Writing XGBoost from scratch - part 1: decision trees
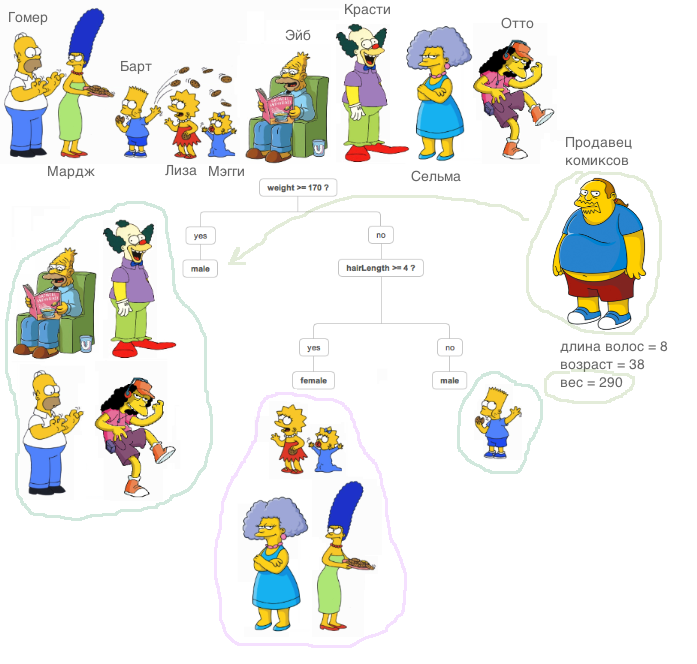
Hi, Habr!
After numerous searches for high-quality guides on decision trees and ensemble algorithms (boosting, decisive forest, etc.) with their direct implementation in programming languages, and without finding anything (whoever finds — write in the comments, maybe I’ll get something new) I decided to make my own guide how I would like it to be. The task in words is simple, but as you know, the devil is in the details, of which there are a lot of algorithms with trees.
Since the topic is quite extensive, it will be very difficult to fit everything into one article, so there will be two publications: the first is devoted to trees, and the second part will be devoted to the implementation of the gradient boosting algorithm. All the material presented here is compiled and executed on the basis of open sources, my code, the code of colleagues and friends. Immediately I warn you, there will be a lot of code.
So you need to know and be able to learn how to write from scratch your ensemble algorithms with decision trees? Since an ensemble of algorithms is nothing more than a composition of “weak algorithms”, then to write a good ensemble requires good “weak algorithms”, we will analyze them in detail in this article. As the name implies, these are decisive trees, and moving from simple to complex, we will learn how to write them. In this case, the emphasis will be placed directly on the implementation, the whole theory will be presented to a minimum, basically I will give references to materials for independent study.
To assimilate the material, you need to understand how good or bad our algorithm is. We will understand very simply - let's fix some specific data set and compare our algorithms with the algorithms of the trees from Sklearn (well, what about without this library). We will compare many things: the complexity of the algorithm, the metrics on the data, the running time, etc.
