (*&__tmp.a), "m" (*&__tmp.b), "d" (_TSS(n)), "c" ((long) task[n])); } Immediately striking how small he is! Small enough to make out each line separately:
#define switch_to(n) { So,
switch_to() is a macro. It appears in exactly one place: in the very last line of schedule() . Therefore, after preprocessing, the macro shares the scheduler area. Checking in the global area of unknown references, such as current and last_task_used_math . The input argument n is the sequence number of the next task (from 0 to 63). struct {long a,b;} __tmp; Reserves 8 bytes (64 bits) per stack, accessible via two 4-byte elements
a and b . We will set some of these bytes later for the long-range transition operation. __asm__("cmpl %%ecx,_current\n\t" Context switch is one long inline assembly block. The first statement determines whether the target is already current. This is a subtractive comparison of the value in the ECX register with the value of the current
current from the scheduler. Both contain pointers to the task_struct a process. Below in ECX is the target task pointer as the specified input: "c" ((long) task[n]) . The result of the comparison sets the value of the state register EFLAGS: for example, ZF = 1, if both pointers are the same (x - x = 0). "je 1f\n\t" If the next task is the current one, you do not need to switch the context, so you should skip (jump over) the whole procedure. The
je instruction verifies that ZF = 1. If this is the case, it goes to the first label '1' after this point in the code, which is 8 lines ahead. "xchgl %%ecx,_current\n\t" Updates the global
current to reflect the new task. The pointer from ECX (task [n]) switches to current. Flags are not updated. "movw %%dx,%1\n\t" Moves the index of the target task descriptor segment selector (TSS) to a previously reserved space. Technically, this moves the value from the DX register to
__tmp.b , that is, bytes 5 through 8 of our reserved 8-byte structure. The DX value is the specified input: "d" (_TSS(n)) . The _TSS multi-level macro _TSS expanded into a valid TSS segment selector, which I will discuss below. The bottom line is that the two high bytes of __tmp.b now contain a segment pointer to the next task. "ljmp %0\n\t" Calls the hardware context switch 80386 by going to the TSS handle. This simple transition can be confusing, because there are three different ideas: first,
ljmp is an indirect long-range transition that needs a 6-byte (48-bit) operand. Second, operand% 0 refers to the uninitialized variable __tmp.А . Finally, the transition to the segment selector in GDT has a special meaning in x86. Let's take a look at these moments.Indirect far transition
The important point is that this transition has a 6-byte operand. The 80386 Programmer's Guide describes the transition as follows:

Go to __tmp.a
Recall that the
__tmp structure contained two 4-byte values, and the structure is based on the a element. But if we use this element as the base address of the 6-byte operand, we will reach two bytes inside the integer __tmp.b . These two bytes are part of the “segment selector” of the far address. When the processor sees that the segment is a TSS in the GDT, the offset portion is completely ignored. The fact that __tmp.a is not initialized does not matter, because __tmp.b still has a valid value due to the previous instruction movw . Add the address of the transition to the chart:
How do we know that this address refers to GDT? I will reveal the details in other lines of code, but the short version is that the four null bits in the selector start the GDT search. The
_TSS(n) macro ensures the presence of these four zeros. The lower two bits are the segment privilege level (00 corresponds to supervisor / kernel), the next zero bit means using the GDT table (stored in the GDTR during system boot). The fourth zero is technically part of the segment index, which forces all TSS searches on the even entries of the GDT table.Hardware context switch
The jump address in
__tmp defines the TSS descriptor in the GDT. Here is how it is described in the manual for 80386:
The processor automatically does the following for us:
- Checks whether the current privilege level is allowed (we are in kernel mode, so everything is fine).
- Verifies that the TSS is valid (must be).
- Saves all the current task status in the old TSS, still stored in the task register (TR), so no need to use EAX, ECX, EDX, EBX, ESP, EBP, ESI, EDI, ES, CS, SS, DS, FS, GS and EFLAGS. EIP is increased to the next instruction and also saved.
- Updates TR for new task.
- Restores all general purpose registers, EIP and PDBR (swap address space). The task switcher has completed its work, so the TS flag is set in the CR0 register.
This is how the only instruction
"ljmp %0\n\t" took and executed all the steps of context switching. It remains only to tidy up a bit. "cmpl %%ecx,%2\n\t" We check that the previous task restored the math coprocessor. The argument is the
last_task_used_math pointer. The TS flag helps to check whether the coprocessor has a different context. Hardware context switches do not control the coprocessor. "jne 1f\n\t" If the last task did not restore the coprocessor, go to the end of the context switch. We want to leave the TS flag so that the next time you use the coprocessor you can perform a lazy cleanup. “Lazy” because we postpone the task until it becomes absolutely necessary.
"clts\n" We remove the TS flag if the last process has restored the state of the coprocessor.
"1:" The end label of the context switch. All transitions to this label skip some or all of the procedures.
::"m" (*&__tmp.a), In this assembly block, there is no output, and the first input data (% 0) is the location in memory of the first four bytes of the long pointer to the TSS descriptor in the GDT. It is used only as a link to an address, the value is uninitialized.
"m" (*&__tmp.b), The second input (% 1) is the location in byte memory 5 and 6 of the far pointer to the TSS descriptor. Technically, this place is four bytes in memory, but only the first two are checked and used.
"m" (last_task_used_math), The third input (% 2) is the location in memory of a pointer to the last
task_struct that restored the state of the coprocessor. "d" (_TSS(n)), The fourth input (% 3 / %% edx) is the address of the TSS descriptor segment selector in the GDT. Let's analyze the macro:
#define _TSS(n) ((((unsigned long) n)<<4)+(FIRST_TSS_ENTRY<<3)) #define FIRST_TSS_ENTRY 4 This means that the first TSS descriptor is the 4th record (the index begins on the 4th bit of the segment selector). Each subsequent TSS takes up every other GDT record: 4, 6, 8, etc. The first eight tasks look like this:
| Task # | 16-bit Segment Selector |
|---|---|
| 0 | 0000000000100 0 00 |
| one | 0000000000110 0 00 |
| 2 | 0000000001000 0 00 |
| 3 | 0000000001010 0 00 |
| four | 0000000001100 0 00 |
| five | 0000000001110 0 00 |
| 6 | 0000000010000 0 00 |
| 7 | 0000000010010 0 00 |
The address bits are separated by the field format, as it should be in 80386:

The four low-order bits are always zero, which corresponds to the supervisor mode, the GDT table, and forces the even entries of the GDT index.
"c" ((long) task[n])); The last entry (% 4 /% ecx) is a pointer to a new task_struct that we are switching to. Notice that the %% ecx value changes to the previous task just before the context switch.
Differences between 0.01 and 0.11
There are two differences between context switches. One of them is simple cleaning of the code, and the other is a partial correction of the error.
_last_task_used_mathremoved as an input variable because the character is already available in the global scope. The corresponding comparison operation is changed to a direct link.- The
xchglinstruction swapped withmovwto bring it closer to the hardware context switch (ljmp). The problem is that these operations are not atomic: it is unlikely that an interrupt may occur betweenxchglandljmp, which will lead to another context switch with an incorrectcurrenttask and an unsaved state of the real task. Replacing these instructions in places makes such a situation very unlikely. However, in a long-running system, “very unlikely” is a synonym for “inevitable”.
Linux 1.x: proof of concept
About 20 patches came out in about a year between 0.11 and 1.0. The main part of the effort was focused on drivers, functions for users and developers. The maximum number of tasks increased to 128, but not many fundamental changes took place in the context switch.
Linux 1.0
Linux 1.0 still runs on the same CPU with a single process, using hardware context switching.

Linux 1.0
/** include/linux/sched.h */ #define switch_to(tsk) __asm__("cmpl %%ecx,_current\n\t" "je 1f\n\t" "cli\n\t" "xchgl %%ecx,_current\n\t" "ljmp %0\n\t" "sti\n\t" "cmpl %%ecx,_last_task_used_math\n\t" "jne 1f\n\t" "clts\n" "1:" : /* no output */ :"m" (*(((char *)&tsk->tss.tr)-4)), "c" (tsk) :"cx") The most significant change is that the input argument is no longer the index of the task number for the array of task_struct structures. Now
switch_to() takes a pointer to a new task. So you can remove the __tmp structure, and instead use a direct link to the TSS. Let's sort out each line. #define switch_to(tsk) Input is now a pointer to the task_struct of the next task.
