Spring Boot 2: what is not written in release notes

When a large-scale project has a large-scale update, everything is never simple: inevitably, there are unobvious nuances (in other words, a rake). And then, no matter how good the documentation is, only experience, either yours or someone else’s, will help with something.
At the 2018 Joker conference, I explained what problems I faced myself during the transition to Spring Boot 2 and how they are solved. And now, especially for Habr, the text version of this report. For convenience, there is a video and a table of contents in the post: you can not read the whole thing, but go directly to the problem that concerns you.
Table of contents
- Videotape
- Introduction
- Rake compile time
Examples of problems
How to be - Content-Type. Determining the type of HTTP response
Problem
How to be - Scheduling Scheduled run
Problem
How to be - Spring Cloud & Co. Library compatibility
Problem
Bonus: difficulty
How to be - Relax Binding. Fuzzy parameter binding
Problem
How to be - Unit Testing. Running tests in Mockito 2
Problem
How to be - Gradle Plugin. Building Spring Boot Projects
Problem
How to be - Other
- Conclusion Summary and conclusions
Good afternoon! I want to tell you about some features (let's call them a rake) that you may encounter when upgrading the Spring Boot framework to the second version and during its subsequent operation.
My name is Vladimir Plizgá ( GitHub ), I work for CFT, one of the largest and oldest software developers in Russia. For the past few years, I have been engaged in backend development there, being responsible for the technical development of online banking of prepaid cards. It was on this project that I became the initiator and performer of the transition from monolithic to microservice architecture (which still lasts). Well, since most of the knowledge that I decided to share with you has been accumulated on the example of this particular project, I will tell about it a little more in detail.
Briefly about the experimental product
This is an Internet bank that alone serves about more than two dozen partner companies across Russia: it provides end customers with the opportunity to manage their funds using remote banking services (mobile applications, websites). One of the partners is Beeline and its payment card. The Internet Bank turned out to be quite good for it, judging by the Markswebb Mobile Banking Rank , where our product took quite a good position for newbies.
The “gut” is still in transition, so we have one monolith, the so-called core, around which 23 microservices are built. Inside the Spring Cloud Netflix microservices, Spring Integration and something else. And on Spring Boot 2, this whole thing has been flying around since July. And just in this place we will stop in more detail. Translating this project to the second version, I came across some features that I want to tell you about.
Report outline

There are quite a few areas where Spring Boot 2 features appeared. We will try to run through all of them. To do this quickly, we need an experienced detective or an investigator - someone who digs all this up as if for us. Since Holmes and Watson have already delivered a report on Joker, another specialist, Lieutenant Colombo, will help us. Forward!
Spring Boot / 2
First, a few words about Spring Boot in general and the second version in particular. First, this version came out, to put it mildly, not yesterday: on March 1, 2018 it was already in General Availability. One of the main goals pursued by developers is full support for Java 8 at the source level. That is, it will not be possible to compile on a smaller version, although runtime is compatible. The Spring Framework of the fifth version, which came out a bit earlier than Spring Boot 2, is taken as the basis. And this is not the only dependency. He also has such a thing as BOM (Bill Of Materials) - this is a huge XML, which lists all the (transitive for us) dependencies on various third-party libraries, additional frameworks, tools, and so on.
Accordingly, not all of the special effects that the second Spring Boot introduces come from it or from the Spring ecosystem. Two excellent documents have been written on this entire farm: the Release Notes and the Migration Guide . The documents are cool, Spring in this sense is generally well done. But, for obvious reasons, it is possible to cover far from everything: there are some particular deviations, etc., that either it is impossible or not worth including there. We will talk about such features.
Compile time. API change examples
Let's start with more or less simple and obvious rakes: those that arise in compile time. That is something that will not let you even compile the project if you simply change the number from Spring Boot in the build script to 1 to 2.
The main source of changes, which became the basis for such edits in Spring Boot, is, of course, Spring's transition to Java 8. In addition, the Spring 5 and Spring Boot 2 web stack was divided, relatively speaking, into two. Now he is servlet, traditional for us, and jet. In addition, it was necessary to take into account a number of shortcomings from previous versions. Other third-party libraries podnakunili (outside Spring). If you look in the Release Notes, then there are no hidden pitfalls on the move and, to be honest, when I first read the Release Notes, it seemed to me that everything is normal there. And it looked to me like this:
But, as you probably guess, everything is not so good.
What will break the compilation (example 1):
- Why : the
WebMvcConfigurerAdapterclassWebMvcConfigurerAdapterno longer; - Why : to support Java 8 chips (default-methods in interfaces);
- What to do : use the
WebMvcConfigurerinterface.
The project may not compile at least due to the fact that some classes simply no longer exist. Why? Yes, because in Java 8 they are not needed. If these were adapters with a primitive implementation of methods, then there is really nothing to be explained, the default methods perfectly solve all this. Using the example of this class, it is clear that it is enough to use the interface itself, and no adapters will be needed anymore.
What will break the compilation (example 2):
- Why :
PropertySourceLoader#loadmethod began to return the list of sources instead of one; - Why : to support multi-document resources, for example, YAML;
- What to do : wrap the response in
singletonList()(when overridden).
An example from a completely different area. Some methods even changed signatures. If you have used the load PropertySourceLoader method, then it now returns the collection. Accordingly, it allowed to support multi-document resources. For example, in YAML after three lines you can specify a bunch of documents in one file. If you now need to work with it from Java, keep in mind that this should be done through the collection.
What will break the compilation (example 3):
- Why : some classes from the
org.springframework.boot.autoconfigure.webpackage haveorg.springframework.boot.autoconfigure.webintoorg.springframework.boot.autoconfigure.webpackages -.servletand.reactive; - Why : to keep the jet stack on par with the traditional one;
- What to do : update imports.
More changes were made by splitting the stacks. For example, what used to be in the same web package has now been spread in two packages with a bunch of classes. These are
.servlet and .reactive . Why done? Because the jet stack was not supposed to be a huge crutch on top of the servlet. It was necessary to do this so that they could maintain their own life cycle, develop in their own directions and not interfere with each other. What to do with it? It is enough to change the imports: most of these classes remain compatible at the API level. Most, but not all.What will break the compilation (example 4):
- Why : the signature of the
ErrorAttributesclass methods hasErrorAttributes: instead ofRequestAttributes,WebRequest(servlet)andServerRequest(reactive); - Why : to keep the jet stack on par with the traditional one;
- What to do : replace the class names in the signatures.
For example, in the ErrorAttributes class, instead of RequestAttributes, the methods now use two other classes: WebRequest and ServerRequest. The reason is the same. And what to do with it? If you are moving from the first to the second Spring Boot, then you need to change RequestAttributes to WebRequest. Well, if you're already on the second, then use ServerRequest. Obviously, isn't it? ..
How to be?
There are quite a few such examples; we will not sort them all out. What to do with it? First of all, it is worth looking at the Spring Boot 2.0 Migration Guide in time to notice the change concerning you. For example, it mentions renaming completely unobvious classes. Still, if something has gone wrong and broken, we should bear in mind that the concept of “web” has been divided into 2: “servlet” and “reactive”. When targeting in all sorts of classes and packages it can help. In addition, we must bear in mind that not only the classes and packages themselves were renamed, but entire dependencies and artifacts. As it happened, for example, with Spring Cloud.
Content-Type. Determining the type of HTTP response
Enough about these simple things from compile time, everything is clear and simple. Let's talk about what can happen during the execution and, accordingly, can shoot, even if Spring Boot 2 has been working for you for a long time. Let's talk about determining the content-type.

