Manage secrets with HashiCorp Vault
How to keep secrets? In the repository, in the deployment system or in the configuration management system? On a personal computer, on servers, and maybe in a box under the bed? How to manage secrets to prevent leaks?
Sergey Noskov ( Albibek ) - head of the group of information security platform from Avito , knows the answer to these questions and will share with us. In Avito, two years have been actively using HashiCorp Vault, during which time lumps have been made, and they have pumped the experience up to the “Master” level.
In the article we will talk comprehensively about Vault: what it is, where and how it is used in the company, how Avito manage secrets with the help of HashiCorp Vault, how Puppet and Kubernetes are used, use cases with Puppet and other SCM, what problems arise, what hurts the security men and developers, and, of course, share ideas on how to fix it.
Any confidential information:
All the information that we want to keep secret, we call a secret. This creates a problem with storage: storing badly in the repository, in encrypted form - you need to keep the encryption keys somewhere.
HashiCorp Vault is one of the good solutions to the problem.
In my opinion, this is quite a convenient tool.
What's new in HashiCorp Vault
The tool is developing and lately many interesting features have appeared in it: CORS headers for GUI without intermediaries; built-in GUI; native integration with Kubernetes; plugins for logical- and auth-backends and frameworks.
Most of the changes that I personally liked were the possibility not to write extensions and add-ons that would stand outside the tool.
For example, there is a Vault, you want to expand it - write additional logic or your UI for automation, which will automate something. Before the changes, we had to raise an additional service that stands before the Vault, and proxies all requests: first, requests go to the service, then to Vault. This is bad because there may be a reduced level of security in the intermediate service, and all the secrets go through it. Security risks are much higher when the secret passes through several points at once!
Chicken and egg problem
When you raise the issue of storing confidential information and decide to encrypt, then as soon as you encrypt something, your secret shifts from the location of the encryption to where the key is stored. This happens all the time: as soon as you keep a secret somewhere or change an existing one, you have another one and the vicious circle begins - where to keep the secret for accessing the secret .
The secret to accessing a secret is that part of security called authentication . Security has another part - authorization. The authorization process checks if the user can access exactly where he is requesting. In the case of Vault, there is a trusted third party who decides whether to give a secret or not. Authorization only partially solves the problem.
HashiCorp Vault in Avito
In Avito, HashiCorp is installed in a single large installation on the entire network. HashiCorp Vault has many different backends. We use the Consul backend from HashiCorp, too, because Vault can only maintain its own fault tolerance through Consul.
Unseal is a way to not keep a master key in one place. When Vault is launched, it encrypts everything on some key, and the chicken and egg problem again appears: where to keep the secret, which will encrypt all the other secrets. To avoid this problem, Vault has a composite key, which requires several parts of the key, which we distribute to several employees. In Avito, we set up Unseal options for 3 people out of 7. If we launch Vault, then in order for it to start working, at least 3 people must come and enter their part of the key. The key is divided into 7 parts and you can bring any of them.
We have compiled a small test Vault - a sandbox for developers where they can play. It is in the form of a Docker container and creates simple secrets so that people can touch the tool with their hands, get comfortable. In the sandbox there is no Consul and clustering, it’s just the file system on which Vault holds the encrypted secrets, and a small script for initialization.
This is what we currently store in Vault:
Inside itself, Vault stores everything only in JSON, it is not always convenient and requires additional actions from the developer, so basically we post the secrets as a file.
We do not tell the developer: “Go to Vault, take the secret!”, But put the file on the disk and inform you: “Developer, you will have a file on the disk, take the secret from it, and we will figure out how to get it from the Vault and bring you".

We have adopted a simple agreement for JSON fields, in which we indicate with what rights to upload the file. This is the metadata for the file system, and the data field is an encoded string with the secret itself, which will become the contents of the file.
Puppet + Hiera + Vault
Almost the entire Avito infrastructure uses Puppet, all servers are rolled out to them.
Puppet has a handy hierarchy tool - Hiera . Vault integrates very well with Hiera through an add-on module, because the key-value query is being sent to this library, and Vault is the key-value base itself, but with all the security features - with transparent encryption and the ability to choose access to the keys.
Therefore, the first thing we implemented is Vault in Puppet, but with one addition - we have an intermediate layer called the Router backend . Router backend is a separate Hiera module, just files on the disk in which it is written where Hiera should go after the key - to the Vault or to another location.
He needed to Hiera did not go to the Vault all the time, because it always goes across the hierarchy. This is not a problem of Vault or the load on it, but a feature of the work of Hiera itself. Therefore, if you leave only the module for the Vault without the Router backend, the Puppet master will take a very long time to build the configuration for the Puppet agent, since it will check each key in the Vault.

For Puppet, the chicken and egg problem is solved by the fact that the authorizing party is Puppet-master. It is he who gives the secret to access the secret. The puppet master has access to all the secrets at once, but each host is allowed to receive only the one that is intended for it. The host on the Puppet master is already authorized by its certificate, which is generated locally and does not leave the host limits. In principle, the secret for accessing the secret remains, but this is not so critical.
Our process of laying out a new secret in Puppet consists of the following steps.
Puppet agents are run every 30 minutes, so you have to wait a bit until the secret rolls out. This does not cause problems - we do not lay out secrets every day . While Kubernetes is not included in the case, there is little overhead and we are ready to lay out the secrets in the Vault with our hands with minimal automation.
An additional advantage is that we get the “chip” of Hiera - the secret can be laid out immediately for a group of hosts or, depending on the role of the host, which we set in the role variable.
The only danger is that if you have Puppet, and you use Hiera, do not substitute anything into the templates for variables, because many facts and variables are collected on the client side. If the attacker replaces the fact on the client, the Puppet-master will give him other people's secrets. Be sure to check the variables : use only those that the Puppet-master does not allow to determine on the client side.