"__asm__("cmpl %%ecx,_current\n\t" Has not changed. Checks whether the input task is already current, so the switch is not required.
"je 1f\n\t" Has not changed. Skip the context switch if the switch is absent.
"cli\n\t" Disables interrupts so that the timer (or someone else) does not crash between updating a global task and hardware context switching. This interrupt banhammer solves the problem of earlier kernel versions, making the following two instructions (pseudo) atomic.
"xchgl %%ecx,_current\n\t" "ljmp %0\n\t" No change: swap the current process to reflect the new task and call the hardware context switch.
"sti\n\t" Enable interrupts back.
"cmpl %%ecx,_last_task_used_math\n\t" "jne 1f\n\t" "clts\n" "1:" Everything is unchanged from Linux 0.11. Manages the TS register and tracks the math coprocessor clearing from the previous task.
: /* no output */ This built-in assembler has no output - someone is clearly annoyed by the lack of comments in earlier versions of the kernel.
:"m" (*(((char *)&tsk->tss.tr)-4)), Loads the segment selector for the TSS handle of the new task, which is now directly accessible from the task_struct pointer. The
tss.tr element contains _TSS (task_number) for the GDT / TSS memory reference, which was used in the kernel up to 1.0. We are still retreating 4 bytes and loading the 6-byte segment selector to take the top two bytes. Fun! "c" (tsk) Almost unchanged - now we directly load the pointer, rather than looking for an index.
:"cx") Context switching blocks the ECX register.
Linux 1.3
The kernel now supports several new architectures: Alpha, MIPS and SPARC. Therefore, there are four different versions of
switch_to() , one of which is included when the kernel is compiled. The architecture-dependent code was separated from the kernel, so you need to look for the x86 version elsewhere.Linux 1.3
/** include/asm-i386/system.h */ #define switch_to(tsk) do { __asm__("cli\n\t" "xchgl %%ecx,_current\n\t" "ljmp %0\n\t" "sti\n\t" "cmpl %%ecx,_last_task_used_math\n\t" "jne 1f\n\t" "clts\n" "1:" : /* no output */ :"m" (*(((char *)&tsk->tss.tr)-4)), "c" (tsk) :"cx"); /* Now maybe reload the debug registers */ if(current->debugreg[7]){ loaddebug(0); loaddebug(1); loaddebug(2); loaddebug(3); loaddebug(6); } } while (0) A few small changes: the entire context switch is wrapped in a fake do-while loop. Fake, because he never repeats. The switch test for a new task has moved from
switch_to() to the sheduler code on C. Some debugging tasks have been moved from C code to switch_to () , probably to avoid separating them. Let's look at the changes. #define switch_to(tsk) do { Now
switch_to() wrapped in a do-while (0) loop. This construct prevents errors if the macro expands to several statements as a consequence of the condition (if it exists). Currently it is not there, but given the changes in the scheduler, I suspect that this is the result of the code editing, left just in case. My suggestion:Real scheduler at 1.3
...within schedule()... if (current == next) return; kstat.context_swtch++; switch_to(next); Possible variant that breaks switch_to ()
...within schedule()... if (current != next) switch_to(next); /* do-while(0) 'captures' entire * block to ensure proper parse */ __asm__("cli\n\t" "xchgl %%ecx,_current\n\t" "ljmp %0\n\t" "sti\n\t" "cmpl %%ecx,_last_task_used_math\n\t" "jne 1f\n\t" "clts\n" "1:" : /* no output */ :"m" (*(((char *)&tsk->tss.tr)-4)), "c" (tsk) :"cx"); No change from Linux 1.0. As before, interrupts are disabled before * task_struct from
current swap, then a hardware context switch is activated and the use of the coprocessor is checked. /* Now maybe reload the debug registers */ if(current->debugreg[7]){ It checks the debug control for the new process for active ptrace (a non-zero address here implies active ptrace). Debug tracking has moved to
switch_to() . Exactly the same sequence C is used in 1.0. I guess the developers wanted to make sure that: 1) debugging is as close as possible to the context switch 2) switch_to is the latest in schedule() . loaddebug(0); loaddebug(1); loaddebug(2); loaddebug(3); Restores the debug breakpoint registers from the saved ptrace state.
loaddebug(6); Restores the debug control register from the saved ptrace state.
} while (0) Closes the
switch_to() block. Although the condition is always the same, it guarantees that the parser takes the function as a base unit that does not interact with the neighboring conditions in schedule() . Note the absence of a comma at the end - it is after the macro is called: switch_to(next); .Linux 2.0: Candidate (1996)
In June 1996, the kernel was updated to version 2.0, starting a 15-year odyssey under this basic version, which ended with extensive commercial support. At 2.x, almost all the fundamental systems in the kernel underwent radical changes. Consider all minor releases before release 2.6. Version 2.6 has been developed for so long that it deserves a separate section.
Linux 2.0
Linux 2.0 began with a fundamental innovation: multiprocessing ! Two or more processors can simultaneously process user / kernel code. Naturally, this required some work. For example, each processor now has a dedicated interrupt controller, APIC, so interrupts must be managed on each processor separately. It is necessary to rework mechanisms such as interrupting a timer (disabling interrupts affects only one processor). Synchronization is difficult, especially when trying to apply it to an already large and unrelated code base. Linux 2.0 lays the groundwork for what will become a big kernel lock (BKL) ... something has to start.
Now we have two versions of
switch_to() : a single-processor version (UP) of Linux 1.x and a new improved version for symmetric multiprocessing (SMP). First, let's consider the edits in the old code, because some changes from there are also included in the SMP version.Linux 2.0.1: single processor version (UP)

Linux 2.0.1 (UP)
/** include/asm-i386/system.h */ #else /* Single process only (not SMP) */ #define switch_to(prev,next) do { __asm__("movl %2,"SYMBOL_NAME_STR(current_set)"\n\t" "ljmp %0\n\t" "cmpl %1,"SYMBOL_NAME_STR(last_task_used_math)"\n\t" "jne 1f\n\t" "clts\n" "1:" : /* no outputs */ :"m" (*(((char *)&next->tss.tr)-4)), "r" (prev), "r" (next)); /* Now maybe reload the debug registers */ if(prev->debugreg[7]){ loaddebug(prev,0); loaddebug(prev,1); loaddebug(prev,2); loaddebug(prev,3); loaddebug(prev,6); } } while (0) #endif Two changes are immediately obvious:
- We have
switch_to()a new argument: the process*task_structfrom which we are switching. - Macro for proper handling of characters in inline assembly.
As usual, let's go through the lines and discuss the changes.
#define switch_to(prev,next) do { The argument
prevspecifies the task with which we switch ( *task_struct). We still wrap the macro in a do-while (0) loop to help parse the single-line if around the macro. __asm__("movl %2,"SYMBOL_NAME_STR(current_set)"\n\t" Updates the current active task to the new selected one. This is functionally equivalent
xchgl %%ecx,_currentexcept for the fact that we now have an array of several task_struct and a macro ( SYMBOL_NAME_STR) for processing inline assembly symbols. Why use a preprocessor for this? The fact is that some assemblers (GAS) require adding an underscore character (_) to the name of the variable C. Other assemblers do not have such a requirement. In order not to drive the convention hard, you can customize it during compilation according to your set of tools. "ljmp %0\n\t" "cmpl %1,"SYMBOL_NAME_STR(last_task_used_math)"\n\t" "jne 1f\n\t" "clts\n" "1:" : /* no outputs */ :"m" (*(((char *)&next->tss.tr)-4)), No changes that we haven't talked about yet.