It's no secret that Spring can write web applications, both page-based and REST APIs, and they can deliver content with a wide variety of types, be it XML, JSON, or something else. And one of the charms for which Spring is so loved is that you can never bother with the definition of the type given in your code. You can hope for magic. This magic works, relatively speaking, in three different ways: either it relies on the Accept header from the client, or on the extension of the requested file, or on a special parameter in the URL, which, of course, can also be steered.
Consider a simple example ( full source code ). Hereinafter I will use the notation from Gradle, but even if you are a Maven fan, you will not be hard to understand what is written here: we build a tiny application on the first Spring Boot and use only one starter web.
Example (v1.x):
dependencies { ext { springBootVersion = '1.5.14.RELEASE' } compile("org.springframework.boot:spring-boot-starter-web:$springBootVersion") } As an executable code, we have a single class in which the controller method is immediately declared.
@GetMapping(value = "/download/{fileName: .+}", produces = {TEXT_HTML_VALUE, APPLICATION_JSON_VALUE, TEXT_PLAIN_VALUE}) public ResponseEntity<Resource> download(@PathVariable String fileName) { //формируем только тело ответа, без Content-Type } It takes as input a kind of file name that it will supposedly generate and give away. It really forms its content in one of the three specified types (by defining it by the file name), but does not specify the content-type in any way — we have Spring, he will do everything himself.
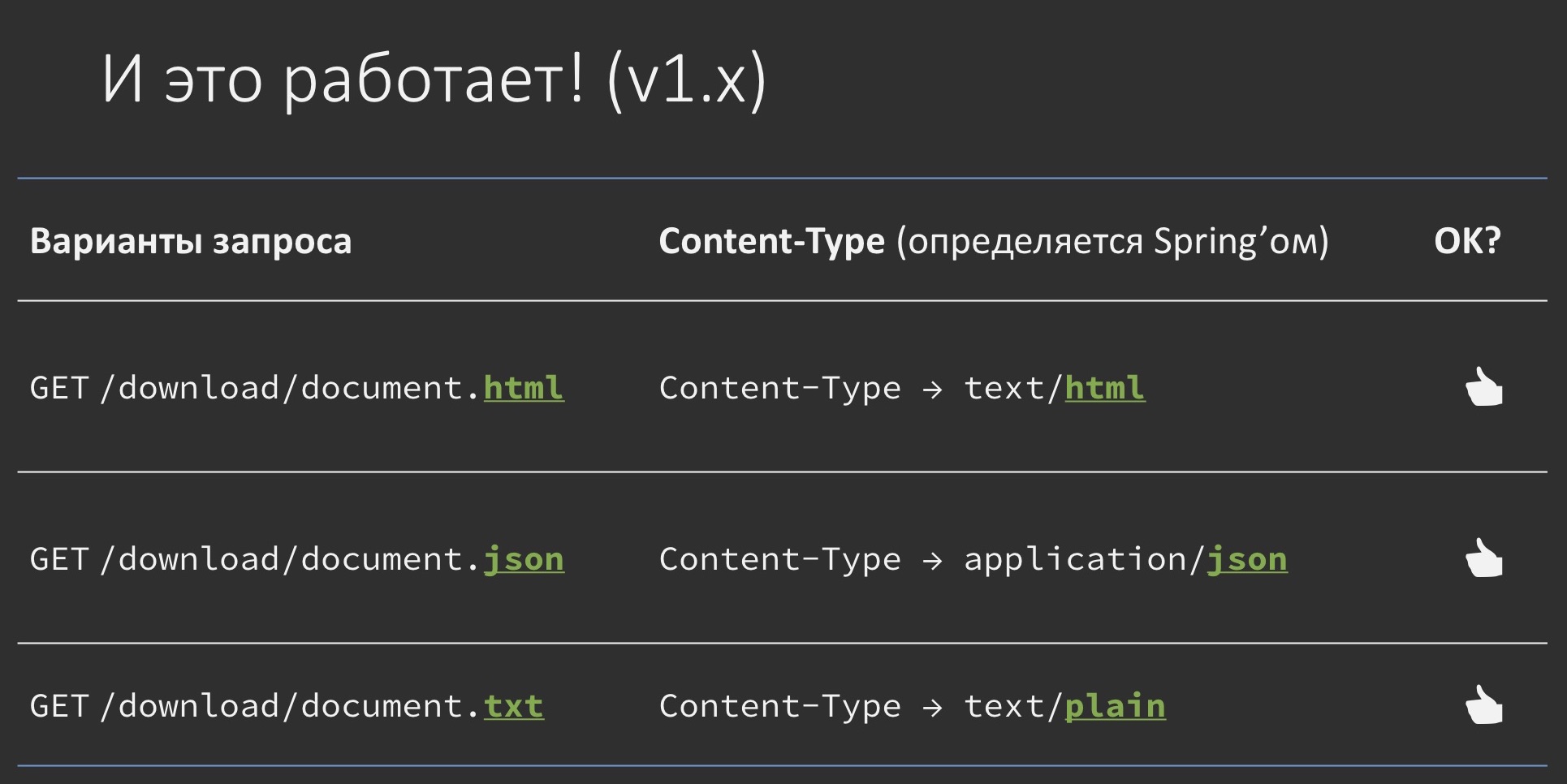
In general, you can even try to do so. Indeed, if we request the same document with different extensions, it will be given with the correct content-type, depending on what we return: you want - json, you want - txt, you want - html. Works like a fairy tale.
Update to v2.x
dependencies { ext { springBootVersion = '2.0.4.RELEASE' } compile("org.springframework.boot:spring-boot-starter-web:$springBootVersion") } It is time to upgrade to the second Spring Boot. We just change the number 1 to 2.

Spring MVC Path Matching Default Behavior Change
But we are engineers, we will look at the Migration Guide, but what if there is something said about it. But there is some sort of “suffix path matching” mentioned. It's about how to correctly map methods in Java from a URL. But this is not our case, although a bit similar.

Therefore, we score, check and bang! - suddenly does not work. For some reason, just text / html starts to be given everywhere, and if you dig, it’s not text / html, but just the first of the types you specify in the creates attribute for the @GetMapping annotation. Why is that? It looks, to put it mildly, incomprehensible.

And here, no Release Notes will help, you will have to read the source code.
ContentNegotiationManagerFactoryBean
public ContentNegotiationManagerFactoryBean build() { List<ContentNegotiationStrategy> strategies = new ArrayList<>(); if (this.strategies != null) { strategies.addAll(this.strategies); } else { if (this.favorPathExtension) { PathExtensionContentNegotiationStrategy strategy; // … There you can find a classic with a very clear concise short name, which mentions a certain flag called “take into account the expansion in the way” (favorPathExtension). The value of this flag “true” corresponds to the use of a certain strategy with another understandable short concise name, from which it is clear that it is responsible for determining the content-type by file extension. As you can see, if the flag is false, the strategy will not apply.

Yes, probably, many noticed that in Spring, apparently, there is some kind of guideline, so that the name must have been well, at least of twenty characters.

If you dig a little deeper, you can dig up a fragment like this. In the Spring framework itself, and not in the fifth version, as one would expect, but for centuries this flag defaults to "true." While in Spring Boot and in the second version it was blocked by another one, which is now available for management from the settings. That is, we can now steer them from the environment, and this is only in the second version. Feeling? There, he has already taken the meaning of "false." That is, they wanted, it seemed, to do it better, brought this flag to the settings (and this is great), but the default was switched to another (this is not very good).
The developers of the framework are also people, they too are prone to make mistakes. What to do with it? Clearly, you need to switch the parameter in your project, and everything will be fine.
The only thing that needs to be done just in case, to clear our conscience, is to look into the Spring Boot documentation just for any mention of this flag. And there he is indeed mentioned , but only in some strange context:
If you understand the following configuration is required:It’s written, they say, if you understand all the tricks and still want to use suffix path matching, then check this box. Feel the discrepancy? It seems like we are talking about defining a content-type in the context of this flag, and here we are talking about matching Java methods and URLs. It looks somehow incomprehensible.
spring.mvc.contentnegotiation.favor-path-extension = true
...
We have to dig further. GitHub has this pull request :

Within the framework of this pull request, these changes were made - switching the default values - and there one of the framework authors says that this problem has two aspects: one is just path matching, and the second is the definition of content-type . That is, in other words, the box applies to the one and the other, and they are inextricably linked.
It would be possible, of course, to find it immediately on GitHub, if you only know where to look.