How to deal with SCM without a master?
If suddenly you do not have Puppet, then, most likely, Ansible. For Chef and other centralized SCM, their solutions are a plugin that can access Vault. I offer several options that can be implemented with Ansible.
Local agent
Locally for the server, generate a token, which is actually a password to access the Vault. Token acts constantly. You can update it or automate it. With this token, you go to Vault and take your secrets.
The idea is that on your server, where you need to deliver the secrets, the agent is spinning, who comes to the Vault, looks at all the secrets and puts them in the form of files. We use the agent on several separate servers where there is no Puppet.
Minuses:
Transit encryption
Vault has a function of transit encryption, the essence of which is that the Vault acts as an encryption server . You simply bring him the plaintext, and he encrypts and issues the closed text on his private key, which he has only. Then you choose who can decrypt this closed text.
Ansible has an entity, which is also called Vault. This is not HashiCorp Vault, but Ansible Vault . Here you need not to confuse, and the secrets can be stored both in the first and in the second. In Ansible there is a ready-made plug-in for giving secrets from the Hashicorp Vault. If you give personal access to the Vault, then you can decipher the secrets. When you roll Ansible, it goes to Vault on your behalf, decrypts secrets that are in the encrypted form in the repository, and rolls it into production.
There is a drawback here too - each administrator gets access to secrets . But there is an audit: Vault is able to keep an activity log about which user came, which secret he read, which one got access. You always know who, when and what you did with the secret. This option seems to me quite good.
Big Fault No. 1
The biggest drawback that causes us the most pain is that in Vault you cannot delegate the full control of any piece of data to anyone. In Vault, access to the secret is carried out in paths that are similar to paths in UNIX — the names are usually separated by slashes, and the result is a “directory”. When you have such a path, sometimes you want to take a part of the path and give it to someone else to manage.

For example, you have entered certificates, named / certs , and want to give to individual security personnel who deal with PKI. Vault won't do it. You cannot give the right to issue rights within this prefix - so that the security officers themselves can distribute the rights to certificates to someone else.
In Vault there is no possibility to selectively issue rights to issue rights . As soon as you gave the right to issue rights, you were given the opportunity to get full access to all the secrets. In other words, you cannot give access to the Vault part.
This is one of the biggest problems. I have an idea how to solve it, I'll tell you about it later.
Kubernetes
In RIT ++, I talked about a separate system that we implemented for Kubernetes : it serves as a third party, goes to the API, checks access, and then requests a secret in Vault.
Now our system is no longer relevant, because Kubernetes native support appeared in Vault 0.9. Now Vault can go to Kubernetes and make sure that access to the secret is allowed. He does this with the help of the Service Account Token . For example, when your pod rolled out, there is a special, signed and authorized for it JWT , designed for requests to the Kubernetes API. With a token, you can also log in to Vault and get secrets for your namespace.
Everything is done at the level of the Vault itself. True, for each namespace it will be necessary to start a role, that is, to inform Vault that there is such a namespace, there will be authorization in it, and to prescribe where to go to Kubernetes. This is done once, and then Vault will go to the API itself, confirm the validity of JWT and issue its own access token.
Kubernetes Rules
In terms of the name of the services and additional metadata, we trust the developers. There is a small chance that developers may accidentally or intentionally obtain the secrets of other services that revolve in one namespace, so we introduced a rule: one service - one namespace.
New microservice? Get a new namespace with your secrets. It is impossible to cross the border into the neighboring one - there are your Service Account Token The security boundary in Kubernetes is currently a namespace. If in two different namespace you need one secret - we copy.
Kubernetes has kubernetes secrets . They are stored in etcd in Kubernetes in an unencrypted form and can “light up” in the dashboard or when launching kubectl get pods. If authentication in etcd is disabled in your cluster, or if you have given someone full read-only access, then all secrets are visible to him. That is why we introduced two rules: it is forbidden to use kubernetes secrets and it is forbidden to specify secrets in environment variables in manifests . If you set up a secret in deployment.yaml in the environment, this is bad, because the manifest itself can be seen by everyone.
Kubernetes Shipping
As I said, we need to somehow put the file in Kubernetes. We have some secret: the essence, the password, which in JSON is recorded in the Vault. How to turn it into a file inside a container in Kubernetes now?
