Kubernetes Handbook Part 2: Creating and Working With a Cluster
Last time we considered two approaches to working with microservices. In particular, one of them involves the use of Docker containers, in which you can run microservice code and auxiliary programs. Today, using images of containers that we already have, we will work with Kubernetes.

I promise, and at the same time I do not exaggerate at all that when you finish reading this article, ask yourself: “Why don't you call Kubernetes Supernetes?”.

Supernetes
If you read the previous part of this material, then you know that there we have analyzed a lot of things related to preparing applications for containerization and working with Docker containers. It may seem to you that the most difficult thing is waiting for you now, but, in fact, what we are going to talk about here is much simpler than what we have already figured out. The only reason for which the study of Kubernetes may seem to someone a very difficult task is the amount of additional information that you need to have in order to understand Kubernetes and to use this system effectively. We have already discussed all the “additional information” necessary for the successful development of Kubernetes.
In the first part of this material, after running microservices in containers, you were asked to think about the issue of scaling containerized applications.
I propose to reflect on it together, in the format of questions and answers:
Q: How are containerized applications scaled?
Answer: Launch additional containers.
Question: How do they distribute the load between them? What if some server is already used to the maximum, and the container needs to be deployed on another server? How to find the most efficient way to use hardware?
Answer: So ... I will look on the Internet ...
Question: How to update the program without disturbing the system? And, if the update contains an error, how to return to the working version of the application?
In fact, it is Kubernetes technology that provides decent answers to these and many other questions. I will try to shrink the definition of Kubernetes to one sentence: “Kubernetes is a container management system that abstracts the basic infrastructure (the environment in which containers run).”
I believe that now you are not particularly clear about the concept of "container management", although we have already mentioned this. Below we consider this technology in practice. However, the concept of “abstraction of basic infrastructure” is encountered for the first time. Therefore, now we consider it.
Kubernetes allows applications to abstract from the infrastructure, giving us a simple API to which you can send requests. Kubernetes tries to fulfill these requests using all its capabilities. For example, in ordinary language, a similar query can be described as: “Kubernetes, expand 4 containers of image X”. After receiving the command, Kubernetes will find not too loaded nodes (they are also called “nodes” - from the English “node”), on which you can deploy new containers.

API Server Request
What does this mean for the developer? This means that it does not need to worry about the number of nodes, about exactly where the containers are started, how they interact. It does not have to deal with hardware optimization or worry about nodes whose operation can be broken (and something like that, according to Murphy's law, is bound to happen), since, if necessary, new nodes can be added to the Kubernetes cluster. If there is something wrong with some existing nodes, Kubernetes will deploy containers on those nodes that are still in a healthy state.
Much of what is shown in the previous figure, you are already familiar. But there is something new there:
Please note that in a couple of previous sentences we use the term "container", but here it would be better to use the term "pod". These entities in Russian-language publications are often called "podami", and sometimes - "pods", in the documentation , clarifying the concept of "pod", refer to "a flock of whales" (pod of whales) or "pea pod" , but no one calls them "flocks" or "pods". We, speaking of them, will use the word "under." Now you can quite consider them as containers, we will talk about feeds in more detail below.
We will dwell on this, as we can talk about all this further, and, moreover, there are a lot of good materials concerning the theory of Kubernetes. For example, this is official documentation, although reading it is not easy, or books like this .
Another strength of Kubernetes is that this technology contributes to the standardization of work with cloud service providers (Cloud Service Provider, CSP). This is a bold statement. Consider the following example. A specialist who knows Azure well or the Google Cloud Platform has to work on a project designed for a completely new cloud environment with which he is unfamiliar. In such a situation, much can go wrong. For example, the deadlines for project delivery may be disrupted, the project company may need to rent more cloud resources than planned, and so on.
When using Kubernetes, this problem simply cannot arise, since, regardless of what kind of cloud service provider we are talking about, working with Kubernetes always looks the same. The developer, in a declarative style, tells the API server what he needs, and Kubernetes works with the system resources, allowing the developer to abstract from the details of the implementation of this system.
Stay a little bit on this idea, as this is a very powerful Kubernetes opportunity. For companies, this means that their solutions are not tied to a particular CSP. If a company finds a more profitable offer on the cloud service market, it can freely use this offer by moving to a new provider. At the same time, the experience gained by the specialists of the company is not lost anywhere.
Now let's talk about the practical use of Kubernetes
We set up the launch of microservices in containers, the setup process was rather tedious, but we managed to get to a working system. In addition, as already mentioned, our solution does not scale well and is not resistant to failures. We will solve these problems with the help of Kubernetes. Next we bring our system to the form corresponding to the following scheme. Namely, the containers will be managed by Kubernetes.
Microservices work in a cluster managed by Kubernetes
Here, we will use Minikube to locally deploy the cluster and test the capabilities of Kubernetes, although everything that we are going to do here can also be done using cloud platform tools such as Azure or the Google Cloud Platform.
Follow the directions in the documentation to install Minikube. During the installation of Minikube, you also install Kubectl. This is a client that allows you to make requests to the Kubernetes API server.
To start Minikube, execute the
Minikube puts at our disposal a cluster that consists of only one node. True, it suits us perfectly. Those who work with Kubernetes do not need to worry about how many nodes are present in the cluster, since Kubernetes allows you to abstract from such details.
Now let's talk about the sub.
I really like containers, and you probably also like them now. Why, then, Kubernetes suggests that we use sweats, entities that are minimally deployable computing units in this system? What functions does it perform under? The point is that the composition of the hearth can include one or more containers that share the same execution environment.
But is it necessary to carry out, for example, two containers in one bag? How to say ... Usually, there is only one container per one, and that’s what we are going to do. But for those cases when, for example, two containers need common access to the same data storage, or if they are connected with the use of interprocess communication techniques, or if they are closely related for some other reason, all this can be done by running them in one hearth. Another possibility that pitches differ in is that they do not have to use Docker containers. If necessary, other application containerization technologies can be applied here, for example, Rkt .
The following diagram shows the numbered properties of the hearth.
Properties podov
Consider these properties.
It should be noted that containers have their own isolated file systems, but they can share data using the Kubernetes resource called Volume .
We have what is already said about the subframes, enough to continue to master the Kubernetes. You can read more about them here .
Below is a manifest file for the
Let us explain some of the parameters specified in it.
File description of the pod, which we talked about, can be found at
To find out if the sub works, run the following command:
If the status of the poda when executing this command is
In order to organize access to the application from the outside, it will be correct to create a Kubernetes resource of the Service type, which we will discuss below, but here, for the sake of brevity, we will use a simple port forwarding:
If you now go through the browser at
We have already said that one of the opportunities Kubernetes is scaling applications. In order to experience this opportunity, run another one under. Create another resource
As you can see, if we compare this description with what we considered above, the only change in it is the value of the
Create a new under:
Make sure that it is running:
Now we have two pod! True, there is nothing special to be happy about. Please note that the solution to the problem of scaling an application shown here has many drawbacks. How to do it right, we will talk in the section dedicated to another resource Kubernetes, which is called Deployment (deployment).
Now let's consider what we did after launching two identical pods. Namely, the Nginx web server is now running in two different hearths. In this regard, we can ask two questions:
Wrong approach to scaling
Among the means of Kubernetes are resources of the form Service. Let's talk about them.
Kubernetes services play the role of access points to sets of pods, which provide the same functionality as these pods. Services perform the solution of difficult tasks to work with the hearths and load balancing between them.