Suffix match
Moreover, the documentation on the Spring Framework itself states that the use of file extensions was necessary before, but now it is no longer considered a necessity. Moreover, it proved to be problematic in a number of cases.
We summarize
Changing the default value of a flag is not a bug, but a feature. It is inextricably linked with the definition of path matching and is designed to do three things :
- reduce security risks (which ones, I will clarify);
- align the behavior of WebFlux and WebMvc, they differed in this aspect;
- align the statement in the documentation with the framework code.
How to be?
First, if possible, you should not rely on the definition of a content-type by extension. The example I showed is a counterexample, so don't do that! As well as it is not necessary to rely on the fact that requests of the form “GET something. Json”, for example, will be smiled simply on “GET something”. So it was in the Spring Framework 4 and in Spring Boot 1. It doesn't work like this anymore. If you need to dump a file with an extension, you need to do this explicitly. Instead, it is better to rely on the Accept header or on the URL parameter, the name of which you can steer. Well, if this is not done in any way, let's say you have some old mobile clients that stopped updating in the last century, then you have to return this box, set it to “true”, and everything will work as before.
In addition, for general understanding, you can read the chapter “Suffix match” in the documentation for the Spring Framework, it is considered by the developers themselves to be a kind of collection of best practices in this area, and familiarize themselves with what the Reflected File Download attack is, which is implemented through manipulations with file extension.
Scheduling Perform scheduled tasks or periodically
Let's change the review area a bit and talk about performing tasks on a schedule or periodically.
Sample task. Log a message every 3 seconds
What is at stake, I think, is clear. We have some business needs, to do something with some kind of repetition, so we will go straight to the example. Suppose we have a mega-difficult task: to output some nastiness to the log every 3 seconds.

This can be done, obviously, in a variety of ways, there is something for Spring anyway for them. And to find it is a lot of ways.
Option 1: search for an example in your project
/** *A very helpful service */ @Service public class ReallyBusinessService { // … a bunch of methods … @Scheduled(fixedDelay = 3000L) public void runRepeatedlyWithFixedDelay() { assert Runtime.getRuntime().availableProcessors() >= 4; } // … another bunch of methods … } We can look in our own project and for sure we will find something like that. One annotation will hang on the public method, and from it it will be clear that as soon as you hang it, everything works just like in a fairy tale.
Option 2: search for the desired annotation

You can search the annotation itself by its name, and it will probably also be clear from the documentation that you hang it - and everything works.
Option 3: Googling
If you don’t have any faith, you can google it, and from what you find, it will also be clear that everything will start from one annotation.
@Component public class EventCreator { private static final Logger LOG = LoggerFactory.getLogger(EventCreator.class); private final EventRepository eventRepository; public EventCreator(final EventRepository eventRepository) { this.eventRepository = eventRepository; } @Scheduled(fixedRate = 1000) public void create() { final LocalDateTime start = LocalDateTime.now(); eventRepository.save( new Event(new EventKey("An event type", start, UUID.randomUUID()), Math.random() * 1000)); LOG.debug("Event created!"); } } Who sees this trick? We are engineers after all, let's check how it works in reality.
Show me the code!
Consider a specific task (the task itself and the code are in my repository ).
Who does not want to read, you can watch this fragment of the video with a demonstration (until the 22nd minute):
As a dependency, we will use the first Spring Boot with two starters. One is for the web, we are sort of developing a web server, and the second is a spring starter actuator, so that we have production-ready features, so that we are at least a bit like something real.
dependencies { ext { springBootVersion = '1.5.14.RELEASE' // springBootVersion = '2.0.4.RELEASE' } compile("org.springframework.boot:spring-boot-starter-web:$springBootVersion") compile("org.springframework.boot:spring-boot-starter-actuator:$springBootVersion") // +100500 зависимостей в случае настоящего приложения } And our executable code will be even easier.
package tech.toparvion.sample.joker18.schedule; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.scheduling.annotation.Scheduled; @SpringBootApplication public class EnableSchedulingDemoApplication { private static final Logger log = LoggerFactory.getLogger(EnableSchedulingDemoApplication.class); public static void main(String[] args) { SpringApplication.run(EnableSchedulingDemoApplication.class, args); } @Scheduled(fixedRate = 3000L) public void doOnSchedule() { log.info(“Еще 3 секунды доклада потрачено без дела…”); } } In general, almost nothing remarkable, except for a single method, on which we hung the annotation. We copy it somewhere and expect it to work.
Let's check, we're engineers. We start. We assume that every three seconds such a message will be displayed in the log. Everything should work out of the box, we are convinced that everything is running on the first Spring Boot, and we are waiting for the necessary line to be displayed. Three seconds pass - the line is displayed, six passes - the line is displayed. Optimists won, it works.

It just comes time to upgrade to the second Spring Boot. Let's not bother, just switch from one to another:
dependencies { ext { // springBootVersion = '1.5.14.RELEASE' springBootVersion = '2.0.4.RELEASE' } In theory, the Migration Guide did not warn us about anything, and we expect that everything will work without deviations. From the point of view of the executable code, none of the other rakes, which I mentioned earlier (incompatibility at the API level or something else) we do not have here, because the application is as simple as possible.
We start. First of all, we are convinced that we are working on the second Spring Boot, otherwise there are no, it seems, deviations.

However, it takes 3 seconds, 6, 9, but there is still no Hermann - no conclusion, nothing works.
As is often the case, waiting is at odds with reality. We are often written in the documentation that in fact everything works out of the box in Spring Boot, that we can just run as-is with minimal problems and no configuration is required. But as soon as it comes to reality, it often turns out that you should still read the documentation. In particular, if you dig around thoroughly, you can find the following lines:
7.3.1. Enable Scheduling AnnotationsIn order for the Scheduled annotation to work, you need to hang another annotation on the class with one more annotation. Well, as usual in Spring. But why did it work before? We didn’t do anything like that. Obviously, this annotation hung somewhere earlier in the first Spring Boot, and now for some reason it is not in the second one.
To enable support for @Scheduled and Async annotations, you can add @EnableScheduling and @EnableAsync to one of your @Configuration classes.

We start to rummage in the source code of the first Spring Boot. We find that there is some class on which it supposedly hangs. We look closer, it is called “MetricExportAutoConfiguration” and, apparently, is responsible for the delivery of these performance metrics to the outside, to some centralized aggregators, and there really is this annotation on it.

