Configure the Kubernetes HA cluster on bare metal with kubeadm. Part 1/3
Hello! In this article, I want to streamline the information and share the experience of creating and using the Kubernetes internal cluster.
Over the past few years, this container orchestration technology has taken a big step forward and has become a kind of corporate standard for thousands of companies. Some use it in production, others just test it on projects, but the passions around it, whatever one may say, are burning serious ones. If you have never used it yet, it's time to start dating.
0. Introduction
Kubernetes is a scalable orchestration technology that can begin with installation on a single node and reach the size of huge HA clusters based on several hundred nodes inside. Most of the popular cloud providers represent different types of Kubernetes implementation - take it and use it. But situations are different, and there are companies that do not use clouds, but they want all the benefits of modern orchestration technologies. And here the Kubernetes installation comes out on the “bare iron”.

1. Introduction
In this example, we will create a Kubernetes HA-cluster with a topology for several master nodes (multi masters), with an external cluster etcd as the base layer and the MetalLB load balancer inside. We will deploy GlusterFS as a simple internal distributed cluster storage on all working nodes. We will also try to deploy several test projects in it using our personal Docker registry.
In general, there are several ways to create a Kubernetes ON-cluster: the difficult and in-depth path described in the popular kubernetes-the-hard-way document, or a simpler way, with the help of the kubeadm utility.
Kubeadm is a tool created by the Kubernetes community precisely to simplify the installation of Kubernetes and facilitate the process. Previously, Kubeadm was recommended only to create small test clusters with a single master node, to get started. But over the past year we have improved a lot, and now we can use it to create HA clusters with several master nodes. According to the news from the Kubernetes community, in the future Kubeadm will be recommended as a tool to install Kubernetes.
Documentation on Kubeadm offers two main ways to implement a cluster, with a stack and external etcd-topology. I will choose the second path with external etcd nodes due to the fault tolerance of the HA-cluster.
Here is a diagram from the Kubeadm documentation describing this path:
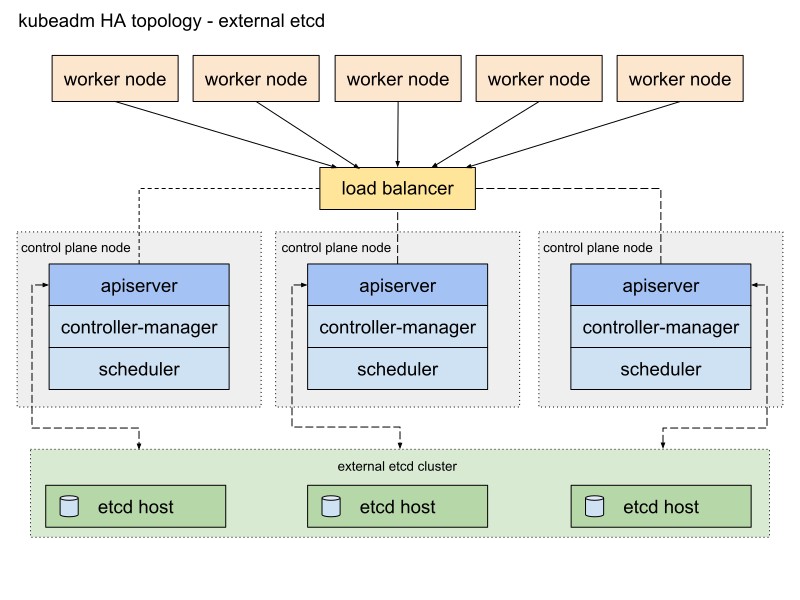
I'll change it a bit. First, I will use a couple of HAProxy servers as load balancers with the Heartbeat package, which will share the virtual IP address. Heartbeat and HAProxy use a small amount of system resources, so I will place them on a pair of etcd nodes to slightly reduce the number of servers for our cluster.
For this Kubernetes cluster scheme, eight nodes will be needed. Three servers for the external cluster etcd (LB services will also use a couple of them), two for the control plane nodes (master nodes) and three for the working nodes. It can be either bare metal or a VM server. In this case, it does not matter. You can easily change the scheme by adding more master nodes and placing HAProxy with Heartbeat on separate nodes if there are a lot of free servers. Although my option for the first implementation of the HA cluster is enough for the eyes.
