Benchmark as a basis for deciding to change the code
Bill Kennedy in one of the lectures of his wonderful course Ultimate Go programming said:
Here, in all the slice elements of the builds returned from the database, PatchURLs is replaced with ReversePatchURLs , ExtractedSize - with RPatchExtractedSize and reversed - the order of the elements changes so that the last element becomes the first and the first element is the last.
In my opinion, the source code is a bit difficult to read and can be optimized. This code performs a simple algorithm consisting of two logical parts: changing slice elements and sorting. But in order for a programmer to isolate these two components, it will take time.
Despite the fact that both parts are important, the reverse is not as emphasized in the code as we would like. It is scattered in three lines separated from each other: initializing a new slice, iterating an existing slice in reverse order, adding an element to the end of a new slice. Nevertheless, the undoubted advantages of this code cannot be ignored: the code is working and tested, and speaking objectively, it is quite adequate. The subjective perception of code by an individual developer cannot serve as an excuse for rewriting it. Unfortunately or fortunately, we don’t rewrite the code just because we simply don’t like it (or, as often happens, simply because it’s not ours, see Fatal flaw ).
But what if we can not only improve the perception of the code, but also significantly speed it up? This is a completely different matter. You can offer several alternative algorithms that perform the functionality laid down in the code.
The first option: enumeration of all elements in the range ; To reverse the initial slice in each iteration, we add an element to the beginning of the final array. So we could get rid of the cumbersome for , variable i , use the len function, hard to read elements from the end, and also reduce the amount of code by two lines (from seven lines to five), and the smaller the code, the less likely it is an error.
By removing the slice iteration from the end, we clearly distinguished the operations of changing the elements (3rd row) and reverse the original array (4th row).
The main idea of the second option is to further spread the change of elements and sorting. First we iterate over the elements and change them, and then sort the slice by a separate operation. This method will require an additional implementation of the sorting interface for the slice, but it will increase readability and allow you to completely separate and isolate the reverse from changing elements, and the Reverse method will unambiguously point the reader to the desired result.
The third option is almost a repetition of the second, but sort.Slice is used for sorting, which increases the amount of code by one line, but avoids the additional implementation of the sorting interface.
At first glance, in terms of internal complexity, the number of iterations, the functions used, the initial code and the first algorithm are close; The second and third options may seem more complicated, but it is still impossible to say which of the four options will be optimal.
So, we have forbidden ourselves to make decisions based on assumptions that are not supported by evidence, but it is obvious that the most interesting thing here is how the append function behaves when adding an element to the end and to the beginning of the slice. After all, in fact, this function is not as simple as it seems.
Append works as follows : it either adds a new element to the existing slice in memory, if its capacity is greater than the total length, or reserves space in the memory for a new slice, copying the data from the first slice into it, adding the second data and returning the result slice.
The most interesting feature of this function is the algorithm used to reserve memory for a new array. Since the most expensive operation is to allocate a new chunk of memory, in order to make the append operation cheaper, the Go developers went for a little trick. Initially, in order not to re-reserve the memory every time an element is added, the memory is allocated with a certain margin - twice the initial one, but after a certain number of elements the volume of the newly reserved memory section becomes not more than twice, but by 25%.
Given the new understanding of the append function , the answer to the question: “What will be faster: add one element to the end of an existing slice or add an existing slice to a slice from one element?” Is already more transparent. It can be assumed that in the second case, compared with the first, there will be more memory allocations, which will directly affect the speed of work.
So we smoothly approached the benchmarks. Using benchmarks, you can estimate the load of the algorithm on the most critical resources, such as runtime and RAM.
Let's write a benchmark for evaluating all four of our algorithms, at the same time we will evaluate what increase we can refuse from sorting (in order to understand how much of the total time is spent on sorting). Benchmark Code:
Run the benchmark with the go test command -bench =. -benchmem .
The results of calculations for slices of 10, 100, 1000, 10 000 and 100 000 elements are shown in the graph below, where F1 is the initial algorithm, F2 is the addition of an element to the beginning of the array, F3 is the use of sort.Reverse for sorting, F4 is the use of sort.Slice , F5 - rejection of sorting.