Kubernetes service serves IP addresses
In our cluster, Kubernetes will be set up, implementing various functions. This is a front-end application, a Spring web application and a Flask application written in Python. This raises the question of how the service should understand which subframes it needs to work with, that is, how to find out on the basis of what information the system should generate a list of endpoints for the pods.
This is done using another Kubernetes abstraction called Label. Work with tags consists of two stages:
Perhaps it is easier to present in the form of an illustration than to describe.
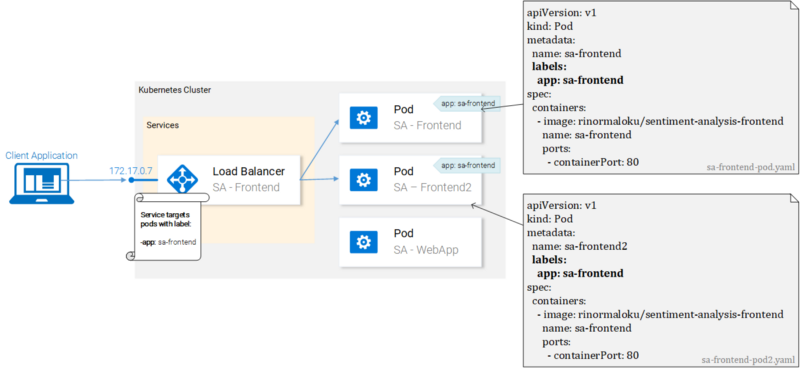
Pods with labels and their manifest files
We see here two hearths, which, using the
Labels give the developer a simple way to organize Kubernetes resources. They are key-value pairs, you can assign them to any resources. Modify the description files of the frontend applets and bring them to the form shown in the previous figure. After that, save these files and run the following commands:
When executing these commands, the system will issue warnings (it does not suit us that we use
Another way to check that the tags were actually assigned is to attach the
Now I’ll assign the tags assigned and we are ready to set up the service to work with them Therefore, let us take a description of the service type

Load balancing using a LoadBalancer type service
Here is the YAML description of the
We explain this text:
In order to create a service, run the following command:
You can check the status of the service as follows:
Here you can see that the
Despite this, Minikube will not allow us to idle, giving us a useful command to debug the system locally:
Thanks to this command, a browser will be launched that will access the service. After the service receives the request, it will redirect it to one of the pods (it doesn't matter which one it will be under). This abstraction allows us to perceive the group of pods as a single entity and work with them, using the service as a single access point to them.
In this section, we talked about how to assign tags to resources, how to use them when setting up services as selectors. Here we also described and created a
Deployment is an abstraction of Kubernetes that allows us to manage what is always present in the application life cycle. This is a change management application. Applications that do not change are, so to speak, "dead" applications. If the application "lives", then you may be faced with the fact that the requirements for it periodically change, its code expands, this code is packaged and deployed. In this case, at each step of this process errors may occur.
Resource type Deployment allows you to automate the transition from one version of the application to another. This is done without interrupting the system, and if an error occurs during this process, we will be able to quickly return to the previous, working version of the application.
Now the cluster has two hearths and a service that gives access to them from the outside and balances the load on them.
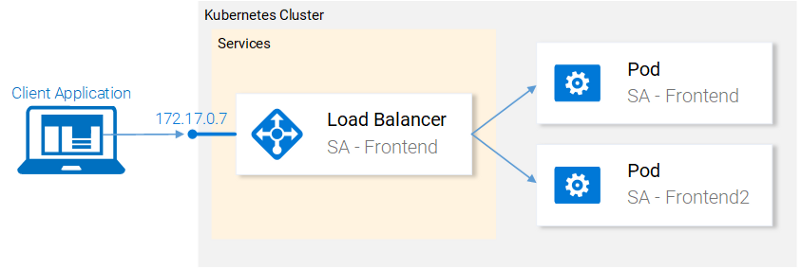
Current cluster status
We said that launching two different pods with the same functionality is not the best idea. When using such a scheme, we have to work with each hearth on an individual basis, creating, updating, deleting each individual under, observing its condition. With this approach, one does not have to talk about a quick system update or a quick rollback of an unsuccessful update. We are not satisfied with this state of affairs, therefore we are going to resort to the possibility of the Deployment resource, which is aimed at solving the above mentioned problems.
Before we continue our work, let's formulate its goals, which will give us guidelines that will be useful when parsing the deployment manifest file. So, this is what we need:
Now we will express these requirements as a description of the Deployment resource.
Here is the YAML description of the Deployment type resource, which was created taking into account the above described system requirements:
Let's sort this description:
Having examined all this, let's move on to practice. Run the deployment:
Check the system status:
As you can see, now we have 4 days. Two of them were created using the Deployment resource, two more are those that we created ourselves. Now you can remove those trails that we created ourselves, using the commands of the following form:
By the way, here is your task for independent work. Remove one of the pods created using the Deployment resource and watch the system. Think about the reasons for what is happening before reading on.
When you remove one sub-resource, the Deployment resource learns that the current state of the system (1 sub) is different from the desired one (2 sub-fields), so another sub flow is launched.
What is the benefit of Deployment resources, besides the fact that when using them the system is maintained in the right state? Consider the strengths of these resources.
Suppose a product manager comes to us and reports that the customer for whom we have created this product wants a green button in the client application. The developers implement this requirement and give us the only thing we need from them - the image container called
Edit the
Check the system status with the following command:
In accordance with the data output in response to this command, we can conclude that the deployment of the update was successful. В ходе обновления старые реплики, по одной, заменялись на новые. Это означает, что наше приложение, в ходе процесса обновления, всегда было доступно. Прежде чем мы продолжим работу, давайте убедимся в том, что приложений действительно обновилось.
Для того чтобы взглянуть на то, как приложение выглядит в браузере, воспользуемся уже известной вам командой:
В ответ на неё будет запущен браузер, а в нём откроется страница приложения.
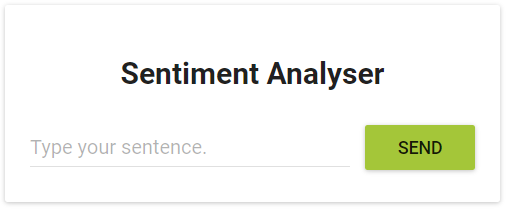
Зелёная кнопка
Как видно, кнопка и правда стала зелёной, значит — обновление системы действительно удалось.
После того, как мы выполнили команду
Замена подов в ходе обновления системы
Механизм
Теперь поговорим об ещё одной сильной стороне ресурсов Deployment. Для того чтобы было интересней, добавим повествованию драматизма. Вот рассказ про ошибку в продакшне.
Менеджер по продукту, сгорая от волнения, влетает в офис. «Баг! В продакшне! Верните всё как было!», — кричит он. Но его беспокойство не заражает вас нездоровым энтузиазмом. Вы, не теряя хладнокровия, открываете терминал и вводите следующую команду:
Вы смотрите на ранее выполненные развёртывания и спрашиваете у менеджера: «Так, свежая версия даёт сбои, но предыдущая работала отлично?».
«Да. Вы что, меня не слышали?», — продолжает надрываться менеджер.
Вы же, не обращая внимания на очередную его попытку вас растревожить, просто вводите в терминале следующее:
После этого вы открываете страницу приложения. Зелёная кнопка исчезла, а вместе с ней и ошибки.
Менеджер застывает с отвисшей от удивления челюстью.