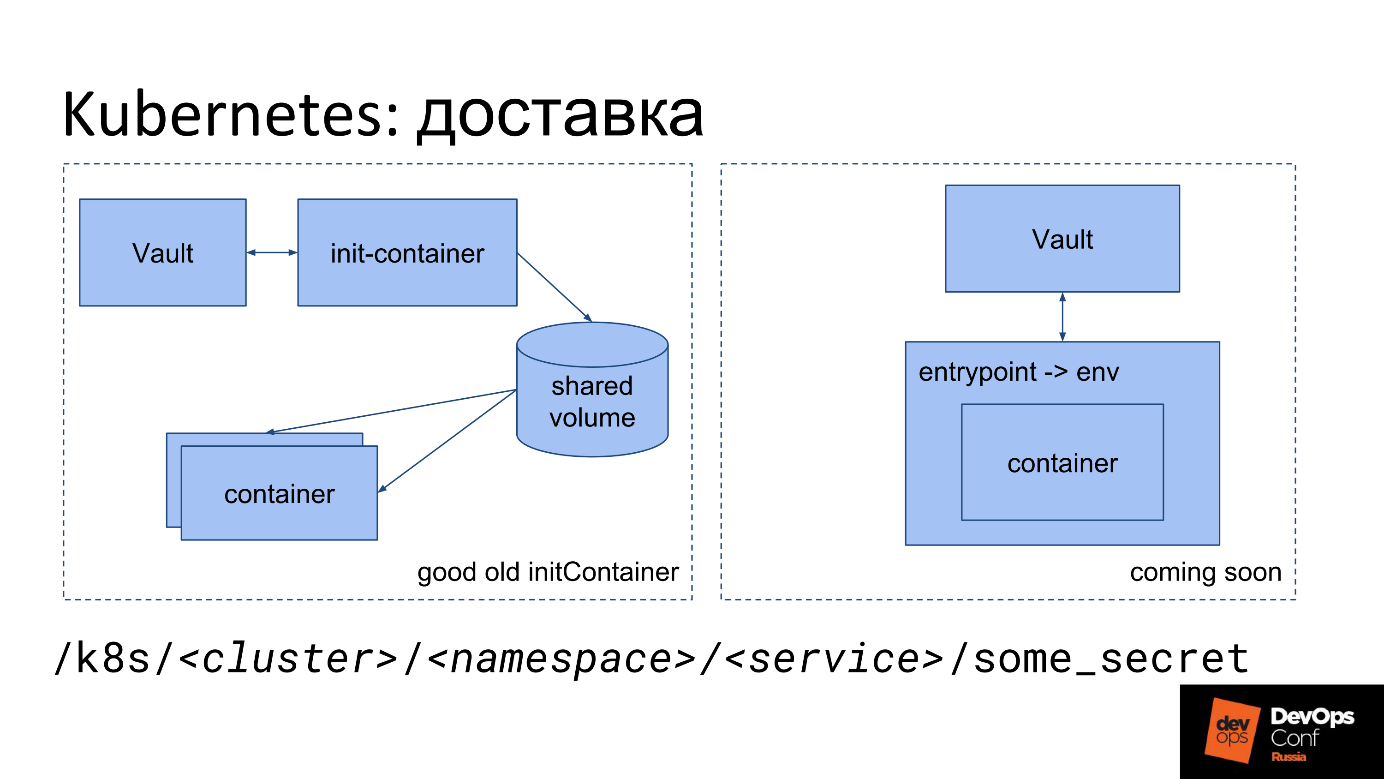
The first delivery option.
The developer just need to remember the path in which lies his secret.
We use approximately the following prefix:
The prefix name contains the cluster name, namespace and service name. Each service has its own secret, each namespace has its own secret.
The second option is your own entry point . To him, we now turn to Avito, because with the init-container developers have a problem. In the diagram, this option is on the right.
Not everyone can afford their own entrypoint. We can do it, so in every container we force our special entry point.
Our entrypoint does the same thing as init-container: it goes to Vault with Service Account Token, takes secrets and puts them out. Except in the files, he puts them back in the environment. You get the opportunity to run the application as recommended by the Twelve-Factor App concept: the application takes all the settings, including secrets, from environment variables.
Environment variables are not visible in manifests and dashboards, since they are set by PID 1 (the main container process) at launch. These are not environment variables from deployment.yaml, but environment variables that the entrypoint has set during operation. They are not visible in the dashboard, they are not visible, even if you make kubectl exec in a container, because in this case another process is launched, parallel to PID1.
Workflow
From an organizational point of view, the process goes as follows. The developer learns from the security champion or from the documentation that he cannot keep secrets in the repository, but only in Vault. Then he comes to us and asks where to put the secrets - submits an application to the security for the institution of the prefix. In the future, you can create a prefix without a request, immediately when you create a service.
The developer is waiting, and this is bad, because for him the main thing is time-to-market. Then he reads the instructions, dealt with long files - “insert that line there, insert this line here”. Never before has a developer started an init-container, but he has to figure it out and set it up in deployment.yaml (helm chart).
Committed, waits until TeamCity rolls out, sees errors in TeamCity, starts to feel pain, tries to fix something, again experiences pain. Additionally, it is superimposed that each rollout in TeamCity can still stand in a queue. Sometimes the developer can not figure out himself, comes to us, and we understand together.
Basically, the developer suffers because of his own mistakes: he incorrectly specified init-container or did not finish reading the documentation .
Security also has problems. The security worker receives a request, in which there is always little information, and we still find out the missing questions: we find out the names of the clusters, the namespace of the service, because the developer does not indicate them in the application and does not even always know what it is. When we’ll find out everything, create policies and roles in Vault, assign policies to groups and, together with the developer, begin to figure out where and why he made a mistake, and read the logs together.
The problem is solved by the unit “Architecture” by concealing from the developer deployment.yaml. They develop a piece that generates everything for the developer, including the entrypoint. Due to the fact that we substitute our entrypoint, we can use it not only to deliver secrets, but also for other things that you may need to do when starting.
Obvious problems with the secrets of Kubernetes.
We say: “Why do you need production secrets in a dev-cluster? Get a test secret, go with it! ”As a result, there are mines and secrets that are difficult to manage. If the secret has changed, do not forget about it, go and change everywhere, and there is no way to determine that it is one and the same secret, except by the name of the service.
Idea: Kubernetes KMS
New versions of Kubernetes have a KMS subsystem - Key Management Service - a new feature of Kubernetes to encrypt secrets. In v1.11 she was in alpha state, in v1.12 she was transferred to beta.

The picture from the site of the project KMS provider for Vault, and there is an error on it. If you find - write in the comments.
The point of KMS is to eliminate one single flaw - unencrypted data storage in etcd.
KMS, like Ansible, knows this.
The developers wrote a special service that does this using transit encryption. The idea seems to be working, but it is important to remember that secrets are no longer only under the control of Vault and go somewhere else, to the area of responsibility of the Kubernetes administrators.
Cons KMS.
Pros KMS.
CI / CD: TeamCity
In TeamCity, everything is simple, because JetBrains wrote a plugin that can write secrets to access the secret, encrypt them using TeamCity, and then substitute interest in the template somewhere in the template. At this point, the TeamCity agent will go off to Vault, pick up the secret and bring it to the build as a parameter.
