Why do you need low-level optimization on Elbrus or how to speed up the recognition system by one and a half times

When we met in 2019 and had a little rest from developing new features for the Smart IDReader, we remembered that we had not written anything about domestic processors for a long time. Therefore, we decided to urgently fix and show another recognition system on Elbrus.
As a recognition system, the system of recognition of objects of painting “under uncontrollable conditions by the method with one-example training” was considered [1]. This system builds a description of the image based on the singular points and their descriptors, which performs a search in the indexed database of paintings. We analyzed the performance of this system and identified the most time-consuming low-level part of the algorithm, which was then optimized using the tools of the Elbrus platform.
What is the recognition system in general?
Currently, most museums and galleries use a variety of tools to familiarize themselves with the exhibition. Along with classic audio guides, mobile applications using image processing and analysis methods are widely used. Some of these applications recognize the graphic codes of the exhibits (bar or QR) [2], for others [3-4] the input data are photo or video frames with an exhibit taken close-ups (Smartify, Artbit). Of course, the “mobile guides” of the latter category are more convenient for the user [5] than solutions with manual input of the exhibit number or recognition of QR: the number and code are rather small, and their search and input require additional actions not related to the exposure review. This is the system we will consider.
The task of recognizing the works of painting on the images was formulated as follows. Image request Q should be assigned to one of the classes C = \ {C_i \} _ {i \ in [0, N]}C = \ {C_i \} _ {i \ in [0, N]} where C i - image class i th exhibit, with i i n [ 1 , N ] , C 0 - class of other images corresponding to the value of "unknown picture". For each C i set the reference image T i .
In addition, we were guided by the following assumptions:
- Image request Q obtained by the camera of the mobile device by an unprepared user during the tour, therefore:
a) it may contain visual defects - glare, defocused areas, noise;
b) the angle, framing, lighting and color balance are unknown (Fig. 1a);
c) there may be foreign objects in the picture, such as decorations, picture frames, visitors (Fig. 1b). - Image reference T It is a high resolution image with a frontal projection of the picture or its digital reproduction. The standard does not contain foreign objects and visual defects. Reference standards can be, for example, high-quality scanned pages of art albums (Fig. 2).
- The picture (both on request and on the standard) can relate to any style - realism,
impressionism, abstractionism, fractal graphics, etc. - Number of classes N fits the size of the collection and for one gallery can reach
hundreds of thousands of exhibits [6].

Figure 1 - Examples of image requests a) the picture was photographed from a distance in low light, b) the visitor in the frame.

Figure 2 - Examples of image-standards for paintings a) Claude Monet "De Voorzaan en de Westerhem", b) Salvador Dali "La persistència de la memòria"
The main idea of our solution to this problem is based on constructing a special description of a picture from an input image, which is then used to search for this picture in the base of descriptions of reference images of high-resolution pictures that are not subject to geometric distortion and other photodefects. Such descriptions are the coordinates of the singular points found using the YACIPE algorithm [7], and their RFD descriptors.
For each reference T i we will construct the description, and then we will index it - for each point in the description we will put a record of the form l a n g l e i , f i r a n g l e in a randomized hierarchical clustering search tree [8], which allows you to perform an approximate search for the nearest neighbors with a significant gain in speed compared to a linear search. Hamming distance is used as a metric, since we use a binary descriptor.
The recognition process is as follows:
On request image Q painting area Q L pre-localized using the assumption about the squareness of the frame. A zone search is performed using the fast quadrangle search algorithm [9] with the aspect ratio removed. This prevents the following problems:
- insufficient description of the area of the picture due to extraneous objects in the frame, which may have special points with the best estimates;
- computational cost of matching descriptors of regions located outside the picture;
- a significant discrepancy between the scale and the angle of inclination between the standard in the base and the picture of the picture, which leads to an incorrect result of the descriptor matching.The image in the found zone is projectively normalized:
Q ∗ = H ( Q L ) ,
Where H - projective transformation.
