An example of a simple neural network in C / C ++
Hello.
I decided to share a simple and capacious in my opinion solution of a neural network in C ++.
Why this information should be interesting?
Answer: I tried in the minimum set to program the work of the multilayer perceptron, so that it could be configured as you please in just a few lines of code, and the implementation of the basic algorithms of work on “C” will allow to easily transfer oriented languages to “C” ( and any other) without the use of third-party libraries!
I will not tell you about the purpose of neural networks , I hope you are not banned from google and you can find the information you are interested in (purpose, possibilities, areas of application, and so on).
You will find the source code at the end of the article, but for now in order.
- multi-layer perceptron with the ability to configure any number of layers with a given width. Below is
Please note that setting the input and output widths for each layer is performed according to a certain rule - the input of the current layer = the output of the previous one. The exception is the input layer.
Thus, you have the opportunity to customize any configuration manually or according to a predetermined rule before compiling or after compiling to read data from source files.
- implementation of the mechanism of back propagation of errors with the ability to set the learning rate
myNeuero.h
- installation of initial scales
myNeuero.h
Note : if there are more than three layers (nlCount> 4), then pow (out, -0.5) needs to be increased so that with direct signal passing its energy does not reduce to 0. Example of pow (out, -0.2)
- the basis of the code in C. The basic algorithms and storage of weight coefficients are implemented as a structure in the C language, everything else is a shell of the calling function of this structure, it is also a display of any of the layers taken separately
Testing the project with the mnist set was successful, we managed to achieve the conditional probability of handwriting recognition 0.9795 (nlCount = 4, learnRate = 0.03 and several epochs). The main purpose of the test was to test the performance of the neural network, with which it coped.
Below we consider the work on the "conditional task . "
Initial data:
-2 random input vectors of 100 values
- neural network with random generation of scales
-2 set goals
Code in main () function
The result of the neural network
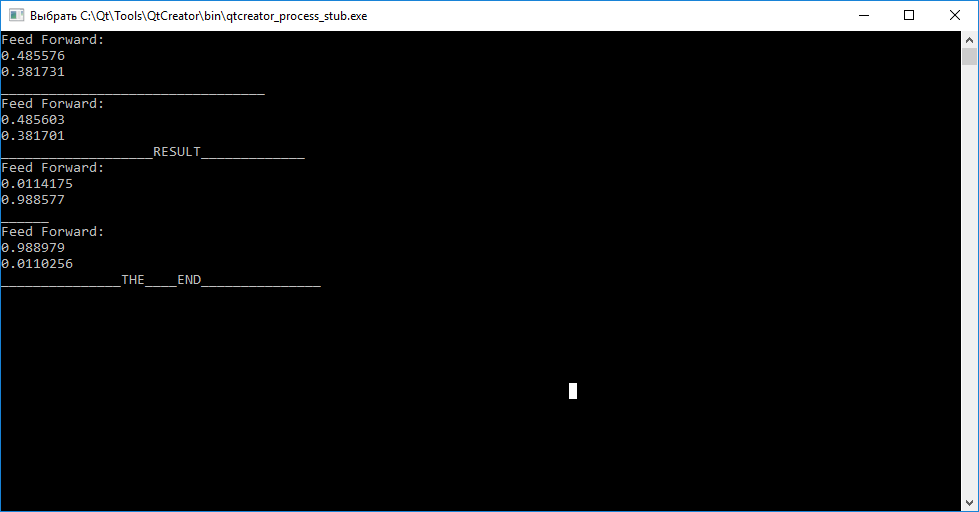
As you can see, calling the query (inputs) function before learning for each of the vectors does not allow us to judge their differences. Further, by calling the train (input, target) function, for training with the goal of arranging weights so that the neural network can later distinguish the input vectors.
After completing the training, we observe that the attempt to compare the vector “abc” - “tar1”, and “cba” - “tar2” succeeded.
You are given the opportunity using the source code to independently test performance and experiment with the configuration!
PS: this code was written from QtCreator, I hope to “replace the output” you will have no difficulty, leave your comments and observations.
PPS: if anyone is interested in a detailed analysis of the work struct nnLay {} write, there will be a new post.
PPPS: I hope someone will come in handy "C" oriented code for transfer to other tools.
I decided to share a simple and capacious in my opinion solution of a neural network in C ++.
Why this information should be interesting?
Answer: I tried in the minimum set to program the work of the multilayer perceptron, so that it could be configured as you please in just a few lines of code, and the implementation of the basic algorithms of work on “C” will allow to easily transfer oriented languages to “C” ( and any other) without the use of third-party libraries!
Please take a look at what came of it.