And it works in such a way that it includes its behavior on the entire application at once, it does not need to be hung up on separate classes. It was this class that was the supplier of this behavior, and then for some reason did not. Why?
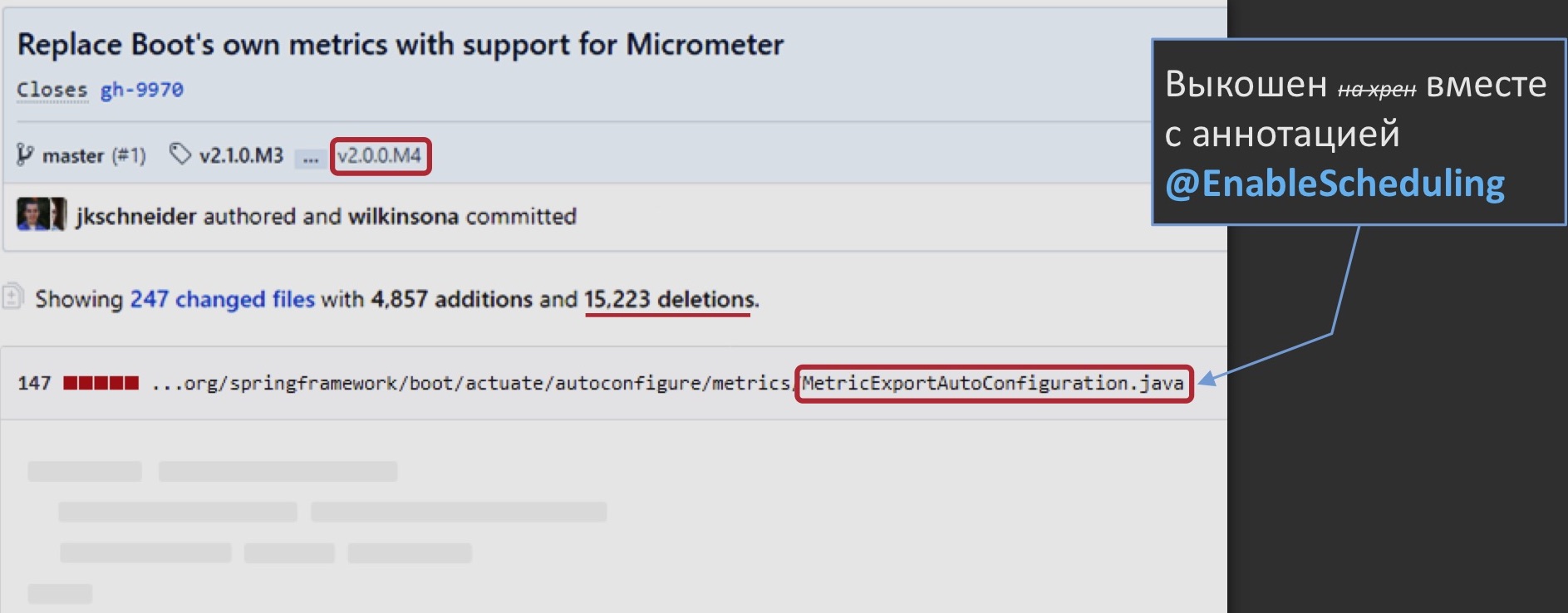
All the same GitHub pushes us to such an archaeological excavation: as part of the transition to the second version of Spring Boot, this class was mowed out along with the annotation. Why? Yes, because the metrics delivery engine also changed: they no longer began to use their own samopisny, but switched to Micrometer - a really sensible solution. It’s just that something superfluous was removed with him. Maybe this is even correct.
Who does not want to read, see a short demo for 30 seconds:
From this it follows that if we now take and manually hang up the missing annotation in our original class, then, in theory, the behavior should become correct.
package tech.toparvion.sample.joker18.schedule; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.scheduling.annotation.Scheduled; @SpringBootApplication @EnableScheduling public class EnableSchedulingDemoApplication { private static final Logger log = LoggerFactory.getLogger(EnableSchedulingDemoApplication.class); public static void main(String[] args) { SpringApplication.run(EnableSchedulingDemoApplication.class, args); } @Scheduled(fixedRate = 3000L) public void doOnSchedule() { log.info(“Еще 3 секунды доклада потрачено без дела…”); } } What do you think will work? Let's check. We start.

It can be seen that after 3 seconds, after 6 and after 9, the message we expected is still displayed in the log.
How to be?
What to do with this in this particular and more generally? No matter how moral this sounds, first of all, it is worth reading not only the copied fragments of the documentation, but also a little wider, just to cover such aspects.
Secondly, remember that in Spring Boot, although many features are out of the box (scheduling, async, caching, ...), they are not always included, they must be explicitly included.
Thirdly, it doesn’t bother to play it safe: add Enable * annotations (and their whole family) to your code, not relying on the framework.But then the question arises: what will happen if by chance I and my colleagues add a few annotations, how will they behave? The framework itself claims that duplication of annotations never leads to errors. And in fact: almost never. The fact is that some of these annotations have attributes.
For example, @EnableAsync and EnableCaching has attributes that, in particular, control the mode in which the beans will be proxied in order to implement the corresponding functionality. Therefore, you can randomly set these annotations in two places with different attribute values. What will happen in this case? Partially this question is answered by javadoc for one of the classes that are directly involved in this functionality. He says that this recorder works by searching for the nearest annotation. He knows that there are several possible Enable *, but by and large he doesn't care which one he chooses. What can this lead to? But about this we just talk in the next case.
Spring Cloud & Co. Library compatibility

Let's take as a basis a small microservice on Spring Boot 2 as a base, we will use Spring Cloud on it - we only need its Service Discovery feature (discovery of services by name). Also as monitoring we will fasten JavaMelody. And we also need some kind of traditional base. It doesn't matter which one, if only it supports JDBC, so let's take the simplest H2.

Not as an advertisement, but just for general understanding, I’ll say that JavaMelody is a built-in monitoring that can be accessed directly from the application and see all graphs, metrics, and so on. Conveniently in the dev-environment, in test, and in combat, she can export metrics for consumption by some centralized tool, such as Prometheus.
Our batch will look like this on Gradle:
dependencies { ext { springBootVersion = '2.0.4.RELEASE' springCloudVersion = '2.0.1.RELEASE' } compile("org.springframework.boot:spring-boot-starter-web:$springBootVersion") runtime("org.springframework.boot:spring-boot-starter-jdbc:$springBootVersion") runtime group: "org.springframework.cloud", name: "spring-clooud-starter-netflix-eureka-client", version: springCloudVersion runtime("net.bull.javamelody:javamelody-spring-boot-starter:1.72.0") //… } (full source code)
We take two dependencies on Spring Boot - this is web and jdbc, from Spring Cloud we take its client to eureka (this, if anyone does not know, just a Service Discovery chip), and JavaMelody itself. We practically will not have executable code at all.
@SpringBootApplication public class HikariJavamelodyDemoApplication { public static void main(String[] args) { SpringApplication.run(HikariJavamelodyDemoApplication.class, args); } } We start.

Such an application will crash right at the start. It will not look very nice, but at the very end of the error log it will be said that some com.sun.proxy to Hikari, HikariDataSource was allegedly not managed to be casted. Just in case, let me explain that Hikari is a pool of connections to the database, just like Tomcat, C3P0, or whatever.

Why did it happen? Here we just need the help of an investigator.
Case file
Spring Cloud wraps proxy dataSource
The investigator dug out that Spring Cloud is involved in the fact that he wraps the dataSource (the only one in this application) in a proxy. It does this in order to support the AutoRefresh or RefreshScope feature - this is when the microservice configuration can be pulled from another centralized microservice config and applied on the fly. Just at the expense of the proxy, he updates this and cranks it up. For this he uses only CGLIB.
As you probably know in Spring Boot and, in principle, Spring supports two proxying mechanisms: based on the mechanism built into the JDK (then not the bin itself is proxied, but its interface) and using the CGLIB library (then the bin itself is designed). Wrapping is done before all BeanPostProcessors by replacing BeanDefinition and setting a so-called factory bean, which releases the target bean immediately wrapped in a proxy.
JavaMelody wraps proxy dataSource
The second participant is JavaMelody. He also wraps the DataSource in a proxy, but does so to remove metrics in order to intercept calls and record them in his repository. JavaMelody uses only JDK proxying, because it can’t do it anymore, it’s just not provided for. But it works in a more traditional way - with the help of BeanPostProcessor.
If you look at all this through the debugger prism, it will be seen that just before the fall, the DataSource looked like a wrapper in a JDK proxy, inside which is a CGLIB proxy wrapper. It turned out this matryoshka: This

in itself is not bad. Unless you take into account the fact that not all wrappers with each other work well.
Spring Boot calls dataSource.unwrap ()
Spring Boot adds fuel to the fire, it does on this DataSource # unwrap () to validate this bin before being exposed to JMX. In this case, the JDK proxy freely passes this call through itself (since it has nothing to do with it), and the CGLIB proxy, which was added by Spring Cloud, again requests the bin from the Spring Context. Naturally, he gets a full-fledged matryoshka, which has an JDK wrapper at the external level, applies the CGLIB API to it and breaks at that.
If you show the same thing in pictures, it looks like this:

https://jira.spring.io/browse/SPR-17381
The outer call passes through the outer shell, but instead of being delegated to the target bean, it asks the same bean again from the context. A bug has been filed for this case, it is not yet resolved, but I hope someday this will be fixed.