Building a compact description w ∗ :
a) the image is reduced to the standard size while preserving the proportions in order to make the algorithm more resistant to scaling;
b) high-frequency noise is suppressed by a Gaussian filter;
c) special points are calculated on the resulting image, their number is artificially limited to M best rated by internal YACIPE;
d) color RFD-like descriptors of the neighborhoods of the found points found are computed, since in our task it was important to store information about the color characteristics of the input images. For example, the paintings in Fig. 3 it would be extremely difficult to distinguish without it;
e) thus the description of the image I can be represented as: w ^ * = \ {\ langle p_i, f_i) \ rangle \} _ {i \ in [1, M]} where pi= langlexi,yi rangle - coordinates of the i-th singular point, and fi - A handle to the neighborhood of the i-th singular point.For each entry langlep,f rangle inw∗ in the index, an approximate search is performed for the nearest neighbors of the descriptor f . The voting procedure - descriptor is applied to the found descriptors. fi adds voice to standard Ti . Then K candidate standards with the highest number of votes are selected.
For each of K selected variants using the RANSAC algorithm searches for a projective transformation H , translating, within a given geometric error delta query points Q∗ to the points of reference T . A couple of points langlep,p′ rangle with close descriptors is considered a correct mapping if:
l e f t | H ( p ) - p ' r i g h t | < d e l t a , p i n w ∗ , p ′ i n w t
The standard is chosen as the final result. T b for which the number of correct comparisons turned out to be maximum. If it is less than a certain threshold R , the result will be the answer “an unknown picture” in order to avoid false positives (for example, in pictures for which there is no reference description in the search database).


Figure 3 - Claude Monet. Rouen Cathedral, West Facade, Sunlight (left) and Rouen Cathedral, Portal and Tower Saint-Romain in the Sun (right).
One of the main parts of the system is the search for close descriptors using the Hamming distance as a metric. Since it is calculated many times, this stage becomes quite computationally time consuming and takes 65% of the system operation time. That is why we optimized it.
A very small description of the architecture of Elbrus
The processor architecture Elbrus uses the principle of a wide command word (Very Long Instruction Word, VLIW). This means that the processor executes commands in groups, and there are no dependencies within each group, and these commands are executed in parallel. Each such group is called a broad command word. The formation of broad command words is performed by the optimizing compiler, due to which a more detailed analysis of the source code is possible, leading to more efficient parallelization [10].
A special feature of the architecture of Elbrus are the methods of working with memory. In addition to having a cache to optimize memory access time, Elbrus processors support a hardware-software method of preliminary data paging. This method allows predicting memory hits and pumping data to the data pre-buffer. The hardware of the processor includes a special device for accessing arrays (Array Access Unit, AAU), but the need to swap is determined by the compiler, which generates special instructions for the AAU. The use of a swap device is more efficient than putting an array of elements into a cache, since array elements are most often processed sequentially and rarely used more than once [11]. However, it should be noted that the use of the preliminary swap buffer on Elbrus is possible only when working with aligned data. Due to this, the read / write of the aligned data takes place noticeably faster than the corresponding operations for the non-aligned data.
In addition, Elbrus processors support several types of parallelism in addition to command-level parallelism: SIMD-parallelism, control flow parallelism, task parallelism in a multi-machine complex. Of particular interest to us is SIMD-parallelism.
Features of using SIMD-expansion processor Elbrus
Using SIMD-extensions can be carried out in two modes: automatic and direct. In the first case, the parallelization of operations is fully performed by the compiler without the participation of the developer. This mode is limited, since the optimized code must completely repeat the behavior of the source code, including the behavior of overflow, rounding, etc. In this case, the behavior of SIMD-expansion commands may differ in these aspects from the processor commands. In addition, the algorithms used in compilers are imperfect and not always able to perform efficient parallelization. However, developers can also access the commands of SIMD extensions directly using intrinsics. Intrinsics are functions whose calls are replaced by the compiler with a highly efficient code for this platform, in particular, with SIMD extension commands. The Elbrus-4C and Elbrus-8C processors support a set of intrinsics, for which the register size is 64 bits. It includes operations for data transformation, initialization of vector elements, arithmetic operations, bitwise logical operations, permutation of vector elements, etc.