Operation time

Number of memory allocations
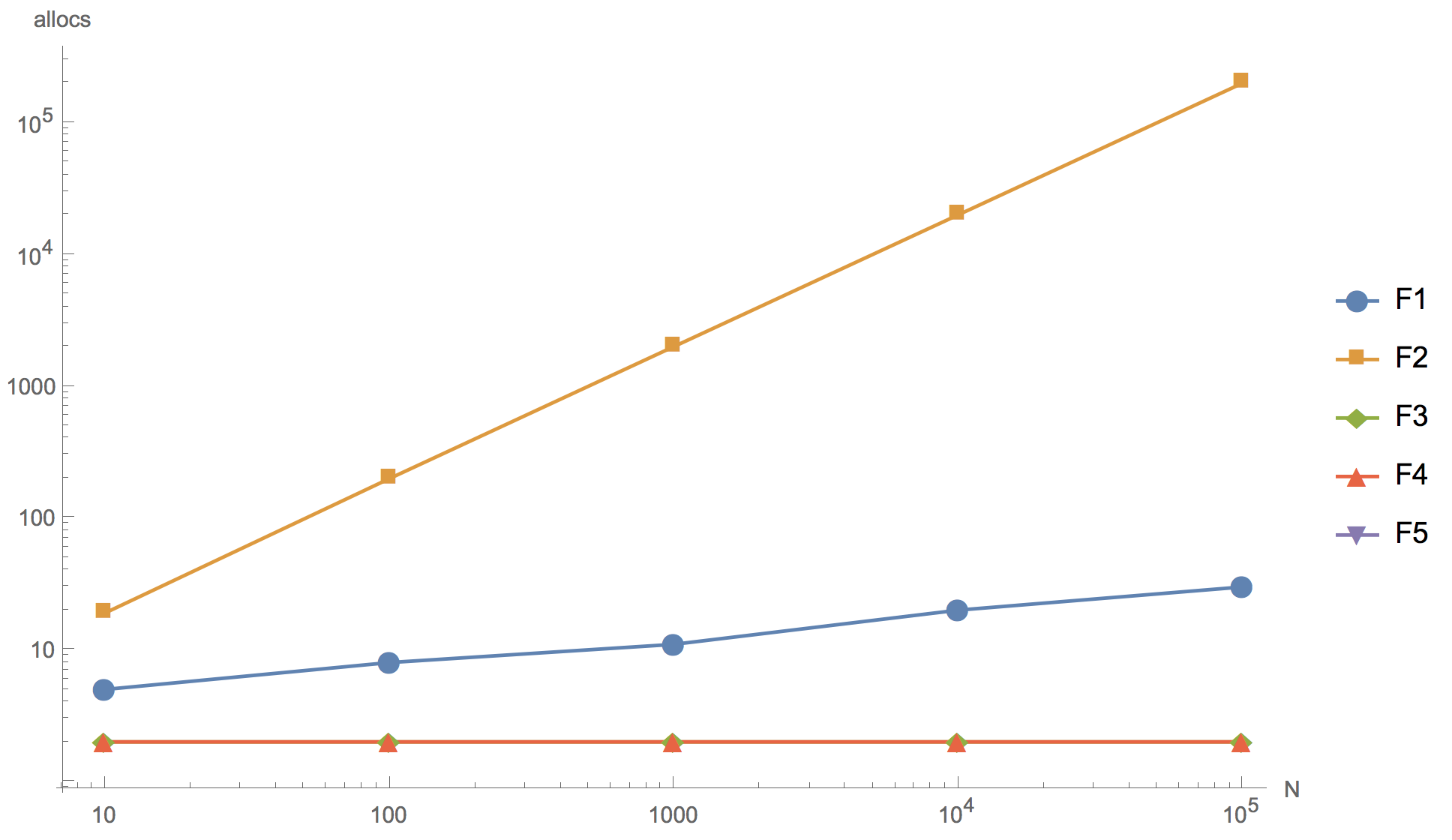
As can be seen from the graph, you can increase the array, but the final result is already in principle distinguishable on a slice of 10 elements. None of the proposed alternative algorithms (F2, F3, F4) could not surpass the original algorithm (F1) in speed. Even in spite of the fact that for all but F2, the number of memory allocations is slightly less than that of the original. The first algorithm (F2) with the addition of an element to the beginning of the slice turned out to be the most inefficient: as it was supposed, there are too many memory allocations in it, so much so that it cannot be used in product development. The algorithm using the built-in reverse sorting function (F3) is significantly slower than the original one. And only the algorithm with sort.Slice sorting is comparable in speed with the original algorithm, but it is slightly inferior to it.
