Why did Google need a knowledge graph
 When I introduce myself and say what our startup does, my interlocutor immediately has a question: have you worked on Facebook before, or has your development been influenced by Facebook? Many are aware of Facebook’s efforts to maintain its social graph, because the company has published several articles about the infrastructure of this graph, which it has carefully constructed.
When I introduce myself and say what our startup does, my interlocutor immediately has a question: have you worked on Facebook before, or has your development been influenced by Facebook? Many are aware of Facebook’s efforts to maintain its social graph, because the company has published several articles about the infrastructure of this graph, which it has carefully constructed.Google talked about its knowledge graph , but nothing about the internal infrastructure. However, the company also has specialized subsystems for it. In fact, now a lot of attention is paid to the knowledge column. Personally, I put at least two of my promotions on this horse - and began work on a new graph back in 2010.
Google needed to build the infrastructure not only to serve the complex relationships in the Knowledge Graph, but also to support all the OneBox thematic blocks in search results that have access to structured data. Infrastructure is necessary for 1) qualitative circumvention of facts with 2) sufficiently high throughput and 3) low enough latency to get into a good share of search queries on the web. It turned out that no available system or database can perform all three actions.
Now that I have told you why the infrastructure is needed, the rest of the article will tell you about my experience in building such systems, including for the Knowledge Graph and OneBox .
How do I know this?
Briefly introduce myself. I worked at Google from 2006 to 2013. First as a trainee, then as a software engineer in the web search infrastructure. In 2010, Google acquired Metaweb , and my team just launched Caffeine . I wanted to do something else - and started working with the guys from Metaweb (in San Francisco), spending time traveling between San Francisco and Mountain View. I wanted to figure out how to use the knowledge graph to improve the web search.
Google has had such projects before me. It is noteworthy that the project called Squared was created in the New York office, and there was some talk about Knowledge Cards. Then there were sporadic efforts of individuals / small teams, but at that time there was no established command chain, which ultimately led me to leave Google. But let's come back to this later ...
Metaweb History
As mentioned, Google acquired Metaweb in 2010. Metaweb built a high-quality knowledge graph using several techniques, including cracking and parsing Wikipedia, as well as crowdsourcing editing system in a wiki-style using Freebase . All this worked on Graphd's own graph database graph database, the graph daemon (now published on GitHub).
Graphd had some fairly typical properties. As a demon, he worked on the same server, kept all the data in memory and could issue the whole Freebase site. After buying Google put one of the tasks to continue working with Freebase.
Google built an empire on standard hardware and distributed software. A single server database could never serve both crawling, indexing, and search results. First created SSTable, then Bigtable, which horizontally scales to hundreds or thousands of machines that collectively serve petabytes of data. The machines are allocated by Borg ( K8 appeared from here), they communicate via Stubby (gRPC appeared from here) with IP address rezolving via the Borg name service (BNC inside K8) and store data in Google File System ( GFS , you can say Hadoop FS). The processes may die, the machines may break, but the system as a whole is unkillable and continues to buzz.
In such an environment got Graphd. The idea of a database serving a whole website on one server is alien to Google (including me). In particular, Graphd required 64 GB or more of memory. If it seems to you that this is a bit, remember: this is 2010. Most Google servers were equipped with a maximum of 32 GB. In fact, Google had to purchase special machines with enough RAM to serve Graphd in its current form.
Graphd replacement
Brainstorming started, how to move Graphd data or rewrite the system to work in a distributed way. But, you see, graphs are complex. This is not a key-value database for you, where you can simply take a piece of data, move it to another server and issue it when a key is requested. Counts perform efficient unions and detours that require the software to work in a certain way.
One idea was to use a project called MindMeld (IIRC). It was assumed that the memory from another server will be available much faster through the network equipment. It had to work faster than regular RPCs, fast enough to pseudo-replicate direct memory access required by the in-memory database. But the idea did not go too far.
Another idea that actually became a project was to create a truly distributed graph service system. Something that can not only replace Graphd for Freebase, but also really work in production. It was called Dgraph - a distributed graph, inverted from Graphd (graph-demon).
If you are interested, then yes. My startup Dgraph Labs, the company and the open source project Dgraph are named after the project at Google (note: Dgraph is a trademark of Dgraph Labs; as far as I know, Google does not release projects with names that coincide with internal ones).
In almost all the rest of the text, when I mention Dgraph, I mean the internal Google project, not the open source project we created. But more about that later.