I will not tell you about the purpose of neural networks , I hope you are not banned from google and you can find the information you are interested in (purpose, possibilities, areas of application, and so on).
You will find the source code at the end of the article, but for now in order.
Let's start the analysis
1) Architecture and technical details
- multi-layer perceptron with the ability to configure any number of layers with a given width. Below is
configuration example
myNeuero.cpp
inputNeurons = 100; //ширина входного слоя outputNeurons =2; //ширина выходного слоя nlCount = 4; //количество слоёв ( по факту их 3, указываемое число намеренно увеличено на 1 list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); inputs = (float*) malloc((inputNeurons)*sizeof(float)); targets = (float*) malloc((outputNeurons)*sizeof(float)); list[0].setIO(100,20); //установка ширины INPUTS/OUTPUTS для каждого слоя list[1].setIO(20,6); // -//- list[2].setIO(6,3); // -//- list[3].setIO(3,2); // -//- выходной слой Please note that setting the input and output widths for each layer is performed according to a certain rule - the input of the current layer = the output of the previous one. The exception is the input layer.
Thus, you have the opportunity to customize any configuration manually or according to a predetermined rule before compiling or after compiling to read data from source files.
- implementation of the mechanism of back propagation of errors with the ability to set the learning rate
myNeuero.h
#define learnRate 0.1 - installation of initial scales
myNeuero.h
#define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5)) Note : if there are more than three layers (nlCount> 4), then pow (out, -0.5) needs to be increased so that with direct signal passing its energy does not reduce to 0. Example of pow (out, -0.2)
- the basis of the code in C. The basic algorithms and storage of weight coefficients are implemented as a structure in the C language, everything else is a shell of the calling function of this structure, it is also a display of any of the layers taken separately
Layer structure
myNeuero.h
struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; }; 2) Application
Testing the project with the mnist set was successful, we managed to achieve the conditional probability of handwriting recognition 0.9795 (nlCount = 4, learnRate = 0.03 and several epochs). The main purpose of the test was to test the performance of the neural network, with which it coped.
Below we consider the work on the "conditional task . "
Initial data:
-2 random input vectors of 100 values
- neural network with random generation of scales
-2 set goals
Code in main () function
{ //!!!________ ДЛЯ ВЫВОДА ВМЕСТО qDebug() можете использовать std::cout или std::cerr myNeuro *bb = new myNeuro(); //----------------------------------INPUTS----GENERATOR------------- /! создаём 2 случайнозаполненных входных вектора qsrand((QTime::currentTime().second())); float *abc = new float[100]; for(int i=0; i<100;i++) { abc[i] =(qrand()%98)*0.01+0.01; } float *cba = new float[100]; for(int i=0; i<100;i++) { cba[i] =(qrand()%98)*0.01+0.01; } //---------------------------------TARGETS----GENERATOR------------- // создаем 2 цели обучения float *tar1 = new float[2]; tar1[0] =0.01; tar1[1] =0.99; float *tar2 = new float[2]; tar2[0] =0.99; tar2[1] =0.01; //--------------------------------NN---------WORKING--------------- // первичный опрос сети bb->query(abc); qDebug()<<"_________________________________"; bb->query(cba); // обучение int i=0; while(i<100000) { bb->train(abc,tar1); bb->train(cba,tar2); i++; } //просмотр результатов обучения (опрос сети второй раз) qDebug()<<"___________________RESULT_____________"; bb->query(abc); qDebug()<<"______"; bb->query(cba); } The result of the neural network
Results
As you can see, calling the query (inputs) function before learning for each of the vectors does not allow us to judge their differences. Further, by calling the train (input, target) function, for training with the goal of arranging weights so that the neural network can later distinguish the input vectors.
After completing the training, we observe that the attempt to compare the vector “abc” - “tar1”, and “cba” - “tar2” succeeded.
You are given the opportunity using the source code to independently test performance and experiment with the configuration!
PS: this code was written from QtCreator, I hope to “replace the output” you will have no difficulty, leave your comments and observations.
PPS: if anyone is interested in a detailed analysis of the work struct nnLay {} write, there will be a new post.
PPPS: I hope someone will come in handy "C" oriented code for transfer to other tools.