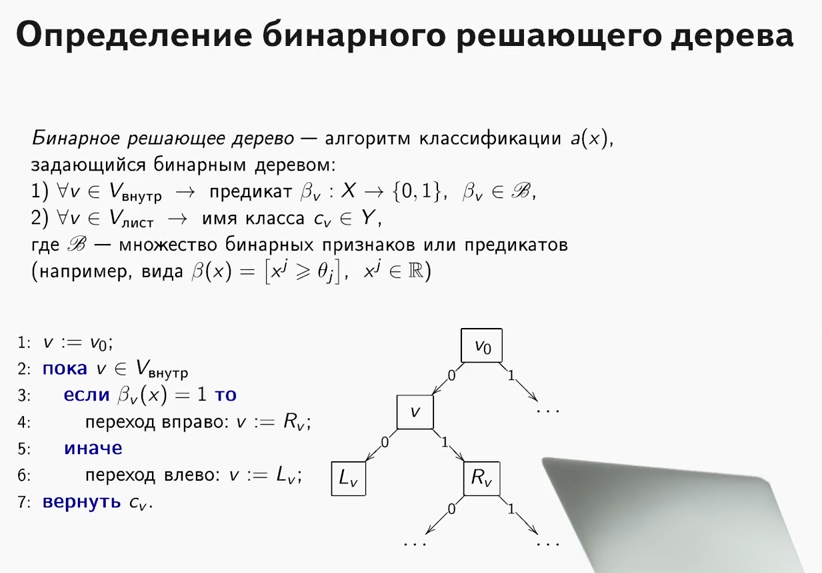
What is the decisive tree? Very good material, where the principle of the work of the decision tree is explained, is contained in the ODS course (by the way, a cool course, I recommend to those who begin their acquaintance with ML).
A very important clarification: in all the cases described below, all signs will be real, we will not do special transformations with data outside the algorithms (we are comparing algorithms, not datasets).
Now let's learn how to solve a regression problem with decision trees. As entropy we will use the MSE metric.
We implement a very simple
RegressionTree class, which is based on a recursive approach. Intentionally we will start with a very inefficient, but easy to understand implementation of this class, in order to be able to further improve it.1. Class RegressionTree ()
class RegressionTree(): ''' Класс RegressionTree решает задачу регрессии. Основан на рекурсивных вызовах, когда прописываются условия выхода из рекурсии. ''' def __init__(self, max_depth=3, n_epoch=10, min_size=8): ''' Объявляем переменные класса. ''' self.max_depth = max_depth # максимальная глубина self.min_size = min_size # минимальный размер поддерева self.value = 0 # значение в поддереве (среднее по всем листьям) self.feature_idx = -1 # номер лучшего признака self.feature_threshold = 0 # значение лучшего признака self.left = None # левый потомок self.right = None # правый потомок def fit(self, X, y): ''' Процедура обучения дерева. На выходе получим обученную модель. ''' # инициализируем начальные значения self.value = y.mean() base_error = ((y - self.value) ** 2).sum() error = base_error flag = 0 # ошибки в левом и правом поддереве prev_error_left = base_error prev_error_right = 0 # если дошли до глубины 0 - выходим if self.max_depth <= 1: return dim_shape = X.shape[1] # значения в левом и правом поддереве left_value = 0 right_value = 0 # начинаем цикл по признакам for feat in range(dim_shape): # сортируем признаки idxs = np.argsort(X[:, feat]) # количество сэмплов в левом и правом поддереве N = X.shape[0] N1, N2 = N, 0 thres = 1 # начинаем проходиться по значениям признака while thres < N - 1: N1 -= 1 N2 += 1 idx = idxs[thres] x = X[idx, feat] # пропускаем одинаковые признаки if thres < N - 1 and x == X[idxs[thres + 1], feat]: thres += 1 continue # данные, которые получаются у нас в результате такого сплита target_right = y[idxs][:thres] target_left = y[idxs][thres:] mean_right = y[idxs][:thres].mean(), mean_left = y[idxs][thres:].mean() # на этом шаге уже нужно считать ошибку - # генерируем предикты (среднее в потомках) left_shape = target_left.shape[0] right_shape = target_right.shape[0] mean_left_array = [mean_left for _ in range(left_shape)] mean_right_array = [mean_right for _ in range(right_shape)] # считаем ошибку слева и справа prev_error_left = N1/N * mse(target_left, mean_left_array) prev_error_right = N2/N * mse(target_right, mean_right_array) # если выполняются условия сплита, то обновляем if (prev_error_left + prev_error_right < error): if (min(N1,N2) > self.min_size): self.feature_idx = feat self.feature_threshold = x left_value = mean_left right_value = mean_right flag = 1 error = prev_error_left + prev_error_right thres += 1 # если не нашли лучший сплит, выходим if self.feature_idx == -1: return # дошли сюда - есть хорошее разбиение, нужно обучать дальше # инициализируем потомков - те же деревья решений self.left = RegressionTree(self.max_depth - 1) self.left.value = left_value self.right = RegressionTree(self.max_depth - 1) self.right.value = right_value # индексы потомков idxs_l = (X[:, self.feature_idx] > self.feature_threshold) idxs_r = (X[:, self.feature_idx] <= self.feature_threshold) # обучаем self.left.fit(X[idxs_l, :], y[idxs_l]) self.right.fit(X[idxs_r, :], y[idxs_r]) def __predict(self, x): ''' Функция для генерирования предсказания - смотрим узлы, идем в соответствующих потомков и смотрим в конце self.value - это и будет ответом. ''' if self.feature_idx == -1: return self.value if x[self.feature_idx] > self.feature_threshold: return self.left.__predict(x) else: return self.right.__predict(x) def predict(self, X): ''' Предикт для матрицы - просто для каждой строчки вызываем __predict(). ''' y = np.zeros(X.shape[0]) for i in range(X.shape[0]): y[i] = self.__predict(X[i]) return y Briefly explain what each method does here.