Вы только что спасли компанию от катастрофы.
Занавес!
На самом деле, скучновато получилось. До существования Kubernetes в подобных рассказах было куда больше неожиданных поворотов сюжета, больше действия, и они так быстро не заканчивались. Эх, старые добрые времена!
Большинство вышеупомянутых команд и результатов их работы говорят сами за себя. Пожалуй, непонятной тут может быть лишь одна деталь. Почему
Если вы предположите, что причиной появления таких сведений стало использование флага --
В следующем разделе мы воспользуемся всем тем, что уже изучили, для того, чтобы выйти на полноценно работающее приложение.
Мы уже разобрались с ресурсами Kubernetes, необходимыми нам для того, чтобы построить полноценное кластерное приложение. На следующем рисунке выделено всё то, что нам ещё нужно сделать.
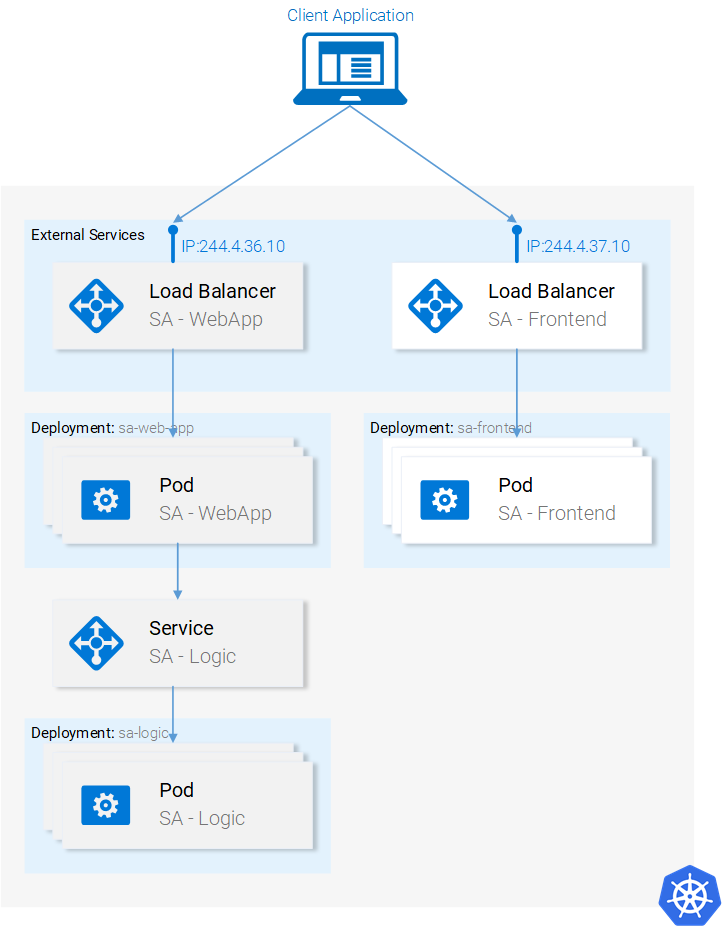
Текущее состояние приложение
Начнём работу с нижней части этой схемы.
Перейдите с помощью терминала в папку проекта
Развёртывание
В общем-то, ничего нового для себя вы там не найдёте, поэтому давайте займёмся следующим ресурсом — сервисом
Подумаем о том, зачем нам нужен этот ресурс вида Service. Дело в том, что наше Java-приложение, которое будет выполняться в подах с меткой
Именно поэтому нам и нужен сервис, который, как мы уже говорили, действует в качестве точки доступа к сущностям, реализующим одинаковые возможности. Это означает, что мы можем использовать сервис
Выполним следующую команду:
Теперь посмотрим на то, как изменилось состояние приложения после выполнения этой команды.
Изменённое состояние приложения
Теперь сервис
Развернём поды
Мы уже не раз выполняли развёртывания, но в данном случае в файле описания соответствующего ресурса Deployment вы можете встретить кое-что новое. Так, если заглянуть в файл
Какую роль играет свойство
Для того чтобы ответить на этот вопрос нам нужно познакомиться с концепцией kube-dns.
В Kubernetes есть специальный под, который называется
Это означает, что когда мы создаём сервис
Теперь продолжим работу с ресурсом Deployment
Выполните следующую команду:
Теперь нам осталось лишь обеспечить доступ к подам
Если вы откроете файл
Теперь кластер полностью готов. Но, чтобы всё было совсем хорошо, нам надо решить ещё одну задачу. Так, когда мы разворачивали поды
Исправление этого недостатка даст нам возможность быстро пробежаться по всему тому, изучением чего мы тут занимались. Кстати, если хотите извлечь из проработки этого материала максимум эффективности — вы можете, не читая пока дальше, попытаться исправить этот недостаток самостоятельно.
Собственно говоря, вот как выглядит пошаговое решение данной проблемы:
Теперь можно обновить страницу приложения, открытую в браузере, или, если вы уже закрыли окно браузера, можно выполнить команду
Готовое кластерное приложение
Использование технологии Kubernetes способно принести пользу командам разработчиков, это благотворно сказывается на работе над различными проектами, упрощает развёртывание приложений, помогает их масштабировать, делает их устойчивыми к сбоям. Благодаря Kubernetes можно пользоваться ресурсами, предоставляемыми самыми разными облачными провайдерами, и при этом не зависеть от решений конкретных поставщиков облачных услуг. Поэтому предлагаю переименовать Kubernetes в Supernetes.
Вот что вы узнали, освоив этот материал:
Кроме того, вы освоили важнейшие понятия Kubernetes:
В процессе работы мы превратили приложение, состоящее из микросервисов, в кластер Kubernetes.
Dear readers! Пользуетесь ли вы Kubernetes?

Meet Kubernetes
I promise, and at the same time I do not exaggerate at all that when you finish reading this article, ask yourself: “Why don't you call Kubernetes Supernetes?”.
Supernetes
If you read the previous part of this material, then you know that there we have analyzed a lot of things related to preparing applications for containerization and working with Docker containers. It may seem to you that the most difficult thing is waiting for you now, but, in fact, what we are going to talk about here is much simpler than what we have already figured out. The only reason for which the study of Kubernetes may seem to someone a very difficult task is the amount of additional information that you need to have in order to understand Kubernetes and to use this system effectively. We have already discussed all the “additional information” necessary for the successful development of Kubernetes.
▍What is Kubernetes?
In the first part of this material, after running microservices in containers, you were asked to think about the issue of scaling containerized applications.
I propose to reflect on it together, in the format of questions and answers:
Q: How are containerized applications scaled?
Answer: Launch additional containers.
Question: How do they distribute the load between them? What if some server is already used to the maximum, and the container needs to be deployed on another server? How to find the most efficient way to use hardware?
Answer: So ... I will look on the Internet ...
Question: How to update the program without disturbing the system? And, if the update contains an error, how to return to the working version of the application?
In fact, it is Kubernetes technology that provides decent answers to these and many other questions. I will try to shrink the definition of Kubernetes to one sentence: “Kubernetes is a container management system that abstracts the basic infrastructure (the environment in which containers run).”
I believe that now you are not particularly clear about the concept of "container management", although we have already mentioned this. Below we consider this technology in practice. However, the concept of “abstraction of basic infrastructure” is encountered for the first time. Therefore, now we consider it.
