How to geocode a million points on Spark in a quick way?
In my previous project, we faced the task of conducting reverse geocoding for many pairs of geographic coordinates. Reverse geocoding is a procedure that associates with the latitude-longitude pair the address or name of the object on the map to which the point specified by the coordinates belongs or is close. That is, we take the coordinates, say these: @ 55.7602485.37.6170409, and we get the result of either “Russia, Central Federal District, Moscow, Theater Square, such-and-such house”, or for example “Bolshoi Theater”.
If the address or name is at the input, and the coordinates are at the output, then this operation is a direct geocoding , I hope we will talk about this later.
As input, we had about 100 or 200 thousand points at the entrance, which lay in the Hadoop cluster in the form of a Hive table. This is so that the scale of the task is clear.
In the end, Spark was chosen as the processing tool, although in the process we tried both MapReduce and Apache Crunch. But this is a separate story, perhaps deserving of its post.
For a start, we tried to approach the problem as if “in the forehead”. As a tool, there was an ArcGIS server that provides a reverse geocoding REST service. It is quite simple to use it, for this we execute an http GET request with the following URL:
Of the many parameters, it is enough to set location = x, y (the main thing is not to confuse which of them is latitude and who is longitude;). And here we already have JSON with the results: country, region, city, street, house number. Example from documentation:
You can optionally specify what types of answers we want - mailing addresses, or say POI (point of interest, is to get answers like “Bolshoi Theater”), or do we need street intersections, for example. You can also specify the radius within which a named object will be searched for from the specified point.
For a quick check of the quality of the response, you can estimate the distance between the source point in the request parameters and the resulting point - the location in the service response.
It would seem that now everything will be fine. But it was not there. Our ArcGIS instance was rather slow, the server seemed to have 4 cores, and approximately 8 gigabytes of RAM. As a result, the task on the cluster could read our 200 thousand points very quickly, but rested against REST and the performance of ArcGIS. And geocoding all points took hours. At the same time, we allocated only 8 cores on Hadoop, and some memory, but since the ArcGIS server load was close to 100% for many hours, the extra resources in the cluster did not give us anything.
ArcGIS does not know how to do reverse geocoding operations, so the query is executed once for each point. And by the way, if the service does not respond, then we fall off on timeout or with an error, and what to do about it is a problem with an unobvious answer. Maybe try again, and maybe complete the whole process, and then repeat it for the raw points.
For a start, we found out that many points in our set have repeating coordinates. The reason is simple - obviously, the accuracy of GPS is not good enough for the coordinates of two points located two meters from each other to be different at the output, or the coordinates obtained not from GPS but from another base were simply entered into the original database. In general, it does not matter why this is so, the main thing is that this is quite a typical situation, so that a cache of the results obtained from the service will allow geocoding each pair of coordinates only once. A memory for the cache, we can afford.
Actually, the first modification of the algorithm was made trivial - all the results obtained from REST were added to the cache, and at first all points were searched for by coordinates in it. We didn’t even start a shared cache for all Spark processes - it had its own on each cluster node.
In this simple way, we were able to get the acceleration up to about 10 times, which roughly corresponds to the number of repetitions of coordinates in the original set. This was already acceptable, but still very slowly.
Well, our customer told us at this time, if we cannot calculate the addresses faster, can we quickly determine at least the city? And we set about ...
What do we have to determine the city? We had the geometry of the regions of Russia, the administrative-territorial division, approximately to the areas of the city.
You can take this data for example here . What is there? This is a database of administrative borders of the Russian Federation, for levels from 2 (country) to 9 (urban districts). The format is either geojson or CSV (and the geometry itself is in wkt format). Total database of about 20 thousand records.
The new simplified solution of the problem looked like this:
As a result, at the exit we get something like: Russia, Central Federal District, Moscow, such and such administrative district, district such and such, that is, a list of territories, which our point belongs to.