When using intrinsics on the Elbrus platform, special attention should be paid to access to memory, since in practical tasks, such as image processing tasks, unaligned reading of data into a 64-bit register is often required. Such a reading is in itself inefficient, as it requires a pair of read commands and a subsequent command to form a data block, but, more importantly, an array swap buffer cannot be used, which increases the speed of data access. However, it is worth noting that the problem of inefficient access to unaligned data is relevant for the Elbrus-4C and Elbrus-8C processors, while for the newer Elbrus-8CB with the 5th version of the command system it is partially solved. It is expected that Elbrus processors with the 6th version of the instruction system will be fully resolved.
However, on Elbrus-4C and Elbrus-8C processors, low-level data processing is efficiently performed with regard to alignment. For example, for numeric arrays, it can consist of several stages: processing the initial part (up to the alignment boundary on 64-bits of one of the arrays), processing the main part using aligned memory access, and processing the remaining elements of the array. Since the analysis of pointers at compile time is a non-trivial task, you can use the –faligned compiler –faligned , with which all memory access operations are performed in an aligned manner.
The following feature of using intrinsics on the Elbrus platform is directly related to its VLIW architecture. Due to the presence of several arithmetic logic units (ALUs) that work in parallel and are loaded when forming broad command words, several commands can be executed simultaneously. In total, Elbrus-4C and Elbrus-8C processors have six ALUs that can be used within one wide team, but each ALU maintains its own set of intrinsics. Simple operations, for example, addition or multiplication of elements in 64-bit registers, as a rule, support two ALUs. This means that the Elbrus processor can execute two such instructions per cycle. To do this, in the executable code you should use loop deployment. The Elbrus optimizing compiler supports the #pragma unroll(n) pragma, which allows you to deploy n loop iterations.
An example of the implementation of the addition function with these features can be found in our previous article .
Experiments
Hurray, the text is over and finally we will launch something on Elbrus!
We first consider separately the Hamming distance. Without further ado, we compared two bit vectors of random data. Binary values were packed into arrays of 8-bit integers, and for simplicity, we thought that the lengths of the original vectors are multiple of 8. As usual, the code was written in C ++, compiled by lcc 1.21.24 - an optimizing e-compiler.
We wrote several realizations of Hamming distance, which consistently took into account the characteristics of Elbrus processors. They looked like this:
- A bitwise XOR between 8-bit integers and a table of pre-calculated values are used. This is a basic implementation without intrusions and other tricks.
- XOR is used between 32-bit integers and intrinsic to calculate the number of ones in a 32-bit integer - popcnt32. Alignment of data on the 32-bit boundary was not performed.
- XOR is used between 64-bit integers and intrinsic to calculate the number of ones in a 64-bit integer - popcnt64. Alignment of data on the border in 64-bit was not performed.
- XOR is used between 64-bit integers and intrinsic to calculate the number of ones in a 64-bit integer - popcnt64. Memory access is carried out in an aligned manner. Since the initial addresses of arrays can have different alignments, reading one of the arrays reads two adjacent 64-bit blocks and forms the necessary 64-bit block from them.
- XOR is used between 64-bit integers and intrinsic to calculate the number of ones in a 64-bit integer - popcnt64. Memory access is carried out in an aligned manner. Since the initial addresses of arrays can have different alignments, reading one of the arrays reads two adjacent 64-bit blocks and forms the necessary 64-bit block from them. Additionally used compiler flag
-faligned. - XOR is used between 64-bit integers and intrinsic to calculate the number of ones in a 64-bit integer - popcnt64. Memory access is carried out in an aligned manner. Since the initial addresses of arrays can have different alignments, reading one of the arrays reads two adjacent 64-bit blocks and forms the necessary 64-bit block from them. Additionally, the compiler flag
-falignedand the pragmas of the#pragma unroll(2)compiler (to use both available ALUs for popcnt64) and#pragma loop count(1000)(to enable additional cyclic optimizations) are used.
