Analysis of Minor Violations Java code on the Duerank.com platform (part 1)

Introduction
What do we know about errors in the code of applications written in Java? Well, we probably know that they meet there. And how often do they meet? How many different things does a developer make in his code? By bugs we mean not only bugs, but also the presence of various code smell, vulnerabilities, violations. Can this all be measured? Is it possible to determine the quality of the repository code, the developers and the product as a whole on the basis of these measurements? Is it possible in this way to compare the quality of the code of different developers and choose a stronger partner? Is it possible to get a salary increase by showing an increase in the quality of your code and a decrease in the level of your technical debt? The task of the team is precisely to answer all these questions in the affirmative.
In this paper, we will look at Minor Violations in Java code that can potentially affect developer productivity like:
- failure to use code convention;
- The finalizer does nothing other than calling the finalizer of the superclass;
- too long lines;
- switch must have at least 3 options, etc.
Beginning of work
Our research is based on an analysis of the quality indicators of source code written in Java and obtained from the open source GitHub repositories. The results of the study were compiled into one large csv file, and the analysis of the obtained data was carried out using the already de facto standard stack: scipy, numpy, pandas, matplotlib.
Standard import of required tools:
import scipy import matplotlib.pyplot as plt import pandas as pd import numpy as np import statsmodels.api as sm We read the data from the csv-file, discard all the lines that contain incomplete data, select for further analysis all data related to the Java language and display some preliminary statistics to find out what the data is:
df = pd.read_csv('ScanGitHub.csv') df = df.dropna() df_Java = df[df['Repository Language'] == 'Java'] print(np.sum(df_Java['Lines Of Code'])) df_Java[['Lines Of Code', 'Minor Violations']].describe() As a result, we obtained that there are 276,015,051 lines of code in the 60,959 scanned repositories. On average, one repository contains 4528 lines of code and 150 Minor Violations:

Interestingly, 50% of all repositories scanned by us are quite small - the number of lines of code is 711, and the number of Minor Violations is 22.
But these figures are quite uninformative, as well as the average temperature in the ward. Further study needed.
Let's see how repositories are distributed by the number of lines of code:
f, ax = plt.subplots(1) ax.hist(df_Java['Lines Of Code'], color='#00ab6c', bins=100, alpha=0.5, rwidth=0.85, label='SLOC distribution') ax.grid(True) ax.set_xlabel('SLOC') ax.set_ylabel('# of repositories') ax.legend(loc='best') df_Java['Lines Of Code'].describe() 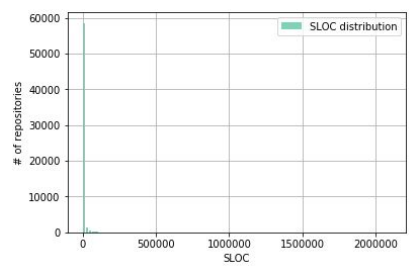
Those who expected to see a normal distribution here, I think, were disappointed. But that his here can not be, we suggested the previous sign! How can this result be explained? A very large number of projects has a relatively very small number of lines of code, since mostly individual projects and small open-source collaborations are laid out in open access on GitHub.
To reduce the scale along the axes, different techniques are used, but in this case it will be convenient to log the number of lines of code. Let's see what happens:
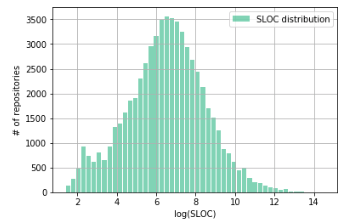
Indeed, after logarithm, our distribution is more like a normal one. There is a small anomaly in the region of 2-3 (which corresponds to ~ 7-20 lines of code), apparently, with a large number of HelloWorld projects.
Now we study the distribution of Minor Violations.