You may also notice that the rejection of sorting (F5) gives a significant acceleration. Therefore, if you really want to rewrite the code, then you can go in this direction, for example, by raising the initial slice builds from the database, use sorting by id DESC in the query instead of ASC. But at the same time, we are forced to go beyond the boundaries of the code section under consideration, which entails the risk of introducing multiple changes.
Write benchmarks.
It makes little sense to spend your time thinking about whether a particular code will be faster. Information from the Internet, judgments of colleagues and other people, no matter how authoritative they may be, serve as supporting arguments, but the role of the main judge, who decides whether or not the new algorithm should be, should remain behind benchmarks.
Go only at first glance rather simple language. Comprehensive 80-20 rule applies here. These 20% are the subtleties of the internal structure of the language, the knowledge of which distinguishes a beginner from an experienced developer. The practice of writing benchmarks to resolve their questions is one of the cheapest and most effective ways to get both an answer and a deeper understanding of the internal structure and principles of the Go language.
Many developers strive to optimize their code. They take the line and rewrite it, saying that it will be faster this way. Need to stop. To say that one or another code is faster, it is possible only after it has been profiled and benchmarks are made. Divination is not the right approach to writing code.I have long wanted on a practical example to demonstrate how this can work. And the other day, my attention was attracted by the following code, which just could be used as such an example:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber) tempList := model.BuildsList{} for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchURLs = b.ReversePatchURLs b.ExtractedSize = b.RPatchExtractedSize tempList = append(tempList, b) } Here, in all the slice elements of the builds returned from the database, PatchURLs is replaced with ReversePatchURLs , ExtractedSize - with RPatchExtractedSize and reversed - the order of the elements changes so that the last element becomes the first and the first element is the last.
In my opinion, the source code is a bit difficult to read and can be optimized. This code performs a simple algorithm consisting of two logical parts: changing slice elements and sorting. But in order for a programmer to isolate these two components, it will take time.
Despite the fact that both parts are important, the reverse is not as emphasized in the code as we would like. It is scattered in three lines separated from each other: initializing a new slice, iterating an existing slice in reverse order, adding an element to the end of a new slice. Nevertheless, the undoubted advantages of this code cannot be ignored: the code is working and tested, and speaking objectively, it is quite adequate. The subjective perception of code by an individual developer cannot serve as an excuse for rewriting it. Unfortunately or fortunately, we don’t rewrite the code just because we simply don’t like it (or, as often happens, simply because it’s not ours, see Fatal flaw ).
But what if we can not only improve the perception of the code, but also significantly speed it up? This is a completely different matter. You can offer several alternative algorithms that perform the functionality laid down in the code.
The first option: enumeration of all elements in the range ; To reverse the initial slice in each iteration, we add an element to the beginning of the final array. So we could get rid of the cumbersome for , variable i , use the len function, hard to read elements from the end, and also reduce the amount of code by two lines (from seven lines to five), and the smaller the code, the less likely it is an error.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*store.Build{build}, tempList...) } By removing the slice iteration from the end, we clearly distinguished the operations of changing the elements (3rd row) and reverse the original array (4th row).
The main idea of the second option is to further spread the change of elements and sorting. First we iterate over the elements and change them, and then sort the slice by a separate operation. This method will require an additional implementation of the sorting interface for the slice, but it will increase readability and allow you to completely separate and isolate the reverse from changing elements, and the Reverse method will unambiguously point the reader to the desired result.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(sort.IntSlice(keys))) The third option is almost a repetition of the second, but sort.Slice is used for sorting, which increases the amount of code by one line, but avoids the additional implementation of the sorting interface.
for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) At first glance, in terms of internal complexity, the number of iterations, the functions used, the initial code and the first algorithm are close; The second and third options may seem more complicated, but it is still impossible to say which of the four options will be optimal.