Some secrets are needed when deploying, for example, database migration or alerts to Slack. AppRole is added to each project - the settings also contain a secret (data for AppRole), but it is entered in the write-only mode — the TeamCity does not allow reading it later.
TeamCity itself makes sure that when a secret hits the build logs, it will automatically be masked. As a result, the secret either does not “drive through” the disk at all, or is cleared from the disk by means of TeamCity. As a result, the entire security of the secret is well provided by the TeamCity itself and the plugin, and no additional dances with a tambourine are required.
CI / CD is not TeamCity?
Here are the main questions you need to think about if you use another system (not TeamCity) as your CI.
As a result, most likely you will write something very similar to the TeamCity plugin for your CI / CD. The authorizing party here will most likely be the CI / CD, and it is she who will decide whether this build can have access to this secret, and give the secret itself or not to give it to the results.
It is important not to forget to clean the build results at the end of the build , if they are laid out on the disk, or to ensure that they are only in memory.
Certificates
With certificates, nothing special - we use Vault mainly to store them.

Vault has a special PKI backend for issuing certificates, in which you can start the Certificate Authority and sign new certificates. We have a single internal PKI ... The root CA and second-level CAs exist separately, and we manage the third-level CA through Vault. To store issued certificates of any level, including certificates signed by external CAs, we use a separate prefix, and put almost all valid certificates for accounting and monitoring purposes. The format for storing certificates is its own, suitable for storing a separate private key and the certificate itself.
Summary
Too much manual work for a security person, too much entry threshold for a developer, and no built-in tools for delegation, although I really want to ...
How to be? Further dreams begin.
Ideas: how to do better
How can I get rid of a heap of copies of a secret?
Master-slave delivery
We have a master-secret and a special demon that walks, looks at the secret and its metadata, puts it in the right place, it turns out the slave-secret. On the way, where the demon laid out the slave, nothing can be changed by hands, because the demon will come and re-place the master-secret over the slave.
First, we wanted to make a symlink mechanism, just to point out: “Look for this secret there!”, As in Linux. It turned out that there are problems with access rights: it is not known how to check access rights - as in Linux or not, with parental paths, with transitions between mount points. Too many ambiguous moments and chances to make a mistake, so we refused from symlinks.
Ownership Authorization
The second thing we want to do is determine the owner for each secret . By default, the secret belongs to the person who created it. If necessary, you can extend the area of responsibility to the unit by issuing the owner group.
When we learn to delegate, we will give the owner the right to a secret, and he can do what he wants with the secret.
Now we are responsible for all the secrets and security, and we want to shift the responsibility to the creator. Security will not suffer , because the person who came to us with the request to keep a secret understands that he needs to keep the secret safely and is aware of his responsibility.
Since this is the owner of the secret, for the delivery option master-slave, he could choose where and in what format to deliver the secret. It turns out that the owner controls everything himself, no need to submit an application, you can take the necessary prefix yourself, you can also create secrets and delete it yourself.
Delegation via ACL templates
The Access Control List access policy in Vault is divided into two parts:
Now only the Vault administrator can change the ACL. Having access to such an ACL, you can prescribe everything that you want, for example, the
We want to set the ACL as a ready-made template that contains the path and placeholders that are allowed to generate new ACLs using this template.
Example
Below, the yellow font shows the path of the finished standard ACL from Vault and further allowed actions on this path. We look at it as an ACL for permission to change another ACL at the bottom, which is specified as a template.

We want to delegate access to / k8s, we allow to generate only such templates. For example, to give read access only to a specific cluster, namespace, service, but not to change the field of capabilities.
Additionally, we want to give permission to bind these ACLs and issue different rights.
We applied the template to issue the rights to the developer. When templating, he ran the

As a result, the developer, at our discretion, assigns this ACL to anyone he wants, and becomes the owner himself, he can manage it as a secret: delete, give and take away from users and groups. Now the person himself is responsible for his prefix: he manages all secrets, generates an ACL pattern, can assign an ACL to those he wants. Naturally, we can also limit it.
All magic works with the help of the new Vault entity - plugins . They are a separate service, very similar to the one I mentioned at the beginning, and work almost exactly as well. The only important difference is that they are not proxies. The plug-ins are launched “from the side” by Vault, and their main Vault process starts. Due to this, all requests go not through the service, but to Vault, which already interacts with the plugin itself, sending it a verified and cleared request.
About plug-ins, how they are arranged and how to write them, you can read on the Vault website . It is best to write them on Go, which is quite simple, because for Go there is a framework. Vault communicates with the plugin via grpc, runs it as a service, but do not be afraid, you don’t touch it - everything is already in the framework. You simply write a more or less standard REST application, in which you specify endpoints, give them ready-made functions, handlers, on which there will be logic.
Do not be afraid that you break something in the main Vault. Plugin is a separate service. Even if the plugin you have panicked and fell, the work of Vault will not break it. Vault simply restarts the plugin and will continue to work.
In addition, there are additional settings for the plugin itself: it always checks the hash sums so that no one replaces the binary. The safety of running plugins is ensured .
Sergey Noskov ( Albibek ) - head of the group of information security platform from Avito , knows the answer to these questions and will share with us. In Avito, two years have been actively using HashiCorp Vault, during which time lumps have been made, and they have pumped the experience up to the “Master” level.
In the article we will talk comprehensively about Vault: what it is, where and how it is used in the company, how Avito manage secrets with the help of HashiCorp Vault, how Puppet and Kubernetes are used, use cases with Puppet and other SCM, what problems arise, what hurts the security men and developers, and, of course, share ideas on how to fix it.
What is the secret
Any confidential information:
- login and password, for example, to the database;
- API keys;
- server certificate key (* .google.com);
- client certificate key (partners, Yandex money, QIWI);
- key for signing mobile apps.