And if you want to, add a small server with the kubectl utility installed to manage this cluster or use your own Linux desktop.
The scheme for this example would look something like this:
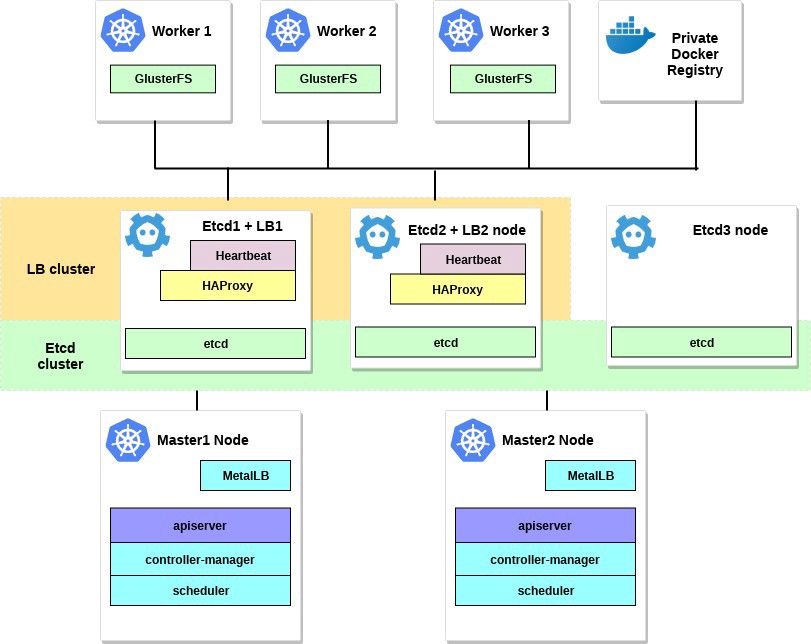
2. Requirements
You will need two master nodes Kubernetes with the minimum recommended system requirements: 2 CPUs and 2 GB of RAM in accordance with the documentation kubeadm . For working nodes, I recommend using more powerful servers, since we will run all our application services on them. And for Etcd + LB, we can also take servers with two CPUs and at least 2 GB of RAM.
Choose a public network or private network for this cluster; IP addresses do not matter; It is important that all servers are accessible to each other and, of course, for you. Later in the Kubernetes cluster, we will configure the overlay network.
The minimum requirements for this example are:
- 2 servers with 2 processors and 2 GB of RAM for master nodes
- 3 servers with 4 processors and 4-8 GB of RAM for working nodes
- 3 servers with 2 processors and 2 GB of RAM for Etcd and HAProxy
- 192.168.0.0/24 - subnet.
192.168.0.1 - virtual IP address HAProxy, 192.168.0.2 - 4 main IP addresses of the Etcd and HAProxy nodes, 192.168.0.5 - 6 main IP addresses of the Kubernetes master node, 192.168.0.7 - 9 main IP addresses of the working Kubernetes nodes .
Debian 9 is installed on all servers.
Also remember that system requirements depend on how large and powerful the cluster is. For more information, see the Kubernetes documentation.
3. Configure HAProxy and Heartbeat.
We have more than one Kubernetes master node, and therefore it is necessary to configure the HAProxy load balancer in front of them - to distribute traffic. This will be a pair of HAProxy servers with one common virtual IP address. Fault tolerance is provided by the Heartbeat package. For deployment, we will use the first two etcd servers.
Install and configure HAProxy with Heartbeat on the first and second etcd servers (192.168.0.2–3 in this example):
etcd1# apt-get update && apt-get upgrade && apt-get install -y haproxy etcd2# apt-get update && apt-get upgrade && apt-get install -y haproxy Save the original configuration and create a new one:
etcd1# mv /etc/haproxy/haproxy.cfg{,.back} etcd1# vi /etc/haproxy/haproxy.cfg etcd2# mv /etc/haproxy/haproxy.cfg{,.back} etcd2# vi /etc/haproxy/haproxy.cfg Add these configuration parameters for both HAProxy:
global user haproxy group haproxy defaults mode http log global retries 2 timeout connect 3000ms timeout server 5000ms timeout client 5000ms frontend kubernetes bind 192.168.0.1:6443 option tcplog mode tcp default_backend kubernetes-master-nodes backend kubernetes-master-nodes mode tcp balance roundrobin option tcp-check server k8s-master-0 192.168.0.5:6443 check fall 3 rise 2 server k8s-master-1 192.168.0.6:6443 check fall 3 rise 2 As you can see, both HAProxy services share the IP address - 192.168.0.1. This virtual IP address will move between the servers, so let's tick off a bit and enable the net.ipv4.ip_nonlocal_bind parameter to allow the binding of system services to a non-local IP address.