So, we have forbidden ourselves to make decisions based on assumptions that are not supported by evidence, but it is obvious that the most interesting thing here is how the append function behaves when adding an element to the end and to the beginning of the slice. After all, in fact, this function is not as simple as it seems.
Append works as follows : it either adds a new element to the existing slice in memory, if its capacity is greater than the total length, or reserves space in the memory for a new slice, copying the data from the first slice into it, adding the second data and returning the result slice.
The most interesting feature of this function is the algorithm used to reserve memory for a new array. Since the most expensive operation is to allocate a new chunk of memory, in order to make the append operation cheaper, the Go developers went for a little trick. Initially, in order not to re-reserve the memory every time an element is added, the memory is allocated with a certain margin - twice the initial one, but after a certain number of elements the volume of the newly reserved memory section becomes not more than twice, but by 25%.
Given the new understanding of the append function , the answer to the question: “What will be faster: add one element to the end of an existing slice or add an existing slice to a slice from one element?” Is already more transparent. It can be assumed that in the second case, compared with the first, there will be more memory allocations, which will directly affect the speed of work.
So we smoothly approached the benchmarks. Using benchmarks, you can estimate the load of the algorithm on the most critical resources, such as runtime and RAM.
Let's write a benchmark for evaluating all four of our algorithms, at the same time we will evaluate what increase we can refuse from sorting (in order to understand how much of the total time is spent on sorting). Benchmark Code:
package services import ( "testing" "sort" ) type Build struct { Id int ExtractedSize int64 PatchUrls string ReversePatchUrls string RPatchExtractedSize int64 } type Builds []*Build func (a Builds) Len() int { return len(a) } func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id } func prepare() Builds { var builds Builds for i := 0; i < 100000; i++ { builds = append(builds, &Build{Id: i}) } return builds } func BenchmarkF1(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize tempList = append(tempList, b) } } } func BenchmarkF2(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*Build{build}, tempList...) } } } func BenchmarkF3(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(builds)) } } func BenchmarkF4(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) } } func BenchmarkF5(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } } } Run the benchmark with the go test command -bench =. -benchmem .
The results of calculations for slices of 10, 100, 1000, 10 000 and 100 000 elements are shown in the graph below, where F1 is the initial algorithm, F2 is the addition of an element to the beginning of the array, F3 is the use of sort.Reverse for sorting, F4 is the use of sort.Slice , F5 - rejection of sorting.
Operation time
Number of memory allocations
As can be seen from the graph, you can increase the array, but the final result is already in principle distinguishable on a slice of 10 elements. None of the proposed alternative algorithms (F2, F3, F4) could not surpass the original algorithm (F1) in speed. Even in spite of the fact that for all but F2, the number of memory allocations is slightly less than that of the original. The first algorithm (F2) with the addition of an element to the beginning of the slice turned out to be the most inefficient: as it was supposed, there are too many memory allocations in it, so much so that it cannot be used in product development. The algorithm using the built-in reverse sorting function (F3) is significantly slower than the original one. And only the algorithm with sort.Slice sorting is comparable in speed with the original algorithm, but it is slightly inferior to it.
You may also notice that the rejection of sorting (F5) gives a significant acceleration. Therefore, if you really want to rewrite the code, then you can go in this direction, for example, by raising the initial slice builds from the database, use sorting by id DESC in the query instead of ASC. But at the same time, we are forced to go beyond the boundaries of the code section under consideration, which entails the risk of introducing multiple changes.
findings
Write benchmarks.
It makes little sense to spend your time thinking about whether a particular code will be faster. Information from the Internet, judgments of colleagues and other people, no matter how authoritative they may be, serve as supporting arguments, but the role of the main judge, who decides whether or not the new algorithm should be, should remain behind benchmarks.
Go only at first glance rather simple language. Comprehensive 80-20 rule applies here. These 20% are the subtleties of the internal structure of the language, the knowledge of which distinguishes a beginner from an experienced developer. The practice of writing benchmarks to resolve their questions is one of the cheapest and most effective ways to get both an answer and a deeper understanding of the internal structure and principles of the Go language.
Source: https://habr.com/ru/post/438446/