All the information that we want to keep secret, we call a secret. This creates a problem with storage: storing badly in the repository, in encrypted form - you need to keep the encryption keys somewhere.
HashiCorp Vault is one of the good solutions to the problem.
- Safely stores and manages keys.
- It is sharpened on the world of microservices, as microservice in itself.
- In HashiCorp Vault, a lot has been done to authenticate and authorize access to secrets, for example, ACL and the principle of minimal privileges.
- REST interface with JSON.
- Security is not perfect, but at a high enough level.
In my opinion, this is quite a convenient tool.
What's new in HashiCorp Vault
The tool is developing and lately many interesting features have appeared in it: CORS headers for GUI without intermediaries; built-in GUI; native integration with Kubernetes; plugins for logical- and auth-backends and frameworks.
Most of the changes that I personally liked were the possibility not to write extensions and add-ons that would stand outside the tool.
For example, there is a Vault, you want to expand it - write additional logic or your UI for automation, which will automate something. Before the changes, we had to raise an additional service that stands before the Vault, and proxies all requests: first, requests go to the service, then to Vault. This is bad because there may be a reduced level of security in the intermediate service, and all the secrets go through it. Security risks are much higher when the secret passes through several points at once!
Chicken and egg problem
When you raise the issue of storing confidential information and decide to encrypt, then as soon as you encrypt something, your secret shifts from the location of the encryption to where the key is stored. This happens all the time: as soon as you keep a secret somewhere or change an existing one, you have another one and the vicious circle begins - where to keep the secret for accessing the secret .
The secret to accessing a secret is that part of security called authentication . Security has another part - authorization. The authorization process checks if the user can access exactly where he is requesting. In the case of Vault, there is a trusted third party who decides whether to give a secret or not. Authorization only partially solves the problem.
HashiCorp Vault in Avito
In Avito, HashiCorp is installed in a single large installation on the entire network. HashiCorp Vault has many different backends. We use the Consul backend from HashiCorp, too, because Vault can only maintain its own fault tolerance through Consul.
Unseal is a way to not keep a master key in one place. When Vault is launched, it encrypts everything on some key, and the chicken and egg problem again appears: where to keep the secret, which will encrypt all the other secrets. To avoid this problem, Vault has a composite key, which requires several parts of the key, which we distribute to several employees. In Avito, we set up Unseal options for 3 people out of 7. If we launch Vault, then in order for it to start working, at least 3 people must come and enter their part of the key. The key is divided into 7 parts and you can bring any of them.
We have compiled a small test Vault - a sandbox for developers where they can play. It is in the form of a Docker container and creates simple secrets so that people can touch the tool with their hands, get comfortable. In the sandbox there is no Consul and clustering, it’s just the file system on which Vault holds the encrypted secrets, and a small script for initialization.
This is what we currently store in Vault:
- Practically all secrets for Kubernetes microservices: passwords for databases, API keys, everything listed above.
- Secrets for calculations on the "iron" servers and LXC.
- Secrets for CI / CD builds in TeamCity, we also put in Vault. Coverage is not 100%, but quite acceptable.
- Keys of all certificates: internal PKI, external CA, for example, GeoTrust and the like.
- Shared secrets for teams.
Inside itself, Vault stores everything only in JSON, it is not always convenient and requires additional actions from the developer, so basically we post the secrets as a file.
We try to deliver secrets in the form of files.
We do not tell the developer: “Go to Vault, take the secret!”, But put the file on the disk and inform you: “Developer, you will have a file on the disk, take the secret from it, and we will figure out how to get it from the Vault and bring you".
We have adopted a simple agreement for JSON fields, in which we indicate with what rights to upload the file. This is the metadata for the file system, and the data field is an encoded string with the secret itself, which will become the contents of the file.
Puppet + Hiera + Vault
Almost the entire Avito infrastructure uses Puppet, all servers are rolled out to them.
Puppet has a handy hierarchy tool - Hiera . Vault integrates very well with Hiera through an add-on module, because the key-value query is being sent to this library, and Vault is the key-value base itself, but with all the security features - with transparent encryption and the ability to choose access to the keys.
Therefore, the first thing we implemented is Vault in Puppet, but with one addition - we have an intermediate layer called the Router backend . Router backend is a separate Hiera module, just files on the disk in which it is written where Hiera should go after the key - to the Vault or to another location.
He needed to Hiera did not go to the Vault all the time, because it always goes across the hierarchy. This is not a problem of Vault or the load on it, but a feature of the work of Hiera itself. Therefore, if you leave only the module for the Vault without the Router backend, the Puppet master will take a very long time to build the configuration for the Puppet agent, since it will check each key in the Vault.
For Puppet, the chicken and egg problem is solved by the fact that the authorizing party is Puppet-master. It is he who gives the secret to access the secret. The puppet master has access to all the secrets at once, but each host is allowed to receive only the one that is intended for it. The host on the Puppet master is already authorized by its certificate, which is generated locally and does not leave the host limits. In principle, the secret for accessing the secret remains, but this is not so critical.
Our process of laying out a new secret in Puppet consists of the following steps.
- We take a secret somewhere - someone gives it to us or spreads it.
- Put the secret in Vault, with a hierarchy like in Hiera: /puppet/role/www/site.ssl.key .
- We register the prefix in the manifest Puppet, indicating that the file is in Vault and where to get it.
- Register in YAML for Hiera router the path to the Vault and point to the backend so that Hiera can find it.
- Pull request via GIT into the manifest repository.
- We run or wait for the Puppet agent to run.
Puppet agents are run every 30 minutes, so you have to wait a bit until the secret rolls out. This does not cause problems - we do not lay out secrets every day . While Kubernetes is not included in the case, there is little overhead and we are ready to lay out the secrets in the Vault with our hands with minimal automation.