The results of time measurements are shown in table 1.
Table 1. Time to calculate the Hamming distance between two arrays of packed binary numbers of length 10 ^ 5 on a machine with an Elbrus-4C processor. Time averaged over 10 ^ 5 runs.
| No | Experiment | Time, ms |
|---|---|---|
| one | table of pre-calculated values | 141.18 |
| 2 | popcnt32, without alignment | 125.54 |
| 3 | popcnt64, without alignment | 58.00 |
| four | popcnt64 alignment | 17.36 |
| five | popcnt64, alignment, -faligned | 17.15 |
| 6 | popcnt64, alignment, -faligned, pragma unroll | 12.23 |
It can be seen that all the considered optimizations resulted in a decrease in the operation time by 11.5 times. It is worth noting that the use of intrinsics with unallocated access to memory showed acceleration only 1.13 times (for popcnt32) and 2.4 times (for popcnt64), while accounting for data alignment led to the use of the APB array swap buffer , with which it was possible to achieve acceleration by 3.4 times (58 ms versus 17.15 ms). Despite the fact that in the above example, the use of the -faligned flag did not show significant performance gains, in more complex algorithms it is possible that the compiler will not be able to analyze the source code deep enough to generate commands for APB. Accounting for the current number of specialized ALUs allowed speeding up the calculations by another 1.4 times.
Not so bad! Since we compared as many as 6 options for implementation, we give the pseudocode of the final, the fastest:
Вход: массивы 8-битных целых чисел A и B, массив T, где T[i] содержит число единиц в числе i Выход: целое число res, равное расстоянию Хэмминга между A и B offset ← число байтов до границы выравнивания массива A на 64-бита effective_len ← максимальная длина массива, которую можно обработать блоками по 64-бита for i from 1 to offset: res ← res + T[xor(A[i] , B[i])] v_a ← 64-битный блок данных, начиная с A[offset+1] v_b1 ← 64-битный блок данных, включающий элемент B[offset] v_b2 ← 64-битный блок данных, следующий за v_b1 //включение развертывания цикла и цикловых оптимизаций для всех 64-битных блоков данных for i from offset to effective_len: v_b ← align(v_b1, v_b2) // создание 64-битного блока данных, соответствующего v_a res ← res + popcnt64(xor(v_a, v_b)) v_a ← следующий 64-битный блок данных v_b1 ← v_b2 v_b2 ← следующий 64-битный блок данных // Обработать оставшиеся элементы массивов It would be great once and for all to speed up the calculation of the Hamming distance by 11.5 times, but in life everything is a bit more complicated: such an implementation will have an advantage only if the arrays are long enough. In Fig. 4 shows a comparison of the counting time using the table of pre-calculated values and our final implementation. It can be seen that with our version it starts to win only starting from lengths exceeding 400 bytes, and this must also be taken into account when optimizing on Elbrus.
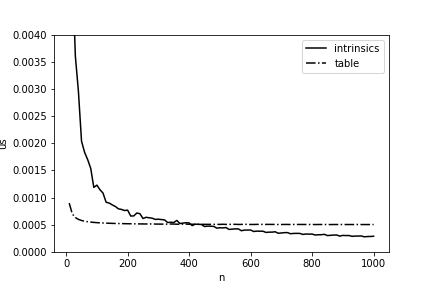
Figure 4 - The average time (per 1 byte) for calculating the Hamming distance between two arrays depending on their length on Elbrus-4C.
That's all, now we are ready to measure the time of the entire system. We measured the average request processing time (excluding image loading) for 933 requests. In compiling a compact image description, a color RFD-like binary descriptor of 5328 bits was used. It consisted of 3 concatenated 1776-bit gray RFD descriptors calculated for each channel of the input image section. On the one hand, such long descriptors are not pleasing to the high speed of calculation and comparison, on the other hand, they allow to ensure a fairly high quality of work. However, there is good news - we can use the fast implementation of Hamming distance to compare them! The lengths of the arrays being compared are 666 bytes, which is more than a 400 byte threshold for Elbrus-4C.