"r" (prev), "r" (next)); We now carry both tasks as input to the inline assembler. One of the minor changes - now any use of the register is allowed.
nextWas previously encoded in ECX. /* Now maybe reload the debug registers */ if(prev->debugreg[7]){ loaddebug(prev,0); loaddebug(prev,1); loaddebug(prev,2); loaddebug(prev,3); loaddebug(prev,6); } } while (0) Everything is exactly as in kernel 1.3.
Linux 2.0.1: multiprocessor version (SMP)

Linux 2.0.1 (SMP)
/** include/asm-i386/system.h */ #ifdef __SMP__ /* Multiprocessing enabled */ #define switch_to(prev,next) do { cli(); if(prev->flags&PF_USEDFPU) { __asm__ __volatile__("fnsave %0":"=m" (prev->tss.i387.hard)); __asm__ __volatile__("fwait"); prev->flags&=~PF_USEDFPU; } prev->lock_depth=syscall_count; kernel_counter+=next->lock_depth-prev->lock_depth; syscall_count=next->lock_depth; __asm__("pushl %%edx\n\t" "movl "SYMBOL_NAME_STR(apic_reg)",%%edx\n\t" "movl 0x20(%%edx), %%edx\n\t" "shrl $22,%%edx\n\t" "and $0x3C,%%edx\n\t" "movl %%ecx,"SYMBOL_NAME_STR(current_set)"(,%%edx)\n\t" "popl %%edx\n\t" "ljmp %0\n\t" "sti\n\t" : /* no output */ :"m" (*(((char *)&next->tss.tr)-4)), "c" (next)); /* Now maybe reload the debug registers */ if(prev->debugreg[7]){ loaddebug(prev,0); loaddebug(prev,1); loaddebug(prev,2); loaddebug(prev,3); loaddebug(prev,6); } } while (0) What, it is already becoming incomprehensible? I would like to say that later it will be better, but this will not happen in the SMP world. To save space, I will no longer list unchanged lines.
Three additions for the SMP context switch: 1) Changing the way a single coprocessor works with multiple processors; 2) Managing the depth of the lock, since the kernel lock is recursive; 3) Link to APIC to get the CPU ID for the current * task_struct.
if(prev->flags&PF_USEDFPU) Verifies that the task with which we are switching, used the coprocessor. If so, then you need to capture the context in the FPU before switching.
__asm__ __volatile__("fnsave %0":"=m" (prev->tss.i387.hard)); Saves the state of the FPU in the TSS. FNSAVE is used to skip exception handling.
__volatile__should protect this instruction from being modified by the optimizer. __asm__ __volatile__("fwait"); Waiting for the CPU while the FPU is busy with the previous save.
prev->flags&=~PF_USEDFPU; Disables the use of the coprocessor for this task, there is always zero.
prev->lock_depth=syscall_count; Stores the number of nested kernel lock uses for the old task.
kernel_counter+=next->lock_depth-prev->lock_depth; Updates the global kernel lock count to the next task minus the old task. Effectively removes the lock from the now inactive old task, and the new task can continue to work from where it left off.
syscall_count=next->lock_depth; Returns the lock status of the new task. It should be where she stopped at the last time interval.
__asm__("pushl %%edx\n\t" We are going to use EDX, so we will keep its current value.
"movl "SYMBOL_NAME_STR(apic_reg)",%%edx\n\t" Moves the APIC I / O address to EDX. We need to use APIC to get the CPU ID, since we do not know which processor is running.
apic_regbroadcast during OS initialization. "movl 0x20(%%edx), %%edx\n\t" It dereferences the value of the APIC identifier register to EDX. The actual ID is in bits 24-27.

"shrl $22,%%edx\n\t" Shifts the APIC ID in bits 2-5.
"and $0x3C,%%edx\n\t" Masks only the APIC ID in bits 2-5, leaving the CPU number * 4.
"movl %%ecx,"SYMBOL_NAME_STR(current_set)"(,%%edx)\n\t" Updates the current CPU task pointer to the next task. In the UP version, the specific use of ECX for storing the current task has already been removed, but in the SMP version it is still used. EDX contains the CPU number in bits 2–5, multiplied by 4, in scale to offset the pointer size from _current_set.
"popl %%edx\n\t" We are done with EDX, so we will restore the value that was before this procedure.
The remaining lines are the same.
Linux 2.2 (1999)
Linux 2.2 was really worth the wait: software context switching appeared here ! We still use the task register (TR) to refer to the TSS. The SMP and UP procedures are combined with unified FPU state processing. Most context switching is now performed in C code.
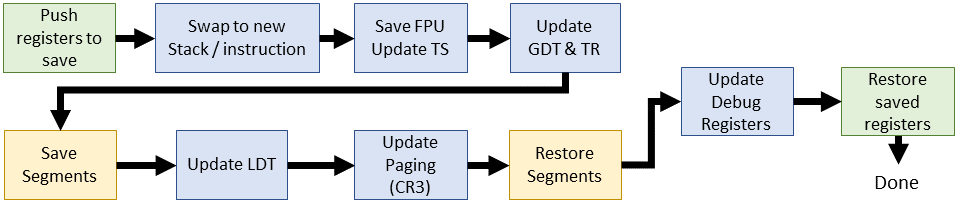
Linux 2.2.0 (inline assembler)
/** include/asm-i386/system.h */ #define switch_to(prev,next) do { unsigned long eax, edx, ecx; asm volatile("pushl %%ebx\n\t" "pushl %%esi\n\t" "pushl %%edi\n\t" "pushl %%ebp\n\t" "movl %%esp,%0\n\t" /* save ESP */ "movl %5,%%esp\n\t" /* restore ESP */ "movl $1f,%1\n\t" /* save EIP */ "pushl %6\n\t" /* restore EIP */ "jmp __switch_to\n" "1:\t" "popl %%ebp\n\t" "popl %%edi\n\t" "popl %%esi\n\t" "popl %%ebx" :"=m" (prev->tss.esp),"=m" (prev->tss.eip), "=a" (eax), "=d" (edx), "=c" (ecx) :"m" (next->tss.esp),"m" (next->tss.eip), "a" (prev), "d" (next)); } while (0) This new one is
switch_to()radically different from all previous versions: it's simple! In the inline assembler, we interchange the stack and instruction pointers (context switching tasks 1 and 2). Everything else is done after the transition to the code C ( __switch_to()). asm volatile("pushl %%ebx\n\t" "pushl %%esi\n\t" "pushl %%edi\n\t" "pushl %%ebp\n\t" Stores EBX, ESI, EDI and EBP in the stack of the process that we are going to swap. (... why EBX?)
"movl %%esp,%0\n\t" /* save ESP */ "movl %5,%%esp\n\t" /* restore ESP */ As is clear from the comments, we swap the stack pointers between the old and the new process. The old process has operand% 0 (
prev->tss.esp), and the new one has% 5 ( next->tss.esp). "movl $1f,%1\n\t" /* save EIP */ Saving the value of the instruction pointer for the next instruction of the old task after the context switch back. Note that the value of the following instruction uses a label
1: "pushl %6\n\t" /* restore EIP */ Preparing the next instruction for a new task. Since we have just switched to a new stack, this IP is taken from the TSS of the new task and placed on top of the stack. Execution will start with the next instruction after 'ret' from the C code that we are going to execute.
"jmp __switch_to\n" Moving on to our new and improved software context switch (see below).
"popl %%ebp\n\t" "popl %%edi\n\t" "popl %%esi\n\t" "popl %%ebx" We restore registers from the stack in reverse order, presumably after switching to the old task in the new time interval.