Б Abstraction of basic infrastructure
Kubernetes allows applications to abstract from the infrastructure, giving us a simple API to which you can send requests. Kubernetes tries to fulfill these requests using all its capabilities. For example, in ordinary language, a similar query can be described as: “Kubernetes, expand 4 containers of image X”. After receiving the command, Kubernetes will find not too loaded nodes (they are also called “nodes” - from the English “node”), on which you can deploy new containers.
API Server Request
What does this mean for the developer? This means that it does not need to worry about the number of nodes, about exactly where the containers are started, how they interact. It does not have to deal with hardware optimization or worry about nodes whose operation can be broken (and something like that, according to Murphy's law, is bound to happen), since, if necessary, new nodes can be added to the Kubernetes cluster. If there is something wrong with some existing nodes, Kubernetes will deploy containers on those nodes that are still in a healthy state.
Much of what is shown in the previous figure, you are already familiar. But there is something new there:
- API Server. Making calls to this server is the only way to interact with the cluster, which we have, whether we are talking about starting or stopping containers, checking the state of the system, working with logs, or performing other actions.
- Kubelet. This is the agent that monitors the containers inside the node and interacts with the main node.
Please note that in a couple of previous sentences we use the term "container", but here it would be better to use the term "pod". These entities in Russian-language publications are often called "podami", and sometimes - "pods", in the documentation , clarifying the concept of "pod", refer to "a flock of whales" (pod of whales) or "pea pod" , but no one calls them "flocks" or "pods". We, speaking of them, will use the word "under." Now you can quite consider them as containers, we will talk about feeds in more detail below.
We will dwell on this, as we can talk about all this further, and, moreover, there are a lot of good materials concerning the theory of Kubernetes. For example, this is official documentation, although reading it is not easy, or books like this .
▍Standardization of work with cloud service providers
Another strength of Kubernetes is that this technology contributes to the standardization of work with cloud service providers (Cloud Service Provider, CSP). This is a bold statement. Consider the following example. A specialist who knows Azure well or the Google Cloud Platform has to work on a project designed for a completely new cloud environment with which he is unfamiliar. In such a situation, much can go wrong. For example, the deadlines for project delivery may be disrupted, the project company may need to rent more cloud resources than planned, and so on.
When using Kubernetes, this problem simply cannot arise, since, regardless of what kind of cloud service provider we are talking about, working with Kubernetes always looks the same. The developer, in a declarative style, tells the API server what he needs, and Kubernetes works with the system resources, allowing the developer to abstract from the details of the implementation of this system.
Stay a little bit on this idea, as this is a very powerful Kubernetes opportunity. For companies, this means that their solutions are not tied to a particular CSP. If a company finds a more profitable offer on the cloud service market, it can freely use this offer by moving to a new provider. At the same time, the experience gained by the specialists of the company is not lost anywhere.
Now let's talk about the practical use of Kubernetes
Practice working with Kubernetes: pods
We set up the launch of microservices in containers, the setup process was rather tedious, but we managed to get to a working system. In addition, as already mentioned, our solution does not scale well and is not resistant to failures. We will solve these problems with the help of Kubernetes. Next we bring our system to the form corresponding to the following scheme. Namely, the containers will be managed by Kubernetes.
Microservices work in a cluster managed by Kubernetes
Here, we will use Minikube to locally deploy the cluster and test the capabilities of Kubernetes, although everything that we are going to do here can also be done using cloud platform tools such as Azure or the Google Cloud Platform.
▍Minikube installation and launch
Follow the directions in the documentation to install Minikube. During the installation of Minikube, you also install Kubectl. This is a client that allows you to make requests to the Kubernetes API server.
To start Minikube, execute the
minikube start command, and after it runs, execute the kubectl get nodes command. As a result, you should see something like the following: kubectl get nodes NAME STATUS ROLES AGE VERSION minikube Ready <none> 11m v1.9.0 Minikube puts at our disposal a cluster that consists of only one node. True, it suits us perfectly. Those who work with Kubernetes do not need to worry about how many nodes are present in the cluster, since Kubernetes allows you to abstract from such details.
Now let's talk about the sub.
▍Fets
I really like containers, and you probably also like them now. Why, then, Kubernetes suggests that we use sweats, entities that are minimally deployable computing units in this system? What functions does it perform under? The point is that the composition of the hearth can include one or more containers that share the same execution environment.
But is it necessary to carry out, for example, two containers in one bag? How to say ... Usually, there is only one container per one, and that’s what we are going to do. But for those cases when, for example, two containers need common access to the same data storage, or if they are connected with the use of interprocess communication techniques, or if they are closely related for some other reason, all this can be done by running them in one hearth. Another possibility that pitches differ in is that they do not have to use Docker containers. If necessary, other application containerization technologies can be applied here, for example, Rkt .
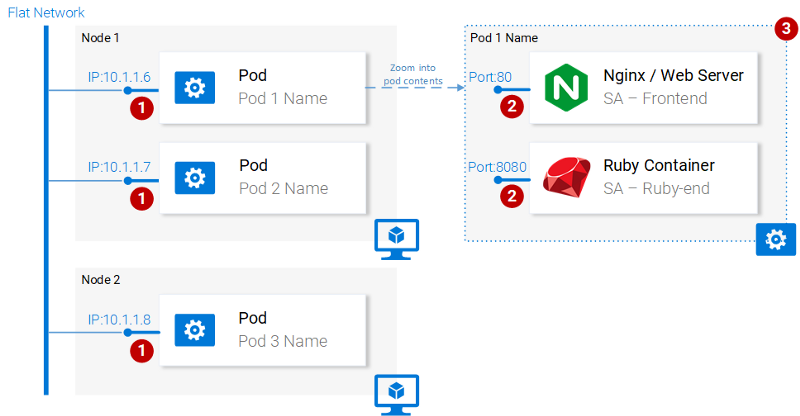
The following diagram shows the numbered properties of the hearth.
Properties podov
Consider these properties.
- Each hearth in the Kubernetes cluster has a unique IP address.
- In the hearth can contain many containers. They share the available port numbers, that is, for example, they can exchange information with each other through
localhost(of course, they cannot use the same ports). Interaction with containers located in other sub-fields is organized using the IP addresses of these subfields. - The containers in the sub-sites share the data storage volumes, the IP address, the port numbers, the IPC namespace.
It should be noted that containers have their own isolated file systems, but they can share data using the Kubernetes resource called Volume .
We have what is already said about the subframes, enough to continue to master the Kubernetes. You can read more about them here .
▍Description
Below is a manifest file for the
sa-frontend application. apiVersion: v1 kind: Pod # 1 metadata: name: sa-frontend # 2 spec: # 3 containers: - image: rinormaloku/sentiment-analysis-frontend # 4 name: sa-frontend # 5 ports: - containerPort: 80 Let us explain some of the parameters specified in it.
Kind: sets the type of Kubernetes resource we want to create. In our case, this is aPod.Name: the name of the resource. We called itsa-frontend.Spec: An object that describes the desired state of the resource. The most important property here is an array of containers.Image: image of the container that we want to run in this pane.Name: a unique name for the container located in the pod.ContainerPort: the port that listens on the container. This parameter can be considered an indication for who reads this file (if you omit this parameter, it will not restrict access to the port).
