What hardware to analyze a huge shaft of information?
We are Big Data in MTS and this is our first post. Today we will talk about what technologies allow us to store and process big data so that there is always enough resources for analytics, and the cost of purchasing iron does not go beyond the clouds.
The creation of the Big Data Center at MTS was thought of in 2014: there was a need to scale the classical analytical repository and BI reporting over it. At that time, the data processing engine and BI were SASovskie - it happened historically. And although the business needs for storage were closed, over time, the functionality of BI and ad hoc analytics on top of the analytical repository grew so much that it was necessary to solve the issue of increasing productivity, given that over the years the number of users increased tenfold and continued to grow.
As a result of the competition, the Teradata MPP system appeared in the MTS, covering the needs of the telecom at that time. This was the impetus for trying something more popular and open source.

In the photo - the Big Data MTS team in the new Descartes office in Moscow
The first cluster was from 7 nodes. This was enough to test several business hypotheses and tamper with the first cones. The efforts were not in vain: Big Data in the MTS has existed for three years now and data analysis is involved in almost all functional areas. The team grew from three people to two hundred.
We wanted to have easy development processes, quickly test hypotheses. To do this, you need three things: a team with start-up thinking, lightweight development processes and a developed infrastructure. There are a lot of places where you can read and listen about the first and second, but you should tell about developed infrastructure separately, as legacy and data sources that are in telecom are important here. The developed data infrastructure is not only the construction of the data lake, a detailed data layer and a storefront layer. It is also tools and data access interfaces, isolation of computing resources for products and teams, data delivery mechanisms to consumers - both in real-time and in batch mode. And many many others.
All this work has been singled out for us in a separate area, which is engaged in the development of utilities and tools for working with data. This direction is called the IT Big Data platform.
There are a lot of data sources in MTS. One of the main ones is base stations, we serve the subscriber base of more than 78 million subscribers in Russia. We also have many services and services that do not belong to a telecom and allow you to receive more versatile data (e-commerce, system integration, Internet of things, cloud services, etc. - all of “non-telecom” brings about 20% of the total revenue).
Briefly, our architecture can be represented as such a graph:
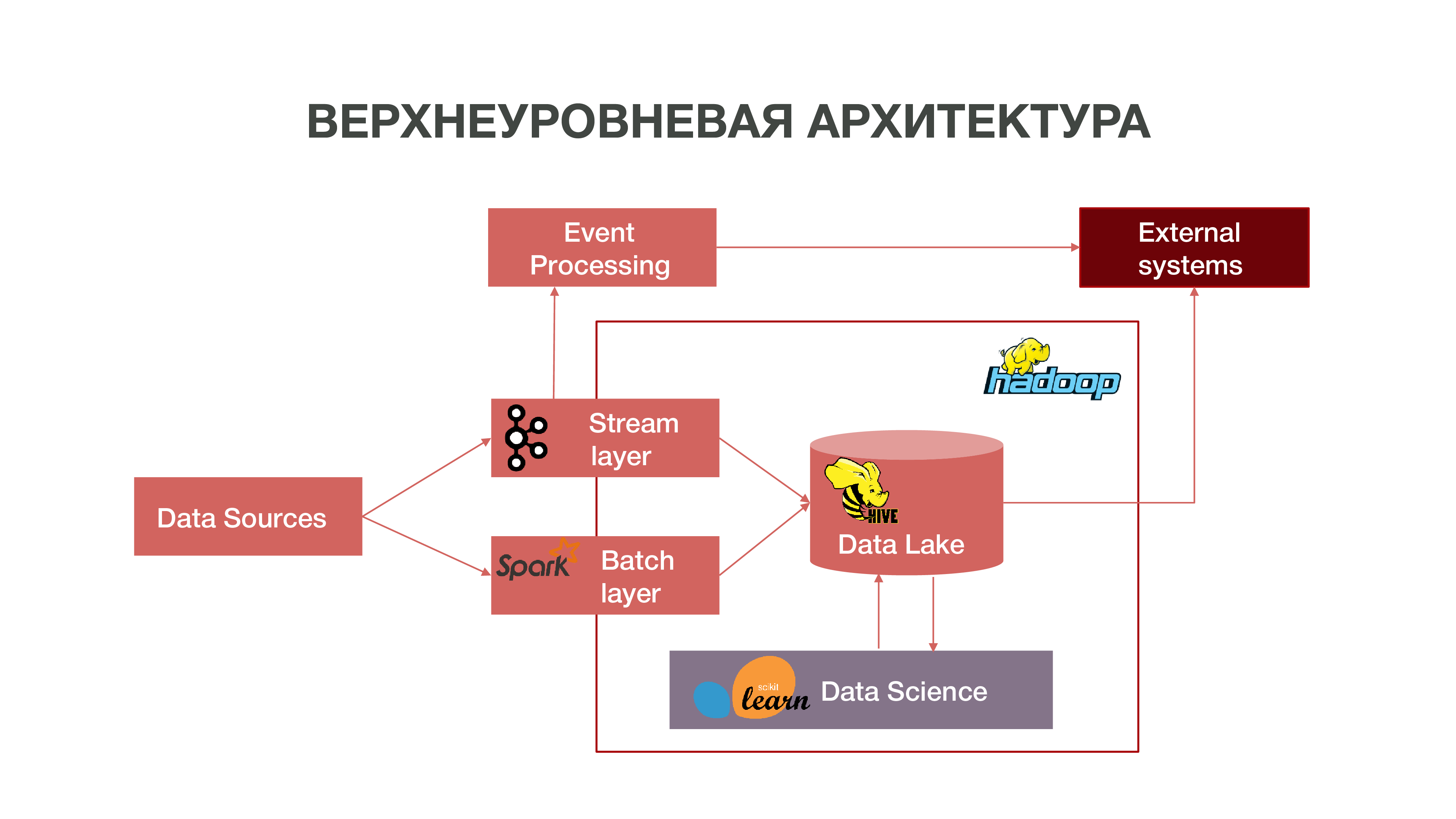
As can be seen in the graph, Data Sources can give out information in real time. We use the stream layer - we can process information in real-time, extract some events from it that we are interested in, and build analytics on this. In order to provide such event processing, we have developed a fairly standard implementation (from an architectural point of view) using Apache Kafka, Apache Spark and Scala code. Information obtained as a result of this analysis can be consumed both inside the MTS and in the future outside: the fact that certain actions of subscribers are often interesting is for businesses.