To download CSV easier, we will apply kite . This tool can build a very good scheme for Hive based on the column headers in CSV. In fact, the import is reduced to three commands (one of which is repeated for each level file):
What did we do here? The first team built us Avro-scheme for csv, for which we specified some parameters of the scheme (class, in this case), and field separator for CSV. Further, it is worth looking at the resulting scheme with eyes, and it is possible to make some corrections, because Kite does not look at all the lines of our file, but only at a certain sample, so sometimes it can make incorrect assumptions about the type of data (I saw three numbers - I decided that the column is numeric, and then the lines go).
Well, then on the basis of the scheme we create a dataset (this is the general term Kite, which generalizes the tables in Hive, the tables in HBase, and something else). In this case, default is the database (for Hive, too, as the schema), and levelswkt is the name of our table.
Well, the last commands upload CSV files to our dataset. After successfully completing the download, you can already execute the query:
somewhere in Hue.
To work with geometry in Java, we chose Esri's Java Geometry API (developer of ArcGIS). In principle, it was possible to take other frameworks, some choice of Open Source is available, for example, the well-known package JTS Topology Suite , or Geotools .
The first task allows us to cope with another framework from the same Esri company, called the Spatial Framework for Hadoop , and based on the first one. In fact, from it we need the so-called SerDe, the serialization-de-serialization module for Hive, which allows us to represent a pack of geojson files as a table in Hive, whose columns are taken from the geojson attributes. And the geometry itself becomes another column (with binary data). As a result, we have a table, one of the columns of which is the geometry of a certain region, and the rest are its attributes (name, level in ADT, etc.). This table is available to the Spark application.
If we upload to the database in CSV format, then we have a column where the geometries are in text form, in the WKT format. In this case, Spark can create a geometry object at runtime using the Geometry API.
We chose the CSV format (and WKT), for one simple reason - as everyone knows, Russia occupies a map on the map with the coordinates of Chukotka for the 180 meridian. The geojson format has a restriction - all polygons inside it should be limited to 180 degrees, and those that cross the 180 meridian need to be cut into two parts. As a result, when importing geometry into the Geometry API, we get an object for which the Geometry API incorrectly determines the Bounding Box (enclosing rectangle) for the Russian border. The answer is -180.180 in longitude. Which of course is not true - in reality, Russia takes about 20 to -170 degrees. This is the problem of the Geometry API, today it may have already been fixed, but then we had to bypass it.
WKT has no such problem. You ask, why do we need Bounding Box? I'll tell you later ;)
It remains to solve the so-called PIP problem, point in poligon. This is again a Java Geometry API, for us it is simple, one geometry of type Point, the second polygon (Multipoligon) for the region, and one contains method.
As a result, the second solution, and also on the forehead, looked like this: Spark application loads ADT, including geometry. Something of the Map type name-> geometry is built from them (in fact, a little more complicated, since the ADT are nested in each other, and we need to search only for those lower levels that are included in the upper one already found. As a result, there is a certain tree of geometries that according to the source data still need to build). And then we build Spark Dataset with our points, and for each point we apply our UDF, which checks the occurrence of the point in all geometries (by tree).
Writing a new version takes about a day of work, the benefit of the Spatial Framework for Hadoop bundle were quite good examples directly to solve the PIP problem (albeit by several other means).
We start, and ... oh, horror, it’s not so fast anymore. Watch again. It's time to think about optimization.
The reason for the brakes is fairly obvious - say, the geometry of Russia, i.e. external borders, these are geojson megabytes, a hefty polygon, and not one. If we recall how the PIP problem is solved, then one of the well-known methods is to construct a ray from a point, say somewhere up, to infinity, and determine at how many points it crosses a polygon. If the number of points is even, the point is outside the polygon, if odd is inside.
Let's say the description of the wiki .

It is clear that for a huge polygon the solution of the intersection problem is complicated by as many times as we have straight line segments in the polygon. Therefore, it is desirable to somehow reject those polygons, in which the point can not obviously enter. And as an additional lifehack, it is possible to reject the check for entry into the borders of Russia (if we know that all the coordinates are obviously included in it).