Add this feature to the /etc/sysctl.conf file:
etcd1# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1 etcd2# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1 Run on both servers:
sysctl -p Also run HAProxy on both servers:
etcd1# systemctl start haproxy etcd2# systemctl start haproxy Make sure that HAProxy is running and listening on the virtual IP address on both servers:
etcd1# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy etcd2# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy Good! Now install Heartbeat and configure this virtual IP.
etcd1# apt-get -y install heartbeat && systemctl enable heartbeat etcd2# apt-get -y install heartbeat && systemctl enable heartbeat It's time to create several configuration files for it: for the first and second servers they will be basically the same.
First create the file /etc/ha.d/authkeys , in this file the Heartbeat stores the data for mutual authentication. The file must be the same on both servers:
# echo -n securepass | md5sum bb77d0d3b3f239fa5db73bdf27b8d29a etcd1# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a etcd2# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a This file must be accessible only by the root:
etcd1# chmod 600 /etc/ha.d/authkeys etcd2# chmod 600 /etc/ha.d/authkeys Now we will create the main configuration file for Heartbeat on both servers: for each server it will be slightly different.
Create /etc/ha.d/ha.cf :
etcd1
etcd1# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.3 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to log/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname etcd2
etcd2# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.2 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to vlog/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname The “nodes” parameters for this configuration will be obtained by running uname -n on both Etcd servers. Also use the name of your network card instead of ens18.
Finally, you need to create the /etc/ha.d/haresources file on these servers. For both servers, the file must be the same. In this file we set our common IP-address and determine which node is the main default:
etcd1# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1 etcd2# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1 When everything is ready, we start Heartbeat services on both servers and check that we have received this declared virtual IP on the etcd1 node :
etcd1# systemctl restart heartbeat etcd2# systemctl restart heartbeat etcd1# ip a ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff inet 192.168.0.2/24 brd 192.168.0.255 scope global ens18 valid_lft forever preferred_lft forever inet 192.168.0.1/24 brd 192.168.0.255 scope global secondary You can check that HAProxy is working fine by running nc at 192.168.0.1 6443. You must have timed out, because the Kubernetes API is not yet listening on the server side. But this means that HAProxy and Heartbeat are configured correctly.
# nc -v 192.168.0.1 6443 Connection to 93.158.95.90 6443 port [tcp/*] succeeded! 4. Preparing Nodes for Kubernetes
The next step is to prepare all the Kubernetes nodes. You need to install Docker with some additional packages, add the Kubernetes repository and install the kubelet , kubeadm , kubectl packages from it. This setting is the same for all Kubernetes nodes (master, work, etc.)
The main advantage of Kubeadm is that no additional software is needed. Install kubeadm on all hosts - and use; at least generate CA certificates.
Installing Docker on all nodes:
Update the apt package index # apt-get update Install packages to allow apt to use a repository over HTTPS # apt-get -y install \ apt-transport-https \ ca-certificates \ curl \ gnupg2 \ software-properties-common Add Docker's official GPG key # curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - Add docker apt repository # apt-add-repository \ "deb [arch=amd64] https://download.docker.com/linux/debian \ $(lsb_release -cs) \ stable" Install docker-ce. # apt-get update && apt-get -y install docker-ce Check docker version # docker -v Docker version 18.09.0, build 4d60db4 After that, install Kubernetes packages on all nodes:
kubeadm: command to load the cluster.kubelet: a component that runs on all computers in a cluster and performs actions such as launching podov and containers.kubectl: util command line to communicate with the cluster.- kubectl - optional; I often install it on all nodes to run some Kubernetes commands for debugging.