There is also a mode of loading data in batches - batch layer. Usually the download occurs once an hour on a schedule, as a scheduler, we use Apache Airflow, and the batch download processes themselves are implemented in python. In this case, Data Lake loads much more data needed to fill Big Data with historical data, which our Data Science models should be trained on. As a result, a subscriber profile is formed in a historical context based on data about its network activity. This allows you to get predictive statistics and build models of human behavior, even to create his psychological portrait - we have such a separate product. This information is very useful, for example, for marketing companies.
We also have a large amount of data that make up the classic repository. That is, we aggregate information on various events - both user and network. All this anonymized data also helps to more accurately predict the interests of users and events important to the company — for example, to predict possible equipment failures and to troubleshoot problems on time.
If you look back in time and remember how big data appeared at all, then it should be noted that mostly data was collected for marketing purposes. There is no such clear definition of what big data is - gigabyte, terabyte, petabyte. Unable to draw a line. For some, big data is tens of gigabytes, for others - petabytes.
It so happened that over time a lot of data has accumulated around the world. And in order to conduct some kind of more or less significant analytics of these data, the usual repositories that have been developed since the 70s of the last century turned out to be insufficient. When the shaft of information began in the 2000s, the 10s, and when there were a lot of devices that had access to the Internet, when the Internet of things appeared, these storages could not cope with the concept. At the heart of these repositories lay the relational theory. That is, there were relays of different forms that interacted with each other. There was a description system for how to build and design storage facilities.
When old technologies fail, new ones appear. In the modern problem of analytics big data is solved in two ways:
Creating your own framework that allows you to process large amounts of information. This is usually a distributed application from many hundreds of thousands of servers - like Google, Yandex, which have created their own distributed databases, allowing you to work with such a volume of information.
The development of technology Hadoop - a framework for distributed computing, a distributed file system that can store and process a very large amount of information. Data Science tools are mostly compatible with Hadoop and this compatibility opens up many possibilities for advanced data analysis. Many companies, including us, are moving toward the open source Hadoop ecosystem.
The central Hadoop cluster is located in Nizhny Novgorod. Information is accumulated there from practically all regions of the country. By volume, it can now load about 8.5 petabytes of data. Also in Moscow we have separate RND clusters where we conduct experiments.