The
fit method, as the name implies, teaches the model. The training sample is sent to the input and the tree learning procedure takes place. Sorting signs, we are looking for the best partitioning of the tree in terms of reduced entropy, in this case mse . Determining that we managed to find a good split is very simple; two conditions are enough. We do not want few objects to fall into the partition (protection against retraining), and the weighted average error by mse must be less than the error that is now in the tree - we are looking for that very increase in information gain . Having thus all the signs and all the unique values for them, we will sort out all the options and choose the best partition. And further we do the recursive call on the received partitions until the conditions for exit from recursion are fulfilled.The
__predict method, as the name implies, makes a prediction. Having received an object as input, it goes along the nodes of the obtained tree - each node has a sign number and a value on it, and depending on what value the incoming method of the object has on this sign, we go either to the right descendant or to the left, until we reach the sheet, in which will be the answer for this object.The
predict method does the same as the last method, only for a group of objects.We import a well-known set of data on homes in California. This is a common dataset with data and target for solving a regression problem.
data = datasets.fetch_california_housing() X = np.array(data.data) y = np.array(data.target) Well, let's start the comparison! First, let's see how fast the algorithm learns. We will set a single parameter
max_depth in ourselves and in Sklearn, let it be equal to 2. %%time A = RegressionTree(2) # это наш алгоритм A.fit(X,y) from sklearn.tree import DecisionTreeRegressor %%time model = DecisionTreeRegressor(max_depth=2) # из Sklearn model.fit(X,y) The following is displayed:
- For our algorithm, CPU times: user 4min 47s, sys: 8.25 ms, total: 4min 47s
Wall time: 4min 47s - For Sklearn - CPU times: user 53.5 ms, sys: 0 ns, total: 53.5 ms
Wall time: 53.4 ms
As you can see, the algorithm learns thousands of times more slowly. What is the reason? Let's figure it out.
Recall how the procedure for finding the best partition is arranged. As is known, in the general case, with the size of objects N and with the number of signs d , the difficulty of finding the best split is O(N∗logN∗d) .
Where does this complexity come from?
First, in order to effectively recalculate the error, it is necessary to sort all the columns before passing by the feature in order to move from the smallest to the largest. Since we do this for every attribute, this creates an appropriate complexity. As you can see, we sort the signs, but the whole trouble lies in recalculating the error - every time we drive the data into the
mse method, which works beyond the line. This makes the error recalculation so inefficient! After all, then the difficulty of finding a split increases to O(N2∗d) that when large N tremendously slows down the algorithm. Therefore, smoothly proceed to the next item.2. RegressionTree () class with quick error recalculation
What should I do to quickly recalculate the error? Take a pen and paper, and paint how we should change the formulas.