▍Creating a SA-Frontend Bottom
File description of the pod, which we talked about, can be found at
resource-manifests/sa-frontend-pod.yaml . In this folder, you must either go through the terminal, or, when calling the appropriate command, specify the full path to the file. Here is this command and an example of the system's reaction to it: kubectl create -f sa-frontend-pod.yaml pod "sa-frontend" created To find out if the sub works, run the following command:
kubectl get pods NAME READY STATUS RESTARTS AGE sa-frontend 1/1 Running 0 7s If the status of the poda when executing this command is
ContainerCreating , then you can run the same command with the --watch key. Because of this, when you go to the Running state, this information will be displayed automatically.▍Access to the application from outside
In order to organize access to the application from the outside, it will be correct to create a Kubernetes resource of the Service type, which we will discuss below, but here, for the sake of brevity, we will use a simple port forwarding:
kubectl port-forward sa-frontend 88:80 Forwarding from 127.0.0.1:88 -> 80 If you now go through the browser at
127.0.0.1:88 , you will see the React-application page.▍ Wrong approach to scaling
We have already said that one of the opportunities Kubernetes is scaling applications. In order to experience this opportunity, run another one under. Create another resource
Pod description by placing the following code in the sa-frontend-pod2.yaml file: apiVersion: v1 kind: Pod metadata: name: sa-frontend2 # Единственное изменение spec: containers: - image: rinormaloku/sentiment-analysis-frontend name: sa-frontend ports: - containerPort: 80 As you can see, if we compare this description with what we considered above, the only change in it is the value of the
Name property.Create a new under:
kubectl create -f sa-frontend-pod2.yaml pod "sa-frontend2" created Make sure that it is running:
kubectl get pods NAME READY STATUS RESTARTS AGE sa-frontend 1/1 Running 0 7s sa-frontend2 1/1 Running 0 7s Now we have two pod! True, there is nothing special to be happy about. Please note that the solution to the problem of scaling an application shown here has many drawbacks. How to do it right, we will talk in the section dedicated to another resource Kubernetes, which is called Deployment (deployment).
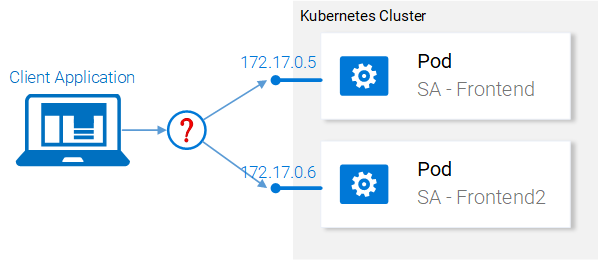
Now let's consider what we did after launching two identical pods. Namely, the Nginx web server is now running in two different hearths. In this regard, we can ask two questions:
- How to give access to these servers from the outside, by URL?
- How to organize load balancing between them?
Wrong approach to scaling
Among the means of Kubernetes are resources of the form Service. Let's talk about them.
Practice working with Kubernetes: services
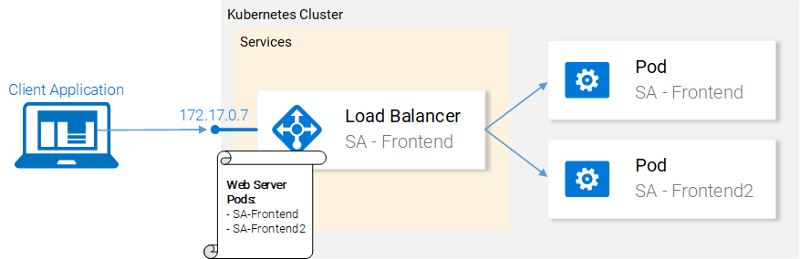
Kubernetes services play the role of access points to sets of pods, which provide the same functionality as these pods. Services perform the solution of difficult tasks to work with the hearths and load balancing between them.
Kubernetes service serves IP addresses
In our cluster, Kubernetes will be set up, implementing various functions. This is a front-end application, a Spring web application and a Flask application written in Python. This raises the question of how the service should understand which subframes it needs to work with, that is, how to find out on the basis of what information the system should generate a list of endpoints for the pods.
This is done using another Kubernetes abstraction called Label. Work with tags consists of two stages:
- The purpose of the label will be the one with which the service should work.
- Application to the service of "selector", which determines the fact with which particular trays, which are assigned tags, the service will work.
Perhaps it is easier to present in the form of an illustration than to describe.
Pods with labels and their manifest files
We see here two hearths, which, using the
app: sa-frontend construction, are assigned the same labels. Service interested pods with such tags.▍Tags
Labels give the developer a simple way to organize Kubernetes resources. They are key-value pairs, you can assign them to any resources. Modify the description files of the frontend applets and bring them to the form shown in the previous figure. After that, save these files and run the following commands:
kubectl apply -f sa-frontend-pod.yaml Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply pod "sa-frontend" configured kubectl apply -f sa-frontend-pod2.yaml Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply pod "sa-frontend2" configured When executing these commands, the system will issue warnings (it does not suit us that we use
apply instead of create , we understand this), but, after the warning, it reports that the corresponding heartbeats are configured. To check whether tags have been assigned, we can, by filtering the tags, the information about which we want to display: kubectl get pod -l app=sa-frontend NAME READY STATUS RESTARTS AGE sa-frontend 1/1 Running 0 2h sa-frontend2 1/1 Running 0 2h Another way to check that the tags were actually assigned is to attach the
--show-labels key to the previous command. Thanks to this information about their tags will be included in the list of information about the subfields.Now I’ll assign the tags assigned and we are ready to set up the service to work with them Therefore, let us take a description of the service type
LoadBalancer .Load balancing using a LoadBalancer type service
▍Description of service
Here is the YAML description of the
LoadBalancer type LoadBalancer : apiVersion: v1 kind: Service # 1 metadata: name: sa-frontend-lb spec: type: LoadBalancer # 2 ports: - port: 80 # 3 protocol: TCP # 4 targetPort: 80 # 5 selector: # 6 app: sa-frontend # 7 We explain this text:
Kind: we create a service, resourceService.Type: the type of resource indicated in its specification. We chose the typeLoadBalancer, because with the help of this service we want to solve the problem of load balancing between the sweeps.Port: the port on which the service receives requests.Protocol: the protocol used by the service.TargetPort: the port to which incoming requests are redirected.Selector: an object containing information about which subsection the service should work with.app: sa-frontend: this property indicates which subscription the service will work with. Namely, these are the pods that have theapp: sa-frontendlabel assignedapp: sa-frontend.
In order to create a service, run the following command:
kubectl create -f service-sa-frontend-lb.yaml service "sa-frontend-lb" created You can check the status of the service as follows:
kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE sa-frontend-lb LoadBalancer 10.101.244.40 <pending> 80:30708/TCP 7m Here you can see that the
EXTERNAL-IP property is in the <pending> state, and you can not wait for its change. This happens due to the fact that we use Minikube. If we created such a service, working with a certain cloud service provider, like Azure or the Google Cloud Platform, then the service would have a public IP address that would enable it to access it from the Internet.Despite this, Minikube will not allow us to idle, giving us a useful command to debug the system locally:
minikube service sa-frontend-lb Opening kubernetes service default/sa-frontend-lb in default browser... Thanks to this command, a browser will be launched that will access the service. After the service receives the request, it will redirect it to one of the pods (it doesn't matter which one it will be under). This abstraction allows us to perceive the group of pods as a single entity and work with them, using the service as a single access point to them.