Linux 2.2.0 (C)
/** arch/i386/kernel/process.c */ void __switch_to(struct task_struct *prev, struct task_struct *next) { /* Do the FPU save and set TS if it wasn't set before.. */ unlazy_fpu(prev); gdt_table[next->tss.tr >> 3].b &= 0xfffffdff; asm volatile("ltr %0": :"g" (*(unsigned short *)&next->tss.tr)); asm volatile("movl %%fs,%0":"=m" (*(int *)&prev->tss.fs)); asm volatile("movl %%gs,%0":"=m" (*(int *)&prev->tss.gs)); /* Re-load LDT if necessary */ if (next->mm->segments != prev->mm->segments) asm volatile("lldt %0": :"g" (*(unsigned short *)&next->tss.ldt)); /* Re-load page tables */ { unsigned long new_cr3 = next->tss.cr3; if (new_cr3 != prev->tss.cr3) asm volatile("movl %0,%%cr3": :"r" (new_cr3)); } /* Restore %fs and %gs. */ loadsegment(fs,next->tss.fs); loadsegment(gs,next->tss.gs); if (next->tss.debugreg[7]){ loaddebug(next,0); loaddebug(next,1); loaddebug(next,2); loaddebug(next,3); loaddebug(next,6); loaddebug(next,7); } } In the software context switch, the old transition to the TSS descriptor was replaced with the transition to the new C: function
__switch_to(). This function is written in C and includes several familiar components, such as debug registers. Going to code C allows you to move them even closer to the context switch. unlazy_fpu(prev); We check the use of the FPU and save its state if it was used. Now this happens for each process that the FPU used, so cleaning is no longer lazy. The procedure is the same as the SMP routine from 2.0.1, except for the fact that we now have a clean macro, which includes manual TS tuning.
gdt_table[next->tss.tr >> 3].b &= 0xfffffdff; Clears the BUSY bit for a future task descriptor. Uses task number to index GDT.
tss.trcontains the value of the task segment selector, where permissions use the bottom three bits. We only need an index, so we shift these bits. The second byte of the TSS is modified to remove bit 10.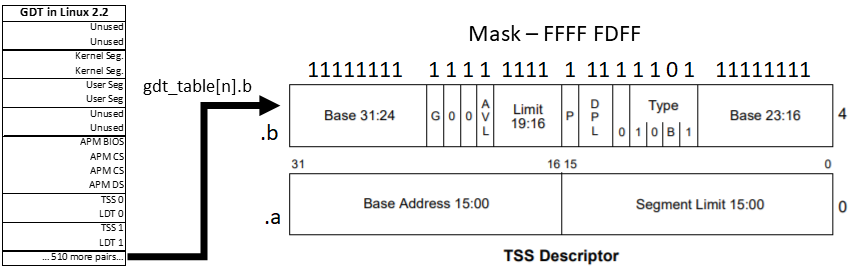
asm volatile("ltr %0": :"g" (*(unsigned short *)&next->tss.tr)); The task register is loaded with a pointer to the next task segment selector.
asm volatile("movl %%fs,%0":"=m" (*(int *)&prev->tss.fs)); asm volatile("movl %%gs,%0":"=m" (*(int *)&prev->tss.gs)); The FS and GS segment registers for the previous task are stored in the TSS. In the hardware context switch, this step was performed automatically, but now we need to do it manually. But why? How does Linux use FS and GS?
In Linux 2.2 (1999) there is no clear answer. It is only said that they are used, so you should save them so that they remain accessible. Kernel-mode code will “borrow” these segments to point to kernel or user data segments. Sound and network drivers do the same. Recently (~ 2.6 and later) FS and GS often support local stream storage and data areas for each processor, respectively.
if (next->mm->segments != prev->mm->segments) asm volatile("lldt %0": :"g" (*(unsigned short *)&next->tss.ldt)); Restores segments of the local descriptor table, if they do not yet correspond to the old process. This is done by loading the LDT register.
if (new_cr3 != prev->tss.cr3) asm volatile("movl %0,%%cr3": :"r" (new_cr3)); Updates the virtual memory state for the new task. Specifically, the CR3 register is set, which contains the page directory for memory access in the new context.
loadsegment(fs,next->tss.fs); loadsegment(gs,next->tss.gs); FS and GS are restored for the new task. This ensures proper alignment, and in case of a problem, the zero segment is loaded.
loaddebug(prev,7); Finally, the debug control register is now stored and switched using TSS. Previously, this register was only checked, and not used for storage.
Linux 2.4 (2001)
In version 2.4, many new features have appeared, such as kernel threads and task queues. Despite this and a few changes in the scheduler, the context switch remained almost unchanged compared to version 2.2, although it stopped updating the TR in favor of replacing all the register data. I unofficially call it the “latest legacy kernel,” since all the following releases use the x86 x86 architecture.

Linux 2.4.0 (inline assembler)
/** include/asm-i386/system.h */ #define switch_to(prev,next,last) do { asm volatile("pushl %%esi\n\t" "pushl %%edi\n\t" "pushl %%ebp\n\t" "movl %%esp,%0\n\t" /* save ESP */ "movl %3,%%esp\n\t" /* restore ESP */ "movl $1f,%1\n\t" /* save EIP */ "pushl %4\n\t" /* restore EIP */ "jmp __switch_to\n" "1:\t" "popl %%ebp\n\t" "popl %%edi\n\t" "popl %%esi\n\t" :"=m" (prev->thread.esp),"=m" (prev->thread.eip), "=b" (last) :"m" (next->thread.esp),"m" (next->thread.eip), "a" (prev), "d" (next), "b" (prev)); } while (0) The context switch in kernel 2.4 introduces only a few minor changes: EBX is no longer pushing, but is included in the output of the inline assembler. A new input argument has appeared
lastthat contains the same value as prev. It is transmitted via EBX, but not used. :"=m" (prev->thread.esp),"=m" (prev->thread.eip), :"m" (next->thread.esp),"m" (next->thread.eip), I / O operands now refer to stack / instruction pointers for kernel threads. Previously, context switches referred to stack pointers from TSS.
Linux 2.4.0 (C)
/** arch/i386/kernel/process.c */ void __switch_to(struct task_struct *prev_p, struct task_struct *next_p) { struct thread_struct *prev = &prev_p->thread, *next = &next_p->thread; struct tss_struct *tss = init_tss + smp_processor_id(); unlazy_fpu(prev_p); tss->esp0 = next->esp0; asm volatile("movl %%fs,%0":"=m" (*(int *)&prev->fs)); asm volatile("movl %%gs,%0":"=m" (*(int *)&prev->gs)); /* Restore %fs and %gs. */ loadsegment(fs, next->fs); loadsegment(gs, next->gs); /* Now maybe reload the debug registers */ if (next->debugreg[7]){ loaddebug(next, 0); loaddebug(next, 1); loaddebug(next, 2); loaddebug(next, 3); /* no 4 and 5 */ loaddebug(next, 6); loaddebug(next, 7); } if (prev->ioperm || next->ioperm) { if (next->ioperm) { memcpy(tss->io_bitmap, next->io_bitmap, IO_BITMAP_SIZE*sizeof(unsigned long)); tss->bitmap = IO_BITMAP_OFFSET; } else tss->bitmap = INVALID_IO_BITMAP_OFFSET; } } In part of the C code, several things have changed. Any mention of the TR register has disappeared; instead, we directly change the active TSS for the current processor. As with the inline assembler, each task references the TSS data in the thread_struct inside the task_struct. Each active CPU uses a dedicated TSS from the GDT and directly updates these fields.
void __switch_to(struct task_struct *prev_p, struct task_struct *next_p) A suffix has been added to the pointers to the previous and next tasks
_p. This is a small but important nuance because prevand nextgoing to convert to kernel threads. struct thread_struct *prev = &prev_p->thread, *next = &next_p->thread; Pointers to TSS data for each task are determined.
tss->esp0 = next->esp0; Replacing the stack offset ring 0 offset from the new task. While not forcing the reload of the page table ...
asm volatile("movl %%fs,%0":"=m" (*(int *)&prev->fs)); asm volatile("movl %%gs,%0":"=m" (*(int *)&prev->gs)); Save FS and GS for the old task. The purpose of these segments is still not clear, but they are somehow used. Ultimately, in version 2.6, they are beginning to be used for the local FS: thread storage and the GS: per-processor data area.
if (prev->ioperm || next->ioperm) { if (next->ioperm) { memcpy(tss->io_bitmap, next->io_bitmap, IO_BITMAP_SIZE*sizeof(unsigned long)); tss->bitmap = IO_BITMAP_OFFSET; Sets the I / O permissions with port mapping in the active TSS service for the upcoming task.