The results of the measurements are given in Table 2. It can be seen that only one quick realization of the Hamming distance gives the query processing acceleration 1.5 times. It is also worth noting that this optimization does not change the results of the calculations, and therefore the quality of recognition.
Table 2. The average processing time of the request to the system of recognition of objects of painting in uncontrolled conditions.
| Experiment | Request time, with | Hamming distance calculation took | Acceleration times |
|---|---|---|---|
| Base implementation | 2.81 | 63% | - |
| Quick implementation | 1.87 | 40% | 1.5 |
Conclusion
In this article, we talked a little about the structure of the object recognition system of painting in uncontrolled conditions and once again showed how low-level manipulations can significantly improve its speed on the Elbrus platform. Thus, the proposed implementation of the Hamming distance, works an order of magnitude (!) Faster than the implementation of a table of pre-calculated values with a sufficiently large length of input vectors, and the entire system has accelerated one and a half times! To achieve this result, SIMD-extensions were used, as well as the peculiarities of the architecture and memory access to the Elbrus-4C and Elbrus-8C processors were taken into account. These results show that Elbrus processors contain significant resources for efficient operation, which are not fully utilized in the absence of specially implemented optimization. However, it is expected that on newer Elbrus processors memory access methods will be improved, which will allow to perform some of these optimizations in automatic mode and will significantly simplify the lives of developers.
Literature
[1] N.S. Skoryukina, A.N. Milovzorov, D.V. Polevoy, V.V. Arlazarov. The method of recognition of painting objects in uncontrolled conditions with learning by one example // Proceedings of the ISA RAS. - Special edition, 2018 - with. 5-15.
[2] Pérez-Sanagustín M. et al. Using QR codes to increase user engagement in muse-like spaces // Computers in Human Behavior. - 2016. - T. 60. - p. 73-85. doi: 10.1016 / j.chb.2016.02.012
[3] Antoshchuk S. G., Godovichenko N. A. Analysis of the point features of the image in the Mobile Virtual Guide system // Pratsi. - 2013. - №. 1 (40). - pp. 67-72.
[4] Andreatta, C., Leonardi F. Appearance and the VISAPP. - 2006.
[5] Leonard Wein. 2014. In the SIGCHI Conference on Computing Systems (CHI '14). ACM, New York, NY, USA, 635-638.
doi: 10.1145 / 2556288.2557270
[6] The Tretyakov Gallery, https://www.tretyakovgallery.ru/collection/
[7] Lukoyanov A. S., Nikolaev D. P., Konovalenko I. A. Modification of the YAPE algorithm for images with a large spread of local contrast // Information technologies and nanotechnologies. - 2018. - p. 1193-1204.
[8] Muja M., Lowe DG Fast matching of binary features // Computer and Robot Vision (CRV), 2012 Ninth Conference on. - IEEE, 2012. - p. 404-410.
doi: 10.1109 / CRV.2012.60
[9] Skoryukina, N., Nikolaev, DP, Sheshkus, A., Polevoy, D. (2015, February). Real time rectangular document detection on mobile devices. In Seventh International Conference on Machine Vision (ICMV 2014) (Vol. 9445, p. 94452A). International Society for Optics and Photonics.
doi: 10.1117 / 12.2181377
[10] Kim A.K., Bychkov I.N. Russian Technologies “Elbrus” for personal computers, servers and supercomputers // Modern information technologies and IT education, M .: Foundation for Assistance in the Development of Internet Media, IT Education, Human Potential “League of Internet Media”, 2014, No 10, p. 39-50.
[11] Kim A.K., Perekatov V.I., Ermakov S.G. Microprocessors and computing systems
family "Elbrus". - SPb .: Peter, 2013. - 272 C.
Source: https://habr.com/ru/post/438948/