But this is not the whole picture. What does it really Hikari?
If you watch, then when you replace Hikari pool with some other pool, the problem disappears, because Spring Cloud just does not wrap it. Another observation: Hikari became the default pool in Spring Boot 2. Do you feel? Something here already smacks of some innovations. But it would seem, where is Spring Cloud? From the name it is assumed that it hovers somewhere in the clouds, and where is the pool of connections to the database? Also not close. In theory, they should not know about each other.
And in fact…
org.springframework.cloud.autoconfigure.RefreshAutoConfiguration .RefreshScopeBeanDefinitionEnhancer: /** * Class names for beans to post process into refresh scope. Useful when you * don't control the bean definition (eg it came from auto-configuration). */ private Set<String> refreshables = new HashSet<>( Arrays.asList("com.zaxxer.hikari.HikariDataSource")); Actually, in Spring Cloud there is a magical autoconfiguration, in which there is an even more magical Enhancer BeanDefinition, in which, if not explicitly, but directly dependent on Hikari. That is, the developers of Spring Cloud immediately provided the opportunity to work with this pool. And that's why they wrap it in a proxy.
What conclusions can be drawn from this? Auto-update of beans in Spring Cloud is not for free, all bins are immediately out of the box in CGLIB wrappers. This should be taken into account, for example, in order to know that not all proxy wrappers work equally well with each other. This example just proves it to us (jira.spring.io/browse/SPR-17381). Wrap in a proxy can not only BeanPostProcessor, if you suddenly thought so. You can issue wrappers through the substitution of BeanDefinition and redefining the factory bean even before all BeanPostProcessors have been applied. And Stack Overflow often teaches us that if you encounter some kind of such heresy, then just turn on the checkboxes, switch proxyTargetClass from true to false or vice versa, and everything will pass. But not everything passes, and in some cases this flag simply does not exist.We saw two such examples at once.
In fact, this is just a special case of such an individual compatibility of components, which has to be taken into account by displacing one of them in order for the entire bad combination to collapse.
You can force out in three ways:
- Switch to another connection pool (for example, Tomcat JDBC Pool)
spring.datasource.type = org.apache.tomcat.jdbc.pool.DataSource
Not forgetting to add the
runtime dependency 'org.apache.tomcat: tomcat-jdbc: 8.5.29'
Hikari It takes, like, performance, but not the fact that you have already rested against it, you can return to the old Tomcat pool, which was used in the first Spring Boot. - You can push JavaMelody, either by disabling JDBC monitoring, or by displacing it completely.
javamelody.excluded-datasources = scopedTarget.dataSource - Disable auto-update on the fly in Spring Cloud.
spring.cloud.refresh.enabled = false
We, if you remember, dragged this feature in order to work with Service Discovery, we did not need to update the bins at all.
This way you can avoid this problem. It seems like a degenerate case, and it would be possible not to mention it, but in fact there are much more manifestations of such a problem.
Bonus (similar case *)
* but without Spring Cloud (and you can do without JavaMelody)
@Component @ManagedResource @EnableAsync public class MyJmxResource { @ManagedOperation @Async public void launchLongLastingJob() { // какой-то долгоиграющий код } } Full source code: github.com/toparvion/joker-2018-samples/tree/master/jmx-resource .
Take a similar case. The same application, only we throw out of it Spring Cloud. You can also throw out JavaMelody, leaving only one Spring bin created by this monitoring. And in order to give this project more utility, we assume that there is a class in it that exposes one public method of JMX. And this method supposedly performs some long work, so we labeled it as Async, so as not to make the JMX console wait a long time. To make it visible through JMX, we post the @ManagedOperation annotation on it, and to make it all work, we add two more switches (as we like in Spring, we need to add more annotations, and then everything will be OK).
So, if you run such an application, it will really start successfully, there will be no errors in the logs, but, alas, the myJMXResource bin will not be available via JMX, it will not even be visible. And if you look through the debugger, then the same matryoshka will again be visible - the bin is wrapped in two proxies, CGLIB and JDK.

JDK and CGLIB proxy again. And it immediately becomes clear that BeanPostProcessor is involved somewhere here.
Indeed, there are two participatory BeanPostProcessors:
AsyncAnnotationBeanPostProcessor
- Position: Async annotation director
- Registration: org.springframework.scheduling
- Birthplace: @EnableAsync annotation (via Import )
2. DefaultAdvisorAutoProxyCreator
- Должность: помощник по работе с AOP-прокси, отвечает за перехват вызовов для навешивания аспектов
- Прописка: org.springframework.aop.framework.autoproxy
- Место рождения: @Configuration-класс PointcutAdvisorConfig (библиотечный или самописный)
DefaultAdvisorAutoProxyCreator originates from the @ Configuration class. In my case, when I was doing this for the first time, it was JavaMelody, but in fact it could have been added by any other applied configuration class. And by the way, if it is called PointcutAdvisorConfig, then there will be another interesting observation with it.

It is necessary to rename it, how suddenly the problem goes away. It was called PointcutAdvisorConfig, it became just AdvisorConfig, and this is not an ordinary bin, but a configuration class that supplies bins, that is, it seems like nothing should break, but the behavior really changes from wrong to correct or vice versa.
It would seem that renaming has nothing to do with it, but it is important to remember that where renaming is, there is the order of something.

And in this case, this is the order of BeanPostProcessors. If you look at their list in two modes, when everything is good and when everything is bad, you will see that these two BeanPostProcessor follow the opposite order to each other. If you dig into the intestines, the first one bites at the artificially added Advised interface (inserted by the previous BeanPostProcessor), sees this interface, thinks that it is applied, and if there is an application interface, then it is better to use JDK proxying, it just allows do it in a more natural way. He does and by this breaks everything.
But in reality this is not the whole picture. If you look at the whole chain of influence, it looks like this:

The discovery of a bean to be exposed via JMX was influenced precisely by the proxy order. That, in turn, was determined by the order of application BeanPostProcessor. It is inextricably linked with the order of registering BeanPostProcessors, which comes from the order of the names of the beans in the context, which, in turn, oddly enough, is determined by the order of loading or sorting resources from the file system or from the JAR, depending on where you start .
How to be?
First, if possible, use higher level abstractions provided by the Spring AOP framework, in particular, aspects. Why "possible"? Because often you may not even know that somewhere you have bins of these Advice and Advisor, they can be brought in by third-party libraries, as was the case with monitoring.
Secondly, do not forget about the best practices. Elementary, if we took and hid this application bin JMX-resource under the interface, then the problem could not be. If it still broke, you can look at the proxy composition through the debugger, see which layers it consists of. If suddenly this is not done before, you can try to autowire'it (inject) this bin to any other. This will open the problem earlier. Most likely, you will see by exception that there is some kind of layering there. As a traversal, you can try to steer the order of bins through the Order annotations , so as not to engage in random renaming. And, where applicable, you can try to steer the proxy mode, i.e. all the same flag proxyTargetClass, if applicable.
Summary: what to do in general cases related to the proxy. First, Keep calm and YAGNI. You should not think that such a tin is waiting for you around every corner and you need to defend against it right now. Try to "head on", in a pinch, you can always roll back somewhere, try to work around somewhere else, but do not think that you need to solve this problem before it appears. If you introduce new libraries, you should ask how they work specifically for proxies: whether they create proxy objects, in what order, and whether proxy modes can be affected — as you see, this is not always the case. And you should not include everything just in case. Yes, Spring teaches us that there is nothing to do, everything works out of the box. And here are the reports of the same Kirill Tolkachev tolkkvwhere it shows that a simple application consists of 436 bins, this is vividly proved. And on this example, it was clear that not all features are equally useful.
Relax Binding. Work with properties (parameters) of the application
Talked about the proxy, switch to another topic.