} else tss->bitmap = INVALID_IO_BITMAP_OFFSET; Indicates I / O permissions for the active TSS on a known non-valid bitmap (0x8000).
Linux 2.6: popularity (2003)
As the core 2.5 was gone, the scheduler with linear execution time reached the limit of practical use, and AMD released an extension for x86, which required the immediate attention of kernel developers: x86-64.
Linux 2.6.0
In kernel 2.6.0, a scheduler appeared with constant execution time. Although this is a step forward from the previous linear scheduler, in 2.6.23 it was eventually replaced by the Completely-Fair Scheduler (CFS). On the other hand, the new 64-bit architecture has made the most significant changes to date.
Linux 2.6.0: i386 version
This is the last appearance of the 32-bit context switch in the article.

Linux 2.6.0 (i386 integrated assembler)
/** include/asm-i386/system.h */ #define switch_to(prev,next,last) do { unsigned long esi,edi; asm volatile("pushfl\n\t" "pushl %%ebp\n\t" "movl %%esp,%0\n\t" /* save ESP */ "movl %5,%%esp\n\t" /* restore ESP */ "movl $1f,%1\n\t" /* save EIP */ "pushl %6\n\t" /* restore EIP */ "jmp __switch_to\n" "1:\t" "popl %%ebp\n\t" "popfl" :"=m" (prev->thread.esp),"=m" (prev->thread.eip), "=a" (last),"=S" (esi),"=D" (edi) :"m" (next->thread.esp),"m" (next->thread.eip), "2" (prev), "d" (next)); } while (0) Removed four lines. ESI and EDI were previously placed on the stack, but are now transferred through I / O operands.
Linux 2.6.0 (i386 C)
/** arch/i386/kernel/process.c */ struct task_struct * __switch_to(struct task_struct *prev_p, struct task_struct *next_p) { struct thread_struct *prev = &prev_p->thread, *next = &next_p->thread; int cpu = smp_processor_id(); struct tss_struct *tss = init_tss + cpu; __unlazy_fpu(prev_p); load_esp0(tss, next->esp0); /* Load the per-thread Thread-Local Storage descriptor. */ load_TLS(next, cpu); asm volatile("movl %%fs,%0":"=m" (*(int *)&prev->fs)); asm volatile("movl %%gs,%0":"=m" (*(int *)&prev->gs)); /* Restore %fs and %gs if needed. */ if (unlikely(prev->fs | prev->gs | next->fs | next->gs)) { loadsegment(fs, next->fs); loadsegment(gs, next->gs); } /* Now maybe reload the debug registers */ if (unlikely(next->debugreg[7])) { loaddebug(next, 0); loaddebug(next, 1); loaddebug(next, 2); loaddebug(next, 3); /* no 4 and 5 */ loaddebug(next, 6); loaddebug(next, 7); } if (unlikely(prev->io_bitmap_ptr || next->io_bitmap_ptr)) { if (next->io_bitmap_ptr) { memcpy(tss->io_bitmap, next->io_bitmap_ptr, IO_BITMAP_BYTES); tss->io_bitmap_base = IO_BITMAP_OFFSET; } else tss->io_bitmap_base = INVALID_IO_BITMAP_OFFSET; } return prev_p; } Some interesting changes: the return value of the function and the appearance of the macro
unlikely(). I will not consider changes to existing code wrapped in [un], so as not to re-explain it. The macro simply tells the code generator which base unit should appear first to help pipelining. struct task_struct *__switch_to(...) __switch_to now returns a pointer to the old task. This is not processed anywhere, so either the change was deleted, or they wanted to follow the convention. For example, the classic convention that when a function changes a state, we return the previous state to save and restore later. While it does not work.
load_TLS(next, cpu); Updates the local thread storage handle in GDT for a new task. Linux 2.6 introduces three TLS entries in GDT for specific stream segments. So, glibc uses the first segment, Wine the second. Now we sequentially use the register of FS segments to refer to the local storage of threads as needed.
if (unlikely(prev->fs | prev->gs | next->fs | next->gs)) { Now we restore only FS and GS, if they were used by the previous or next task.
Linux 2.6.0: x86_64 version
The x86_64 context switch is significantly different from the 32-bit context. At this time, we will carefully study the code, because in the future we will focus only on the 64-bit version.

Linux 2.6.0 (built-in x86_64 assembler)
/** include/asm-x86_64/system.h */ #define SAVE_CONTEXT "pushfq ; pushq %%rbp ; movq %%rsi,%%rbp\n\t" #define RESTORE_CONTEXT "movq %%rbp,%%rsi ; popq %%rbp ; popfq\n\t" #define __EXTRA_CLOBBER ,"rcx","rbx","rdx","r8","r9","r10","r11","r12","r13","r14","r15" #define switch_to(prev,next,last) asm volatile(SAVE_CONTEXT "movq %%rsp,%P[threadrsp](%[prev])\n\t" /* save RSP */ "movq %P[threadrsp](%[next]),%%rsp\n\t" /* restore RSP */ "call __switch_to\n\t" ".globl thread_return\n" "thread_return:\n\t" "movq %%gs:%P[pda_pcurrent],%%rsi\n\t" "movq %P[thread_info](%%rsi),%%r8\n\t" "btr %[tif_fork],%P[ti_flags](%%r8)\n\t" "movq %%rax,%%rdi\n\t" "jc ret_from_fork\n\t" RESTORE_CONTEXT : "=a" (last) : [next] "S" (next), [prev] "D" (prev), [threadrsp] "i" (offsetof(struct task_struct, thread.rsp)), [ti_flags] "i" (offsetof(struct thread_info, flags)), [tif_fork] "i" (TIF_FORK), [thread_info] "i" (offsetof(struct task_struct, thread_info)), [pda_pcurrent] "i" (offsetof(struct x8664_pda, pcurrent)) : "memory", "cc" __EXTRA_CLOBBER) The macro has been updated in x86_64
_switch_to(), so you have to re-walk through its lines. Many changes are simply register names ( r..instead of e..). There are a few more helpers that I have mentioned above. asm volatile(SAVE_CONTEXT Keeps the kernel context on the stack through the auxiliary macro shown above. Very similar to the 32-bit version, with the exception of the new register names. The macro is paired with RESTORE_CONTEXT at the end of the inline assembly.
"movq %%rsp,%P[threadrsp](%[prev])\n\t" /* save RSP */ Stores the current stack pointer in the old task's TSS. Notice the new notation defined in the input operand section:
[threadrsp]is an immediate offset of thread.rsp inside the task_struct. %Pdereference the prev: threadsp pointer to ensure proper storage of the updated SP. "movq %P[threadrsp](%[next]),%%rsp\n\t" /* restore RSP */ Restores the stack pointer of a new task.
"call __switch_to\n\t" Calls part C of the context switch. It is described in the next section.
".globl thread_return\n" Defines a global label
thread_return. "thread_return:\n\t" Transition point for
thread_return. Purely mechanically, according to it the instruction pointer should proceed to the next instruction. In fact, not used in the kernel or in the library (for example, glibc). My guess is that pthreads can use it ... but it doesn't seem like it is. "movq %%gs:%P[pda_pcurrent],%%rsi\n\t" Sets the index for the current task using a link to the Per-process Data Area (PDA) data area. In kernel mode, the GS should always point to data for each processor.
"movq %P[thread_info](%%rsi),%%r8\n\t" Moves structure
thread_infoto r8. This is new in Linux 2.6, and in fact a lightweight version task_structthat easily fits onto the stack. "btr %[tif_fork],%P[ti_flags](%%r8)\n\t" Stores the TIF_FORK bit value in CF
thread_info->flagsand resets the bit in the structure. After a few lines, this bit will be set after the fork / clone and enabled to start ret_from_fork. "movq %%rax,%%rdi\n\t" Saves the
task_structprevious stream to RDI. The last instruction that works with EAX is a call to a C function __switch_tothat returns prevto EAX. "jc ret_from_fork\n\t" If this thread is a fresh fork / clone, go to ret_from_fork to start again.
