How to work with cyber prospecting data: learn to collect and identify indicators of system compromise
Throughout the past year, the topic of cyber intelligence, or Threat Intelligence, has become increasingly popular in the cyber arms race between attackers and defenders. Obviously, preventive information on cyber threats is a very useful thing, but in itself it will not protect the infrastructure. It is necessary to build a process that will help you correctly manage both information about the method of a possible attack and the time available to prepare for it. And the key condition for the formation of such a process is the completeness of information about cyber threats.

Primary Threat Intelligence data can be obtained from a variety of sources. These may be free subscriptions , information from partners, a company technical investigation team, etc.
There are three main stages of working with information obtained as part of the Threat Intelligence process (although we, as a center for monitoring and responding to cyber attacks, have a fourth stage - notifying customers about the threat):
The first stage can be called the most creative. To correctly understand the description of a new threat, to identify relevant indicators, to determine their applicability to a particular organization, to weed out unnecessary information about attacks (for example, those focused on specific regions) are all often not an easy task. At the same time, there are sources that provide exclusively verified and relevant data that can be added to the database automatically.
For a systematic approach to information processing, we recommend dividing the indicators obtained in the framework of Threat Intelligence into two large groups - host and network. Detection of network indicators still does not indicate an unambiguous compromise of the system, but detection of host indicators, as a rule, reliably signals the success of the attack.
Network indicators include domains, URLs, email addresses, a set of IP addresses and ports. Host indicators are running processes, changes to registry keys and files, hash sums.
Indicators received in the framework of a single alert about the threat, it makes sense to combine into one group. In the case of detection of indicators, this greatly facilitates the determination of the type of attack, and also makes it easy to check a potentially compromised system for all possible indicators from a specific threat report.
However, we often have to deal with indicators, the detection of which does not allow us to unequivocally talk about the compromise of the system. These can be IP addresses belonging to large networks of corporations and hosting companies, mail domains of advertising mailing services, names and hash sums of legitimate executable files. The simplest examples are the IP addresses of Microsoft, Amazon, CloudFlare, which are often listed, or legitimate processes that appear on the system after installing software packages, for example, pageant.exe, an agent for storing keys. In order to avoid a large number of false positives, it is better to screen such indicators, but, let's say, not to throw them away - most of them are not completely useless. If there is a suspicion that the system is compromised, a full check is made on all indicators, and even an indirect indicator can be found to confirm these suspicions.
Since not all indicators are equally useful, we use the so-called indicator weight in Solar JSOC. Conventionally, the detection of the launch of a file, the hash sum of which coincides with the hash sum of the executable file of the malware, has a threshold weight. Detection of such an indicator instantly leads to an information security event. A single address to the IP address of a potentially dangerous host on a non-specific port will not lead to an information security event, but will fall into a special profile that accumulates statistics, and the detection of further requests will also lead to an investigation.
At the same time, there are mechanisms that seemed reasonable to us at the time of creation, but ultimately found to be ineffective. For example, initially it was assumed that certain types of indicators will have a limited lifespan, after which they will be deactivated. However, as practice has shown, when connecting a new infrastructure, hosts are sometimes found that have been infected for years with various types of malware. For example, once when a customer connected to the computer, the head of the information security service detected the Corkow virus (at the time the indicators were more than five years old), and a further investigation revealed on the host an exploited backdoor and keylogger.
We work with a variety of installations of various SIEM systems, however, the general structure of the records that fall into the database of indicators is standardized and looks like this:
For example, by sorting the indicators by TIReportID, you can find all the indicators that appeared in the description of a specific threat, and by clicking on URLlink, you can get a detailed description of it.
When building the Threat Intelligence process, it is very important to analyze the information systems connected to the SIEM from the point of view of their use in identifying indicators of compromise.
The fact is that the description of the attack usually includes indicators of different types of compromise - for example, the hash sum of the malware, the IP address of the CC server, on which it knocks, and so on. But if the IP addresses accessed by the host are tracked by many means of protection, then information about hash sums is much more difficult to obtain. Therefore, we consider all systems that can serve as the source of any logs from the point of view of which indicators they are able to track:
Schematically, the process of detecting indicators of compromise can be represented as follows:

I have already discussed the first two points above, now a little more about the IOC check. For example, let's take events that contain information about IP addresses. The correlation rule for each event performs four possible checks on the basis of indicators:

The search is carried out by the relevant indicators of the Socket type, and the aggregate construction from the IP address and the corresponding port is checked for compliance with the indicator. Since the threat information is far from always specifying a specific port, by the IP construct: any checks whether the address in the database has an unspecified port.
A similar construction is implemented in a rule that detects indicators of compromise in registry change events. In the incoming information, there is often no data on a specific key or value, therefore, when the indicator is entered into the database, unknown or non-accurate values are replaced with 'any'. The final search options are as follows:

Having found the indicator of compromise in the logs, the correlation rule creates a correlation event marked by the category that the incident rule handles (we described this in detail in the article “ RULING Kitchen ”).
In addition to the category, the correlation event will be supplemented with information on which alert or report featured this indicator, its weight, threat data, and a link to the source. Further processing of event detection of indicators of all types produces an incident rule. His work can be schematically represented as follows:

But, of course, one should keep in mind the exceptions: in almost any infrastructure there are devices whose actions are legitimate, despite the fact that they formally contain signs of a system being compromised. These devices often include sandboxes, various scanners, etc.
The need to correlate the events of detecting indicators of different types is also due to the fact that in the information on threats most often there are various types of indicators.
Accordingly, the grouping of indicator detection events may allow one to see the entire attack chain from the moment of penetration to operation.
The event of information security, we propose to consider the implementation of one of the following scenarios:
With the first two options, everything is clear, and the third is necessary in the case when we have no other data than the network activity of the system.
After receiving information about the threat, identifying indicators and organizing their detection, there is a need for retrospective verification, which allows you to detect a compromise that has already occurred.
If you go a little deeper into how it is arranged in SOC, I can say that this process requires a truly enormous amount of time and resources. The search for indicators of compromise in the logs for six months forces us to keep an impressive amount of them available for online checks. At the same time, the result of the verification should be not only information about the presence of indicators, but also general data on the development of the attack. When connecting new customer information systems, data from them should also be checked for the presence of indicators. To do this, it is necessary to constantly refine the so-called "content" SOC - correlation rules and indicators of compromise.
For the ArcSight SIEM system, performing such a search even over the past couple of weeks can be very time consuming. Therefore, it was decided to use the trends.
After several tests on loaded systems, the following algorithm for using trends was developed:

Profiling rules that fill the corresponding active sheets with useful data allow you to distribute the total load on the SIEM. After receiving the indicators, requests are created for the corresponding sheets and trends, on the basis of which reports will be made, which in turn will be distributed across all installations. In fact, it remains only to run the reports and process the results.
It is worth noting that the processing process can be continuously improved and automated. For example, we have implemented a platform for storing and processing indicators of MISP compromise, which currently meets our requirements for flexibility and functionality. Its counterparts are widely represented on the open source market - YETI, foreign - Anomali ThreatStream, ThreatConnect, ThreatQuotinet, EclecticIQ, Russian - TI.Platform, R-Vision Threat Intelligence Platform. Now we are conducting the final tests of automated event uploads directly from the SIEM database. This will significantly speed up the reporting of the presence of compromise indicators.
However, the final link in the processing of both the indicators themselves and the reports are engineers and analysts, and the listed tools only help in making decisions. We have a response group responsible for adding indicators, and a monitoring group is responsible for the correctness of reports.
Without people, the system will not work adequately enough, it is impossible to foresee all the details and exceptions. For example, we mark the calls to the IP addresses of the TOR node, but in the reports for the customer we share the activity of the compromised host and the host on which we just installed the TOR Browser. It is possible to automate it, but it is rather difficult to think over all such moments beforehand when setting up rules. So it turns out that the response team eliminates indicators that will create a large number of false positives. And vice versa - it can add a specific indicator, highly relevant for some customers (for example, the financial sector).
The monitoring group can remove the sandbox activity from the final report, check the administrators for successful blocking of the malicious resource, but add activity about the unsuccessful external scan, showing the customer that the infrastructure is being checked by intruders. The machine will not accept such decisions.