For this we need a tree of quadrants . Fortunately, the implementation is all in the same Geometry API (and much else where).

The tree-based solution looks like this:
Further, when processing points:
It all takes another four hours of development. Run again, and we see that the task was completed somehow very quickly. We check - everything is fine, the solution is received. And all - in a couple of minutes. QuadTree gives us acceleration by several orders of magnitude.
So what we got in the end? We got a reverse geocoding mechanism, which is effectively parallelized on the Hadoop cluster, and which solves our original problem from 200 thousand points in about minutes. Those. we can safely apply this solution to millions of points.
What are the limitations of this solution? First, the obvious - it is based on the data available to us ATD, which a) may not be relevant b) limited only by Russia.
And second, we are not able to solve the reverse geocoding problem for objects other than closed polygons. And that means - for the streets as well.
What can be done with this?
To have actual geometry of the ADT, the simplest thing is to take them from OpenStreetMap. Of course, they will have to work a little, but this is a completely solvable task. If there is interest, I will tell you about the task of loading OpenStreetMap data into the Hadoop cluster some other time.
What can be done for streets and houses? In principle, the streets are in the same OSM. But these are not closed structures, but lines. To determine that the point is “close” to a certain street, you will have to build a landfill for the street from points equidistant from it, and check that it is hit. As a result, such a sausage turns out ... it looks like this:
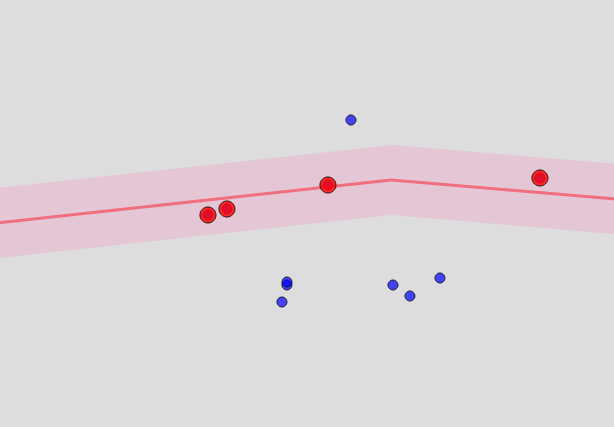
How close is the point? This is a parameter, and roughly corresponds to the radius within which it searches for ArcGIS objects, and which I mentioned at the very beginning.
Thus we find the streets, the distance from the point to which is less than a certain limit (say, 100 meters). And the smaller this limit is, the faster the algorithm works, but the greater the chance that you will not find a single match.
The obvious problem is that it is impossible to calculate these so-called buffers in advance - their size is a service parameter. They need to be built on the fly, after we have determined the desired area of the city, and have selected the streets that pass through this area from the OSM base. Streets, however, can be selected and in advance.
Houses that are located in the area found are not moving anywhere either, so their list can be built in advance, but hitting them anyway will have to be considered on the fly.
That is, you need to first build an index of the form "district of the city" -> a list of houses with references to the geometry, and a similar one for the list of streets.
And as soon as we have determined the area, we get a list of houses and streets, build borders along the streets, and already for them we solve the PIP problem (probably, using the same optimizations as for the borders of the regions). In this case, a quad tree for houses can obviously also be built in advance, and saved somewhere.
Our main goal is to minimize the amount of calculations, while maximizing and saving in advance everything that can be calculated and saved. In this case, the process will consist of the slow stage of building indexes, and the second stage of calculation, which will already pass quickly, close to the online version.
If the address or name is at the input, and the coordinates are at the output, then this operation is a direct geocoding , I hope we will talk about this later.
As input, we had about 100 or 200 thousand points at the entrance, which lay in the Hadoop cluster in the form of a Hive table. This is so that the scale of the task is clear.