Cerebro history: knowledge engine
Creating inadvertently infrastructure for graphs
Although I was generally aware of Dgraph's attempts to replace Graphd, my goal was to create something to improve the web search. In Metaweb, I met a DH research engineer who created Cubed .
As I mentioned, a motley group of engineers from the New York subdivision developed Google Squared . But the DH system was much better. I started thinking how to embed it in Google. Google had puzzle pieces that I could easily use.
The first part of the puzzle is the search engine. This is a way to determine with a high degree of accuracy which words are related to each other. For example, when you see a phrase like [tom hanks movies], she can tell you that [tom] and [hanks] are related to each other. Similarly, from [san francisco weather] we see the connection between [san] and [francisco]. These are obvious things for people, but not so obvious for cars.
The second part of the puzzle is understanding grammar. When in the query [books by french authors], the machine can interpret it as [books] from [french authors], i.e. the books of those authors who are French. But she can also interpret this as [french books] from [authors], i.e. books in French of any author. I used Part-Of-Speech (POS) tegger from Stanford University to better understand the grammar and build the tree.
The third part of the puzzle is the understanding of entities. [french] can mean a lot. This may be a country (region), nationality (belonging to the French people), cuisine (relating to food) or language. Here I applied another system to get a list of entities that can correspond to a word or phrase.
The fourth part of the puzzle was to understand the relationship between entities. When it is known how to link words into phrases, in which order the phrases should be executed, that is, their grammar, and to which entities they can match, it is necessary to find relationships between these entities in order to create machine interpretations. For example, we run the query [books by french authors], and POS says that it is [books] from [french authors]. We have several entities for [french] and several entities for [authors]: the algorithm must determine how they are related. For example, they may be related by place of birth, that is, authors who were born in France (although they can write in English). Or it may be authors who are French citizens. Or authors who may speak or write French (but may not be related to France as a country), or authors who simply love French cuisine.
The system of graphs on the search index
To determine whether there is a connection between objects and how they are related, a graph system is needed. Graphd was never going to scale to Google, but you could use the search itself. Knowledge Graph data is stored in Triples triples format, that is, each fact is represented in three parts: the subject (entity), the predicate (relation) and the object (other entity). Requests go as
[SP] → [O] or [PO] → [S] , and sometimes [SO] → [P] .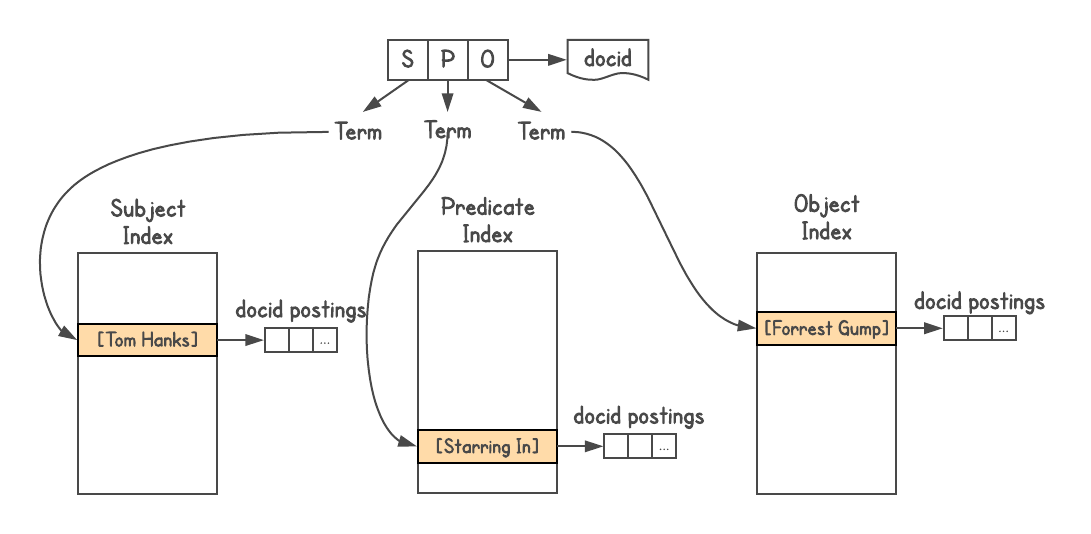
I used the Google search index , assigned a docid to each three, and built three indexes, one for S, P, and O. In addition, the index allows attachments, so I added information about the type of each entity (i.e. actor, book, person, and etc.)