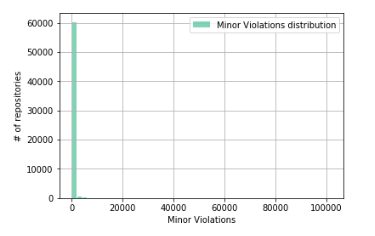
Something similar to what happened when the number of lines of code in the repository was distributed? Indeed, it would be naive to believe that Minor Violations would be distributed differently, assuming that the average number of Minor Violations per line of code is a constant value.
Let's do the logarithm trick again:
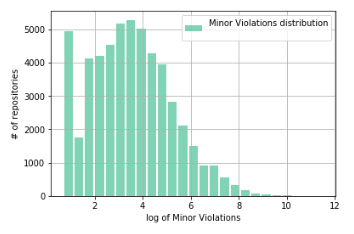
And again we get the distortion of the distribution in the region of small Minor Violations values, corresponding to small values of the number of lines of code.
We filter the data by the number of lines of code and see what happens (why we filter by the number of lines of code> 1000 will be clear below):
sample = df_Java[(df_Java['Minor Violations'] > 1)&(df_Java['Lines Of Code']>1000)]['Minor Violations'] ax.hist(np.log(sample), color='#00ab6c', bins=25, alpha=0.5, rwidth=0.85, label='Minor Violations distribution\nSLOC > 1000') ax.grid(True) ax.set_xlabel('log of Minor Violations') ax.set_ylabel('# of repositories') ax.legend(loc='best') 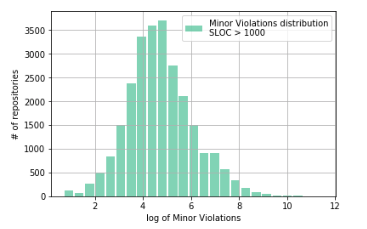
Here, another thing! As can be seen from the graph, our hypothesis about the distortion of the distribution of data corresponding to the repositories with a small (up to 1000) number of lines of code, was confirmed.
Finding the relationship between SLOC and Minor Violations
We now proceed to the study of the correlation between the number of lines of code and Minor Violations and try to answer the sacred question: what happens to the quality of the code if its volume increases.
ax.scatter(df_Java['Lines Of Code'], df_Java['Minor Violations'], c='#00ab6c', alpha=0.30, edgecolors='none', marker='.', label='Java') ax.set_xlabel('SLOC') ax.set_ylabel('Minor Violations') ax.legend(loc='best') ax.grid(True) And-and-and-and ... This is probably not what we expected to see again!
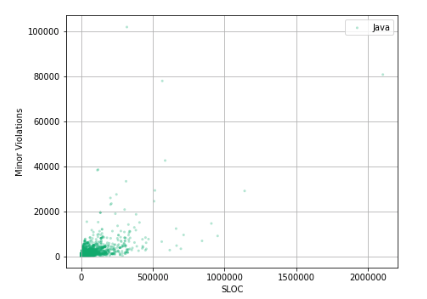
Most of the data is in the range of 0-500000 lines of code and 0-2000 Minor Violations. Increase this area and see what is there.
ax.scatter(df_Java['Lines Of Code'], df_Java['Minor Violations'], c='#00ab6c', alpha=0.30, edgecolors='none', marker='.', label='Java') ax.set_xlabel('SLOC') ax.set_ylabel('Minor Violations') ax.legend(loc='best') ax.grid(True) ax.set_xlim(0, 50000) ax.set_ylim(0, 5000) 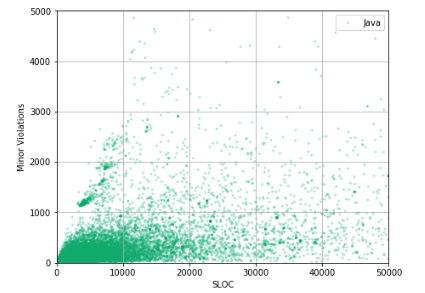
It is difficult to say if there is any correlation between the number of lines of code and the number of Minor Violations in the repository. In order to reveal this correlation, it is necessary to linearize this dependence, to carry out feature engineering.