In this section, we talked about how to assign tags to resources, how to use them when setting up services as selectors. Here we also described and created a
LoadBalancer type LoadBalancer . Thanks to this, we solved the task of scaling the application (scaling is to add new pods with corresponding labels to the cluster) and to organize load balancing between the pods using the service as an entry point.Practice working with Kubernetes: deployment
Deployment is an abstraction of Kubernetes that allows us to manage what is always present in the application life cycle. This is a change management application. Applications that do not change are, so to speak, "dead" applications. If the application "lives", then you may be faced with the fact that the requirements for it periodically change, its code expands, this code is packaged and deployed. In this case, at each step of this process errors may occur.
Resource type Deployment allows you to automate the transition from one version of the application to another. This is done without interrupting the system, and if an error occurs during this process, we will be able to quickly return to the previous, working version of the application.
▍Use of deployments
Now the cluster has two hearths and a service that gives access to them from the outside and balances the load on them.
Current cluster status
We said that launching two different pods with the same functionality is not the best idea. When using such a scheme, we have to work with each hearth on an individual basis, creating, updating, deleting each individual under, observing its condition. With this approach, one does not have to talk about a quick system update or a quick rollback of an unsuccessful update. We are not satisfied with this state of affairs, therefore we are going to resort to the possibility of the Deployment resource, which is aimed at solving the above mentioned problems.
Before we continue our work, let's formulate its goals, which will give us guidelines that will be useful when parsing the deployment manifest file. So, this is what we need:
- We want to be able to create two pods based on one
rinormaloku/sentiment-analysis-frontendcontainer. - We need an application deployment system that allows it, when it is updated, to work without interruption.
- We want the
app: sa-frontendtag to be assigned, which will allow thesa-frontend-lbservice to detect these feeds.
Now we will express these requirements as a description of the Deployment resource.
▍Description of deployment
Here is the YAML description of the Deployment type resource, which was created taking into account the above described system requirements:
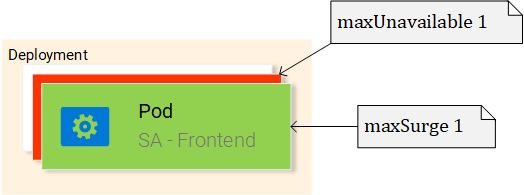
apiVersion: extensions/v1beta1 kind: Deployment # 1 metadata: name: sa-frontend spec: replicas: 2 # 2 minReadySeconds: 15 strategy: type: RollingUpdate # 3 rollingUpdate: maxUnavailable: 1 # 4 maxSurge: 1 # 5 template: # 6 metadata: labels: app: sa-frontend # 7 spec: containers: - image: rinormaloku/sentiment-analysis-frontend imagePullPolicy: Always # 8 name: sa-frontend ports: - containerPort: 80 Let's sort this description:
Kind: it says here that we are describing the resource of theDeploymentview.Replicas: a property of the deployment specification object, which specifies how many instances (replicas) of the sweeps need to be run.Type: describes the strategy used in this deployment when upgrading from the current version to the new one.RollingUpdatestrategy provides zero system downtime when upgrading.MaxUnavailable: This is a property of theRollingUpdateobject that specifies the maximum number of inaccessible sweeps (compared to the desired number of sweeps) when performing a sequential system update. In our deployment, which implies the presence of 2 replicas, the value of this property indicates that after the completion of one hearth, another one will be executed, which makes the application available during the update.MaxSurge: This is a property of theRollingUpdateobject that describes the maximum number of pods that can be added to the deployment (as compared to the specified number of pods). In our case, its value, 1, means that, when upgrading to a new version of the program, we can add one more to the cluster, which will lead to the fact that we can simultaneously run up to three subs.Template: This object specifies the pod template that theDeploymentresource will use to create new pods. This setting will probably seem familiar to you.app: sa-frontend: label for pods created on a given pattern.ImagePullPolicy: determines the order of working with images. In our case, this property is set toAlways, that is, during each deployment, the corresponding image will be loaded from the repository.
Having examined all this, let's move on to practice. Run the deployment:
kubectl apply -f sa-frontend-deployment.yaml deployment "sa-frontend" created Check the system status:
kubectl get pods NAME READY STATUS RESTARTS AGE sa-frontend 1/1 Running 0 2d sa-frontend-5d5987746c-ml6m4 1/1 Running 0 1m sa-frontend-5d5987746c-mzsgg 1/1 Running 0 1m sa-frontend2 1/1 Running 0 2d As you can see, now we have 4 days. Two of them were created using the Deployment resource, two more are those that we created ourselves. Now you can remove those trails that we created ourselves, using the commands of the following form:
kubectl delete pod <pod-name> By the way, here is your task for independent work. Remove one of the pods created using the Deployment resource and watch the system. Think about the reasons for what is happening before reading on.
When you remove one sub-resource, the Deployment resource learns that the current state of the system (1 sub) is different from the desired one (2 sub-fields), so another sub flow is launched.
What is the benefit of Deployment resources, besides the fact that when using them the system is maintained in the right state? Consider the strengths of these resources.
▍ Execute deployment with zero system downtime
Suppose a product manager comes to us and reports that the customer for whom we have created this product wants a green button in the client application. The developers implement this requirement and give us the only thing we need from them - the image container called
rinormaloku/sentiment-analysis-frontend:green . Now comes our time. We, the DevOps team, need to perform the deployment of the updated system and ensure zero downtime. Now let's see if the efforts to master and configure the Deployment resource are justified.Edit the
sa-frontend-deployment.yaml file, replacing the image container name with a new one, with rinormaloku/sentiment-analysis-frontend:green , and then save this file as sa-frontend-deployment-green.yaml and execute the following command: kubectl apply -f sa-frontend-deployment-green.yaml --record deployment "sa-frontend" configured Check the system status with the following command:
kubectl rollout status deployment sa-frontend Waiting for rollout to finish: 1 old replicas are pending termination... Waiting for rollout to finish: 1 old replicas are pending termination... Waiting for rollout to finish: 1 old replicas are pending termination... Waiting for rollout to finish: 1 old replicas are pending termination... Waiting for rollout to finish: 1 old replicas are pending termination... Waiting for rollout to finish: 1 of 2 updated replicas are available... deployment "sa-frontend" successfully rolled out In accordance with the data output in response to this command, we can conclude that the deployment of the update was successful. В ходе обновления старые реплики, по одной, заменялись на новые. Это означает, что наше приложение, в ходе процесса обновления, всегда было доступно. Прежде чем мы продолжим работу, давайте убедимся в том, что приложений действительно обновилось.
Проверка развёртывания
Для того чтобы взглянуть на то, как приложение выглядит в браузере, воспользуемся уже известной вам командой:
minikube service sa-frontend-lb В ответ на неё будет запущен браузер, а в нём откроется страница приложения.
Зелёная кнопка
Как видно, кнопка и правда стала зелёной, значит — обновление системы действительно удалось.
Закулисье обновления системы по схеме RollingUpdate
После того, как мы выполнили команду
kubectl apply -f sa-frontend-deployment-green.yaml --record , Kubernetes сравнил состояние системы, к которому мы стремимся прийти, с её текущим состоянием. В нашем случае для перехода в новое состояние нужно, чтобы в кластере имелись бы два пода, основанные на образах rinormaloku/sentiment-analysis-frontend:green . Так как это отличается от того состояния, в котором пребывает система, запускается операция обновления.Замена подов в ходе обновления системы
Механизм
RollingUpdate действует в соответствии с заданными нами правилами, а именно, речь идёт о параметрах maxUnavailable: 1 и maxSurge: 1 . Это значит, что ресурс Deployment может, при наличии двух работающих подов, остановить один из них, или запустить ещё один под. Этот процесс, показанный на предыдущем рисунке, повторяется до тех пор, пока все старые поды не будут заменены на новые.Теперь поговорим об ещё одной сильной стороне ресурсов Deployment. Для того чтобы было интересней, добавим повествованию драматизма. Вот рассказ про ошибку в продакшне.