I made such a system, although I saw a problem with the depth of associations (which is explained below) and it is not suitable for complex queries. Actually, when someone from the Metaweb team asked me to publish a system for colleagues, I refused.
To determine the relationship, you can see how many results each query gives. For example, how many results give [french] and [author]? We take these results and see how they are related to [books], etc. So a lot of machine interpretations of the query appeared. For example, the query [tom hanks movies] generates a variety of interpretations, such as [movies directed by tom hanks], [movies starring tom hanks], [movies produced by tom hanks], but automatically rejects interpretations like [movies named tom hanks].
Each interpretation generates a list of results — valid entities on the graph — and also returns their types (present in the attachments). This proved to be an extremely powerful function, because understanding the type of results opened up possibilities such as filtering, sorting, or further expansion. You can sort out the results with movies by year of production, length of the film (short, long), language, awards received, etc.
The project seemed so intellectual that we (DH was also partially involved as an expert in the knowledge graph) called it Cerebro, in honor of the eponymous device from the movie “X-Men” .
Cerebro often uncovered very interesting facts that were not originally in the search query. For example, on request [US presidents], Cerebro will understand that presidents are people, and people have growth. This allows presidents to be sorted by height and to show that Abraham Lincoln is the highest president of the United States. In addition, people can be filtered by nationality. In this case, America and the United Kingdom appear on the list because the United States had one British president, namely George Washington. (Disclaimer: the results are based on the state of the knowledge graph at the time of the experiments; I can not vouch for their correctness).
Blue links against knowledge
Cerebro was able to really understand user requests. Having obtained the data for the entire graph, we could generate machine interpretations of the query, generate a list of results, and understand much of these results for further study of the graph. It was explained above: as soon as the system understands that it deals with films, people or books, etc., certain filters and sorting can be activated. You can also go around the nodes and show related information: from [US presidents] to [schools they went to] or [children they fathered]. Here are some other queries that the system generated by itself: [female african american politicians], [bollywood actors married to politicians], [children of us presidents], [movies starring tom hanks released in the 90s]
DH demonstrated this opportunity to move from one list to another in another project called Parallax .
Cerebro showed a very impressive result, and Metaweb management supported it. Even in terms of infrastructure, it was operational and functional. I called it the knowledge engine (like a search engine). But on Google, no one was directing this topic specifically. She was of little interest to my manager, they advised me to talk to one person or another, and in the end I got a chance to demonstrate the system to one very high top search manager.
The answer was not the one I hoped for . When demonstrating the results of the knowledge engine for [books by french authors], he launched a Google search, showed ten lines with blue links, and said that Google could do the same. In addition, they do not want to take traffic from sites, because they are angry.
If you think he's right, think about this: when Google does a search on the Internet, you really don't understand the query. The system is looking for the right words in the right position, taking into account the weight of the page and so on. This is a very complex system, but it does not understand either the query or the results. The user himself does all the work: reading, analyzing, extracting the necessary information from the results and further searches, adding together a complete list of results, etc.
For example, for [books by french authors], a person will first try to find an exhaustive list, although there may not be a single page with such a list. Then sort these books by year of publication or filter by publishers, and so on - all this requires a person to process a large amount of information, numerous searches and results processing. Cerebro is able to reduce these efforts and make user interaction simple and flawless.
But then there was no complete understanding of the importance of the knowledge graph. The manual was not sure of its usefulness or how to connect it with the search. This new approach to knowledge is not easy to assimilate to an organization that has achieved such significant success by providing users with links to web pages.
For a year, I struggled with a lack of understanding of managers, and eventually gave up. A manager from the Shanghai office approached me, and I handed him the project in June 2011. He put on him a team of 15 engineers. I spent a week in Shanghai, passing on to the engineers everything that I created and what I learned. DH was also involved in this matter, and he led that team for a long time.
Join-depth problem
In the system of work with graphs Cerebro was the problem of the depth of association. A join is performed when the result of an earlier query is needed to perform a later one. A typical union includes some
SELECT , that is, a filter in certain results from the universal data set, and then these results are used to filter by another part of the data set. I will explain with an example.Say you want to know [people in SF who eat eat sushi]. All people are assigned some data, including who lives in what city and what food they eat.
The above query is a single-level join. If the application accesses the database, it will make one request for the first step. Then several requests (one request for each result) to find out what each person eats, choosing only those who eat sushi.
The second step suffers from fan-out problems. If the first step gives a million results (the population of San Francisco), then the second step should give out to everyone on request, asking for their eating habits, and then applying a filter.