To successfully carry out feature engineering, first of all, it is necessary to investigate changes in the shape of the distribution of the number of lines of code as Minor Violations increases, as well as changes in the form of the distribution of Minor Violations as the number of lines of repository code increases.
Consider how the form of the distribution of Minor Violations changes with increasing number of lines of code in the repository:
f, ax = plt.subplots(nrows=5, ncols=2) f.set_figwidth(10) f.set_figheight(10) for i in range(10): low_lim = 5000 * i - 1000 up_lim = 5000 * i + 1000 _df_Java = df_Java[(df_Java['Lines Of Code'] > low_lim) & (df_Java['Lines Of Code'] < up_lim)] ax[i//2][i%2].hist(_df_Java['Minor Violations'], color='#00ab6c', bins=20 if i < 9 else 20, alpha=0.5, rwidth=0.85, label='Minor Violations distribution\n({} < SLOC < {})'.format(0 if low_lim < 0 else low_lim, up_lim)) ax[i//2][i%2].grid(True) ax[i//2][i%2].set_xlabel('# of Minor Violations') ax[i//2][i%2].set_ylabel('# of repositories') ax[i//2][i%2].legend(loc='best') f.savefig('fig.png') In this case, we see that all distributions are not normal and are similar to exponential, lognormal, gamma distribution, or the like. From the graphs it can be seen that the higher the number of rows in the repository, the more sparse the data become, that is, repositories with a large number of lines of code are less common. That is consistent with the data obtained by us earlier.
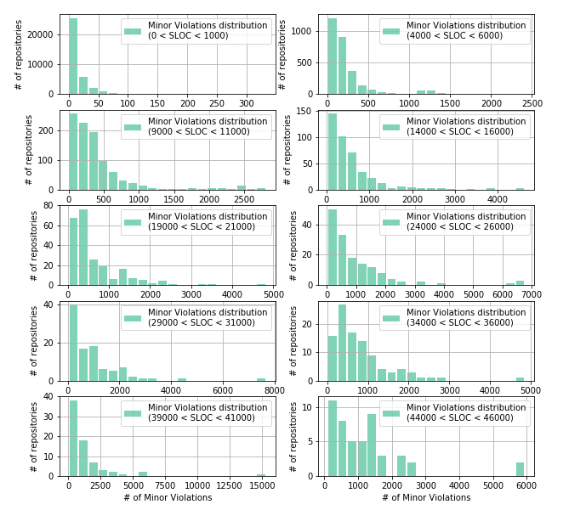
Similarly, we investigate changes in the distribution structure of lines of code as the number of Minor Violations increases:
f, ax = plt.subplots(nrows=5, ncols=2) f.set_figwidth(10) f.set_figheight(10) for i in range(10): low_lim = 500 * i - 100 up_lim = 500 * i + 100 _df_Java = df_Java[(df_Java['Minor Violations'] > low_lim) & (df_Java['Minor Violations'] < up_lim)] ax[i//2][i%2].hist(_df_Java['Lines Of Code'], color='#00ab6c', bins=20 if i < 6 else 20, alpha=0.5, rwidth=0.85, label='SLOC distribution\n({} < Minor Violations < {})'.format(0 if low_lim < 0 else low_lim, up_lim)) ax[i//2][i%2].grid(True) ax[i//2][i%2].set_xlabel('# of SLOC') ax[i//2][i%2].set_ylabel('# of repositories') ax[i//2][i%2].legend(loc='best') f.savefig('fig.png') 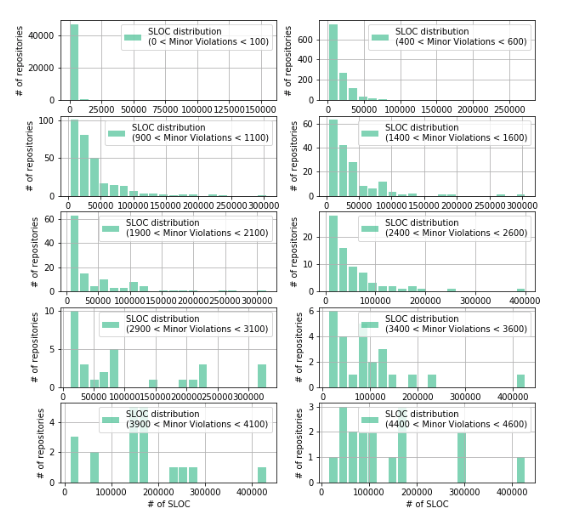
From the graphs it can be seen that the distribution of the number of lines of code in the repository differs from the normal one and is very similar to what we saw in the case of the Minor Violation distribution.