For example, at some step there is already an error calculated for N objects. It has the following formula: sumni=1(yi− frac sumNi=1yiN)2 . Here it is necessary to divide by N but for now let's put it down. We want to quickly get this error - sumN−1i=1(yi− frac sumN−1i=1yiN−1)2 , that is, let's throw the error that the element introduces yi in another part.
Since we are throwing the object, the error must be recalculated in two places - on the right side (excluding this object), and on the left side (taking this object into account). But without loss of generality, we derive only one formula, since they will be similar.
Since we work with
mse , we are not lucky: it’s quite difficult to derive a quick error recalculation, but when working with other metrics (for example, the Gini criterion, if we solve the classification problem), the quick recalculation output is much easier.Well, let's begin to derive formulas!
sumNi=1(yi− frac sumNi=1yiN)2= sumN−1i=1(yi− frac sumNi=1yiN)2+(yN− frac sumNi=1yiN)2
Let's write out the first member:
sumN−1i=1(yi− frac sumNi=1yiN)2= sumN−1i=1(yi− frac sumN−1i=1yi+yNN)2= sumN−1i=1( fracNyi− sumN−1i=1yiN− fracyNN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN− fracyN−yiN)2=sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN)2−2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN+( fracyN−yiN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN−( fracyN−yiN)2)= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN−1)2∗( fracN−1N)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN−−( fracyN−yiN)2)
Phew, just a little bit left. It remains only to express the required amount.
sumNi=1(yi− frac sumNi=1yiN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN−1)2∗( fracN−1N)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN)( fracyN−yiN)−( fracyN−yiN)2)+(yN− sumNi=1 fracyiN)2
And then it is clear how to express the necessary amount. To recalculate the error, we need to store only the amounts of the elements on the right and left, as well as the new element itself, which entered the input. Now the error is recalculated for O(1) .
Well, let's implement this in code.
class RegressionTreeFastMse(): ''' Класс RegressionTree с быстрым пересчетом ошибки. Сложность пересчета ошибки на каждой итерации составляет O(1). ''' # объявляем характеристики класса def __init__(self, max_depth=3, min_size=10): self.max_depth = max_depth self.min_size = min_size self.value = 0 self.feature_idx = -1 self.feature_threshold = 0 self.left = None self.right = None # процедура обучения - сюда передается обучающая выборка def fit(self, X, y): # начальное значение - среднее значение y self.value = y.mean() # начальная ошибка - mse между значением в листе (пока нет # разбиения, это среднее по всем объектам) и объектами base_error = ((y - self.value) ** 2).sum() error = base_error flag = 0 # пришли в максимальную глубину if self.max_depth <= 1: return dim_shape = X.shape[1] left_value, right_value = 0, 0 for feat in range(dim_shape): prev_error1, prev_error2 = base_error, 0 idxs = np.argsort(X[:, feat]) # переменные для быстрого переброса суммы mean1, mean2 = y.mean(), 0 sm1, sm2 = y.sum(), 0 N = X.shape[0] N1, N2 = N, 0 thres = 1 while thres < N - 1: N1 -= 1 N2 += 1 idx = idxs[thres] x = X[idx, feat] # вычисляем дельты - по ним в основном будет делаться переброс delta1 = (sm1 - y[idx]) * 1.0 / N1 - mean1 delta2 = (sm2 + y[idx]) * 1.0 / N2 - mean2 # увеличиваем суммы sm1 -= y[idx] sm2 += y[idx] # пересчитываем ошибки за O(1) prev_error1 += (delta1**2) * N1 prev_error1 -= (y[idx] - mean1)**2 prev_error1 -= 2 * delta1 * (sm1 - mean1 * N1) mean1 = sm1/N1 prev_error2 += (delta2**2) * N2 prev_error2 += (y[idx] - mean2)**2 prev_error2 -= 2 * delta2 * (sm2 - mean2 * N2) mean2 = sm2/N2 # пропускаем близкие друг к другу значения if thres < N - 1 and np.abs(x - X[idxs[thres + 1], feat]) < 1e-5: thres += 1 continue # 2 условия, чтобы осуществить сплит - уменьшение ошибки # и минимальное кол-о эл-в в каждом листе if (prev_error1 + prev_error2 < error): if (min(N1,N2) > self.min_size): # переопределяем самый лучший признак и границу по нему self.feature_idx, self.feature_threshold = feat, x # переопределяем значения в листах left_value, right_value = mean1, mean2 # флаг - значит сделали хороший сплит flag = 1 error = prev_error1 + prev_error2 thres += 1 # ничего не разделили, выходим if self.feature_idx == -1: return self.left = RegressionTreeFastMse(self.max_depth - 1) # print ("Левое поддерево с глубиной %d"%(self.max_depth - 1)) self.left.value = left_value self.right = RegressionTreeFastMse(self.max_depth - 1) # print ("Правое поддерево с глубиной %d"%(self.max_depth - 1)) self.right.value = right_value idxs_l = (X[:, self.feature_idx] > self.feature_threshold) idxs_r = (X[:, self.feature_idx] <= self.feature_threshold) self.left.fit(X[idxs_l, :], y[idxs_l]) self.right.fit(X[idxs_r, :], y[idxs_r]) def __predict(self, x): if self.feature_idx == -1: return self.value if x[self.feature_idx] > self.feature_threshold: return self.left.__predict(x) else: return self.right.__predict(x) def predict(self, X): y = np.zeros(X.shape[0]) for i in range(X.shape[0]): y[i] = self.__predict(X[i]) return y Let's measure the time that is spent on training now and compare it with the analog from Sklearn.
%%time A = RegressionTreeFastMse(4, min_size=5) A.fit(X,y) test_mytree = A.predict(X) test_mytree %%time model = DecisionTreeRegressor(max_depth=4) model.fit(X,y) test_sklearn = model.predict(X) - For our algorithm, it turns out - CPU times: user 3.11 s, sys: 2.7 ms, total: 3.11 s
Wall time: 3.11 s. - For an algorithm from Sklearn - CPU times: user 45.9 ms, sys: 1.09 ms, total: 47 ms
Wall time: 45.7 ms.
The results are already more pleasant. Well, let's further improve the algorithm.
3. Class RegressionTree () with linear combinations of signs
Now our algorithm does not use the relationship between the signs. We fix one feature and see only orthogonal partitions of the space. How to learn to use linear interrelations between signs? That is, look for the best partitions not like afeat<x , but sumKi=1bi∗ai<x where K - is some number less than the dimension of our space?
There are many options, I will highlight the two most interesting from my point of view. Both of these approaches are outlined in the Friedman book (he invented these trees).
I will give a picture so that it is clear what is meant:

First, you can try to find these linear partitions algorithmically. It is clear that it is impossible to sort through all linear combinations, because there are an infinite number of them, therefore such an algorithm must be greedy, that is, at each iteration it is possible to improve the result of the previous iteration. The main idea of this algorithm can be found in the booklet; I will also leave here a link to the repository of my friend and colleague with the implementation of this algorithm.
Secondly, if we do not go far from the idea of finding the best orthogonal partition, then how can we modify the data so that the information about the relationship between the signs is used and the search is by orthogonal partitions? That's right, to make some transformations of the original signs into new ones. For example, you can take the sum of some combination of signs and look for partitions already on them. Such a method is worse in the algorithmic concept, but it performs its task — it searches for orthogonal partitions already in some interrelationships of features.
Well, let's realize - we will add as various signs, for example, all possible combinations of the amounts of signs i,j where I<j . I note that the complexity of the algorithm in this case will increase, it is clear how many times. Well, to be considered faster, we will use cython.