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository # cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install packages # apt-get update && apt-get install -y kubelet kubeadm kubectl Hold back packages # apt-mark hold kubelet kubeadm kubectl Check kubeadm version # kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9dsfdfgdfgfgdfgdfgdf365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T10:36:44Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"linux/amd64"} Installing kubeadm and other packages, do not forget to disable swap.
# swapoff -a # sed -i '/ swap / s/^/#/' /etc/fstab Repeat the installation on the remaining nodes. Software packages are the same for all nodes of the cluster, and only the following configuration will determine the roles that they will receive later.
5. Configure the HA Etcd cluster
So, after completing the preparations, we configure the Kubernetes cluster. The first brick will be the HA Etcd cluster, which is also configured using the kubeadm tool.
Before we begin, make sure that all etcd nodes communicate through ports 2379 and 2380. In addition, you need to configure ssh access between them - to use scp .
Let's start with the first etcd nodes, and then simply copy all the necessary certificates and configuration files to other servers.
On all etcd nodes you need to add a new systemd configuration file for a kubelet unit with a higher priority:
etcd-nodes# cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf [Service] ExecStart= ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true Restart=always EOF etcd-nodes# systemctl daemon-reload etcd-nodes# systemctl restart kubelet Then we will go over ssh to the first etcd node - we will use it to generate all the necessary kubeadm configurations for each etcd node, and then copy them.
# Export all our etcd nodes IP's as variables etcd1# export HOST0=192.168.0.2 etcd1# export HOST1=192.168.0.3 etcd1# export HOST2=192.168.0.4 # Create temp directories to store files for all nodes etcd1# mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/ etcd1# ETCDHOSTS=(${HOST0} ${HOST1} ${HOST2}) etcd1# NAMES=("infra0" "infra1" "infra2") etcd1# for i in "${!ETCDHOSTS[@]}"; do HOST=${ETCDHOSTS[$i]} NAME=${NAMES[$i]} cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml apiVersion: "kubeadm.k8s.io/v1beta1" kind: ClusterConfiguration etcd: local: serverCertSANs: - "${HOST}" peerCertSANs: - "${HOST}" extraArgs: initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380 initial-cluster-state: new name: ${NAME} listen-peer-urls: https://${HOST}:2380 listen-client-urls: https://${HOST}:2379 advertise-client-urls: https://${HOST}:2379 initial-advertise-peer-urls: https://${HOST}:2380 EOF done Now create the main certification authority using kubeadm
etcd1# kubeadm init phase certs etcd-ca This command will create two ca.crt & ca.key files in the / etc / kubernetes / pki / etcd / directory.
etcd1# ls /etc/kubernetes/pki/etcd/ ca.crt ca.key Now we will generate certificates for all etcd nodes:
### Create certificates for the etcd3 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST2}/ ### cleanup non-reusable certificates etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the etcd2 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST1}/ ### cleanup non-reusable certificates again etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the this local node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1 #kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml # No need to move the certs because they are for this node # clean up certs that should not be copied off this host etcd1# find /tmp/${HOST2} -name ca.key -type f -delete etcd1# find /tmp/${HOST1} -name ca.key -type f -delete Then copy the kubeadm certificates and configurations to the etcd2 and etcd3 nodes .
First generate a pair of ssh keys on etcd1 and add the open part to the nodes etcd2 and 3 . In this example, all commands are executed on behalf of a user who owns all rights in the system.
etcd1# scp -r /tmp/${HOST1}/* ${HOST1}: etcd1# scp -r /tmp/${HOST2}/* ${HOST2}: ### login to the etcd2 or run this command remotely by ssh etcd2# cd /root etcd2# mv pki /etc/kubernetes/ ### login to the etcd3 or run this command remotely by ssh etcd3# cd /root etcd3# mv pki /etc/kubernetes/ Before starting the etcd cluster, make sure that files exist on all nodes:
List of required files on etcd1 :
/tmp/192.168.0.2 └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── ca.key ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key For the etcd2 node , this is:
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key And the last etcd3 node:
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key When all the certificates and configurations are in place, we create manifests. On each node, execute the kubeadm command to generate a static manifest for the etcd cluster:
etcd1# kubeadm init phase etcd local --config=/tmp/192.168.0.2/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml Now cluster etcd - in theory - configured and in good condition. Verify by running the following command on the etcd1 node :
etcd1# docker run --rm -it \ --net host \ -v /etc/kubernetes:/etc/kubernetes quay.io/coreos/etcd:v3.2.24 etcdctl \ --cert-file /etc/kubernetes/pki/etcd/peer.crt \ --key-file /etc/kubernetes/pki/etcd/peer.key \ --ca-file /etc/kubernetes/pki/etcd/ca.crt \ --endpoints https://192.168.0.2:2379 cluster-health ### status output member 37245675bd09ddf3 is healthy: got healthy result from https://192.168.0.3:2379 member 532d748291f0be51 is healthy: got healthy result from https://192.168.0.4:2379 member 59c53f494c20e8eb is healthy: got healthy result from https://192.168.0.2:2379 cluster is healthy The etcd cluster is up, so move on.