In the end, Spark was chosen as the processing tool, although in the process we tried both MapReduce and Apache Crunch. But this is a separate story, perhaps deserving of its post.
Rectilinear solution available means
For a start, we tried to approach the problem as if “in the forehead”. As a tool, there was an ArcGIS server that provides a reverse geocoding REST service. It is quite simple to use it, for this we execute an http GET request with the following URL:
http://базовый-url/GeocodeServer/reverseGeocode?<параметры> Of the many parameters, it is enough to set location = x, y (the main thing is not to confuse which of them is latitude and who is longitude;). And here we already have JSON with the results: country, region, city, street, house number. Example from documentation:
{ "address": { "Match_addr": "Beeman's Redlands Pharmacy", "LongLabel": "Beeman's Redlands Pharmacy, 255 Terracina Blvd, Redlands, CA, 92373, USA", "ShortLabel": "Beeman's Redlands Pharmacy", "Addr_type": "POI", "Type": "Pharmacy", "PlaceName": "Beeman's Redlands Pharmacy", "AddNum": "255", "Address": "255 Terracina Blvd", "Block": "", "Sector": "", "Neighborhood": "South Redlands", "District": "", "City": "Redlands", "MetroArea": "Inland Empire", "Subregion": "San Bernardino County", "Region": "California", "Territory": "", "Postal": "92373", "PostalExt": "", "CountryCode": "USA" }, "location": { "x": -117.20558993392585, "y": 34.037880040538894, "spatialReference": { "wkid": 4326, "latestWkid": 4326 } } } You can optionally specify what types of answers we want - mailing addresses, or say POI (point of interest, is to get answers like “Bolshoi Theater”), or do we need street intersections, for example. You can also specify the radius within which a named object will be searched for from the specified point.
For a quick check of the quality of the response, you can estimate the distance between the source point in the request parameters and the resulting point - the location in the service response.
It would seem that now everything will be fine. But it was not there. Our ArcGIS instance was rather slow, the server seemed to have 4 cores, and approximately 8 gigabytes of RAM. As a result, the task on the cluster could read our 200 thousand points very quickly, but rested against REST and the performance of ArcGIS. And geocoding all points took hours. At the same time, we allocated only 8 cores on Hadoop, and some memory, but since the ArcGIS server load was close to 100% for many hours, the extra resources in the cluster did not give us anything.
ArcGIS does not know how to do reverse geocoding operations, so the query is executed once for each point. And by the way, if the service does not respond, then we fall off on timeout or with an error, and what to do about it is a problem with an unobvious answer. Maybe try again, and maybe complete the whole process, and then repeat it for the raw points.
The second approximation, we introduce the cache
For a start, we found out that many points in our set have repeating coordinates. The reason is simple - obviously, the accuracy of GPS is not good enough for the coordinates of two points located two meters from each other to be different at the output, or the coordinates obtained not from GPS but from another base were simply entered into the original database. In general, it does not matter why this is so, the main thing is that this is quite a typical situation, so that a cache of the results obtained from the service will allow geocoding each pair of coordinates only once. A memory for the cache, we can afford.
Actually, the first modification of the algorithm was made trivial - all the results obtained from REST were added to the cache, and at first all points were searched for by coordinates in it. We didn’t even start a shared cache for all Spark processes - it had its own on each cluster node.
In this simple way, we were able to get the acceleration up to about 10 times, which roughly corresponds to the number of repetitions of coordinates in the original set. This was already acceptable, but still very slowly.
Well, our customer told us at this time, if we cannot calculate the addresses faster, can we quickly determine at least the city? And we set about ...
Simplified solution, we implement Geomerty API
What do we have to determine the city? We had the geometry of the regions of Russia, the administrative-territorial division, approximately to the areas of the city.
You can take this data for example here . What is there? This is a database of administrative borders of the Russian Federation, for levels from 2 (country) to 9 (urban districts). The format is either geojson or CSV (and the geometry itself is in wkt format). Total database of about 20 thousand records.