Since we have about a thousand servers in different regions, where we conduct analytics, and we also plan to expand, this raises the question of choosing the right equipment for distributed analytical systems. You can buy equipment that is sufficient for data storage, but which will be unsuitable for analytics - simply because there are not enough resources, the number of CPU cores and free RAM on the nodes. It is important to find a balance in order to get good opportunities for analytics and not very high cost of equipment.
Intel has offered us different options for how to optimize work with a distributed system so that analytics on our data volume can be obtained for reasonable money. Intel develops NAND SSD solid state drive technology. It is hundreds of times faster than regular HDD. What is good for us: SSD, especially with the NVMe interface, provides fairly quick access to data.
Plus, Intel has released the Intel Optane SSD server solid-state drives based on a new type of non-volatile Intel 3D XPoint memory. They cope with intensive mixed loads on the storage system, and have a greater resource than conventional NAND SSD. What is good for us: Intel Optane SSD allows you to work stably under high loads with low latency. We initially considered the NAND SSD as a replacement for traditional hard drives, because we have a very large amount of data moving between the hard drive and RAM - and we had to optimize these processes.
We conducted the first test in 2016. We just took and tried to replace the HDD with a fast NAND SSD. To do this, we ordered samples of the new drive Intel - at that time it was a DC P3700. And they drove the standard Hadoop test - an ecosystem that allows you to evaluate how performance changes in different conditions. These are the standardized tests TeraGen, TeraSort, TeraValidate.

TeraGen allows you to “accumulate” artificial data of a certain amount. For example, we took 1 GB and 1 TB. With TeraSort, we sorted this amount of data into Hadoop. This is a fairly resource-intensive operation. And the last test - TeraValidate - allows you to make sure that the data is sorted in the right order. That is, we go through them a second time.

As an experiment, we took only SSD typewriters - that is, Hadoop was installed only on SSDs without using hard drives. In the second version of the SSD, we used to store temporary files, HDD - to store basic data. And in the third version hard drives were used for this and for the other.
The results of these experiments we were not very pleased, because the difference in performance indicators did not exceed 10-20%. That is, we realized that Hadoop is not very friendly with SSD in terms of storage, because initially the system was created for storing large data on the HDD, and no one optimized it for fast and expensive SSDs. And since the cost of the SSD at that time was quite high, we decided not to go into this story for the time being and do hard drives.
Then Intel got new Intel Optane SSD server based on 3D XPoint memory. They came out at the end of 2017, but the samples were available to us earlier. XPoint 3D memory features allow you to use the Intel Optane SSD as an extension of RAM in servers. Since we already realized that solving the performance problem of IO Hadoop at the level of block storage devices will not be easy, we decided to try a new version - expanding the RAM using Intel Memory Drive Technology (IMDT). And at the beginning of this year, we were one of the first in the world to test it.
Than this is good for us: it is cheaper than RAM, which allows you to collect servers that have terabytes of RAM. And since the RAM works fairly quickly - you can load large data sets into it and analyze them. I recall that a feature of our analytical process is that we refer to the data several times. In order for some analysis to be done, we need to load as much data as possible into memory and “scroll” several times some analytics of this data.
The English laboratory of Intel in Swindon provided us with a cluster of three servers, which we compared during the tests with our test cluster located at MTS.

As can be seen from the graph, according to the results of the test, we obtained fairly good results.