6. Setting up master and working nodes
Configure the master nodes of our cluster - copy these files from the first etcd node to the first master node:
etcd1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.key 192.168.0.5: Then, go through ssh to master1 master1 and create a file kubeadm-config.yaml with the following content:
master1# cd /root && vi kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable apiServer: certSANs: - "192.168.0.1" controlPlaneEndpoint: "192.168.0.1:6443" etcd: external: endpoints: - https://192.168.0.2:2379 - https://192.168.0.3:2379 - https://192.168.0.4:2379 caFile: /etc/kubernetes/pki/etcd/ca.crt certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key Move the previously copied certificates and key to the appropriate directory on the master1 node , as in the configuration description.
master1# mkdir -p /etc/kubernetes/pki/etcd/ master1# cp /root/ca.crt /etc/kubernetes/pki/etcd/ master1# cp /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ master1# cp /root/apiserver-etcd-client.key /etc/kubernetes/pki/ To create the first master node, run:
master1# kubeadm init --config kubeadm-config.yaml If all the previous steps are done correctly, you will see the following:
You can now join any number of machines by running the following on each node as root: kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 Copy this kubeadm initialization output to any text file, we will use this token in the future when we attach the second master and working node to our cluster.
I have already said that the Kubernetes cluster will use some kind of overlay network for pods and other services, so at this stage you need to install some CNI plugin. I recommend the Weave CNI plugin. Experience has shown that it is more useful and less problematic - but you can choose another, for example, Calico.
Installing the Weave network plugin on the first master node:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" The connection to the server localhost:8080 was refused - did you specify the right host or port? serviceaccount/weave-net created clusterrole.rbac.authorization.k8s.io/weave-net created clusterrolebinding.rbac.authorization.k8s.io/weave-net created role.rbac.authorization.k8s.io/weave-net created rolebinding.rbac.authorization.k8s.io/weave-net created daemonset.extensions/weave-net created Wait a while, and then enter the following command to check the launch of the component sweeps:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 6m25s coredns-86c58d9df4-xj98p 1/1 Running 0 6m25s kube-apiserver-master1 1/1 Running 0 5m22s kube-controller-manager-master1 1/1 Running 0 5m41s kube-proxy-8ncqw 1/1 Running 0 6m25s kube-scheduler-master1 1/1 Running 0 5m25s weave-net-lvwrp 2/2 Running 0 78s - It is recommended to attach new nodes to the control plane only after the initialization of the first node.
To check the status of the cluster, run:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 11m v1.13.1 Perfectly! The first master node rose. Now it is ready, and we will finish creating the Kubernetes cluster - we will add the second master node and the working nodes.
To add a second master node, create an ssh key on the master1 node and add the public part to the master2 node. Perform a test login, and then copy some files from the first master node to the second:
master1# scp /etc/kubernetes/pki/ca.crt 192.168.0.6: master1# scp /etc/kubernetes/pki/ca.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.pub 192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.key @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.key @192.168.0.6: master1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.6:etcd-ca.crt master1# scp /etc/kubernetes/admin.conf 192.168.0.6: ### Check that files was copied well master2# ls /root admin.conf ca.crt ca.key etcd-ca.crt front-proxy-ca.crt front-proxy-ca.key sa.key sa.pub On the second master node, move the previously copied certificates and keys to the appropriate directories:
master2# mkdir -p /etc/kubernetes/pki/etcd mv /root/ca.crt /etc/kubernetes/pki/ mv /root/ca.key /etc/kubernetes/pki/ mv /root/sa.pub /etc/kubernetes/pki/ mv /root/sa.key /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.key /etc/kubernetes/pki/ mv /root/front-proxy-ca.crt /etc/kubernetes/pki/ mv /root/front-proxy-ca.key /etc/kubernetes/pki/ mv /root/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt mv /root/admin.conf /etc/kubernetes/admin.conf Let's join the second master node to the cluster. To do this, we need the output of the connection command, which was previously transmitted to us by kubeadm init at the first node.