An additional advantage is that we get the “chip” of Hiera - the secret can be laid out immediately for a group of hosts or, depending on the role of the host, which we set in the role variable.
The only danger is that if you have Puppet, and you use Hiera, do not substitute anything into the templates for variables, because many facts and variables are collected on the client side. If the attacker replaces the fact on the client, the Puppet-master will give him other people's secrets. Be sure to check the variables : use only those that the Puppet-master does not allow to determine on the client side.
How to deal with SCM without a master?
If suddenly you do not have Puppet, then, most likely, Ansible. For Chef and other centralized SCM, their solutions are a plugin that can access Vault. I offer several options that can be implemented with Ansible.
Local agent
Locally for the server, generate a token, which is actually a password to access the Vault. Token acts constantly. You can update it or automate it. With this token, you go to Vault and take your secrets.
The idea is that on your server, where you need to deliver the secrets, the agent is spinning, who comes to the Vault, looks at all the secrets and puts them in the form of files. We use the agent on several separate servers where there is no Puppet.
Minuses:
- It is easy to enter a token in a small segment, but if you have several dozen servers deployed per day, you will have to generate a token for each server and set a policy. It is not comfortable.
- The token must be updated.
- Grouping servers by role, purpose, or fact is difficult; it must be synchronized with Vault.
Transit encryption
Vault has a function of transit encryption, the essence of which is that the Vault acts as an encryption server . You simply bring him the plaintext, and he encrypts and issues the closed text on his private key, which he has only. Then you choose who can decrypt this closed text.
Ansible has an entity, which is also called Vault. This is not HashiCorp Vault, but Ansible Vault . Here you need not to confuse, and the secrets can be stored both in the first and in the second. In Ansible there is a ready-made plug-in for giving secrets from the Hashicorp Vault. If you give personal access to the Vault, then you can decipher the secrets. When you roll Ansible, it goes to Vault on your behalf, decrypts secrets that are in the encrypted form in the repository, and rolls it into production.
There is a drawback here too - each administrator gets access to secrets . But there is an audit: Vault is able to keep an activity log about which user came, which secret he read, which one got access. You always know who, when and what you did with the secret. This option seems to me quite good.
Big Fault No. 1
The biggest drawback that causes us the most pain is that in Vault you cannot delegate the full control of any piece of data to anyone. In Vault, access to the secret is carried out in paths that are similar to paths in UNIX — the names are usually separated by slashes, and the result is a “directory”. When you have such a path, sometimes you want to take a part of the path and give it to someone else to manage.
For example, you have entered certificates, named / certs , and want to give to individual security personnel who deal with PKI. Vault won't do it. You cannot give the right to issue rights within this prefix - so that the security officers themselves can distribute the rights to certificates to someone else.
In Vault there is no possibility to selectively issue rights to issue rights . As soon as you gave the right to issue rights, you were given the opportunity to get full access to all the secrets. In other words, you cannot give access to the Vault part.
This is one of the biggest problems. I have an idea how to solve it, I'll tell you about it later.
Kubernetes
In RIT ++, I talked about a separate system that we implemented for Kubernetes : it serves as a third party, goes to the API, checks access, and then requests a secret in Vault.
Now our system is no longer relevant, because Kubernetes native support appeared in Vault 0.9. Now Vault can go to Kubernetes and make sure that access to the secret is allowed. He does this with the help of the Service Account Token . For example, when your pod rolled out, there is a special, signed and authorized for it JWT , designed for requests to the Kubernetes API. With a token, you can also log in to Vault and get secrets for your namespace.
Everything is done at the level of the Vault itself. True, for each namespace it will be necessary to start a role, that is, to inform Vault that there is such a namespace, there will be authorization in it, and to prescribe where to go to Kubernetes. This is done once, and then Vault will go to the API itself, confirm the validity of JWT and issue its own access token.
Kubernetes Rules
In terms of the name of the services and additional metadata, we trust the developers. There is a small chance that developers may accidentally or intentionally obtain the secrets of other services that revolve in one namespace, so we introduced a rule: one service - one namespace.
New microservice? Get a new namespace with your secrets. It is impossible to cross the border into the neighboring one - there are your Service Account Token The security boundary in Kubernetes is currently a namespace. If in two different namespace you need one secret - we copy.
Kubernetes has kubernetes secrets . They are stored in etcd in Kubernetes in an unencrypted form and can “light up” in the dashboard or when launching kubectl get pods. If authentication in etcd is disabled in your cluster, or if you have given someone full read-only access, then all secrets are visible to him. That is why we introduced two rules: it is forbidden to use kubernetes secrets and it is forbidden to specify secrets in environment variables in manifests . If you set up a secret in deployment.yaml in the environment, this is bad, because the manifest itself can be seen by everyone.
Kubernetes Shipping
As I said, we need to somehow put the file in Kubernetes. We have some secret: the essence, the password, which in JSON is recorded in the Vault. How to turn it into a file inside a container in Kubernetes now?
The first delivery option.
- We have a special init-container.
- It runs from our image.
- In the image is a small utility that with the Service Account Token goes to the Vault, takes the secret and puts it in the Shared volume.
- For the utility, a special Shared volume is mounted only in TMPFS memory so that secrets do not pass through the disk.
- Init-container goes to Vault, puts in this volume in the form of files all the secrets that it finds along the specified path.
- Further Shared volume is mounted in the main container in which it is required.
- When the main container is launched, it immediately gets what the developer needs - secrets as a file on disk.
The developer just need to remember the path in which lies his secret.
We use approximately the following prefix:
/k8s/<cluster>/<namespace>/<service>/some_secret The prefix name contains the cluster name, namespace and service name. Each service has its own secret, each namespace has its own secret.
The second option is your own entry point . To him, we now turn to Avito, because with the init-container developers have a problem. In the diagram, this option is on the right.
Not everyone can afford their own entrypoint. We can do it, so in every container we force our special entry point.