Engineers of distributed systems usually solve this problem by Broadcast , that is, widespread distribution. They accumulate relevant results by making one request to each server in the cluster. This provides a join, but causes problems with the delay of the request.
Broadcast does not work well in a distributed system. This problem is best explained by Jeff Dean from Google in his speech “Achieving a Fast Response in Large Online Services” ( video , slides ). Total delay is always greater than the delay of the slowest component. Small reflections on individual computers cause delays, and the inclusion of many computers in the request dramatically increases the likelihood of delays.
Consider a server that has a delay of more than 1 ms in 50% of cases, and more than 1 s in 1% of cases. If the request goes to only one such server, only 1% of responses exceed a second. But if the request goes to a hundred of these servers, then 63% of the answers exceed a second.
Thus, the broadcaster of a single request greatly increases the delay. Now think, and if you need two, three or more associations? It is too slow to perform in real time.
The problem of fan deployment with query query is typical of most non-native database graphs, including graph Janus , Twitter FlockDB, and Facebook TAO .
Distributed unions are hard problems. Native graph databases allow you to avoid this problem by saving the universal data set within one server (stand-alone database) and performing all the merges without accessing other servers. For example, Neo4j does this.
Dgraph: joins with arbitrary depth
Having completed work on Cerebro and having experience in building a graph service system, I took part in the Dgraph project, becoming one of the three technical project managers. We applied innovative concepts that solved the problem of the depth of integration.
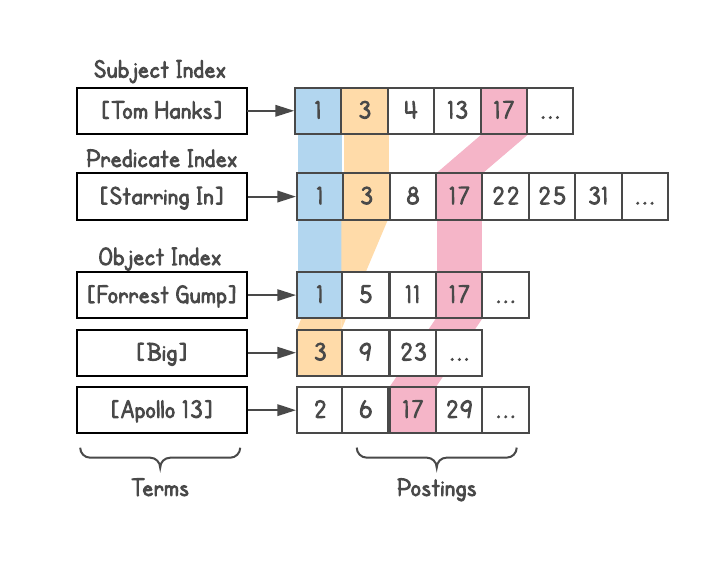
In particular, the Dgraph divides the graph data in such a way that each union can be completely executed by one machine. Returning to the
subject-predicate-object (SPO) subject-predicate-object , each Dgraph instance contains all the subjects and objects corresponding to each predicate in this instance. In a copy several predicates are stored, and everyone is stored completely.This made it possible to carry out queries with arbitrary depth of associations , eliminating the problem of fan deployment with broadcast. For example, the query [people in SF who eat sushi] will generate a maximum of two network calls to the database, regardless of the cluster size. The first challenge will find all the people who live in San Francisco. The second request will send this list to the intersect with all people who eat sushi. You can then add additional restrictions or extensions; each step still requires no more than one network call.

This creates a problem of very large predicates on one server, but it can be solved by further separating the predicates between two or more instances as the size increases. In the worst case, one predicate will split across the cluster. But this happens only in a fantastic situation, when all the data correspond to only one predicate. In other cases, this approach allows to significantly reduce the delay in requests in real systems.
Charding was not the only innovation in the Dgraph. All objects were assigned integer identifiers, sorted and saved as a list (posting list) for quick intersection of such lists afterwards. This allows you to quickly filter during a merge, find common links, etc. It also came in handy ideas from Google search engines.
We combine all OneBox blocks through Plasma
Dgraph at Google was not a database . It was one of the subsystems, besides reacting to updates. Therefore, it needed indexing. I had a lot of experience with real-time incremental indexing systems working under Caffeine .
I started a project to integrate all OneBox within this system of indexing graphs, including weather, flight schedules, events, and so on. Maybe you do not know the term OneBox, but you definitely saw it - this is a separate window that is displayed when performing certain types of requests, where Google returns richer information. To see OneBox in action, try [ weather in sf ].