The new simplified solution of the problem looked like this:
- We load data ATD in Hive.
- For each point with coordinates we look for polygons in the table of territorial division, where this point is included.
- The polygons found are sorted by level.
As a result, at the exit we get something like: Russia, Central Federal District, Moscow, such and such administrative district, district such and such, that is, a list of territories, which our point belongs to.
ATD loading
To download CSV easier, we will apply kite . This tool can build a very good scheme for Hive based on the column headers in CSV. In fact, the import is reduced to three commands (one of which is repeated for each level file):
kite-tools csv-schema admin_level_2.csv --class al --delimiter \; >adminLevel.avrs kite-tools create dataset:hive:/default/levelswkt -s adminLevel.avrs kite-tools csv-import admin_level_2.csv dataset:hive:/default/levelswkt --delimiter \; ... kite-tools csv-import admin_level_10.csv dataset:hive:/default/levelswkt --delimiter \; What did we do here? The first team built us Avro-scheme for csv, for which we specified some parameters of the scheme (class, in this case), and field separator for CSV. Further, it is worth looking at the resulting scheme with eyes, and it is possible to make some corrections, because Kite does not look at all the lines of our file, but only at a certain sample, so sometimes it can make incorrect assumptions about the type of data (I saw three numbers - I decided that the column is numeric, and then the lines go).
Well, then on the basis of the scheme we create a dataset (this is the general term Kite, which generalizes the tables in Hive, the tables in HBase, and something else). In this case, default is the database (for Hive, too, as the schema), and levelswkt is the name of our table.
Well, the last commands upload CSV files to our dataset. After successfully completing the download, you can already execute the query:
select * from levelswkt; somewhere in Hue.
Work with geometry
To work with geometry in Java, we chose Esri's Java Geometry API (developer of ArcGIS). In principle, it was possible to take other frameworks, some choice of Open Source is available, for example, the well-known package JTS Topology Suite , or Geotools .
The first task allows us to cope with another framework from the same Esri company, called the Spatial Framework for Hadoop , and based on the first one. In fact, from it we need the so-called SerDe, the serialization-de-serialization module for Hive, which allows us to represent a pack of geojson files as a table in Hive, whose columns are taken from the geojson attributes. And the geometry itself becomes another column (with binary data). As a result, we have a table, one of the columns of which is the geometry of a certain region, and the rest are its attributes (name, level in ADT, etc.). This table is available to the Spark application.
If we upload to the database in CSV format, then we have a column where the geometries are in text form, in the WKT format. In this case, Spark can create a geometry object at runtime using the Geometry API.
We chose the CSV format (and WKT), for one simple reason - as everyone knows, Russia occupies a map on the map with the coordinates of Chukotka for the 180 meridian. The geojson format has a restriction - all polygons inside it should be limited to 180 degrees, and those that cross the 180 meridian need to be cut into two parts. As a result, when importing geometry into the Geometry API, we get an object for which the Geometry API incorrectly determines the Bounding Box (enclosing rectangle) for the Russian border. The answer is -180.180 in longitude. Which of course is not true - in reality, Russia takes about 20 to -170 degrees. This is the problem of the Geometry API, today it may have already been fixed, but then we had to bypass it.
WKT has no such problem. You ask, why do we need Bounding Box? I'll tell you later ;)
It remains to solve the so-called PIP problem, point in poligon. This is again a Java Geometry API, for us it is simple, one geometry of type Point, the second polygon (Multipoligon) for the region, and one contains method.
As a result, the second solution, and also on the forehead, looked like this: Spark application loads ADT, including geometry. Something of the Map type name-> geometry is built from them (in fact, a little more complicated, since the ADT are nested in each other, and we need to search only for those lower levels that are included in the upper one already found. As a result, there is a certain tree of geometries that according to the source data still need to build). And then we build Spark Dataset with our points, and for each point we apply our UDF, which checks the occurrence of the point in all geometries (by tree).