Sources
main.cpp
myNeuro.cpp
myNeuro.h
#include <QCoreApplication> #include <QDebug> #include <QTime> #include "myneuro.h" int main(int argc, char *argv[]) { QCoreApplication a(argc, argv); myNeuro *bb = new myNeuro(); //----------------------------------INPUTS----GENERATOR------------- qsrand((QTime::currentTime().second())); float *abc = new float[100]; for(int i=0; i<100;i++) { abc[i] =(qrand()%98)*0.01+0.01; } float *cba = new float[100]; for(int i=0; i<100;i++) { cba[i] =(qrand()%98)*0.01+0.01; } //---------------------------------TARGETS----GENERATOR------------- float *tar1 = new float[2]; tar1[0] =0.01; tar1[1] =0.99; float *tar2 = new float[2]; tar2[0] =0.99; tar2[1] =0.01; //--------------------------------NN---------WORKING--------------- bb->query(abc); qDebug()<<"_________________________________"; bb->query(cba); int i=0; while(i<100000) { bb->train(abc,tar1); bb->train(cba,tar2); i++; } qDebug()<<"___________________RESULT_____________"; bb->query(abc); qDebug()<<"______"; bb->query(cba); qDebug()<<"_______________THE____END_______________"; return a.exec(); } myNeuro.cpp
#include "myneuro.h" #include <QDebug> myNeuro::myNeuro() { //--------многослойный inputNeurons = 100; outputNeurons =2; nlCount = 4; list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); inputs = (float*) malloc((inputNeurons)*sizeof(float)); targets = (float*) malloc((outputNeurons)*sizeof(float)); list[0].setIO(100,20); list[1].setIO(20,6); list[2].setIO(6,3); list[3].setIO(3,2); //--------однослойный--------- // inputNeurons = 100; // outputNeurons =2; // nlCount = 2; // list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); // inputs = (float*) malloc((inputNeurons)*sizeof(float)); // targets = (float*) malloc((outputNeurons)*sizeof(float)); // list[0].setIO(100,10); // list[1].setIO(10,2); } void myNeuro::feedForwarding(bool ok) { list[0].makeHidden(inputs); for (int i =1; i<nlCount; i++) list[i].makeHidden(list[i-1].getHidden()); if (!ok) { qDebug()<<"Feed Forward: "; for(int out =0; out < outputNeurons; out++) { qDebug()<<list[nlCount-1].hidden[out]; } return; } else { // printArray(list[3].getErrors(),list[3].getOutCount()); backPropagate(); } } void myNeuro::backPropagate() { //-------------------------------ERRORS-----CALC--------- list[nlCount-1].calcOutError(targets); for (int i =nlCount-2; i>=0; i--) list[i].calcHidError(list[i+1].getErrors(),list[i+1].getMatrix(), list[i+1].getInCount(),list[i+1].getOutCount()); //-------------------------------UPD-----WEIGHT--------- for (int i =nlCount-1; i>0; i--) list[i].updMatrix(list[i-1].getHidden()); list[0].updMatrix(inputs); } void myNeuro::train(float *in, float *targ) { inputs = in; targets = targ; feedForwarding(true); } void myNeuro::query(float *in) { inputs=in; feedForwarding(false); } void myNeuro::printArray(float *arr, int s) { qDebug()<<"__"; for(int inp =0; inp < s; inp++) { qDebug()<<arr[inp]; } } myNeuro.h
#ifndef MYNEURO_H #define MYNEURO_H #include <iostream> #include <math.h> #include <QtGlobal> #include <QDebug> #define learnRate 0.1 #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5)) class myNeuro { public: myNeuro(); struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; }; void feedForwarding(bool ok); void backPropagate(); void train(float *in, float *targ); void query(float *in); void printArray(float *arr,int s); private: struct nnLay *list; int inputNeurons; int outputNeurons; int nlCount; float *inputs; float *targets; }; #endif // MYNEURO_H UPD:
Sources to check for mnist arereference
1) Project
" Github.com/mamkin-itshnik/simple-neuro-network "
There is also a graphic description of the work. Briefly, when polling the network with test data, you are given the value of each of the output neurons (10 neurons correspond to numbers from 0 to 9). To make a decision about the figure shown, you need to know the maximum neuron index. Digit = index + 1 (do not forget where the numbers in the arrays are numbered from)
2) MNIST
" Www.kaggle.com/oddrationale/mnist-in-csv " (if you need to use a smaller dataset, just limit the while counter when reading the CSV PS file: there is an example for git)
" Github.com/mamkin-itshnik/simple-neuro-network "
There is also a graphic description of the work. Briefly, when polling the network with test data, you are given the value of each of the output neurons (10 neurons correspond to numbers from 0 to 9). To make a decision about the figure shown, you need to know the maximum neuron index. Digit = index + 1 (do not forget where the numbers in the arrays are numbered from)
2) MNIST
" Www.kaggle.com/oddrationale/mnist-in-csv " (if you need to use a smaller dataset, just limit the while counter when reading the CSV PS file: there is an example for git)
Source: https://habr.com/ru/post/440162/