https://docs.spring.io/spring-boot/docs/2.0.5.RELEASE/reference/htmlsingle/#boot-features-external-config-relaxed-binding
There is such a wonderful mechanism as Relax Binding in Spring Boot. This is the ability to read properties for an application from somewhere outside without a clear match with the name inside the application. For example, if you have the firstName field in some bin and you want it to be externally cleaned with the prefix acme.my-project.person, then Spring Boot can provide this in a rather loyal way. No matter how these properties are defined from the outside: through camel case, through hyphens, as is customary in variable environments, or something else — all of this is correctly smeared just on firstName. This is what is called Relax Binding.
So, in the second version of Spring Boot, these rules were a little tougher, and it is also argued that it became easier to work with them from the application code - the way of specifying property names in the application code is unified. I honestly did not feel this, but it is written in the documentation:
- github.com/spring-projects/spring-boot/wiki/Spring-Boot-2.0-Migration-Guide#relaxed-binding (approximately 1 page)
- docs.spring.io/spring-boot/docs/2.0.5.RELEASE/reference/htmlsingle/#boot-features-external-config-relaxed-binding (approximately 3 pages)
- github.com/spring-projects/spring-boot/wiki/Relaxed-Binding-2.0 (approximately 4 pages)
Fiction is very exciting, I advise you to read a lot of interesting things. But the rake remained. It is clear that all cases there will not be taken into account.
For example:
dependencies { ext { springBootVersion = '1.5.4.RELEASE' } compile("org.springframework.boot:spring-boot-starter:$springBootVersion") } ( full source code )
We have a tiny application with a single starter, not even a web, on the first Spring Boot, and now it has a little bit more in the executable code.
@SpringBootApplication public class RelaxBindingApplication implements ApplicationRunner { private static final Logger log = LoggerFactory.getLogger(RelaxBindingDemoApplication.class); @Autowired private SecurityProperties securityProperties; public static void main(String[] args) { SpringApplication.run(RelaxBindingDemoApplication.class, args); } @Override public void main run(ApplicationArguments args) { log.info("KEYSTORE TYPE IS: {}", securityProperties.getKeyStoreType()); } } In particular, we inject some POJO object (property carrier) and output one of these properties to the log, in this case KEYSTORE TYPE. This POJO consists of two fields with two getters and setters, values for which are taken from applications.properties or application.yaml, it does not matter.
If we talk specifically about the keystoreType field, then it looks like a private String keystoreType, and the value is set to it in applications.properties: security.keystoreType = jks.
@Component @ConfigurationProperties(prefix = "security") public class SecurityProperties { private String keystorePath; private String keystoreType; public String getKeystorePath() { return keystorePath; } public void setKeystorePath(String keystorePath) { this.keystorePath = keystorePath; } public String getKeyStoreType() { return keystoreType; } public void setKeystoreType(String keystoreType) { this.keystoreType = keystoreType; } } Run this on the first Spring Boot and everything will work fine.

Everything is displayed, everything works, the birds sing, the harp plays. Once we upgrade to the second version, the application suddenly does not even start.

Not that the property is not defined, it does not even start. And the message will be, at first glance, somewhat inadequate, some setter for the property, which we don’t have in the project at all, some kind of key-store-type, is allegedly not found. That is, it cost us the first time to try, everything worked straight fire, and the second time we do virtually the same thing, and it does not work very well.
Here only the paranoia regime can save us. Turn it on and check if we have such a property.

We have no such property. We are testing a project that is not 2 million lines long, so it is easy to verify that the property is missing. We associate directly here with letters and case-sensitive code in Java and in properties - everything is the same, nothing has gone anywhere. But we know that, probably, the reflection is not immediately used there, there must still be a setter, and it must also be correct. We check it - the setter also satisfies the convention for the Java bean and fully corresponds to the other letters in the register. Just in case, since we turned on paranoia, we’ll check the getters. But with the getter there is one feature, his “keystore” is written as if these are two words: “Key” and “Store”. Suddenly ...

It would seem, what have the getter, if you could not zatsetit? We understand.
It turns out that the original source of the list of bins, with this, the Relax Binding suddenly became getters (including getStoreType ()). Not only they, but they first. Accordingly, for each getter must be found and its setter. But under such a property as keyStoreType, there is no setter. Actually, it is about this that Relax Binding breaks down, trying to find the possibility of binding, and displays a message about it in such an unobvious way, as we saw above.
It may seem that this is some kind of degenerate case, someone there once nakosyachil, and from this inflated the problem. But it can be reproduced quite easily, if we accept the amendment to reality. In fact, the configuration class might look something like this:

And the problem can be reproduced not only on the fact that someone made a mistake in one method, but also on the fact that, as a result, for example, a curve was dead or something else, there were two methods in the class with an almost identical name. The manifestation of the problem in this case will be the same.
How to be?
First of all, the paranoia mode will have to be left on: you still need to check the register of letters in the property names. Secondly, if you assume that in your dev-environment properties will be taken, for example, from YAML and properties, and in combat - from environment variables in the operating system, then check this in advance, it may not be smudged. Thirdly, it would be great to familiarize yourself with the guide that was written for the second version of Relax Binding, it’s enough to read it once. And finally, hope that in the third version of Spring Boot everything will be fine.
Unit Testing. Running tests in Mockito 2
Let's talk a little about testing, only not about some kind of high-level integration and functional, but about the usual unit testing using Mockito.
Mockito turned out to be in business, because if you pull yourself up in a Spring Boot Starter dependency, well, or in general, the test rig of Spring, you will automatically get a dependency on Mockito as well.
$gradle -q dependencyInsight --configuration testCompile --dependency mockito org.mockito:mockito-core:2.15.0 variant "runtime" /--- org.springframework.boot:spring-boot-starter-test:2.0.2.RELEASE /---testCompile But what version of this dependency? Here is one unobvious moment. In the first version, Spring Boot also used the first version of Mockito, however, with version 1.5.2, Spring Boot began to allow manual activation of Mockito 2, that is, it became compatible with it. However, by default this is still the same. And only from the second version, he began using Mockito 2.
The Mockito itself was updated quite a long time ago, at the end of 2016, Mockito 2.0 and Mockito.2.1 were released — two serious versions with lots of changes: they supported Java 8 with its type deduction, bypassed the intersection with Hamcrest library and have taken into account a lot of stuffed long cones. And these versions, as it is assumed by changing the major number, are not backward compatible with the first one.
All this leads to the fact that you not only encounter a bunch of problems in the main code, but also get failures (although compiled) tests.