%load_ext Cython %%cython -a import itertools import numpy as np cimport numpy as np from itertools import * cdef class RegressionTreeCython: cdef public int max_depth cdef public int feature_idx cdef public int min_size cdef public int averages cdef public np.float64_t feature_threshold cdef public np.float64_t value cpdef RegressionTreeCython left cpdef RegressionTreeCython right def __init__(self, max_depth=3, min_size=4, averages=1): self.max_depth = max_depth self.min_size = min_size self.value = 0 self.averages = averages self.feature_idx = -1 self.feature_threshold = 0 self.left = None self.right = None def data_transform(self, np.ndarray[np.float64_t, ndim=2] X, list index_tuples): # преобразование данных - дополнение новыми признаками в виде суммы for i in index_tuples: # добавляем суммы, индексы которых переданы в качестве аргумента X = np.hstack((X, X[:, i[0]:(i[1]+1)].sum(axis=1).reshape(X.shape[0],1))) return X def fit(self, np.ndarray[np.float64_t, ndim=2] X, np.ndarray[np.float64_t, ndim=1] y): cpdef np.float64_t mean1 = 0.0 cpdef np.float64_t mean2 = 0.0 cpdef long N = X.shape[0] cpdef long N1 = X.shape[0] cpdef long N2 = 0 cpdef np.float64_t delta1 = 0.0 cpdef np.float64_t delta2 = 0.0 cpdef np.float64_t sm1 = 0.0 cpdef np.float64_t sm2 = 0.0 cpdef list index_tuples cpdef list stuff cpdef long idx = 0 cpdef np.float64_t prev_error1 = 0.0 cpdef np.float64_t prev_error2 = 0.0 cpdef long thres = 0 cpdef np.float64_t error = 0.0 cpdef np.ndarray[long, ndim=1] idxs cpdef np.float64_t x = 0.0 # такую процедуру необходимо сделать только один раз # генерируем индексы, по которым суммируем признаки if self.averages: stuff = list(range(0,X.shape[1],1)) index_tuples = list(combinations(stuff,2)) # выполняем преобразование данных X = self.data_transform(X, index_tuples) # начальное значение - среднее значение y self.value = y.mean() # начальная ошибка - mse между значением в листе (пока нет разбиения, # это среднее по всем объектам) и объектами base_error = ((y - self.value) ** 2).sum() error = base_error flag = 0 # пришли на максимальную глубину if self.max_depth <= 1: return dim_shape = X.shape[1] left_value, right_value = 0, 0 for feat in range(dim_shape): prev_error1, prev_error2 = base_error, 0 idxs = np.argsort(X[:, feat]) # переменные для быстрого переброса суммы mean1, mean2 = y.mean(), 0 sm1, sm2 = y.sum(), 0 N = X.shape[0] N1, N2 = N, 0 thres = 1 while thres < N - 1: N1 -= 1 N2 += 1 idx = idxs[thres] x = X[idx, feat] # вычисляем дельты - по ним в основном будет делаться переброс delta1 = (sm1 - y[idx]) * 1.0 / N1 - mean1 delta2 = (sm2 + y[idx]) * 1.0 / N2 - mean2 # увеличиваем суммы sm1 -= y[idx] sm2 += y[idx] # пересчитываем ошибки за O(1) prev_error1 += (delta1**2) * N1 prev_error1 -= (y[idx] - mean1)**2 prev_error1 -= 2 * delta1 * (sm1 - mean1 * N1) mean1 = sm1/N1 prev_error2 += (delta2**2) * N2 prev_error2 += (y[idx] - mean2)**2 prev_error2 -= 2 * delta2 * (sm2 - mean2 * N2) mean2 = sm2/N2 # пропускаем близкие друг к другу значения if thres < N - 1 and np.abs(x - X[idxs[thres + 1], feat]) < 1e-5: thres += 1 continue # 2 условия осуществления сплита - уменьшение ошибки # и минимальное кол-во элементов в в каждом листе if (prev_error1 + prev_error2 < error): if (min(N1,N2) > self.min_size): # переопределяем самый лучший признак и границу по нему self.feature_idx, self.feature_threshold = feat, x # переопределяем значения в листах