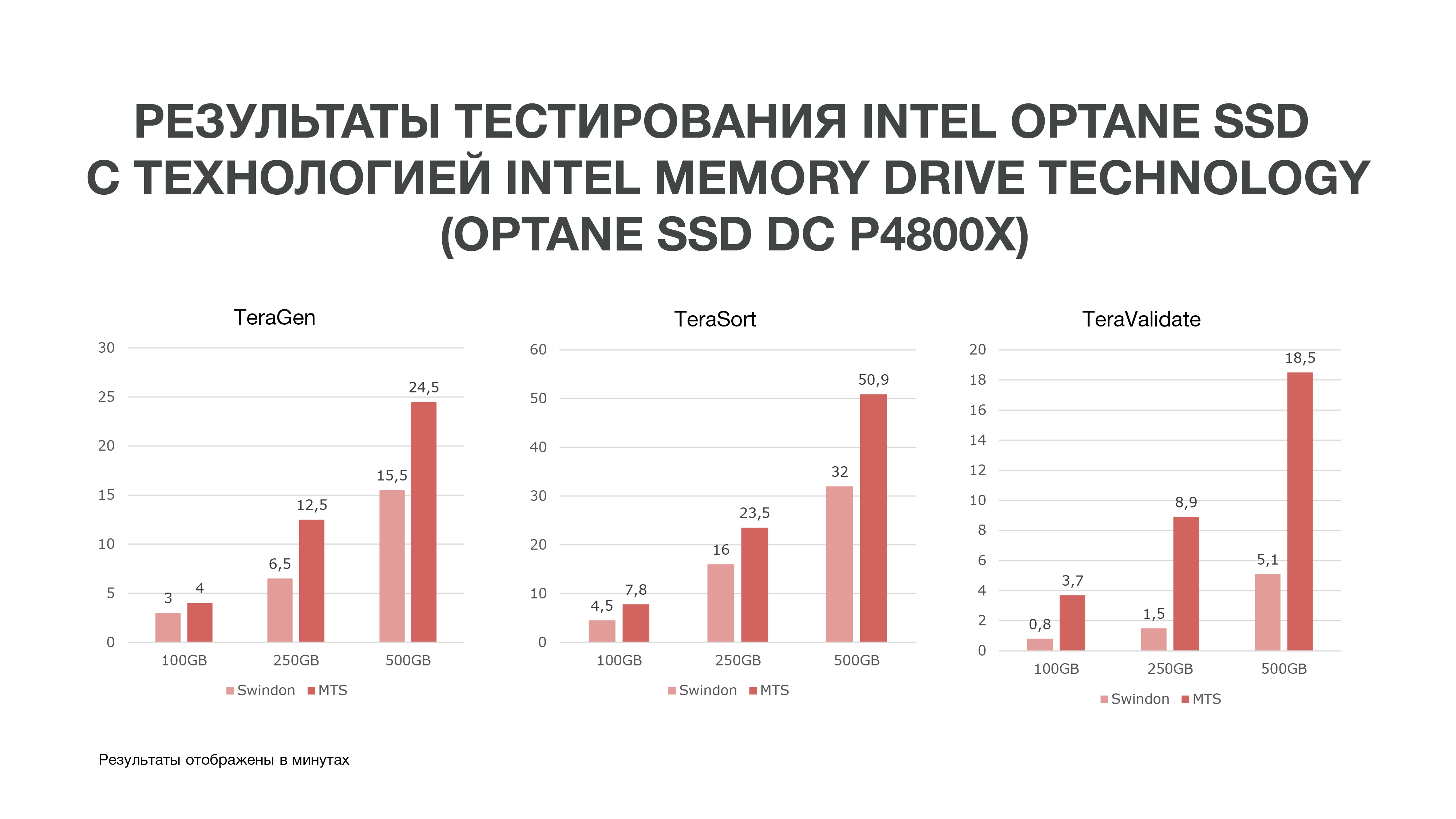
The same TeraGen showed almost twice the performance increase, TeraValidate - by 75%. This is very good for us, because, as I said, we refer several times to the data that we have in our memory. Accordingly, if we get such a performance boost, this will help us particularly well in analyzing data, especially in real-time.
We conducted three tests under different conditions. 100 GB, 250 GB and 500 GB. And the more memory we used, the Intel Optane SSD with Intel Memory Drive Technology performed better. That is, the more data we analyze, the more we get efficiency. Analytics, which took place on a larger number of nodes, can be carried out on a smaller number of them. And we get quite a large amount of memory on our machines, which is very good for Data Science tasks. Based on the test results, we decided to purchase these drives for operation at MTS.
If you also had to choose and test iron for storing and processing large amounts of data, it will be interesting for us to read what difficulties you encountered and what results you came to: write in the comments.
The authors:
Head of the Competence Center for Applied Architecture of the Big Data Department of the MTS Gregory Koval grigory_koval
Dmitry Shostko, Head of Big Data MTS Department of Data Management, zloi_diman
The creation of the Big Data Center at MTS was thought of in 2014: there was a need to scale the classical analytical repository and BI reporting over it. At that time, the data processing engine and BI were SASovskie - it happened historically. And although the business needs for storage were closed, over time, the functionality of BI and ad hoc analytics on top of the analytical repository grew so much that it was necessary to solve the issue of increasing productivity, given that over the years the number of users increased tenfold and continued to grow.