For example, you had such a simple test in which you locked the JButton from Swing, set the name null to it, and then check if you really set any line. On the one hand, you can assign a string to null, on the other hand, null does not pass the instanceof to string. In general, in Mockito 1, this all passed without problems, but Mockito 2 has already learned to delve into this matter more thoroughly and says that anyString does not pass to null anymore, it will explicitly give an error message that this test is no longer correct . And it makes checking explicitly: if you expect to see null there, be so kind as to write it down. According to the developers, they felt that such a change would make the test tooling a little safer than it was in Mockito 1.
Take a similar, at first glance, example.
public class MyService { public void setTarget(Object target) { //… } } <hr/> @Test public void testAnyStringMatcher() { MyService myServiceMock = mock(MyService.class); myServiceMock.setTarget(new JButton()); verify(myServiceMock).setTarget(anyString()); } Suppose we have an application class with a single method that accepts any object. And now we have locked it and in the quality of this any object we assigned him the same JButton. And then suddenly we check it on anyString. It would seem that this is a complete heresy: we passed the button, and we check for a line - not related things at all. But it is here, in the degenerate one class, that seems crazy. When you test any application behavior from different angles in 10 aspects with hundreds of tests, writing this is actually easy. And Mockito 1 will not say that you are checking the full garbage:

Mockito 2 will warn you about this, although, at first glance, anyString behaves in the same way:

Let's talk a little about another area. Another example, only now dealing with exceptions. Suppose we have the same application class, now with an even simpler method that takes nothing at all and does nothing, and we want to simulate a drop in it due to a SocketTimeoutException, that is, as if there is some kind of network failure inside . At the same time, the method itself did not initially declare any checked exceptions, and SocketTimeoutException checked, if you remember. So such a test passed without problems in Mockito 1.

But Mockito 2 has already learned how to delve into this matter and say that the checked exception for this case is not valid:

The trick is that Mockito 1 was also able to do this, but only if the exception was created exactly as an instance of the class. That is, if you created a new SocketTimeoutException directly through new, through the constructor, then Mockito 1 would also be cursed.
What to do with it?We'll have to wrap up such exceptions, for example, in RuntimeException, and then throw them out of the class, as now the Mockito has become clearer in the checks.
There are a lot of such cases. I gave a couple of examples, and the rest will be outlined only in general terms. First of all, this is incompatibility in compile-time. Some classes moved to other packages so as not to overlap with Hamcrest. Regarding Spring Boot, the @MockBean and @SpyBean classes are no longer supported in Mockito 1. And a full-fledged test framework deserves special attention, which was written down in Spring Integration, I happened to have a hand in the review part.
(Read: https://docs.spring.io/spring-integration/docs/5.0.0.RELEASE/reference/htmlsingle/#testing )
How to be?
No matter how moral it may sound, the practices recommended for use with Mockito 1 often allow to get around problems with Mockito 2 ( dzone.com/refcardz/mockito ).
Secondly, if you still have such a transition, you can make it in advance, starting with Spring Boot 1.5.2 using Mockito 2.
Third, of course, you can take into account the guides that are given for Mockito 2, and they already Already collected a lot of interesting experience: one , two .
Gradle Plugin. Building Spring Boot Projects
The last thing I would like to talk about is the Spring Boot plugin for Gradle.
The Migration Guide itself says that the Spring Boot plugin for Gradle has been pretty much rewritten. It is what it is.From the main point: he now needs Gradle 4 versions (respectively, at least empty settings.gradle in the project root). It no longer includes the dependency management plugin by default, so that there is less magic. And the bootRepackage task, the most magical, split into two: bootWar and bootJar. That's just on bootJar, we are a little more detailed and stop.
BootJar task:
- Activated automatically if the org.springframework.boot and java plugins are applied;
- Disables the jar task;
- Able to find mainClassName (the main name of the class to run) in different ways (and knocks the assembly, if you still have not found).
It would seem that such clear, obvious conclusions, but what follows from them is not at all obvious until you try, for this is a Gradle, and even with Spring Boot.
What exactly are we talking about? We will take some simple application on Spring Boot 2, the build, of course, on Gradle 4 and using this Spring Boot plug-in. And in order to add realism to it, we will make it not ordinary, but composite: we will have both application code and a library, as is often done (the general code is allocated to the library, all the others depend on it).