Our entrypoint does the same thing as init-container: it goes to Vault with Service Account Token, takes secrets and puts them out. Except in the files, he puts them back in the environment. You get the opportunity to run the application as recommended by the Twelve-Factor App concept: the application takes all the settings, including secrets, from environment variables.
Environment variables are not visible in manifests and dashboards, since they are set by PID 1 (the main container process) at launch. These are not environment variables from deployment.yaml, but environment variables that the entrypoint has set during operation. They are not visible in the dashboard, they are not visible, even if you make kubectl exec in a container, because in this case another process is launched, parallel to PID1.
Workflow
From an organizational point of view, the process goes as follows. The developer learns from the security champion or from the documentation that he cannot keep secrets in the repository, but only in Vault. Then he comes to us and asks where to put the secrets - submits an application to the security for the institution of the prefix. In the future, you can create a prefix without a request, immediately when you create a service.
The developer is waiting, and this is bad, because for him the main thing is time-to-market. Then he reads the instructions, dealt with long files - “insert that line there, insert this line here”. Never before has a developer started an init-container, but he has to figure it out and set it up in deployment.yaml (helm chart).
Commit -> deploy -> feel pain -> fix -> repeatCommitted, waits until TeamCity rolls out, sees errors in TeamCity, starts to feel pain, tries to fix something, again experiences pain. Additionally, it is superimposed that each rollout in TeamCity can still stand in a queue. Sometimes the developer can not figure out himself, comes to us, and we understand together.
Basically, the developer suffers because of his own mistakes: he incorrectly specified init-container or did not finish reading the documentation .
Security also has problems. The security worker receives a request, in which there is always little information, and we still find out the missing questions: we find out the names of the clusters, the namespace of the service, because the developer does not indicate them in the application and does not even always know what it is. When we’ll find out everything, create policies and roles in Vault, assign policies to groups and, together with the developer, begin to figure out where and why he made a mistake, and read the logs together.
The problem is solved by the unit “Architecture” by concealing from the developer deployment.yaml. They develop a piece that generates everything for the developer, including the entrypoint. Due to the fact that we substitute our entrypoint, we can use it not only to deliver secrets, but also for other things that you may need to do when starting.
Obvious problems with the secrets of Kubernetes.
- A very difficult workflow for both the developer and the security manager.
- You can not delegate anything to anyone. The security officer has full access to the Vault, and it is impossible to give partial access (see Large Defect No. 1).
- Difficulties arise when developers move from a cluster to a cluster, from a namespace to a namespace, when shared secrets are needed, because it is initially assumed that there are different secrets in different clusters.
We say: “Why do you need production secrets in a dev-cluster? Get a test secret, go with it! ”As a result, there are mines and secrets that are difficult to manage. If the secret has changed, do not forget about it, go and change everywhere, and there is no way to determine that it is one and the same secret, except by the name of the service.
Idea: Kubernetes KMS
New versions of Kubernetes have a KMS subsystem - Key Management Service - a new feature of Kubernetes to encrypt secrets. In v1.11 she was in alpha state, in v1.12 she was transferred to beta.
The picture from the site of the project KMS provider for Vault, and there is an error on it. If you find - write in the comments.
The point of KMS is to eliminate one single flaw - unencrypted data storage in etcd.
KMS, like Ansible, knows this.
- Go somewhere, encrypt Kubernetes native native secret and put it in encrypted form.
- If necessary, deliver to pod, decrypt and put in decrypted form.
The developers wrote a special service that does this using transit encryption. The idea seems to be working, but it is important to remember that secrets are no longer only under the control of Vault and go somewhere else, to the area of responsibility of the Kubernetes administrators.
Cons KMS.
- Decentralization of storage - removal from Vault to Kubernetes (etcd) . Secrets become uncontrollable Vault, and he is good as a centralized repository of secrets. It turns out that half of the secrets in Vault, and half somewhere else.
- Kubernetes-only solution . If you have Kubernetes-only infrastructure, you raise the Vault, and you hardly think what is stored there, because it contains only encryption keys that you manage correctly - regularly rotate, etc ... The secrets themselves are in Kubernetes, and this is convenient.
- It is difficult to share secrets between clusters . For each new cluster, you need to get everything new, copying secrets as in the case of a single Vault may not work.
Pros KMS.
- Native support in Kubernetes, including hiding when showing environment.
- Authorization in the area of responsibility Kubernetes .
- Virtually no need to maintain Vault .
- Rotation of keys out of the box .
CI / CD: TeamCity
In TeamCity, everything is simple, because JetBrains wrote a plugin that can write secrets to access the secret, encrypt them using TeamCity, and then substitute interest in the template somewhere in the template. At this point, the TeamCity agent will go off to Vault, pick up the secret and bring it to the build as a parameter.
Some secrets are needed when deploying, for example, database migration or alerts to Slack. AppRole is added to each project - the settings also contain a secret (data for AppRole), but it is entered in the write-only mode — the TeamCity does not allow reading it later.
TeamCity itself makes sure that when a secret hits the build logs, it will automatically be masked. As a result, the secret either does not “drive through” the disk at all, or is cleared from the disk by means of TeamCity. As a result, the entire security of the secret is well provided by the TeamCity itself and the plugin, and no additional dances with a tambourine are required.
CI / CD is not TeamCity?
Here are the main questions you need to think about if you use another system (not TeamCity) as your CI.
- Isolation: limit the scope of a secret to a project, team, etc.
- Who authorizes access to the secret.
- Exclude the ability to view the secret authorizing party.
- A separate build step to import the secret to the files.
- Clean up after yourself.
As a result, most likely you will write something very similar to the TeamCity plugin for your CI / CD. The authorizing party here will most likely be the CI / CD, and it is she who will decide whether this build can have access to this secret, and give the secret itself or not to give it to the results.