▍Откат к предыдущему состоянию системы
Менеджер по продукту, сгорая от волнения, влетает в офис. «Баг! В продакшне! Верните всё как было!», — кричит он. Но его беспокойство не заражает вас нездоровым энтузиазмом. Вы, не теряя хладнокровия, открываете терминал и вводите следующую команду:
kubectl rollout history deployment sa-frontend deployments "sa-frontend" REVISION CHANGE-CAUSE 1 <none> 2 kubectl.exe apply --filename=sa-frontend-deployment-green.yaml --record=true Вы смотрите на ранее выполненные развёртывания и спрашиваете у менеджера: «Так, свежая версия даёт сбои, но предыдущая работала отлично?».
«Да. Вы что, меня не слышали?», — продолжает надрываться менеджер.
Вы же, не обращая внимания на очередную его попытку вас растревожить, просто вводите в терминале следующее:
kubectl rollout undo deployment sa-frontend --to-revision=1 deployment "sa-frontend" rolled back После этого вы открываете страницу приложения. Зелёная кнопка исчезла, а вместе с ней и ошибки.
Менеджер застывает с отвисшей от удивления челюстью.
Вы только что спасли компанию от катастрофы.
Занавес!
На самом деле, скучновато получилось. До существования Kubernetes в подобных рассказах было куда больше неожиданных поворотов сюжета, больше действия, и они так быстро не заканчивались. Эх, старые добрые времена!
Большинство вышеупомянутых команд и результатов их работы говорят сами за себя. Пожалуй, непонятной тут может быть лишь одна деталь. Почему
CHANGE-CAUSE у первой ревизии имеет значение <none> , а у второй — kubectl.exe apply –filename=sa-frontend-deployment-green.yaml –record=true ?Если вы предположите, что причиной появления таких сведений стало использование флага --
record при развёртывании новой версии приложения, то окажетесь совершенно правы.В следующем разделе мы воспользуемся всем тем, что уже изучили, для того, чтобы выйти на полноценно работающее приложение.
Практика работы с Kubernetes: совместное использование изученных механизмов
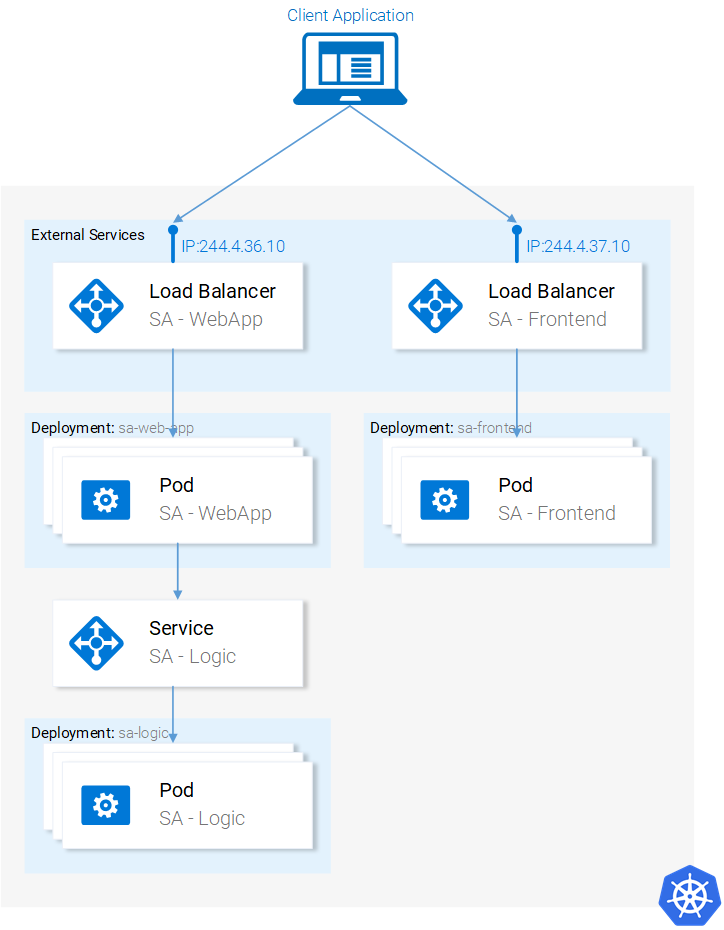
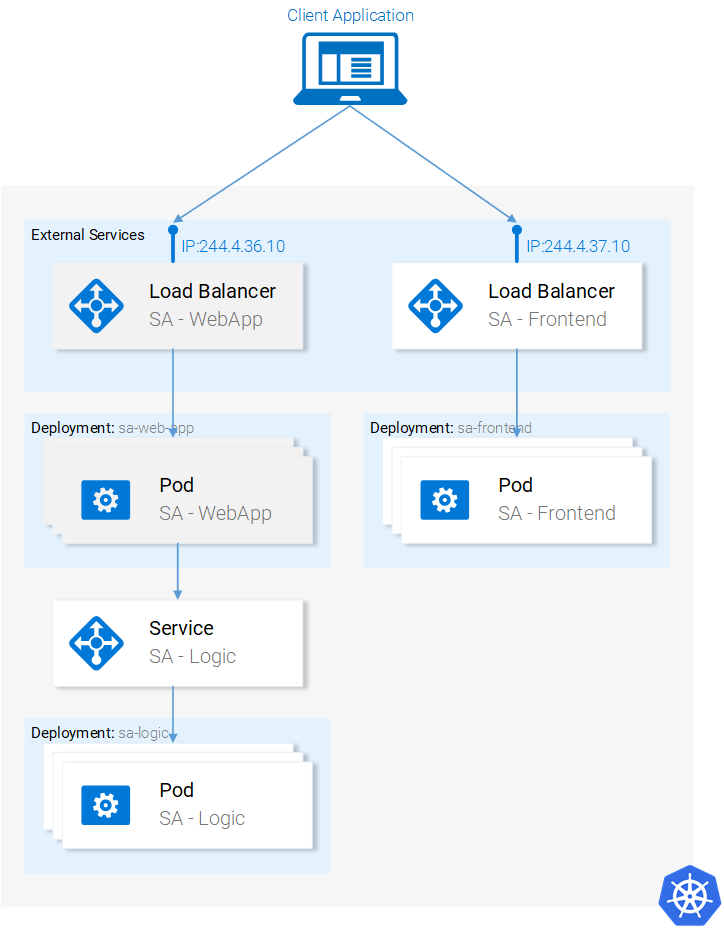
Мы уже разобрались с ресурсами Kubernetes, необходимыми нам для того, чтобы построить полноценное кластерное приложение. На следующем рисунке выделено всё то, что нам ещё нужно сделать.
Текущее состояние приложение
Начнём работу с нижней части этой схемы.