To successfully linearize the data, it is necessary to more accurately determine the type of distribution of our data. To do this, use the two-sided Kolmogorov-Smirnov test. Here is an example of how this is done for Minor Violations in the case when 14000 <SLOC <16000:
low_lim = 14000 up_lim = 16000 sample = df_Java[(df_Java['Lines Of Code'] > low_lim) & (df_Java['Lines Of Code'] < up_lim)]['Minor Violations'] res = [] for cdf in cdfs: parameters = eval("stats."+cdf+".fit(sample)") D, p = scipy.stats.kstest(sample, cdf, args=parameters) if p > 0.05: res.append({'stat':cdf, 'p':p, 'D':D}) res = sorted(res, key=lambda k: k['p'], reverse=True) for i in res: print(i) {'stat': 'johnsonsb', 'p': 0.6921277394819424, 'D': 0.03522119052695105} {'stat': 'exponweib', 'p': 0.6661261317167249, 'D': 0.03630428488021764} {'stat': 'invgauss', 'p': 0.6152804218017391, 'D': 0.037606319965134194} {'stat': 'johnsonsu', 'p': 0.5647176954088229, 'D': 0.03896411311280057} {'stat': 'gengamma', 'p': 0.5472142592213745, 'D': 0.039451029797039294} {'stat': 'f', 'p': 0.4677860605493356, 'D': 0.04179264343902089} Having done such actions for various groups of Minor Violations, we saw that it was Johnson's SU-distribution that was most often the one with the highest p-value sum. Since Johnson's SU-distribution is basically exponential in nature, the logarithm method already used here is a logical way to linearize our data.
fig, ax = plt.subplots(1) sample = df_Java[df_Java['Minor Violations'] > 0] ax.scatter(np.log(sample['Lines Of Code']), np.log(sample['Minor Violations']), c='#00ab6c', alpha=0.30, edgecolors='none', marker='.', label='Linearization of $MV = f(SLOC)$') ax.set_xlabel('log of SLOC') ax.set_ylabel('log of Minor Violations') ax.legend(loc='best') ax.grid(True) 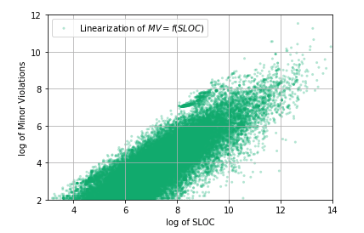
That's so much better! In logarithmic coordinates, a linear relationship between the number of lines of code and Minor Violations clearly appears: that is, there is a correlation between them! And this means that you can build a code quality model, the argument of which is the number of lines of the source code of the repository / project / developer / company, etc.