Previously, each OneBox worked on an autonomous backend and was supported by different development teams. There was a rich set of structured data, but the OneBox blocks did not exchange data with each other. First, different backends multiplied the labor costs many times. Secondly, the lack of information sharing limited the range of requests that Google could respond to.
For example, [events in SF] could show events, and [weather in SF] could show events. But if [events in SF] understood that it was rainy weather, they could filter or sort events by the type of "indoors" or "outdoors" ( perhaps it is better to go to the movies in heavy rain than in football ).
With the help of the Metaweb command, we started to convert all this data into SPO format and index it with one system. I called it Plasma, the real-time graph indexing engine for Dgraph maintenance.
Leapfrog Management
Like Cerebro, the Plasma project received few resources, but continued to gain momentum. In the end, when the management realized that the OneBox blocks inevitably belong to our project, they immediately decided to install the “right people” to manage the graph system. At the height of the political game, three leaders changed, each of whom had zero experience working with graphs.
During this messy Dgraph, Spanner project managers called the Dgraph too complex . For reference, Spanner is a worldwide distributed SQL database that needs its own GPS clock to ensure global consistency. The irony of this is still tearing down my roof.
Dgraph canceled, Plasma survived. And at the head of the project they put a new team with a new leader, with a clear hierarchy and accountability to the CEO. The new team - with a weak understanding of the graphs and related problems - decided to make an infrastructure subsystem based on the existing Google search index (as I did for Cerebro). I suggested using the system I had already done for Cerebro, but it was rejected. I modified Plasma to crawl and expand each knowledge node to several levels so that the system could view it as a web document. They called this system TS ( abbreviation ).
This meant that the new subsystem would not be able to perform deep associations. Again this is a curse that I see in many companies, because engineers start with the wrong idea that “graphs are a simple problem that can be solved simply by building a layer on top of another system”.
A few months later, in May 2013, I left Google, having worked on Dgraph / Plasma for about two years.
Afterword
- A few years later, the Internet Search Infrastructure division was renamed the Internet Search Infrastructure and Knowledge Graph, and the manager, whom I once showed Cerebro, headed the Knowledge Graph direction, telling about how they intend to replace simple blue links Knowledge, as often as possible to directly answer user questions.
- When the team in Shanghai, working on Cerebro, was close to launching it into production, the project was taken from them and sent to the New York subdivision. In the end, it was launched as the Knowledge Strip. If you are looking for [ tom hanks movies ], you will see it at the top. It has improved slightly since the first launch, but still does not support the level of filtering and sorting that was laid in Cerebro.
- All three technical managers who worked on Dgraph (including me) eventually left Google. As far as I know, the rest are now working in Microsoft and LinkedIn.
- I managed to get two promotions in Google and I had to get the third one when I left the company as a senior software engineer.
- Judging by some fragmentary rumors, the current version of TS is in fact very close to the design of the graph system Cerebro, and each subject, predicate and object has an index. Therefore, it still suffers from the problem of depth of association.
- Since then, Plasma has been rewritten and renamed, but it continues to work as a real-time indexing system for graphs for TS. Together, they continue to post and process all structured data on Google, including the Knowledge Graph.
- Google’s inability to make deep associations is visible in many places. For example, we still do not see the data exchange between OneBox blocks: [cities by cities does not give out a list of cities, although all data is in the knowledge column (instead, a web page is quoted in search results); [events in SF] cannot be filtered by weather; [US presidents] results are not sorted, not filtered, or extended by other facts: their children or the schools where they studied. I guess this was one of the reasons why Freebase is no longer supporting.
Dgraph: phoenix bird
Two years after leaving Google, I decided to develop a Dgraph . In other companies, I see the same indecision regarding graphs as in Google. There were many unfinished solutions in graph space, in particular, many user solutions that were hastily assembled over relational or NoSQL databases, or as one of the many features of multi-model databases. If there was a native solution, then it suffered from scalability problems.
Nothing I saw had a coherent story with a productive, scalable design. Building a low latency, horizontally scalable graph database with arbitrary depth combining is extremely challenging , and I wanted to make sure that we built the Dgraph correctly.
The Dgraph team has spent the last three years not only studying my own experience, but also investing a lot of my own efforts in designing - creating a database of graphs that has no analogues in the market. Thus, companies have the opportunity to use reliable, scalable and productive solutions instead of another half-finished.
Source: https://habr.com/ru/post/440938/