If the pictures, then so. The number in the name app1 suggests that there may be app2, app3, etc. This app1 depends on the lib library.
“Show me the code!”
Root project
subprojects { repositories { mavenCentral() } apply plugin: 'java' apply plugin: 'org.springframework.boot' } In the root project, everything is very simple with us - two plugins are applied: java and Spring Boot itself to all subprojects.
By the way, I did not mention that this is not the only way to do this, it can be done in different ways. You can either specify in the root project that we will apply the plugin to each subproject, or specify in each subproject what it will work with. For the sake of brevity of our example, we choose the first method.
app1: build script
dependencies { ext { springBootVersion = '2.0.4.RELEASE' } compile("org.springframework.boot:spring-boot-starter:$springBootVersion") compile project(':lib') } In the application code, we only have a lib dependency and the fact that this is a Spring Boot application.
app1: executable code
@SpringBootApplication public class GradlePluginDemoApplication implements ApplicationRunner { //… @Override public void run(ApplicationArguments args) { String appVersion = Util.getAppVersion(getClass()); log.info("Current application version: {}", appVersion); } } In the executable code, we will only turn to the Util class that lies in our lib.
lib: executable code
public abstract class Util { public static String getAppVersion(Class<?> appClass) { return appClass.getPackage().getImplementationVersion(); } } This Util class will use its getAppVersion method to simply access the package, take the manifest from it, request ImplementationVersion and return it. And the build script for this subproject is generally empty.
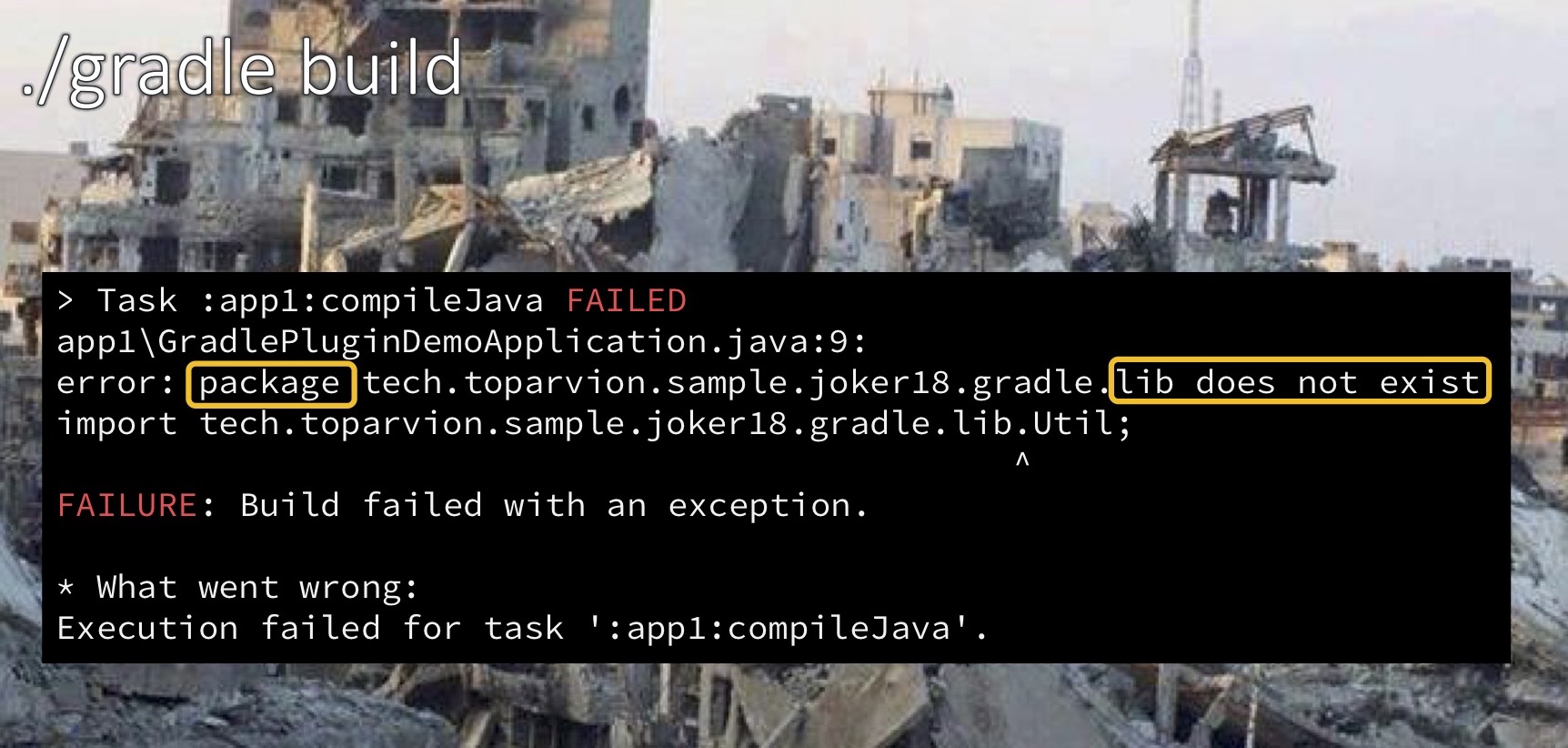
If you run such an application from the IDE, everything will be fine, it will resolve all dependencies, and everything will work perfectly. But it is worth doing a gradle build from outside the IDE manually, as the build will break. And the reason will be the sudden inability to resolve dependencies on Util. That is, it would seem, the library is completely next to each other, but the compiler cannot find it, because it allegedly does not see such a package.
Investigation results
The reasons:
- bootJar jamming jar;
- Gradle delivers dependencies to subprojects based on exhaust from jar.
Consequences:
- The compiler cannot resolve the dependency on the library;
- All manifest attributes set on the jar task (the same ImplementationVersion) are ignored.
How can I fix this? One option is to make an exception in the root script itself.
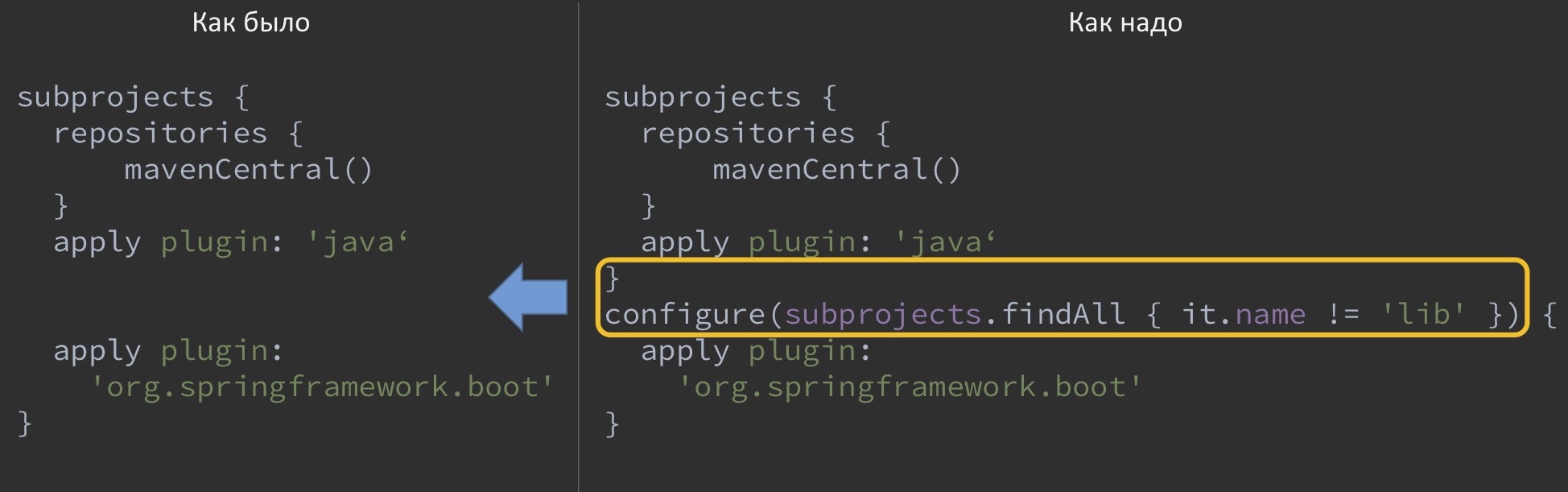
That is, as if to tear off the use of Spring Boot-plugin from other projects, saying that it is not necessary to use it for lib. However, there is another way.
Option 2: Apply SB Gradle Plugin only to Spring Boot Sub-projects
bootJar { enabled = false } If we don’t want the root project to know about some kind of separate ornate library, we can prescribe in it, or rather, in its build script, what specifically for this subproject the bootJar should be turned off. Accordingly, the usual standard jar task will remain enabled, and everything will work as before.
Other
We talked, probably, only about a small share of all the rakes that can occur when updating Spring Boot. Some of the rest I will mention only briefly.

In Spring Boot, numerous parameter renames have remained outside the scope of our consideration: they are associated with switching to a web stack, breaking it down into servlet and reactive, and with other edits. In order to work with this somehow, the second version comes with such a cool thing as Spring Boot properties migrator, I highly recommend using it in order to understand what parameters you have used with outdated names. It will write you straight to the log that this parameter is outdated, it needs to be replaced by such and such, but this one is now useless, and so on.
Many more changes happened in Actuator. In particular, now it is necessary to steer completely differently with the security (availability) of its methods, from now on it looks more like Spring Security. No more special flags for this.

There have been a lot of renames in Spring Cloud. This is important because its version will also be transitively pulled up by you. This is the renaming of artifacts related to Netflix and Feign.

In Spring Integration, which also reached version 5, like the Spring Framework, there were a number of changes. One of the largest is that the once experimental Java DSL has moved into the core of the project itself and, accordingly, it no longer needs to be connected as a separate dependency. Those adapters that are used to communicate with the outside world, input and output, now have their own static methods that can be used in pipelines on the handle method without the special handleWithAdapter method.
Conclusion Summary and conclusions
Summarizing, I will designate four areas from which it is worth waiting for dirty tricks:

When updating this, first of all, of course, the Web, since the separation of the stacks could not pass unnoticed.
The second (Properties Binding), the binding of external parameters, is also pretty enjoyable due to the fact that the Relax Binding mechanism has changed.
Thirdly, everything related to the proxying mechanisms: any kind of caching, AOP, etc., can also become a source of changes due to the fact that the default proxy mode has changed in Spring Boot 2.
And finally, the fourth, tests - just because there was an update from Mockito 1 to Mockito 2. But these are all some common words, but what about this?
- Try "with nahrapa" (YAGNI)
- Check with samples;
- Check for updates in the Migration Guide ;
- See other grabledigsts: one , two.
Firstly, do not think that such a rake will be waiting for you at every turn, you should try to run as it is, remember the principle of YAGNI. Until something breaks in you, do not try to fix it. Such an approach will at least allow you to assess the scale of the problems.
Secondly, if you are still confronted with something, you can check with some of the samples that I collected while preparing for this report. There is no superfluous logic, they are exclusively engaged in reproducing specific situations, which are documented, described, what to do and where to get from. Plus, it would not hurt to periodically look into the Migration Guide itself. Due to the fact that this document is constantly being replenished and developed by the developers themselves, it is likely that as soon as you look at it, it will suddenly become clear that your case has been resolved and that there has already been written about it.
There are other such grabledidzhes who collected experience and summarized all sorts of rakes when upgrading and further operating Spring Boot. I hope that all these tips and knowledge will help you upgrade without problems and continue to successfully use Spring Boot, put it into your service, so that it will serve you faithfully ... right up to the third version.
If you like the report, please note: the JPoint will be held in Moscow on April 5-6 , and there I will give a new report on Spring Boot: this time about transferring Spring Boot-microservices from Java 8 to Java 11. Details about the conference are on the website .
Source: https://habr.com/ru/post/439796/