left_value, right_value = mean1, mean2 # флаг - значит сделали хороший сплит flag = 1 error = prev_error1 + prev_error2 thres += 1 # self.feature_idx - индекс самой крутой разделяющей фичи. # Если это какая-то из сумм, и если есть какое-то экспертное знание # о данных, то интересно посмотреть, что значит эта сумма # ничего не разделили, выходим if self.feature_idx == -1: return # вызываем потомков дерева self.left = RegressionTreeCython(self.max_depth - 1, averages=0) self.left.value = left_value self.right = RegressionTreeCython(self.max_depth - 1, averages=0) self.right.value = right_value # новые индексы для обучения потомков idxs_l = (X[:, self.feature_idx] > self.feature_threshold) idxs_r = (X[:, self.feature_idx] <= self.feature_threshold) # обучение потомков self.left.fit(X[idxs_l, :], y[idxs_l]) self.right.fit(X[idxs_r, :], y[idxs_r]) def __predict(self, np.ndarray[np.float64_t, ndim=1] x): if self.feature_idx == -1: return self.value if x[self.feature_idx] > self.feature_threshold: return self.left.__predict(x) else: return self.right.__predict(x) def predict(self, np.ndarray[np.float64_t, ndim=2] X): # чтобы делать предикты, нужно также добавить суммы в тестовую выборку if self.averages: stuff = list(range(0,X.shape[1],1)) index_tuples = list(itertools.combinations(stuff,2)) X = self.data_transform(X, index_tuples) y = np.zeros(X.shape[0]) for i in range(X.shape[0]): y[i] = self.__predict(X[i]) return y 4. Comparison of results
Well, let's compare the results. We will compare three algorithms with the same parameters - a tree from Sklearn, our usual tree and our tree with new features. Let's divide many times our training and test sets, and calculate the error.
from sklearn.model_selection import KFold def get_metrics(X,y,n_folds=2, model=None): kf = KFold(n_splits=n_folds, shuffle=True) kf.get_n_splits(X) er_list = [] for train_index, test_index in kf.split(X): X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] model.fit(X_train,y_train) predict = model.predict(X_test) er_list.append(mse(y_test, predict)) return er_list Now let's run all the algorithms.
import matplotlib.pyplot as plt data = datasets.fetch_california_housing() X = np.array(data.data) y = np.array(data.target) er_sklearn_tree = get_metrics(X,y,30,DecisionTreeRegressor(max_depth=4, min_samples_leaf=10)) er_fast_mse_tree = get_metrics(X,y,30,RegressionTreeFastMse(4, min_size=10)) er_averages_tree = get_metrics(X,y,30,RegressionTreeCython(4, min_size=10)) %matplotlib inline data = [er_sklearn_tree, er_fast_mse_tree, er_averages_tree] fig7, ax7 = plt.subplots() ax7.set_title('') ax7.boxplot(data, labels=['Sklearn Tree', 'Fast Mse Tree', 'Averages Tree']) plt.grid() plt.show() Results:

Our usual tree lost Sklearn (it’s understandable: Sklearn is well optimized, and in it, by default, the tree uses many more parameters that we don’t take into account), but when adding amounts, the result becomes more pleasant.
To summarize: we learned how to write decisive trees from scratch, learned how to improve their work and checked their performance on real datasets by comparing it with an algorithm from Sklearn. However, the improvement of the algorithms is not limited to the methods described here, so keep in mind that the proposed code can be made even better. In the next article we will write the boosting based on these algorithms.
Successes to all!
Source: https://habr.com/ru/post/438560/