: "=a" (last) The previous thread is returned to EAX.
: [next] "S" (next), [prev] "D" (prev), [threadrsp] "i" (offsetof(struct task_struct, thread.rsp)), [ti_flags] "i" (offsetof(struct thread_info, flags)), [tif_fork] "i" (TIF_FORK), [thread_info] "i" (offsetof(struct task_struct, thread_info)), [pda_pcurrent] "i" (offsetof(struct x8664_pda, pcurrent)) Input links for inline assembly. Most of them are direct operands with offsets. Above, we have already run over them.
: "memory", "cc" __EXTRA_CLOBBER) Linux 2.6.0 (x86_64 C)
/** arch/x86_64/kernel/process.c */ struct task_struct *__switch_to(struct task_struct *prev_p, struct task_struct *next_p) { struct thread_struct *prev = &prev_p->thread, *next = &next_p->thread; int cpu = smp_processor_id(); struct tss_struct *tss = init_tss + cpu; unlazy_fpu(prev_p); tss->rsp0 = next->rsp0; asm volatile("movl %%es,%0" : "=m" (prev->es)); if (unlikely(next->es | prev->es)) loadsegment(es, next->es); asm volatile ("movl %%ds,%0" : "=m" (prev->ds)); if (unlikely(next->ds | prev->ds)) loadsegment(ds, next->ds); load_TLS(next, cpu); /* Switch FS and GS. */ { unsigned fsindex; asm volatile("movl %%fs,%0" : "=g" (fsindex)); if (unlikely(fsindex | next->fsindex | prev->fs)) { loadsegment(fs, next->fsindex); if (fsindex) prev->fs = 0; } /* when next process has a 64bit base use it */ if (next->fs) wrmsrl(MSR_FS_BASE, next->fs); prev->fsindex = fsindex; } { unsigned gsindex; asm volatile("movl %%gs,%0" : "=g" (gsindex)); if (unlikely(gsindex | next->gsindex | prev->gs)) { load_gs_index(next->gsindex); if (gsindex) prev->gs = 0; } if (next->gs) wrmsrl(MSR_KERNEL_GS_BASE, next->gs); prev->gsindex = gsindex; } /* Switch the PDA context. */ prev->userrsp = read_pda(oldrsp); write_pda(oldrsp, next->userrsp); write_pda(pcurrent, next_p); write_pda(kernelstack, (unsigned long)next_p->thread_info + THREAD_SIZE - PDA_STACKOFFSET); /* Now maybe reload the debug registers */ if (unlikely(next->debugreg7)) { loaddebug(next, 0); loaddebug(next, 1); loaddebug(next, 2); loaddebug(next, 3); /* no 4 and 5 */ loaddebug(next, 6); loaddebug(next, 7); } /* Handle the IO bitmap */ if (unlikely(prev->io_bitmap_ptr || next->io_bitmap_ptr)) { if (next->io_bitmap_ptr) { memcpy(tss->io_bitmap, next->io_bitmap_ptr, IO_BITMAP_BYTES); tss->io_bitmap_base = IO_BITMAP_OFFSET; } else { tss->io_bitmap_base = INVALID_IO_BITMAP_OFFSET; } } return prev_p; } In the x86_64 version, several changes have been added to the context switch code in C. I will not repeat simple case changes (for example, renaming EAX to RAX).
asm volatile("movl %%es,%0" : "=m" (prev->es)); if (unlikely(next->es | prev->es)) loadsegment(es, next->es); Saves the ES segment for the old task, and then loads the new one, if necessary.
asm volatile ("movl %%ds,%0" : "=m" (prev->ds)); if (unlikely(next->ds | prev->ds)) loadsegment(ds, next->ds); Saves a data segment for an old task, and then loads a new one, if necessary.
unsigned fsindex; asm volatile("movl %%fs,%0" : "=g" (fsindex)); if (unlikely(fsindex | next->fsindex | prev->fs)) { loadsegment(fs, next->fsindex); if (fsindex) prev->fs = 0; } Moves the FS segment to
fsindex, and then loads the FS for the new task, if necessary. In principle, if an old or new task has a valid value for FS, something is loaded in its place (maybe NULL). FS is typically used for local stream storage, but there are other uses depending on when context switching occurs. Exactly the same code is used for GS, so there is no need to repeat. GS is usually a segment for thread_info. if (next->fs) wrmsrl(MSR_FS_BASE, next->fs); If the next task uses the FS register, then you need to check that the entire 64-bit value is written. Recall that the segment registers are an artifact of the 16/32-bit era, so a special function checks that the top 32 bits are written.
prev->fsindex = fsindex; Save the FS for the old task.
prev->userrsp = read_pda(oldrsp); write_pda(oldrsp, next->userrsp); write_pda(pcurrent, next_p); write_pda(kernelstack, (unsigned long)next_p->thread_info + THREAD_SIZE - PDA_STACKOFFSET); Update the PDA for the upcoming task, including storing the old RSP (syscall) of the old task. The PDA is updated with the flow and stack information.
Linux 3.0: Modern OS (2011)
Do not be fooled by the number. In fact, version 3.0 was released almost 8 years after 2.6.0. A huge number of changes worthy of the whole book, and I can not tell you about everything. As for the context switch, i386 and x86_64 merged into x86 with separate process files (process_32.c and process_64.с.) This article is too large, so we will continue to analyze only the x86_64 version . Some details are only denoted and discussed in more detail in the last LTS.

Linux 3.0.1 (built-in x86_64 assembler)
/** arch/x86/include/asm/system.h */ #define SAVE_CONTEXT "pushf ; pushq %%rbp ; movq %%rsi,%%rbp\n\t" #define RESTORE_CONTEXT "movq %%rbp,%%rsi ; popq %%rbp ; popf\t" #define __EXTRA_CLOBBER \ ,"rcx","rbx","rdx","r8","r9","r10","r11","r12","r13","r14","r15" #define switch_to(prev, next, last) asm volatile(SAVE_CONTEXT "movq %%rsp,%P[threadrsp](%[prev])\n\t" /* save RSP */ "movq %P[threadrsp](%[next]),%%rsp\n\t" /* restore RSP */ "call __switch_to\n\t" "movq "__percpu_arg([current_task])",%%rsi\n\t" __switch_canary "movq %P[thread_info](%%rsi),%%r8\n\t" "movq %%rax,%%rdi\n\t" "testl %[_tif_fork],%P[ti_flags](%%r8)\n\t" "jnz ret_from_fork\n\t" RESTORE_CONTEXT : "=a" (last) __switch_canary_oparam : [next] "S" (next), [prev] "D" (prev), [threadrsp] "i" (offsetof(struct task_struct, thread.sp)), [ti_flags] "i" (offsetof(struct thread_info, flags)), [_tif_fork] "i" (_TIF_FORK), [thread_info] "i" (offsetof(struct task_struct, stack)), [current_task] "m" (current_task) __switch_canary_iparam : "memory", "cc" __EXTRA_CLOBBER) Eight years - and in the macro,
switch_to()only four changes. Two of them are connected with each other, and nothing cardinally new. movq "__percpu_arg([current_task])",%%rsi\n\t Moves a new straturu
task_structto RSI. This is the “new” way to access information about the task: each CPU has a static symbol. Previously information was available through GS: [pda offset]. Subsequent RSI operations are the same as in version 2.6. __switch_canary This macro allows you to additionally check if the CONFIG_CC_STACKPROTECTOR macro is enabled when building the kernel. I'm not going to dig this topic too deeply, except for the fact that this mechanism protects against hacker stack destruction . In fact, we save a random value, and later we check it. If the value has changed - it means trouble.