▍Развёртывание подов sa-logic
Перейдите с помощью терминала в папку проекта
resource-manifests и выполните следующую команду: kubectl apply -f sa-logic-deployment.yaml --record deployment "sa-logic" created Развёртывание
sa-logic создаёт три пода. В них выполняются контейнеры Python-приложения. Им назначены метки app: sa-logic . Это позволяет нам работать с ними с помощью сервиса sa-logic , используя соответствующий селектор. Откройте файл sa-logic-deployment.yaml и ознакомьтесь с его содержимым.В общем-то, ничего нового для себя вы там не найдёте, поэтому давайте займёмся следующим ресурсом — сервисом
sa-logic .▍Сервис sa-logic
Подумаем о том, зачем нам нужен этот ресурс вида Service. Дело в том, что наше Java-приложение, которое будет выполняться в подах с меткой
sa-webapp , зависит от возможностей по анализу текстов, реализуемых Python-приложением. Но сейчас, в отличие от ситуации, в которой всё работает на локальной машине, у нас нет единственного Python-приложения, прослушивающего некий порт. У нас есть несколько подов, количество которых, при необходимости, можно увеличить.Именно поэтому нам и нужен сервис, который, как мы уже говорили, действует в качестве точки доступа к сущностям, реализующим одинаковые возможности. Это означает, что мы можем использовать сервис
sa-logic в качестве абстракции, дающей возможность работать со всеми подами sa-logic .Выполним следующую команду:
kubectl apply -f service-sa-logic.yaml service "sa-logic" created Теперь посмотрим на то, как изменилось состояние приложения после выполнения этой команды.
Изменённое состояние приложения
Теперь сервис
sa-logic позволяет, из подов sa-webapp , работать с набором подов, реализующих функционал анализа текста.Развернём поды
sa-webapp .▍Развёртывание подов sa-webapp
Мы уже не раз выполняли развёртывания, но в данном случае в файле описания соответствующего ресурса Deployment вы можете встретить кое-что новое. Так, если заглянуть в файл
sa-web-app-deployment.yaml , там можно обратить внимание на следующее: - image: rinormaloku/sentiment-analysis-web-app imagePullPolicy: Always name: sa-web-app env: - name: SA_LOGIC_API_URL value: "http://sa-logic" ports: - containerPort: 8080 Какую роль играет свойство
env ? Можно предположить, что оно объявляет, внутри подов, переменную окружения SA_LOGIC_API_URL со значением http://sa-logic . Если это так, то хорошо бы понять, почему значение переменной содержит такой необычный адрес. На что он указывает?Для того чтобы ответить на этот вопрос нам нужно познакомиться с концепцией kube-dns.
▍DNS-сервер кластера Kubernetes
В Kubernetes есть специальный под, который называется
kube-dns . По умолчанию все поды используют его как DNS-сервер. Одной из важных особенностей kube-dns является тот факт, что этот под создаёт DNS-запись для каждого сервиса кластера.Это означает, что когда мы создаём сервис
sa-logic , ему назначается IP-адрес. В kube-dns делается запись со сведениями об имени и IP-адресе сервиса. Это позволяет всем подам преобразовывать адрес вида http://sa-logic в IP-адрес.Теперь продолжим работу с ресурсом Deployment
sa-webapp .▍Развёртывание подов sa-webapp
Выполните следующую команду:
kubectl apply -f sa-web-app-deployment.yaml --record deployment "sa-web-app" created Теперь нам осталось лишь обеспечить доступ к подам
sa-webapp с помощью сервиса, организующего балансировку нагрузки. Это позволит React-приложению выполнять запросы к сервису, который является точкой доступа к подам sa-webapp .▍Сервис sa-webapp
Если вы откроете файл
service-sa-web-app-lb.yaml , то поймёте, что всё, что там можно увидеть, уже вам встречалось. Поэтому, без ненужных пояснений, выполним следующую команду: kubectl apply -f service-sa-web-app-lb.yaml service "sa-web-app-lb" created Теперь кластер полностью готов. Но, чтобы всё было совсем хорошо, нам надо решить ещё одну задачу. Так, когда мы разворачивали поды
sa-frontend , контейнеризированное приложение было рассчитано на обращение к Java-приложению sa-webapp , находящемуся по адресу http://localhost:8080/sentiment . Теперь же нам нужно сделать так, чтобы оно обращалось бы к балансировщику нагрузки, к сервису sa-webapp , который обеспечит взаимодействие React-приложения с подами, в которых запущены экземпляры Java-приложения.Исправление этого недостатка даст нам возможность быстро пробежаться по всему тому, изучением чего мы тут занимались. Кстати, если хотите извлечь из проработки этого материала максимум эффективности — вы можете, не читая пока дальше, попытаться исправить этот недостаток самостоятельно.
Собственно говоря, вот как выглядит пошаговое решение данной проблемы:
- Узнаем IP-адрес балансировщика нагрузки
sa-webapp, выполнив следующую команду:minikube service list
|-------------|----------------------|-----------------------------|
| NAMESPACE | NAME | URL |
|-------------|----------------------|-----------------------------|
| default | kubernetes | No node port |
| default | sa-frontend-lb | http://192.168.99.100:30708 |
| default | sa-logic | No node port |
| default | sa-web-app-lb | http://192.168.99.100:31691 |
| kube-system | kube-dns | No node port |
| kube-system | kubernetes-dashboard | http://192.168.99.100:30000 |
|-------------|----------------------|-----------------------------| - Используем найденный IP-адрес в файле
sa-frontend/src/App.js. Вот фрагмент файла, в который мы вносим изменения:analyzeSentence() { fetch('http://192.168.99.100:31691/sentiment', { /* убрано ради краткости */}) .then(response => response.json()) .then(data => this.setState(data)); } - Соберём React-приложение, перейдя с помощью терминала в папку
sa-frontendи выполнив командуnpm run build. - Соберём образ контейнера:
docker build -f Dockerfile -t $DOCKER_USER_ID/sentiment-analysis-frontend:minikube. - Отправим образ в репозиторий Docker Hub:
docker push $DOCKER_USER_ID/sentiment-analysis-frontend:minikube - Отредактируем файл
sa-frontend-deployment.yaml, внеся в него сведения о новом образе. - Выполним следующую команду:
kubectl apply -f sa-frontend-deployment.yaml
Теперь можно обновить страницу приложения, открытую в браузере, или, если вы уже закрыли окно браузера, можно выполнить команду
minikube service sa-frontend-lb . Испытайте систему, попытавшись проанализировать какое-нибудь предложение.Готовое кластерное приложение
Results
Использование технологии Kubernetes способно принести пользу командам разработчиков, это благотворно сказывается на работе над различными проектами, упрощает развёртывание приложений, помогает их масштабировать, делает их устойчивыми к сбоям. Благодаря Kubernetes можно пользоваться ресурсами, предоставляемыми самыми разными облачными провайдерами, и при этом не зависеть от решений конкретных поставщиков облачных услуг. Поэтому предлагаю переименовать Kubernetes в Supernetes.
Вот что вы узнали, освоив этот материал:
- Сборка, упаковка и запуск приложений, основанных на React, Java и Python.
- Работа с контейнерами Docker, а именно, их описание и сборка с использованием файла
Dockerfile. - Работа с репозиториями контейнеров, в частности, с Docker Hub.
Кроме того, вы освоили важнейшие понятия Kubernetes:
- Поды
- Services
- Развёртывания
- Важные концепции наподобие выполнения обновления приложений без остановки работы системы
- Масштабирование приложений
В процессе работы мы превратили приложение, состоящее из микросервисов, в кластер Kubernetes.
Dear readers! Пользуетесь ли вы Kubernetes?
Source: https://habr.com/ru/post/438984/