It is important not to forget to clean the build results at the end of the build , if they are laid out on the disk, or to ensure that they are only in memory.
Certificates
With certificates, nothing special - we use Vault mainly to store them.
Vault has a special PKI backend for issuing certificates, in which you can start the Certificate Authority and sign new certificates. We have a single internal PKI ... The root CA and second-level CAs exist separately, and we manage the third-level CA through Vault. To store issued certificates of any level, including certificates signed by external CAs, we use a separate prefix, and put almost all valid certificates for accounting and monitoring purposes. The format for storing certificates is its own, suitable for storing a separate private key and the certificate itself.
Summary
Too much manual work for a security person, too much entry threshold for a developer, and no built-in tools for delegation, although I really want to ...
How to be? Further dreams begin.
Ideas: how to do better
How can I get rid of a heap of copies of a secret?
Master-slave delivery
We have a master-secret and a special demon that walks, looks at the secret and its metadata, puts it in the right place, it turns out the slave-secret. On the way, where the demon laid out the slave, nothing can be changed by hands, because the demon will come and re-place the master-secret over the slave.
First, we wanted to make a symlink mechanism, just to point out: “Look for this secret there!”, As in Linux. It turned out that there are problems with access rights: it is not known how to check access rights - as in Linux or not, with parental paths, with transitions between mount points. Too many ambiguous moments and chances to make a mistake, so we refused from symlinks.
Ownership Authorization
The second thing we want to do is determine the owner for each secret . By default, the secret belongs to the person who created it. If necessary, you can extend the area of responsibility to the unit by issuing the owner group.
When we learn to delegate, we will give the owner the right to a secret, and he can do what he wants with the secret.
- Laying out in k8s - a policy is generated, a slave copy is created.
- Laying out on the server - a policy is generated, a slave copy is created.
- Spread in CI / CD - ...
- Transfer to another owner.
- Give new access, generate new ACLs.
Now we are responsible for all the secrets and security, and we want to shift the responsibility to the creator. Security will not suffer , because the person who came to us with the request to keep a secret understands that he needs to keep the secret safely and is aware of his responsibility.
Since this is the owner of the secret, for the delivery option master-slave, he could choose where and in what format to deliver the secret. It turns out that the owner controls everything himself, no need to submit an application, you can take the necessary prefix yourself, you can also create secrets and delete it yourself.
Delegation via ACL templates
The Access Control List access policy in Vault is divided into two parts:
- Access Control List in the classic view, which describes the access to the prefix, which way you can read and write, which way you can read, etc.
- When creating an ACL inside, you can register an asterisk at the end, which means "this prefix, and everything below it." The prefix can be assigned to a separate operation, given to a user or group, that is, linked to several different entities.
Now only the Vault administrator can change the ACL. Having access to such an ACL, you can prescribe everything that you want, for example, the
path “*” { capabilities = [sudo, ...] } , and get full access. This is the essence of Big No. 1 flaw - it is impossible to prohibit changing the contents of an ACL.We want to set the ACL as a ready-made template that contains the path and placeholders that are allowed to generate new ACLs using this template.
Example
Below, the yellow font shows the path of the finished standard ACL from Vault and further allowed actions on this path. We look at it as an ACL for permission to change another ACL at the bottom, which is specified as a template.
We want to delegate access to / k8s, we allow to generate only such templates. For example, to give read access only to a specific cluster, namespace, service, but not to change the field of capabilities.
Additionally, we want to give permission to bind these ACLs and issue different rights.
We applied the template to issue the rights to the developer. When templating, he ran the
$ vault write policy-mgr/create/k8s-microservice ... . As a result, we got ACLs in which cluster = prod, namespace = ..., service = ..., etc. are indicated. The rights were added automatically, a policy was created with the name /k8s/some-srv - this is just an ACL name that can be generated from a template.As a result, the developer, at our discretion, assigns this ACL to anyone he wants, and becomes the owner himself, he can manage it as a secret: delete, give and take away from users and groups. Now the person himself is responsible for his prefix: he manages all secrets, generates an ACL pattern, can assign an ACL to those he wants. Naturally, we can also limit it.
All magic works with the help of the new Vault entity - plugins . They are a separate service, very similar to the one I mentioned at the beginning, and work almost exactly as well. The only important difference is that they are not proxies. The plug-ins are launched “from the side” by Vault, and their main Vault process starts. Due to this, all requests go not through the service, but to Vault, which already interacts with the plugin itself, sending it a verified and cleared request.
About plug-ins, how they are arranged and how to write them, you can read on the Vault website . It is best to write them on Go, which is quite simple, because for Go there is a framework. Vault communicates with the plugin via grpc, runs it as a service, but do not be afraid, you don’t touch it - everything is already in the framework. You simply write a more or less standard REST application, in which you specify endpoints, give them ready-made functions, handlers, on which there will be logic.
Do not be afraid that you break something in the main Vault. Plugin is a separate service. Even if the plugin you have panicked and fell, the work of Vault will not break it. Vault simply restarts the plugin and will continue to work.
In addition, there are additional settings for the plugin itself: it always checks the hash sums so that no one replaces the binary. The safety of running plugins is ensured .
Useful links:
- www.vaultproject.io
- github.com/jovandeginste/hiera-router
- github.com/jsok/hiera-vault
- www.owasp.org/index.php/Security_Champions
- blog.jetbrains.com/teamcity/2017/09/vault
- github.com/oracle/kubernetes-vault-kms-plugin
About DevOps and security, CI / CD, k8s, Puppet and everything in this spirit will be spoken in HighLoad ++ (nearest to St. Petersburg in April) and DevOpsConf . Come share your experience or look at others. In order not to forget, subscribe to the blog and newsletter , in which we will remind of deadlines and collect useful materials.
Source: https://habr.com/ru/post/438740/