testl %[_tif_fork],%P[ti_flags](%%r8)\n\t jnz ret_from_fork\n\t Checks whether a new task was simply created using cloning / fork, and then proceeds to
ret_from_fork(). Previously, it was an instruction btr, but now we postpone resetting the bit until the call is completed. The name has changed to JNZ due to a test change: if the bit is set, TEST (AND) will be positive. __switch_canary_oparam Output stack canary for
CONFIG_CC_STACKPROTECTOR. __switch_canary_iparam Typing stack canary for
CONFIG_CC_STACKPROTECTORLinux 3.0.1 (x86_64 C)
/** arch/x86/kernel/process_64.c */ __notrace_funcgraph struct task_struct * __switch_to(struct task_struct *prev_p, struct task_struct *next_p) { struct thread_struct *prev = &prev_p->thread; struct thread_struct *next = &next_p->thread; int cpu = smp_processor_id(); struct tss_struct *tss = &per_cpu(init_tss, cpu); unsigned fsindex, gsindex; bool preload_fpu; preload_fpu = tsk_used_math(next_p) && next_p->fpu_counter > 5; /* we're going to use this soon, after a few expensive things */ if (preload_fpu) prefetch(next->fpu.state); /* Reload esp0, LDT and the page table pointer: */ load_sp0(tss, next); savesegment(es, prev->es); if (unlikely(next->es | prev->es)) loadsegment(es, next->es); savesegment(ds, prev->ds); if (unlikely(next->ds | prev->ds)) loadsegment(ds, next->ds); savesegment(fs, fsindex); savesegment(gs, gsindex); load_TLS(next, cpu); __unlazy_fpu(prev_p); /* Make sure cpu is ready for new context */ if (preload_fpu) clts(); arch_end_context_switch(next_p); /* Switch FS and GS. */ if (unlikely(fsindex | next->fsindex | prev->fs)) { loadsegment(fs, next->fsindex); if (fsindex) prev->fs = 0; } /* when next process has a 64bit base use it */ if (next->fs) wrmsrl(MSR_FS_BASE, next->fs); prev->fsindex = fsindex; if (unlikely(gsindex | next->gsindex | prev->gs)) { load_gs_index(next->gsindex); if (gsindex) prev->gs = 0; } if (next->gs) wrmsrl(MSR_KERNEL_GS_BASE, next->gs); prev->gsindex = gsindex; /* Switch the PDA and FPU contexts. */ prev->usersp = percpu_read(old_rsp); percpu_write(old_rsp, next->usersp); percpu_write(current_task, next_p); percpu_write(kernel_stack, (unsigned long)task_stack_page(next_p) + THREAD_SIZE - KERNEL_STACK_OFFSET); /* Now maybe reload the debug registers and handle I/O bitmaps */ if (unlikely(task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT || task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV)) __switch_to_xtra(prev_p, next_p, tss); /* Preload the FPU context - task is likely to be using it. */ if (preload_fpu) __math_state_restore(); return prev_p; } There are a few more changes in C code, but they are relatively few, given eight years between releases. Some of them are cosmetic, for example, moving up all the declarations. Here is what has changed:
__notrace_funcgraph struct task_struct * __switch_to(...) New signature
__notrace_funcgraphprohibits active ftrace track switch_to. preload_fpu = tsk_used_math(next_p) && next_p->fpu_counter > 5; if (preload_fpu) prefetch(next->fpu.state); Checks if the FPU was used in the last task in the last 5 time slices, and then tries to capture the data in the cache for later use.
load_sp0(tss, next); Loads the kernel space stack pointer, updates the page tables and notifies the hypervisor (if applicable).
savesegment(es, prev->es); Saves the ES segment. This is not exactly an innovation, just a replacement for the inline assembler from 2.6:
asm volatile("movl %%es,%0" : "=m" (prev->es)); . if (preload_fpu) clts(); Immediately restarts the FPU if the likelihood of use is high. Application
clts()- the same idea that we saw from the first version of Linux : "cmpl %%ecx,%2\n\t jne 1f\n\t clts\n". jne 1f\n\t clts\n" arch_end_context_switch(next_p); It matters only when virtualization . Under normal circumstances, the function does nothing . See the final kernel for details.
if (unlikely(task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT || task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV)) __switch_to_xtra(prev_p, next_p, tss); It is engaged in administrative work, which was previously described at the end
switch_to, including debug registers and I / O bitmap parameters. More about this will tell the review code 4.14.67. if (preload_fpu) __math_state_restore(); Restores FPU after checking its use. With good luck, the data should already be in the cache due to the prefetch made earlier.
Linux 4.14.67: Latest LTS (2018)
This is our deepest immersion in the inner workings of the context switch. The procedure was significantly revised from the release of 3.0 and organized code. Overall, he now looks cleaner and organized than ever. For x86_64:

- После версии 3.4 макрос верхнего уровня
switch_to()обзавёлся собственным заголовочным файлом arch/x86/include/asm/switch_to.h . Макрос вызывается ровно один раз, в концеcontext_switch()из kernel/sched/core.с . - Начиная с версии 4.9
switch_to()разбит на две части: макросprepare_switch_to()и часть встроенного ассемблера перемещены в реальный файл ассемблера ( arch/x86/entry/entry_64.S ). - Написанная на C часть переключателя контекста всё ещё вызывается через переход в середине ассемблерного кода. С версии 2.6.24 исходник находится в arch/x86/kernel/process_64.c .
Linux 4.14.67
/** arch/x86/include/asm/switch_to.h */ #define switch_to(prev, next, last) do { prepare_switch_to(prev, next); ((last) = __switch_to_asm((prev), (next))); } while (0) It looks simple compared to old kernels. This reorganization was the result of a solution to the problem when Andy Lutomirsky introduced virtual kernel stacks .
prepare_switch_to(prev, next); Ensures that kernel stacks are available before attempting context switching. This avoids a possible double error or panic of the kernel during an attempt to switch context when using virtually mapped kernel stacks.
((last) = __switch_to_asm((prev), (next))); Runs the actual context switch.
Take a look at the
prepare_switch_toone defined in the same source file.Linux 4.14.67
/** arch/x86/include/asm/switch_to.h */ static inline void prepare_switch_to(struct task_struct *prev, struct task_struct *next) { #ifdef CONFIG_VMAP_STACK READ_ONCE(*(unsigned char *)next->thread.sp); #endif } #ifdef CONFIG_VMAP_STACK It is determined when the stack is using virtual memory. We need to prepare for context switching only if we use virtual stacks. This is a configuration parameter during kernel build. Many modern distributions default to its value
yes. READ_ONCE(*(unsigned char *)next->thread.sp); Refer to the next stack to correct page tables (pgd). The main problem is that we are trying to access the pointer, which is not only outside the pages (paged-out), but not even in the context of the memory of this task due to the delayed loading of the vmalloc area. The absence and inaccessibility of the pointer means a kernel panic , if the problem is not solved in advance.
Linux 4.16.67
/** arch/x86/entry/entry_64.S */ ENTRY(__switch_to_asm) UNWIND_HINT_FUNC /* Save callee-saved registers */ pushq %rbp pushq %rbx pushq %r12 pushq %r13 pushq %r14 pushq %r15 /* switch stack */ movq %rsp, TASK_threadsp(%rdi) movq TASK_threadsp(%rsi), %rsp #ifdef CONFIG_CC_STACKPROTECTOR movq TASK_stack_canary(%rsi), %rbx movq %rbx, PER_CPU_VAR(irq_stack_union)+stack_canary_offset #endif #ifdef CONFIG_RETPOLINE FILL_RETURN_BUFFER %r12, RSB_CLEAR_LOOPS, X86_FEATURE_RSB_CTXSW #endif /* restore callee-saved registers */ popq %r15 popq %r14 popq %r13 popq %r12 popq %rbx popq %rbp jmp __switch_to END(__switch_to_asm) In entry_64.S contains work that the previous 25 years in the Linux performed inline assembler.