Writing a new version takes about a day of work, the benefit of the Spatial Framework for Hadoop bundle were quite good examples directly to solve the PIP problem (albeit by several other means).
We start, and ... oh, horror, it’s not so fast anymore. Watch again. It's time to think about optimization.
Optimized solution, QuadTree
The reason for the brakes is fairly obvious - say, the geometry of Russia, i.e. external borders, these are geojson megabytes, a hefty polygon, and not one. If we recall how the PIP problem is solved, then one of the well-known methods is to construct a ray from a point, say somewhere up, to infinity, and determine at how many points it crosses a polygon. If the number of points is even, the point is outside the polygon, if odd is inside.
Let's say the description of the wiki .
It is clear that for a huge polygon the solution of the intersection problem is complicated by as many times as we have straight line segments in the polygon. Therefore, it is desirable to somehow reject those polygons, in which the point can not obviously enter. And as an additional lifehack, it is possible to reject the check for entry into the borders of Russia (if we know that all the coordinates are obviously included in it).
For this we need a tree of quadrants . Fortunately, the implementation is all in the same Geometry API (and much else where).
The tree-based solution looks like this:
- Load geometry ADT
- For each geometry, we define an enclosing rectangle.
- We place it in QuadTree, we receive in the answer an index
- index remember
Further, when processing points:
- Ask QuadTree which of the known geometries can include a dot.
- Get Geometry Indexes
- Only for them we check the occurrence by solving the PIP problem.
It all takes another four hours of development. Run again, and we see that the task was completed somehow very quickly. We check - everything is fine, the solution is received. And all - in a couple of minutes. QuadTree gives us acceleration by several orders of magnitude.
Results
So what we got in the end? We got a reverse geocoding mechanism, which is effectively parallelized on the Hadoop cluster, and which solves our original problem from 200 thousand points in about minutes. Those. we can safely apply this solution to millions of points.
What are the limitations of this solution? First, the obvious - it is based on the data available to us ATD, which a) may not be relevant b) limited only by Russia.
And second, we are not able to solve the reverse geocoding problem for objects other than closed polygons. And that means - for the streets as well.
Development
What can be done with this?
To have actual geometry of the ADT, the simplest thing is to take them from OpenStreetMap. Of course, they will have to work a little, but this is a completely solvable task. If there is interest, I will tell you about the task of loading OpenStreetMap data into the Hadoop cluster some other time.
What can be done for streets and houses? In principle, the streets are in the same OSM. But these are not closed structures, but lines. To determine that the point is “close” to a certain street, you will have to build a landfill for the street from points equidistant from it, and check that it is hit. As a result, such a sausage turns out ... it looks like this:
How close is the point? This is a parameter, and roughly corresponds to the radius within which it searches for ArcGIS objects, and which I mentioned at the very beginning.
Thus we find the streets, the distance from the point to which is less than a certain limit (say, 100 meters). And the smaller this limit is, the faster the algorithm works, but the greater the chance that you will not find a single match.
The obvious problem is that it is impossible to calculate these so-called buffers in advance - their size is a service parameter. They need to be built on the fly, after we have determined the desired area of the city, and have selected the streets that pass through this area from the OSM base. Streets, however, can be selected and in advance.
Houses that are located in the area found are not moving anywhere either, so their list can be built in advance, but hitting them anyway will have to be considered on the fly.
That is, you need to first build an index of the form "district of the city" -> a list of houses with references to the geometry, and a similar one for the list of streets.
And as soon as we have determined the area, we get a list of houses and streets, build borders along the streets, and already for them we solve the PIP problem (probably, using the same optimizations as for the borders of the regions). In this case, a quad tree for houses can obviously also be built in advance, and saved somewhere.
Our main goal is to minimize the amount of calculations, while maximizing and saving in advance everything that can be calculated and saved. In this case, the process will consist of the slow stage of building indexes, and the second stage of calculation, which will already pass quickly, close to the online version.
Source: https://habr.com/ru/post/438046/