As a result of the competition, the Teradata MPP system appeared in the MTS, covering the needs of the telecom at that time. This was the impetus for trying something more popular and open source.
In the photo - the Big Data MTS team in the new Descartes office in Moscow
The first cluster was from 7 nodes. This was enough to test several business hypotheses and tamper with the first cones. The efforts were not in vain: Big Data in the MTS has existed for three years now and data analysis is involved in almost all functional areas. The team grew from three people to two hundred.
We wanted to have easy development processes, quickly test hypotheses. To do this, you need three things: a team with start-up thinking, lightweight development processes and a developed infrastructure. There are a lot of places where you can read and listen about the first and second, but you should tell about developed infrastructure separately, as legacy and data sources that are in telecom are important here. The developed data infrastructure is not only the construction of the data lake, a detailed data layer and a storefront layer. It is also tools and data access interfaces, isolation of computing resources for products and teams, data delivery mechanisms to consumers - both in real-time and in batch mode. And many many others.
All this work has been singled out for us in a separate area, which is engaged in the development of utilities and tools for working with data. This direction is called the IT Big Data platform.
Where does Big Data come from in MTS
There are a lot of data sources in MTS. One of the main ones is base stations, we serve the subscriber base of more than 78 million subscribers in Russia. We also have many services and services that do not belong to a telecom and allow you to receive more versatile data (e-commerce, system integration, Internet of things, cloud services, etc. - all of “non-telecom” brings about 20% of the total revenue).
Briefly, our architecture can be represented as such a graph:
As can be seen in the graph, Data Sources can give out information in real time. We use the stream layer - we can process information in real-time, extract some events from it that we are interested in, and build analytics on this. In order to provide such event processing, we have developed a fairly standard implementation (from an architectural point of view) using Apache Kafka, Apache Spark and Scala code. Information obtained as a result of this analysis can be consumed both inside the MTS and in the future outside: the fact that certain actions of subscribers are often interesting is for businesses.
There is also a mode of loading data in batches - batch layer. Usually the download occurs once an hour on a schedule, as a scheduler, we use Apache Airflow, and the batch download processes themselves are implemented in python. In this case, Data Lake loads much more data needed to fill Big Data with historical data, which our Data Science models should be trained on. As a result, a subscriber profile is formed in a historical context based on data about its network activity. This allows you to get predictive statistics and build models of human behavior, even to create his psychological portrait - we have such a separate product. This information is very useful, for example, for marketing companies.
We also have a large amount of data that make up the classic repository. That is, we aggregate information on various events - both user and network. All this anonymized data also helps to more accurately predict the interests of users and events important to the company — for example, to predict possible equipment failures and to troubleshoot problems on time.
Hadoop
If you look back in time and remember how big data appeared at all, then it should be noted that mostly data was collected for marketing purposes. There is no such clear definition of what big data is - gigabyte, terabyte, petabyte. Unable to draw a line. For some, big data is tens of gigabytes, for others - petabytes.
It so happened that over time a lot of data has accumulated around the world. And in order to conduct some kind of more or less significant analytics of these data, the usual repositories that have been developed since the 70s of the last century turned out to be insufficient. When the shaft of information began in the 2000s, the 10s, and when there were a lot of devices that had access to the Internet, when the Internet of things appeared, these storages could not cope with the concept. At the heart of these repositories lay the relational theory. That is, there were relays of different forms that interacted with each other. There was a description system for how to build and design storage facilities.
When old technologies fail, new ones appear. In the modern problem of analytics big data is solved in two ways:
Creating your own framework that allows you to process large amounts of information. This is usually a distributed application from many hundreds of thousands of servers - like Google, Yandex, which have created their own distributed databases, allowing you to work with such a volume of information.
The development of technology Hadoop - a framework for distributed computing, a distributed file system that can store and process a very large amount of information. Data Science tools are mostly compatible with Hadoop and this compatibility opens up many possibilities for advanced data analysis. Many companies, including us, are moving toward the open source Hadoop ecosystem.
The central Hadoop cluster is located in Nizhny Novgorod. Information is accumulated there from practically all regions of the country. By volume, it can now load about 8.5 petabytes of data. Also in Moscow we have separate RND clusters where we conduct experiments.