Launch master2 master2 :
master2# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 --experimental-control-plane - It is necessary to add a flag -
--experimental-control-plane. It automates the joining of master node data to a cluster. Without this flag, the usual working node will simply be added.
Wait a bit until the node joins the cluster, and check the new cluster status:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 32m v1.13.1 master2 Ready master 46s v1.13.1 Also make sure that all the scams from all master nodes are running normally:
master1# kubectl — kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 46m coredns-86c58d9df4-xj98p 1/1 Running 0 46m kube-apiserver-master1 1/1 Running 0 45m kube-apiserver-master2 1/1 Running 0 15m kube-controller-manager-master1 1/1 Running 0 45m kube-controller-manager-master2 1/1 Running 0 15m kube-proxy-8ncqw 1/1 Running 0 46m kube-proxy-px5dt 1/1 Running 0 15m kube-scheduler-master1 1/1 Running 0 45m kube-scheduler-master2 1/1 Running 0 15m weave-net-ksvxz 2/2 Running 1 15m weave-net-lvwrp 2/2 Running 0 41m Wonderful! We have almost finished the configuration of the Kubernetes cluster. And the last thing to do is add the three work nodes that we prepared earlier.
Enter the work nodes and execute the kubeadm join command without the - --experimental-control-plane .
worker1-3# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 Check the cluster status again:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 1h30m v1.13.1 master2 Ready master 1h59m v1.13.1 worker1 Ready <none> 1h8m v1.13.1 worker2 Ready <none> 1h8m v1.13.1 worker3 Ready <none> 1h7m v1.13.1 As you can see, we have a fully configured Kubernetes HA cluster with two master and three working nodes. It is built on the basis of a HA etcd cluster with a fail-safe load balancer in front of master nodes. Sounds good to me.
7. Configuring Remote Cluster Management
Another action that remains to be considered in this - the first - part of the article is setting up the remote utility kubectl to manage the cluster. Previously, we ran all commands from master1 master1 nodes, but this is only suitable for the first time - when setting up a cluster. It would be nice to configure the external control node. To do this, you can use a laptop or another server.
Log on to this server and run:
Add the Google repository key control# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository control# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install kubectl control# apt-get update && apt-get install -y kubectl In your user home dir create control# mkdir ~/.kube Take the Kubernetes admin.conf from the master1 node control# scp 192.168.0.5:/etc/kubernetes/admin.conf ~/.kube/config Check that we can send commands to our cluster control# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 6h58m v1.13.1 master2 Ready master 6h27m v1.13.1 worker1 Ready <none> 5h36m v1.13.1 worker2 Ready <none> 5h36m v1.13.1 worker3 Ready <none> 5h36m v1.13.1 Ok, now let's run the test sub in our cluster and check how it works.
control# kubectl create deployment nginx --image=nginx deployment.apps/nginx created control# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-5c7588df-6pvgr 1/1 Running 0 52s Congratulations! You just hit Kubernetes. And that means your new HA cluster is ready. In fact, the process of setting up a Kubernetes cluster using kubeadm is quite simple and fast.
In the next part of the article, we will add internal storage by configuring GlusterFS on all working nodes, configure the internal load balancer for our Kubernetes cluster, and also run certain stress tests, disable some nodes, and check the cluster for stability.
Afterword
Yes, working on this example, you will encounter a number of problems. No need to worry: to undo the changes and return the nodes to their original state, simply run kubeadm reset — the changes that kubeadm made earlier will be reset, and you can re-configure. Also, do not forget to check the status of the Docker containers on the nodes of the cluster - make sure that all of them start and run without errors. For more information about damaged containers, use the docker logs containerid command .
That's all for today. Good luck!
Source: https://habr.com/ru/post/439562/