UNWIND_HINT_FUNC Generates prompts used by the stack trace tool of the objtool that has just been released. This is necessary for special assembly procedures that do not comply with the usual C language calling conventions. Such hints are the reason for the successful implementation of the ORC code decoder in version 4.6.
pushq %rbp, %rbx, %r12, %r13, %r14, %r15 We save registers to the old stack , from which we switch.
movq %rsp, TASK_threadsp(%rdi) movq TASK_threadsp(%rsi), %rsp Swap pointers stack between the old and the new task. Directly from the surrounding assembler, this is not clear, but RDI and RSI contain input arguments
task_struct *, prev and next, in accordance with the System V ABI conventions. Here is a subset of registers along with their use:
#ifdef CONFIG_CC_STACKPROTECTOR movq TASK_stack_canary(%rsi), %rbx movq %rbx, PER_CPU_VAR(irq_stack_union)+stack_canary_offset If stack protection is enabled, the canary value of this task is moved to the appropriate place in the interrupt stack of the current CPU. Stack protection is usually enabled by default, so it usually does.
#ifdef CONFIG_RETPOLINE FILL_RETURN_BUFFER %r12, RSB_CLEAR_LOOPS, X86_FEATURE_RSB_CTXSW This is a defense against the possible exploitation of branch prediction (Specter vulnerability). Pure voodoo !
popq %r15, %r14, %r13, %r12, %rbx, %rbp Recovers all registers from the new stack in the reverse order: (r15, r14, r13, r12, rbx, rbp)
Linux 4.16.67 ( source with comments)
/** arch/x86/kernel/process_64.c */ __visible __notrace_funcgraph struct task_struct * __switch_to(struct task_struct *prev_p, struct task_struct *next_p) { struct thread_struct *prev = &prev_p->thread; struct thread_struct *next = &next_p->thread; struct fpu *prev_fpu = &prev->fpu; struct fpu *next_fpu = &next->fpu; int cpu = smp_processor_id(); struct tss_struct *tss = &per_cpu(cpu_tss_rw, cpu); WARN_ON_ONCE(IS_ENABLED(CONFIG_DEBUG_ENTRY) && this_cpu_read(irq_count) != -1); switch_fpu_prepare(prev_fpu, cpu); save_fsgs(prev_p); load_TLS(next, cpu); arch_end_context_switch(next_p); savesegment(es, prev->es); if (unlikely(next->es | prev->es)) loadsegment(es, next->es); savesegment(ds, prev->ds); if (unlikely(next->ds | prev->ds)) loadsegment(ds, next->ds); load_seg_legacy(prev->fsindex, prev->fsbase, next->fsindex, next->fsbase, FS); load_seg_legacy(prev->gsindex, prev->gsbase, next->gsindex, next->gsbase, GS); switch_fpu_finish(next_fpu, cpu); /* Switch the PDA and FPU contexts. */ this_cpu_write(current_task, next_p); this_cpu_write(cpu_current_top_of_stack, task_top_of_stack(next_p)); /* Reload sp0. */ update_sp0(next_p); /* Now maybe reload the debug registers and handle I/O bitmaps */ if (unlikely(task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT || task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV)) __switch_to_xtra(prev_p, next_p, tss); #ifdef CONFIG_XEN_PV if (unlikely(static_cpu_has(X86_FEATURE_XENPV) && prev->iopl != next->iopl)) xen_set_iopl_mask(next->iopl); #endif if (static_cpu_has_bug(X86_BUG_SYSRET_SS_ATTRS)) { unsigned short ss_sel; savesegment(ss, ss_sel); if (ss_sel != __KERNEL_DS) loadsegment(ss, __KERNEL_DS); } /* Load the Intel cache allocation PQR MSR. */ intel_rdt_sched_in(); return prev_p; } This last block of code allows you to get acquainted with the latest changes in the context switch! If you immediately squandered an article on this place, do not worry - I will here (again) review most of the points, and in more detail. Notice some exceptions that hit the context switch.
__visible __notrace_funcgraph struct task_struct * __switch_to(struct task_struct *prev_p, struct task_struct *next_p) The signature for the context switch on C has several parts:
- __visible - this attribute ensures that optimization during the build process will not remove the symbol
__switch_to(). - __notrace_funcgraph - protects
__switch_to()against the ftrace tracer. The function was added approximately in version 2.6.29, and soon it was turned on. - The input arguments are pointers to the old and new tasks, which are passed to RDI and RSI.
struct thread_struct *prev = &prev_p->thread; struct thread_struct *next = &next_p->thread; struct fpu *prev_fpu = &prev->fpu; struct fpu *next_fpu = &next->fpu; Collects some information from the input
task_struct *. The thread_struct contains TSS data for the task (registers, etc.). The structure fpu>contains FPU data, such as the last used CPU, initialization, and register values. int cpu = smp_processor_id(); Returns the number of the processor that we need to manage the GDT for TSS data, local storage of streams and compare the state of the AZG.
struct tss_struct *tss = &per_cpu(cpu_tss_rw, cpu); Indicates the current TSS CPU .
WARN_ON_ONCE(IS_ENABLED(CONFIG_DEBUG_ENTRY) && this_cpu_read(irq_count) != -1); Determines whether the IRQ stack is used during a context switch, and reports this once per load. This was added at the beginning of development 4.14, and in fact this code does not affect the context switching.
switch_fpu_prepare(prev_fpu, cpu); Keeps the current state of the FPU while we are in the old task.
save_fsgs(prev_p); Stores FS and GS before we change the local stream storage.
load_TLS(next, cpu); Reloads the GDT for local storage of the new task stream. It mechanically copies tls_array from the new stream to the GDT records 6, 7 and 8.
arch_end_context_switch(next_p); This function is determined only by paravirtualization. Changes the paravirt mode and clears all remaining batch jobs. Introduced in recent versions 2.6.x. I am not too strong in this functionality, therefore I will leave for research to readers.
savesegment(es, prev->es); if (unlikely(next->es | prev->es)) loadsegment(es, next->es); Saves the ES segment and loads a new one if necessary. A similar DS call is omitted. Even if the new task does not use DS / ES, it still removes all old values.
load_seg_legacy(prev->fsindex, prev->fsbase, next->fsindex, next->fsbase, FS); Loads new FS segments (GS omitted). This will allow you to detect and load registers for 32-bit and 64-bit register types. New task is now ready to work TLS.
switch_fpu_finish(next_fpu, cpu); Initializes the state of the FPU for the incoming task.
this_cpu_write(current_task, next_p); Updates the current CPU (
task_struct *) task . Effectively updates FPU and PDA states (data area for each processor). this_cpu_write(cpu_current_top_of_stack, task_top_of_stack(next_p)); Updates the CPU pointer to the top of the stack, which in fact is overloaded by sp1 as generated code (entry trampoline) for security.
update_sp0(next_p); Validate a new stack to check it out. It seems that sp0 should be specified here, not sp1? Probably should be renamed.
if (unlikely(task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT || task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV)) __switch_to_xtra(prev_p, next_p, tss); Updates debug registers and I / O bitmaps. These two tasks were previously processed directly in the context switch, but now moved to
__switch_to_xtra(). #ifdef CONFIG_XEN_PV if (unlikely(static_cpu_has(X86_FEATURE_XENPV) && prev->iopl != next->iopl)) xen_set_iopl_mask(next->iopl); Manually swaps the I / O privilege bits for Xen paravirtualization. Apparently, the usual flag switch does not work properly , and therefore it is necessary to directly mask the current bits.
if (static_cpu_has_bug(X86_BUG_SYSRET_SS_ATTRS)) { unsigned short ss_sel; savesegment(ss, ss_sel); if (ss_sel != __KERNEL_DS) loadsegment(ss, __KERNEL_DS); Hides unexpected SYSRET behavior in AMD processors that incorrectly update segment descriptors.
intel_rdt_sched_in(); Some of Intel’s resource cleanup tasks. Updates RMID and CLOSid .
return prev_p; Done!
FAQ
Why did you choose these particular kernel versions?
The first and last versions were obvious candidates. Initially, I planned to consider four more intermediate versions (2.1, 2.3, 2.5 and 2.6.26), but the changes were not enough to over-inflate the article. She is too big.
How long did this study take?
Two weeks. One week for code analysis, notes, and technical study guides. Then one week to rewrite notes, draw diagrams, and format the article.
4.14.67 - not the latest LTS release?
I began to study the code on September 1 and took the source code 4.14.67. Version 4.14.68 completed in four days.
Other questions will add as they become available.
Source: https://habr.com/ru/post/438042/