Since we have about a thousand servers in different regions, where we conduct analytics, and we also plan to expand, this raises the question of choosing the right equipment for distributed analytical systems. You can buy equipment that is sufficient for data storage, but which will be unsuitable for analytics - simply because there are not enough resources, the number of CPU cores and free RAM on the nodes. It is important to find a balance in order to get good opportunities for analytics and not very high cost of equipment.
Intel has offered us different options for how to optimize work with a distributed system so that analytics on our data volume can be obtained for reasonable money. Intel develops NAND SSD solid state drive technology. It is hundreds of times faster than regular HDD. What is good for us: SSD, especially with the NVMe interface, provides fairly quick access to data.
Plus, Intel has released the Intel Optane SSD server solid-state drives based on a new type of non-volatile Intel 3D XPoint memory. They cope with intensive mixed loads on the storage system, and have a greater resource than conventional NAND SSD. What is good for us: Intel Optane SSD allows you to work stably under high loads with low latency. We initially considered the NAND SSD as a replacement for traditional hard drives, because we have a very large amount of data moving between the hard drive and RAM - and we had to optimize these processes.
First test
We conducted the first test in 2016. We just took and tried to replace the HDD with a fast NAND SSD. To do this, we ordered samples of the new drive Intel - at that time it was a DC P3700. And they drove the standard Hadoop test - an ecosystem that allows you to evaluate how performance changes in different conditions. These are the standardized tests TeraGen, TeraSort, TeraValidate.
TeraGen allows you to “accumulate” artificial data of a certain amount. For example, we took 1 GB and 1 TB. With TeraSort, we sorted this amount of data into Hadoop. This is a fairly resource-intensive operation. And the last test - TeraValidate - allows you to make sure that the data is sorted in the right order. That is, we go through them a second time.
As an experiment, we took only SSD typewriters - that is, Hadoop was installed only on SSDs without using hard drives. In the second version of the SSD, we used to store temporary files, HDD - to store basic data. And in the third version hard drives were used for this and for the other.
The results of these experiments we were not very pleased, because the difference in performance indicators did not exceed 10-20%. That is, we realized that Hadoop is not very friendly with SSD in terms of storage, because initially the system was created for storing large data on the HDD, and no one optimized it for fast and expensive SSDs. And since the cost of the SSD at that time was quite high, we decided not to go into this story for the time being and do hard drives.
Second test
Then Intel got new Intel Optane SSD server based on 3D XPoint memory. They came out at the end of 2017, but the samples were available to us earlier. XPoint 3D memory features allow you to use the Intel Optane SSD as an extension of RAM in servers. Since we already realized that solving the performance problem of IO Hadoop at the level of block storage devices will not be easy, we decided to try a new version - expanding the RAM using Intel Memory Drive Technology (IMDT). And at the beginning of this year, we were one of the first in the world to test it.
Than this is good for us: it is cheaper than RAM, which allows you to collect servers that have terabytes of RAM. And since the RAM works fairly quickly - you can load large data sets into it and analyze them. I recall that a feature of our analytical process is that we refer to the data several times. In order for some analysis to be done, we need to load as much data as possible into memory and “scroll” several times some analytics of this data.
The English laboratory of Intel in Swindon provided us with a cluster of three servers, which we compared during the tests with our test cluster located at MTS.
As can be seen from the graph, according to the results of the test, we obtained fairly good results.
The same TeraGen showed almost twice the performance increase, TeraValidate - by 75%. This is very good for us, because, as I said, we refer several times to the data that we have in our memory. Accordingly, if we get such a performance boost, this will help us particularly well in analyzing data, especially in real-time.
We conducted three tests under different conditions. 100 GB, 250 GB and 500 GB. And the more memory we used, the Intel Optane SSD with Intel Memory Drive Technology performed better. That is, the more data we analyze, the more we get efficiency. Analytics, which took place on a larger number of nodes, can be carried out on a smaller number of them. And we get quite a large amount of memory on our machines, which is very good for Data Science tasks. Based on the test results, we decided to purchase these drives for operation at MTS.
If you also had to choose and test iron for storing and processing large amounts of data, it will be interesting for us to read what difficulties you encountered and what results you came to: write in the comments.
The authors:
Head of the Competence Center for Applied Architecture of the Big Data Department of the MTS Gregory Koval grigory_koval
Dmitry Shostko, Head of Big Data MTS Department of Data Management, zloi_diman
Source: https://habr.com/ru/post/439498/