Why do we recommend this method of working with Threat Intelligence? First of all, it allows you to escape from the scheme, when for each new attack you need to create a separate correlation rule. This takes an inadmissibly long amount of time and makes it possible to reveal only the ongoing attack.
The described method makes the most of TI's capabilities — you just need to add indicators, which is a maximum of 20 minutes from the moment they appeared, and then conduct a full retrospective check of the logs. So you will shorten the response time, and get more complete test results.
If you have any questions, welcome to the comments.
Primary Threat Intelligence data can be obtained from a variety of sources. These may be free subscriptions , information from partners, a company technical investigation team, etc.
There are three main stages of working with information obtained as part of the Threat Intelligence process (although we, as a center for monitoring and responding to cyber attacks, have a fourth stage - notifying customers about the threat):
- Getting information, primary processing.
- Detection of indicators of compromise (Indicator of Compromise, IOC).
- Retrospective check.
Receiving information, primary processing
The first stage can be called the most creative. To correctly understand the description of a new threat, to identify relevant indicators, to determine their applicability to a particular organization, to weed out unnecessary information about attacks (for example, those focused on specific regions) are all often not an easy task. At the same time, there are sources that provide exclusively verified and relevant data that can be added to the database automatically.
For a systematic approach to information processing, we recommend dividing the indicators obtained in the framework of Threat Intelligence into two large groups - host and network. Detection of network indicators still does not indicate an unambiguous compromise of the system, but detection of host indicators, as a rule, reliably signals the success of the attack.
Network indicators include domains, URLs, email addresses, a set of IP addresses and ports. Host indicators are running processes, changes to registry keys and files, hash sums.
Indicators received in the framework of a single alert about the threat, it makes sense to combine into one group. In the case of detection of indicators, this greatly facilitates the determination of the type of attack, and also makes it easy to check a potentially compromised system for all possible indicators from a specific threat report.
However, we often have to deal with indicators, the detection of which does not allow us to unequivocally talk about the compromise of the system. These can be IP addresses belonging to large networks of corporations and hosting companies, mail domains of advertising mailing services, names and hash sums of legitimate executable files. The simplest examples are the IP addresses of Microsoft, Amazon, CloudFlare, which are often listed, or legitimate processes that appear on the system after installing software packages, for example, pageant.exe, an agent for storing keys. In order to avoid a large number of false positives, it is better to screen such indicators, but, let's say, not to throw them away - most of them are not completely useless. If there is a suspicion that the system is compromised, a full check is made on all indicators, and even an indirect indicator can be found to confirm these suspicions.
Since not all indicators are equally useful, we use the so-called indicator weight in Solar JSOC. Conventionally, the detection of the launch of a file, the hash sum of which coincides with the hash sum of the executable file of the malware, has a threshold weight. Detection of such an indicator instantly leads to an information security event. A single address to the IP address of a potentially dangerous host on a non-specific port will not lead to an information security event, but will fall into a special profile that accumulates statistics, and the detection of further requests will also lead to an investigation.
At the same time, there are mechanisms that seemed reasonable to us at the time of creation, but ultimately found to be ineffective. For example, initially it was assumed that certain types of indicators will have a limited lifespan, after which they will be deactivated. However, as practice has shown, when connecting a new infrastructure, hosts are sometimes found that have been infected for years with various types of malware. For example, once when a customer connected to the computer, the head of the information security service detected the Corkow virus (at the time the indicators were more than five years old), and a further investigation revealed on the host an exploited backdoor and keylogger.
Detection of compromise indicators
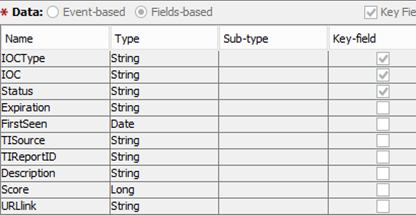
We work with a variety of installations of various SIEM systems, however, the general structure of the records that fall into the database of indicators is standardized and looks like this:
For example, by sorting the indicators by TIReportID, you can find all the indicators that appeared in the description of a specific threat, and by clicking on URLlink, you can get a detailed description of it.
When building the Threat Intelligence process, it is very important to analyze the information systems connected to the SIEM from the point of view of their use in identifying indicators of compromise.
The fact is that the description of the attack usually includes indicators of different types of compromise - for example, the hash sum of the malware, the IP address of the CC server, on which it knocks, and so on. But if the IP addresses accessed by the host are tracked by many means of protection, then information about hash sums is much more difficult to obtain. Therefore, we consider all systems that can serve as the source of any logs from the point of view of which indicators they are able to track:
| Indicator Type | Sourcetype |
| Domain | Proxy servers, NGFW, DNS servers |
| URL | |
| Socket | Proxy servers, NGFW, FW |
| Mail | Mail servers, Antispam, DLP |
| Process | Logs from the host, DB AVPO, Sysmon |
| Registry | Logs from the host |
| Hash sum | Logs from the host, the database AVPO, Sysmon, Sandbox CMDB |
Schematically, the process of detecting indicators of compromise can be represented as follows:
I have already discussed the first two points above, now a little more about the IOC check. For example, let's take events that contain information about IP addresses. The correlation rule for each event performs four possible checks on the basis of indicators:
The search is carried out by the relevant indicators of the Socket type, and the aggregate construction from the IP address and the corresponding port is checked for compliance with the indicator. Since the threat information is far from always specifying a specific port, by the IP construct: any checks whether the address in the database has an unspecified port.
A similar construction is implemented in a rule that detects indicators of compromise in registry change events. In the incoming information, there is often no data on a specific key or value, therefore, when the indicator is entered into the database, unknown or non-accurate values are replaced with 'any'. The final search options are as follows:
Having found the indicator of compromise in the logs, the correlation rule creates a correlation event marked by the category that the incident rule handles (we described this in detail in the article “ RULING Kitchen ”).
In addition to the category, the correlation event will be supplemented with information on which alert or report featured this indicator, its weight, threat data, and a link to the source. Further processing of event detection of indicators of all types produces an incident rule. His work can be schematically represented as follows:
But, of course, one should keep in mind the exceptions: in almost any infrastructure there are devices whose actions are legitimate, despite the fact that they formally contain signs of a system being compromised. These devices often include sandboxes, various scanners, etc.
The need to correlate the events of detecting indicators of different types is also due to the fact that in the information on threats most often there are various types of indicators.
Accordingly, the grouping of indicator detection events may allow one to see the entire attack chain from the moment of penetration to operation.
The event of information security, we propose to consider the implementation of one of the following scenarios:
- Detection of a highly relevant indicator of compromise.
- Detection of two different indicators from one report.
- Reaching the threshold.
With the first two options, everything is clear, and the third is necessary in the case when we have no other data than the network activity of the system.
Retrospective verification of indicators of compromise
After receiving information about the threat, identifying indicators and organizing their detection, there is a need for retrospective verification, which allows you to detect a compromise that has already occurred.
If you go a little deeper into how it is arranged in SOC, I can say that this process requires a truly enormous amount of time and resources. The search for indicators of compromise in the logs for six months forces us to keep an impressive amount of them available for online checks. At the same time, the result of the verification should be not only information about the presence of indicators, but also general data on the development of the attack. When connecting new customer information systems, data from them should also be checked for the presence of indicators. To do this, it is necessary to constantly refine the so-called "content" SOC - correlation rules and indicators of compromise.
For the ArcSight SIEM system, performing such a search even over the past couple of weeks can be very time consuming. Therefore, it was decided to use the trends.
"It will be the aggregate that has been evaluated and will be evaluated for prevailing tendencies or currents. "Trend schedule and time duration."
ESM_101_Guide
After several tests on loaded systems, the following algorithm for using trends was developed:
Profiling rules that fill the corresponding active sheets with useful data allow you to distribute the total load on the SIEM. After receiving the indicators, requests are created for the corresponding sheets and trends, on the basis of which reports will be made, which in turn will be distributed across all installations. In fact, it remains only to run the reports and process the results.
It is worth noting that the processing process can be continuously improved and automated. For example, we have implemented a platform for storing and processing indicators of MISP compromise, which currently meets our requirements for flexibility and functionality. Its counterparts are widely represented on the open source market - YETI, foreign - Anomali ThreatStream, ThreatConnect, ThreatQuotinet, EclecticIQ, Russian - TI.Platform, R-Vision Threat Intelligence Platform. Now we are conducting the final tests of automated event uploads directly from the SIEM database. This will significantly speed up the reporting of the presence of compromise indicators.
The main element of cyber intelligence
However, the final link in the processing of both the indicators themselves and the reports are engineers and analysts, and the listed tools only help in making decisions. We have a response group responsible for adding indicators, and a monitoring group is responsible for the correctness of reports.
Without people, the system will not work adequately enough, it is impossible to foresee all the details and exceptions. For example, we mark the calls to the IP addresses of the TOR node, but in the reports for the customer we share the activity of the compromised host and the host on which we just installed the TOR Browser. It is possible to automate it, but it is rather difficult to think over all such moments beforehand when setting up rules. So it turns out that the response team eliminates indicators that will create a large number of false positives. And vice versa - it can add a specific indicator, highly relevant for some customers (for example, the financial sector).
The monitoring group can remove the sandbox activity from the final report, check the administrators for successful blocking of the malicious resource, but add activity about the unsuccessful external scan, showing the customer that the infrastructure is being checked by intruders. The machine will not accept such decisions.
Instead of output
Why do we recommend this method of working with Threat Intelligence? First of all, it allows you to escape from the scheme, when for each new attack you need to create a separate correlation rule. This takes an inadmissibly long amount of time and makes it possible to reveal only the ongoing attack.
The described method makes the most of TI's capabilities — you just need to add indicators, which is a maximum of 20 minutes from the moment they appeared, and then conduct a full retrospective check of the logs. So you will shorten the response time, and get more complete test results.
If you have any questions, welcome to the comments.
Source: https://habr.com/ru/post/438798/