We study the structure of the distribution of Minor Violations, but in logarithmic coordinates. This will help us understand the density distribution of the number of vulnerabilities from the logarithm of the number of lines of code:
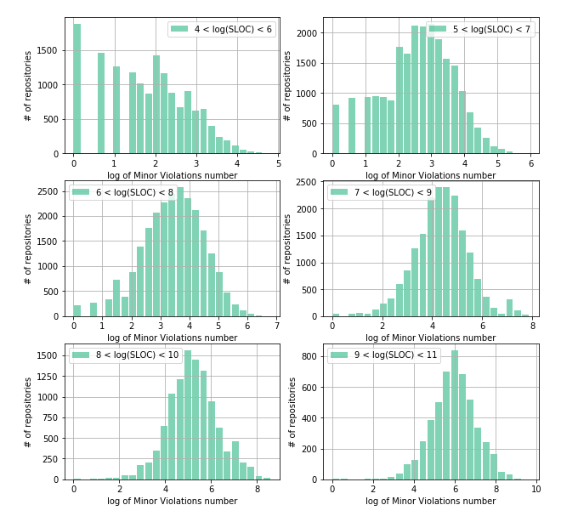
As can be seen from the obtained distribution graphs, the density structure of Minor Violations differs as the size of the repository grows. Thus, in the case of a small number of lines of code (4 <log (SLOC) <6), a significant amount of repositories has the number of Minor Violation equal to 0 (~ 1900 repositories), and the distribution structure differs from the symmetrical dome-shaped one. This is due to the fact that there is a restriction on the left, that is, a restriction on the minimum number of lines of code in the repository (obviously, it must be> = 0) on the one hand, as well as a large number of repositories with a small number of lines of code.
The distribution structure of the Minor Violation acquires a symmetrical, regular dome-shaped form only from values of the number of lines of code in the repository from ~ 1000 (exp (7) ≈ 1096), therefore from that moment the distribution structure of the Minor Violation ceases to “feel” the influence of the restriction to the left.
Thus, we decided on the range of variation of the argument, and also carried out feature engineering, having obtained the linearization of data in logarithmic coordinates:
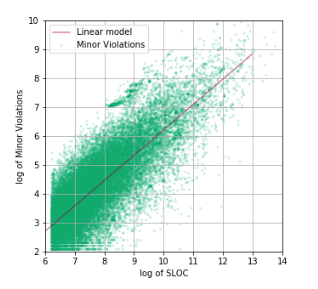
Using a linear regression, we obtained a model describing the correlation between the number of lines of code and the number of Minor Violation. The statistical characteristics of the resulting model are as follows:
R2 = 0.516, Fstats = 27510
And the model itself has the form:
log (MV) = -2.570 + 0.878 log (SLOC),
where MV is the number of Minor Violation, SLOC is the number of lines of code in the repository.
Answers to some questions
Why is such a low R2 value obtained? Because the data have a fairly large variance of the logarithm of Minor Violation for the selected logarithm of the SLOC. This immediately seemed to us a disadvantage, but then, after reflection, it became clear that this was not a disadvantage, but, on the contrary, an advantage, since it reveals all the data in its diversity. All this is a good basis for further improvement of the model, as well as the construction of a scale for assessing the quality of the source code, which will make it possible to compare repositories with different amounts of code.
How can we interpret the meaning of the line we have built? This straight line can be interpreted as a certain boundary between the code with a higher quality parameter Minor Violation and a code lower quality.
Where is the better code? A better code is under the straight line shown on the graph. Thus, although being some basis for further improvement, our model can already be used as a simple ruler for assessing the quality of source code written in Java.
Conclusion
The distribution structure of Minor Violation in repositories with source code written in Java has a non-linear nature, and its study opens up the possibility of developing an evaluation system and, accordingly, ranking the quality of the code. The code quality assessment system developed in our company allows developers and companies to track the “health” of the code of their product, as well as to quickly manage its quality.
The simplest quality model of the source code developed by us in this work serves as a good base line for its further improvement.
PS
In the near future, we are planning to study the quality of the source code for other programming languages and quality metrics, as well as the answer to the most sacramental question of all programmers of all times and peoples: which programming language is better. So stay with us!
Posted by: Yevhen Krasnokutsky
Source: https://habr.com/ru/post/439996/